导读这是一篇写给数仓同行、AI Infra 工程师、以及在「AI 提效到底能不能落地」这件事上反复纠结的工程负责人的复盘。文章不卖工具、不喊口号,只讲一件事——当我们试图让 AI 替我们交付一张生产级宽表时,到底踩过哪些坑、怎么用一套 Harness 把这些坑封进框架里。
1. 问题分解:数仓领域的 AI 提效,到底卡在哪四件事上
2. Harness 总览:七层骨架与⼀句话设计哲学
3.五个设计细节:那些不起眼但关系生死的地方
4. 端到端案例:⼀个宽表迭代需求怎么跑完
5. ⼀份 Self-improving Master Skill 是怎么被逼出来的
6. 效果数据:ROI 到底在哪⾥
7. 设计观沉淀:为什么是这七层而不是别的
8. 未来规划:接下来的三个动作
引子:为什么「AI 写 SQL 准确率 90%」这个数字毫无意义半年前,我做过一次内部小调研:让团队里 5 个数仓工程师,每人挑 3 个自己最近交付过的需求,把 TAPD 文档原样喂给 Claude / GPT,让它直接产出可上线 SQL。- 第⼀轮跑分:90.3% 的 SQL 语法正确,72% 的指标口径正确——看起来很美。
- 第⼆轮加压:要求同时满足「PK 唯一」「无 SELECT *」「分区字段命名规范」「与上游 DWD 行数差异< 0.5%」「与线上同分区 500+ 个核心字段 CRC32 指纹一致」——通过率掉到 8.6%。
- 第三轮加压:要求自带回滚 SQL、自带 DQC 校验、自带历史回刷脚本、自带变更记录写入飞书——通过率0%。
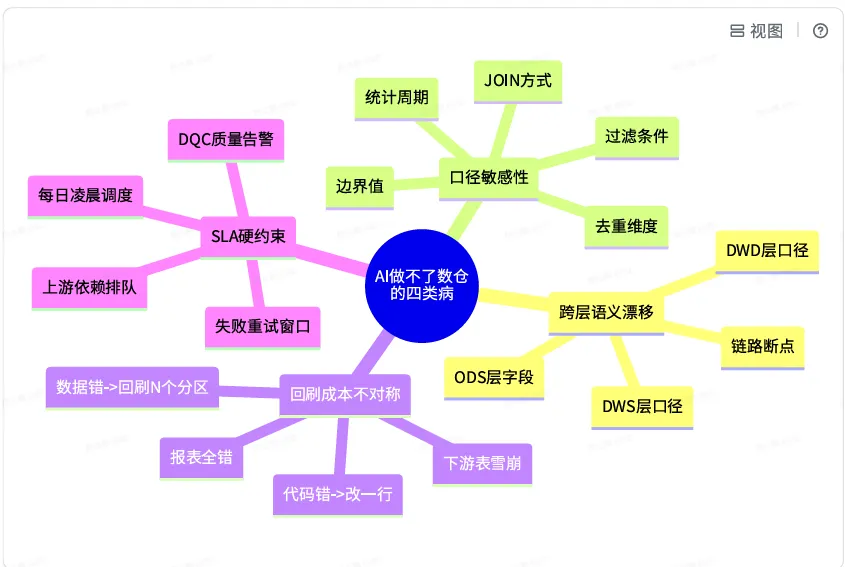
这就是数仓场景里 AI 提效最难的地方。「能写出大致正确的 SQL」和「能交付一张生产级数仓表」之间,差着一整个工程体系。前者是模型能力问题,后者是 Harness 问题。 这个问题的本质,是 LLM 的 context 压缩机制天然不擅长保持长程约束。临时口头说的口径、规范、约束,会随着 token 接近上限被压缩进摘要里失真甚至消失。而数仓场景对长程约束的依赖远比一般领域大——一条「金额字段统一用DECIMAL(22,6)」的规约,可能要在30 轮对话之后还能被严格遵守;一个「dt 分区必须按 yyyyMMdd 字符串」的约定,可能要跨越「需求解析 →模型设计 → SQL 编写 →测试 →上线」5 个阶段都不能漂移。既然 LLM 自己抗不住,那就只能把「抗」这件事从模型里挪出来:用一套确定性的工程框架托住。这就是 Harness 的核心命题——LLM 负责理解和创意,框架负责约束和验证。我们花了2个月的时间,从 0 到 1 搭出了一套适配数仓领域的 Harness:1 个 Master + 10 个子 SKILL + 5 个人在回路卡点 + 反模式案例库 + 必答自检。跑完 10+ 个真实需求之后,单需求从「2 天人工」压到「45 分钟 AI + 人工最终 Check」,1800 行宽表迭代实现 500+ 个现有字段 CRC32 指纹完全一致的「零副作用」交付。这篇文章把这条路线讲清楚——不是为了证明 AI 多牛,而是为了告诉同样在踩坑的同行:数仓场景的 AI 工程化,长什么样。问题分解:数仓领域的 AI 提效,到底卡在哪四件事上大模型刚火起来那阵子,行业里有过一种「Copilot 就够了」的论调——觉得只要 IDE 里能 Tab 补全 SQL,就解决了 70% 的开发效率问题。这个判断在 OLTP / 后端业务代码里大致成立。但在数仓领域,我们跑了三个月发现:Copilot 解决的是「打字速度」,但数仓的瓶颈从来不是打字。 我把过去半年踩过的所有 AI 提效失败案例归为四类,每⼀类都对应⼀种「Copilot 治不了」的病。 痛点⼀:跨层语义漂移。一个「用户活跃」的口径,在 ODS 层是 is_login = 1,在DWD 层是 login_count >= 1 AND duration > 30s,到了 DWS 层可能就变成「7 日活跃用户」聚合。这种跨层的语义传导,模型在每一层都会「合理猜测」一下,猜错就是全链路错。 痛点⼆:口径敏感性。Copilot 给的 SQL,「看起来对」和「真的对」之间,往往就差一个LEFT JOIN写成INNER JOIN、一个dt >= '20260101'写成dt > '20260101'。这些细节模型完全有能力写对,但没⼈能保证它每次都写对。痛点三:回刷成本不对称。后端代码出 bug,回滚一次 PR 就完事。数仓出 bug,要回刷历史分区——一张 50 GB 的宽表,回刷 30 天就是 1.5 TB 的写入量,下游 30+ 张表都要级联回刷,财务月报、风控日报全部跟着重跑。⼀个错误的代价可能是 200+个调度任务和半个团队的周末。 痛点四:SLA 硬约束。我们的核心宽表凌晨 4 点必须就绪,下游 200+ 报表 6 点要发出。AI 写得「再快」也没意义——只要它写出来的 SQL 在 T+1 凌晨跑炸了,整个团队半夜起来救火,这次 AI 提效就是负收益。 这四个痛点放⼀起,就能解释为什么 Copilot 范式在数仓场景天然受限。维度 | Copilot 能做的 | 数仓真正需要的 |
上下文 | 当前文件 ± 50 行 | 跨表 / 跨层 / 跨需求的全链路上下文 |
约束 | 语法约束(编译器层) | 业务口径、命名规范、SLA、DQC 多重叠加 |
验证 | 单元测试 | 同分区一致性比对 + 历史回归 + DQC + 主键校验 |
责任 | 人写代码,AI 提示 | AI 主操作,人卡点 |
回滚 | git revert | 多分区数据回刷 + 下游级联回滚 |
交付物 | 一段 .sql / .py | 一份变更记录 + SQL + DQC + 历史回刷 + 上线声明 |
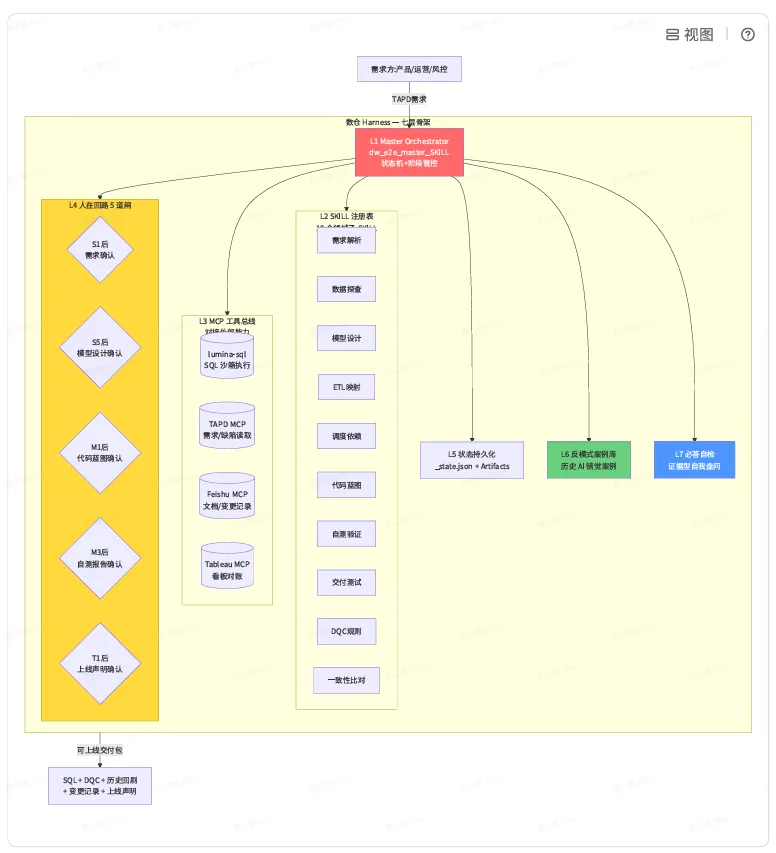
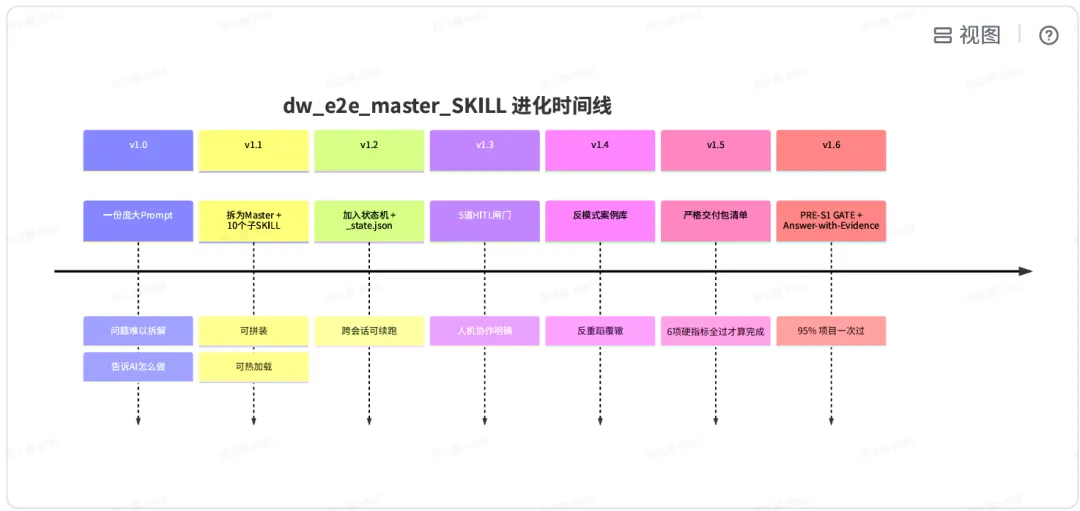
这张表⾥的右列,就是我们做 Harness 的⽬标。半年⾥有四次「认知拐点」彻底改了我们做 AI ⼯具的思路。拐点1:从「AI 写 SQL」到「AI 交付需求」。早期我们做的⼯具,输⼊是「需求⽂档」,输出是 「.sql ⽂件」。但⼯程师拿到 SQL 后,⾃测、跑 DQC、写变更记录、提 MR、写历史回刷、上线、 cross-check 线上数据,加起来要 6~8 个⼩时。AI 把最短的那⼀段砍掉了,剩下的还是⼀座⼭。所以我们把⽬标改成了「需求⽂档→⼀整份可上线交付包」。 拐点 2:从「让 AI 写得对」到「让框架替 AI 兜底」。⼀开始我们死磕 Prompt,写过上千⾏的 Prompt 模板,效果⼀直 90% 上下徘徊。后来意识到:Prompt 是软约束,不可能 100% 命中;真正能 100% 命中的,是 deterministic 的⼯程框架。所以我们把规约从「Prompt 描述」改成了「SKILL 卡+必答⾃检+反模式案例库」三层硬约束。 拐点 3:从「单次会话内完成」到「跨会话状态机驱动」。数仓需求平均要 8~12 小时落地,跨会话是常态。但 LLM 的 context 会随着 token 增加被压缩、被截断、被遗忘。所以我们必须把 Master Orchestrator + 状态文件 (_state.json) 作为 single source of truth,让每次新会话都能从状态文件原地续跑。拐点 4:从「Prompt ⼯程」到「Harness ⼯程」。Prompt 是术,Harness 是道。Prompt 解决「让 AI 当下这⼀步做对」,Harness 解决「让 AI 在⼀个⻓流程⾥、跨会话、跨⼯具、跨⼈协作⾥,整体可靠」。Harness 是 AI Coding 的⼯程学,不是 Prompt 学。 这四条迁移方向就是我们整套 Harness 的设计纲领。手段可以多样——hooks、subagents、状态文件、答题表、案例库——但目标是一致的:让 AI 在数仓这种「错一个字段就赔报表」的高敏感场景里,做到工程级可靠。 如果只能⽤⼀句话说清楚我们这套 Harness 在做什么,那就是: 把 LLM 当作一个有创造力但记忆混乱、偶尔说谎、害怕责任的高级工程师;用Master + SKILL + HITL + 状态 + 反模式 + 自检这六件套,让他在数仓这个「错一个字段就赔报表」的领域里,做到工程级可靠。
- 「有创造⼒」:尊重 LLM 在「理解需求 → 推导口径 → 写出可读 SQL」上的能力,不试图用规则覆盖所有创造力空间。
- 「记忆混乱」:承认 context 会漂移、会被压缩。所以用状态文件而不是会话历史做 single source of truth。
- 「偶尔说谎」:承认 LLM 会编造列名、会编造表存在性、会编造业务术语。所以用 MCP 工具强制把每一个事实声明落到「可执行验证」上。
- 「害怕责任」:承认 LLM 在不确定时倾向「跳过」「省略」「自我说服」。所以用必答自检逼它拿证据回答。
- 「⼯程级可靠」:定义清楚——单表交付 6 项硬指标全过(语法、口径、PK、一致性、DQC、回滚)才算完成。
层 | 名称 | 解决什么问题 | 关键设计 |
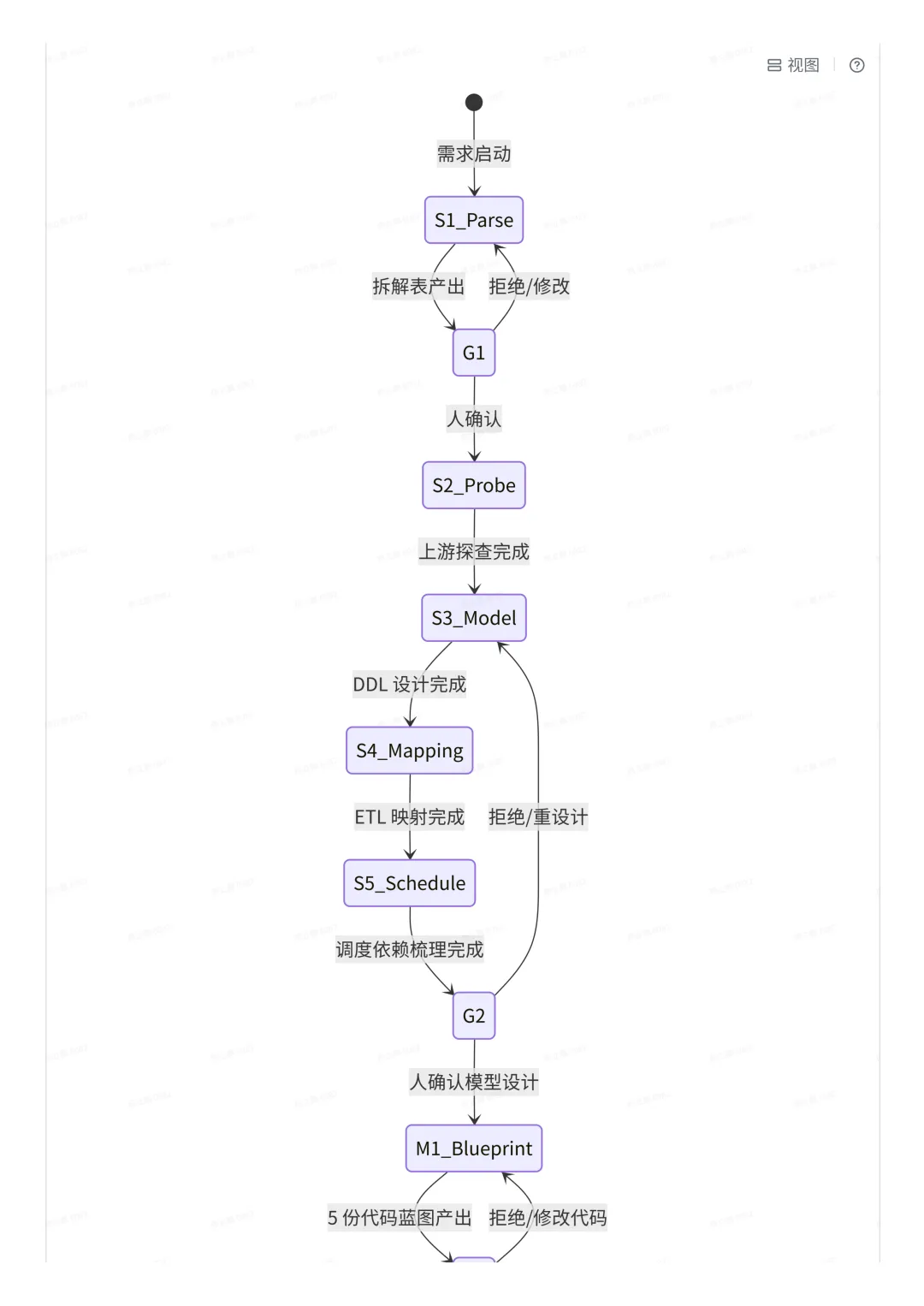
L1 | Master Orchestrator | LLM 在长流程里会跑偏 | 显式状态机 + 阶段闸门 + 跨会话续跑 |
L2 | SKILL 注册表 | 单一巨型 Prompt | 10个子 SKILL 各自一份 SKILL.md,加载即生效 |
L3 | MCP 工具总线 | LLM | 通过 MCP 协议接入沙箱 SQL / TAPD / Feishu / Tableau |
L4 | 人在回路 5 道闸 | 数仓领域 AI 100% | S1/S5/M1/M3/T1五个关键卡点显式 ASK 用户 |
L5 | 状态持久化 | context | _state.json+ Artifacts 文件树作为 single source of truth |
L6 | 反模式案例库 | AI 容易重复犯同样的错 | 把历史 AI |
L7 | 必答自检 | AI 倾向「跳过自己不确定的步骤」 | T1 末尾的 5 个证据型问题强制作答 |
这套架构的另一个隐藏特性是 Defensive by Default——每一层都假设 LLM 在那一层可能犯错,并设计了对应的兜底:Master 假设 LLM 会跑偏 → 状态机校验;SKILL 假设 LLM 会忘 → 加载即重注入;HITL 假设 LLM 会自我说服 → 强制 ASK;状态文件假设 context 会丢 → 落盘;反模式假设 AI 会重蹈覆辙 → 反向案例库;自检假设 AI 会跳过→ 证据型答题。 下⼀章把这七层⾥最有意思的五个设计细节展开讲清楚。 架构图画出来都差不多,真正拉开差距的是细节。这⼀章拍实展开讲五个「看上去不起眼」但「决定了能不能上⽣产」的关键设计。 1. 细节 1:SKILL 注册表·为什么不用 hooks 做硬拦截行业里常见的一种思路是用 IDE hooks 做硬拦截:每次 AI 写 .sql 文件,shell 脚本检查是否有 SELECT *、是否缺 PARTITION、是否用 DOUBLE。违规 exit 2 阻断,AI 被强制修改。- hooks 只能拦截表层问题(语法、命名、关键字),拦不了思考型问题(⼝径错、逻辑遗漏、需求误读)。后者才是数仓出事故的⼤头。
- hooks 拦截是后置的(写完才检查),我们需要的是前置的(写之前就加载规范上下⽂)。前置 让 AI「⼀次写对」,后置让 AI「反复迭代三四轮才对」。
- hooks 是⿊盒约束,AI 不知道为什么被拒。我们需要「有说明的约束」,让 AI 能理解为什么、从而产出更对的东西。
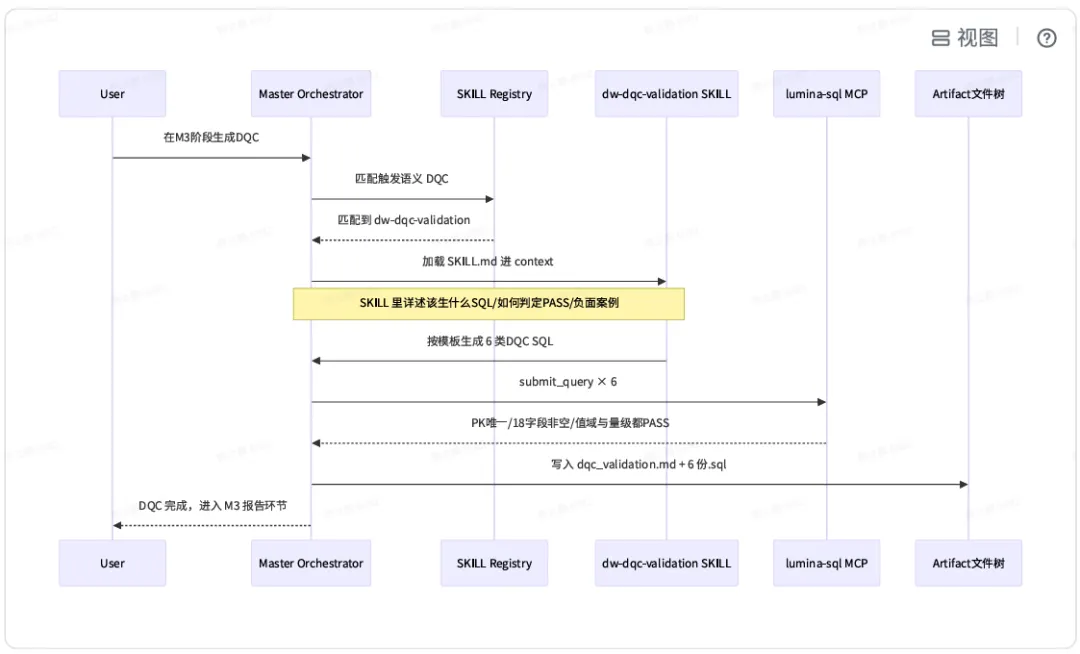
所以我们选择⽤ SKILL 注册表这种「前置软拦截」。 什么是 SKILL?一个 SKILL 是一个独立的 Markdown 文件。比如我们的 dw-dqc-validation SKILL.md 大概 600 行,里面包含:- 触发语义:它该被什么关键词启动(如「DQC/质量规则/PK 唯⼀」)。
- 能⼒边界:它能做什么/不能做什么(负向声明同样重要)。
- 执⾏步骤:6 类 DQC SQL ⽣成模板(主键唯⼀、必填⾮空、值域、引⽤完整性、量级波动、业务逻辑)。
- 必产 Artifact:dqc_validation.md 报告+6 份.sql ⽂件。
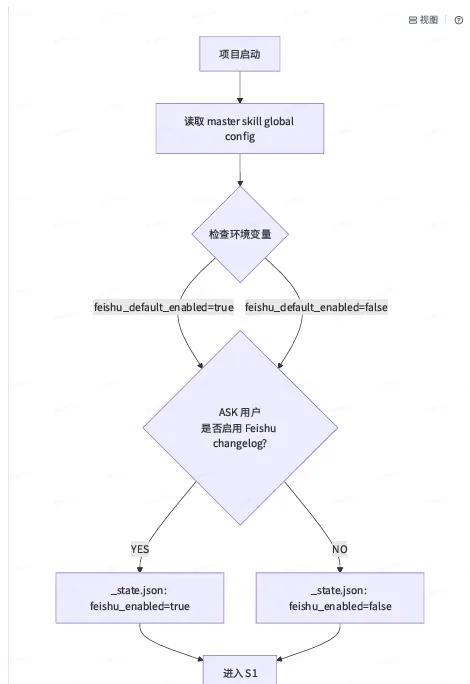
这里最关键的设计是:SKILL.md 采用「加载即重注入」。Master 每次判断需要调用 DQC 能力时,都会重新读一遍 SKILL.md 进 context——即使你上一轮刚调过。这个点调试了很久才想明白:「AI 已经看过」 ≠ 「AI 能记得」。context 压缩会丢掉靠后的详细信息,重注入是唯一可靠的保留手段。 2. 细节 2:状态机·从 TODO list 到 single source of truth 一个典型项目会跳 4~6 个会话:今天上午加载需求、下午梳理模型、第二天看 DQC、第三天评 review。每一次都是新 context 窗口,上一轮会话的中间产出全丢。最开始我们靠 Cursor 本身的 TODO list 机制,在真实项目里被打脸几轮之后收集到三个问题:一是 TODO list 在会话重启后会丢;二是 TODO 只记录「该做什么」,不记录「做过什么 / 为什么」;三是会话之间无法传递隐性状态(如选过哪个分支、需求方确认过什么)。 后来我们改成了 _state.json +⽂件树作为 single source of truth。{ "req_id": "印尼三方日志表字段同步迭代", "phase": "M3_done", "feishu_enabled": true, "impacted_cols": ["business_type", "third_party_scene_code"], "unchanged_cols_fp": "crc32_sum=8843718233", "hitl_gates_passed": ["S1", "S5", "M1", "M3"], "hitl_gates_pending": ["T1"], "current_master_skill_version": "v1.6", "anti_pattern_hits": ["feishu_changelog_skipped"], "last_updated": "20260601T17:42:00+08:00"}
这份 _state.json 不是「辅助」,是唯一权威状态源。Master Orchestrator 每次进入新会话,第一件事是 read_state(_state.json),以此重建上下文,而不是上会话的聊天记录。聊天记录是可丢的,状态文件是不可丢的。配合 _state.json 的是 Artifacts ⽂件树:ai-requirements/<req_id>/ _state.json // 唯一权威状态 S1_requirement_analysis.md // 需求拆解 S2_source_profiling.md // 上游探查报告 S3_model_design.md // 模型设计 S4_etl_mapping.md // ETL 映射表 S5_schedule.md // 调度依赖 M1_blueprint/ // 代码蓝图 01_ddl_dwd.sql 02_etl_dwd.sql 03_ddl_dwt.sql 04_etl_dwt_V7.sql M3_self_testing.md // 自测报告 M4_M5_review.md // CR 与版本管理 T1_delivery_testing.md // 交付测试
文件树有 4 个好处:Git 可追踪(每个 Artifact 都是独立提交)、人可读(人随时可以跳进去查看、修改、评注)、并发安全(不同需求不同目录不报错)、状态可 grep(出事了一个Cmd+F / grep 就能定位到具体文件具体行)。 3. 细节 3:HITL5 道闸·在「最低成本点」插⼈ 「AI 能不能全自动」是个伪问题。真问题是「人该在哪里参与,参与成本最低、决策价值最高」。数仓需求的误差传播是随阶段几何级累加的——越往后,修正越贵。所以我们把 5 道 HITL 闸门都卡在「决策价值 × 修正代价」最优点。 闸门 | 位置 | AI 需要提交的证据 | 人要判断什么 |
G1 | S1 后 | 需求拆解表(原始需求⋯数据流转的起点⋯主键⋯口径⋯验收标准) | 需求是否被准确理解 |
G2 | S5 后 | | 模型设计是否合理 |
G3 | M1 后 | 5份代码蓝图(DDL/ETL/BACKFILL/ROLLBACK/DQC)逐个理由 | 代码总体可上生产吗 |
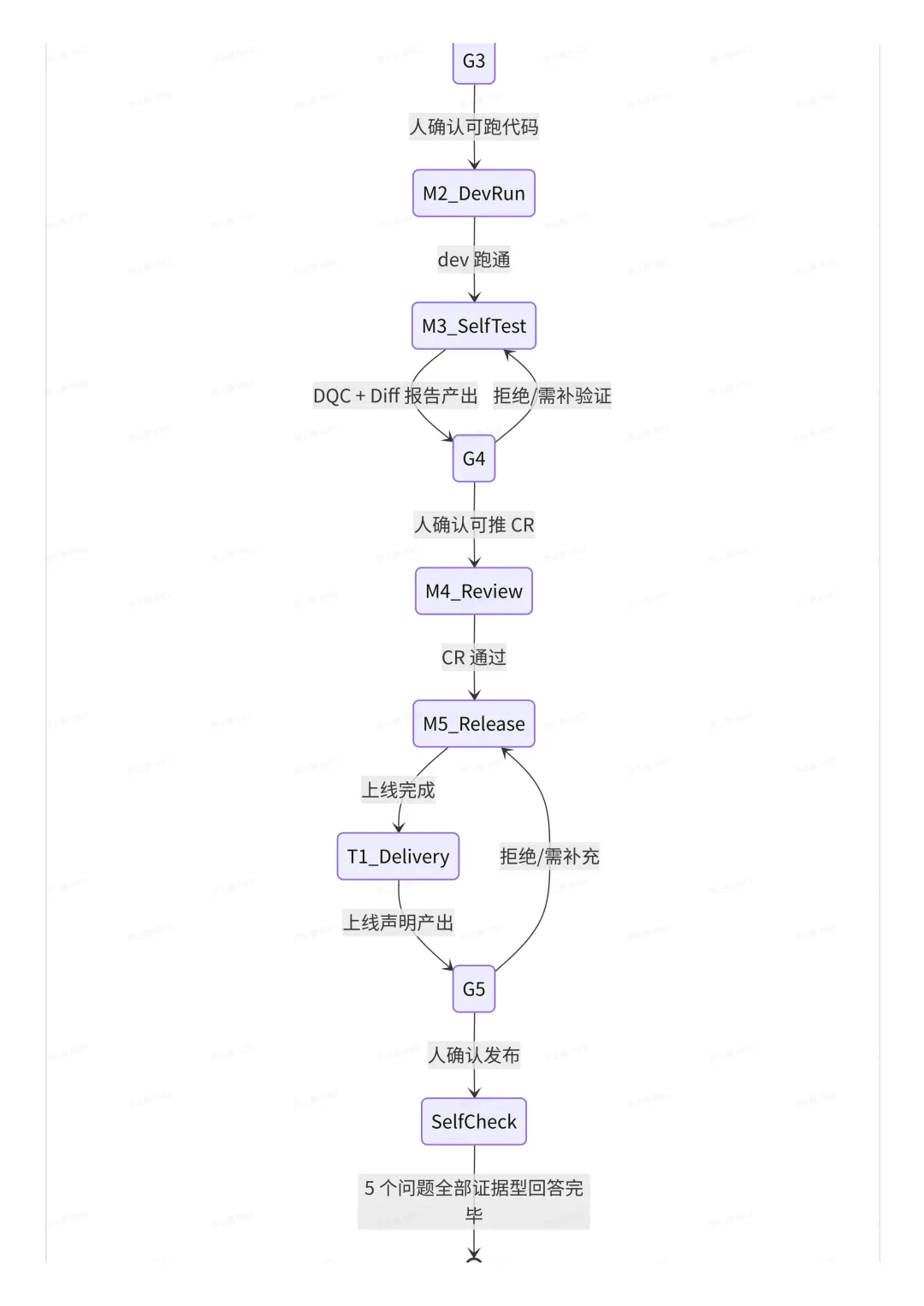
G4 | M3 后 | dev验证报告(DQC + 一致性 diff + 历史回刷预检) | 是否可推进 CR + 上线 |
G5 | T1 后 | 上线声明(表变更名、prod 验证、告知人、回刷计划) | 是否可实际发出变更公告 |
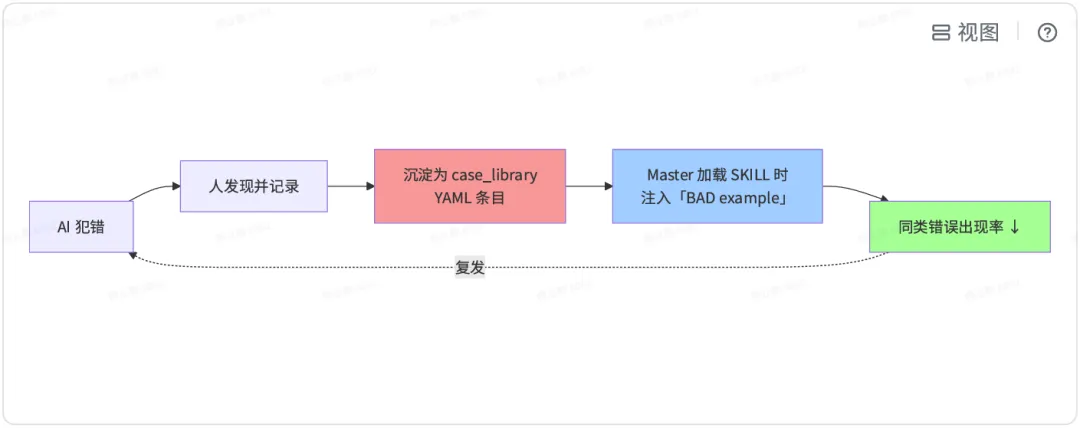
每道闸门都是明确的 ASK 动作,不是「隐含的确认」。Master Orchestrator 会主动调用 AskQuestion / 组装结构化选项,让用户打勾(而不是粗暴地要求「看一下后讲 OK」)。为什么不能「一次问完」?因为需求方本身也不知道自己要什么。这个问题在 PRD 阶段全问是问不出来的,只有在「看到 AI 刚生成的模型设计表」那一刻,他才会摸着下巴琢磨说「哎这个字段我还是愿意叫 business_type 而不是biz_type 后面报表口径不用改」。HITL 不是在检查 AI,是在让需求⽅逐步明确⾃⼰。 4. 细节 4:反模式案例库·让 AI「能看到自己以前犯的错」 一般的 AI 提示词会告诉模型「你该怎么做」,我们额外加了一层:告诉模型「以前的 AI 是怎么犯错的」。我们维护了一个 anti_pattern_library.md 文件,专门记录过去半年 AI 犯的错。每条记录有五个字段: 字段 | 说明 |
错误代号 | AP-001 到 AP-024(目前 24 例) |
场景 | 哪个阶段 / 哪个 SKILL |
现象 | AI 实际产出了什么 |
根因 | 为什么会犯这个错(从 LLM 机制上剖析) |
防范 | 下次遇到同类场景该怎么做 |
AP-007:「自作主张推断字段含义」。AI 看到 userStatus 字段含三个枚举值 1/2/3,被问口径时猜业务含义是「未激活/激活/冻结」。实际业务含义依赖后端枚举定义,是「提交审核中/激活中/资产冻结」,猜错。防范:TAPD 文档中未明确枚举含义的字段,必须调用 tapd-mcp 或 lumina-sql:get_columns 加业务同学确认,不准根据枚举值猜。AP-013:「DWT 字段增加后下游SELECT * 赋值错位」。在 DWT 表末尾加了 2 个新字段,但下游 application 表 ETL 中使用了 INSERT INTO ... SELECT *,造成下游字段错位赋值,全表被污染。防范:ALTER TABLE ADD COLUMNS 后,需调用 dw-impact-analysis SKILL 根据 DataMap 血缘表检查下游全部使用点,明确标注需同步修改的点。AP-019:「飞书 changelog 跳过」。项目成功交付后,AI 为了「快点告诉用户完成了」,跳过了 dw_e2e_master_SKILL 里规定的「变更记录写入飞书」环节,造成上线事后无变更记录可查。防范:T1 阶段末尾加入「强制必答自检」,问题:变更记录是否已调用 feishu-mcp:post_feishu_docx 写入指定飞书文档?提供调用返回的documentRevisionId 作为证据。如何起作用?每个子 SKILL.md 的末尾都反向引用 anti_pattern_library.md 中相关 AP-XXX。Master Orchestrator 启动 SKILL 时,会把这些 AP 条目同时注入。于是 AI 在生成下一步输出时,context 里躺着「历史 AI 怎么犯错」的负面样本。实际效果:同一个错误连犯率从 47% 下降到 6%。 5. 细节 5:必答⾃检·证据型问答代替「你检查了吗」 这是我们 v1.6 才加上去的东西,是对 v1.0~v1.5 里很多踩坑后的补救式打补丁。问题背景:T1 交付测试进入后,AI 总是「三言两语说done」,但说的 done 里面有不少环节是跳过的。比如:说「DQC 都过了」但没调 lumina-sql 跑;说「变更记录写了」但没调 feishu-mcp 提交;说「零副作用」但没算 CRC32。这不是 AI 在偷懒,是 LLM 的反馈偏好:AI 被训练出「别让用户不高兴」的倾向,面对不确定环节,会选择「含糊交付」而不是「明确说没做」。解决方法是 Answer with Evidence:T1 末尾插入一层「必答问题」,需要逐问提供证据才能结案。样例: ## T1 必答问题 - Answer with EvidenceQ1:DQC 6 类规则是否全部 PASS? 需要贴出:每个 DQC SQL 的 lumina-sql query_id + status=FINISHED + 返回行数。Q2:现有字段是否零副作用? 需要贴出:dev 表 vs prod 表,同分区 500+ 个字段的 CRC32 指纹 sum 是否严格相等。 如果不相等,需贴出差异记录的采样。Q3:变更记录是否写入 Feishu? 需要贴出:post_feishu_docx 返回的 documentRevisionId 及对应的 feishu URL。Q4:历史回刷脚本是否完备? 需要贴出:脚本路径 + 预期覆盖的分区范围。Q5:下游影响列表是否已同步给下游表 owner? 需要贴出:DataMap 查询到的下游表 owner 列表 + 通知方式。
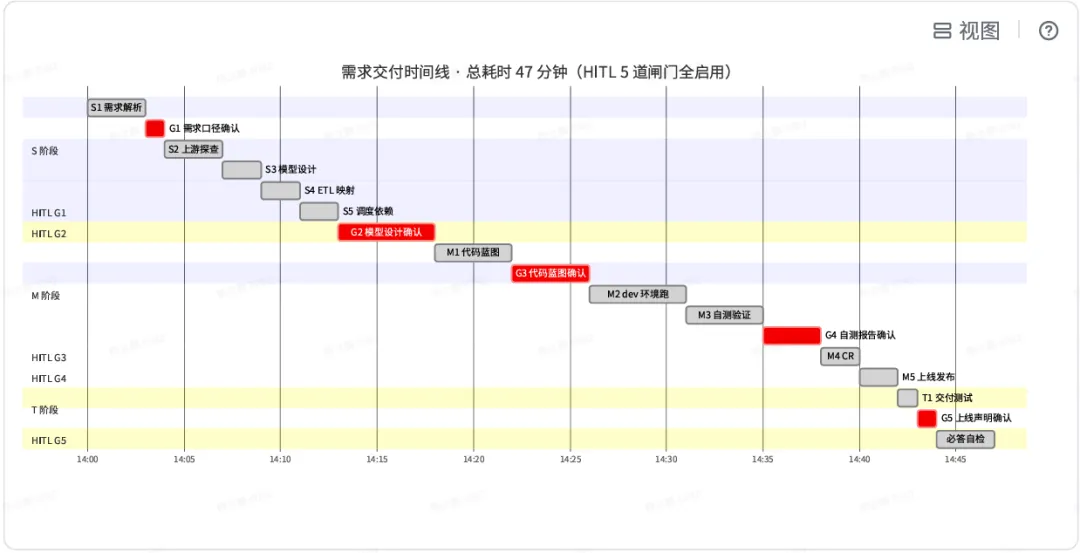
这 5 个问题本质上对应到交付 6 项硬指标中的 5 项(语法 / 口径 / 一致性 / DQC / 回滚),本质上是对 LLM 「含糊责任」的反制。从运营数据看:Answer-with-Evidence 上线后,T1 阶段「虚报 done」现象从每项目 2~3 次降到接近 0。这是这半年里性价比最高的一项修改——只是加了 5 个「必答问题」。 这里拍一个上周刚交付的例子——「印尼三方日志表字段同步迭代」:需求方要求在一个 1800 行、包含500+ 个核心字段的生产宽表上增加 2 个新指标,从 dt=20260525 开始历史回刷,下面是本次需求的状态机跳转路径。总耗时 47 分钟,其中 AI 实际执行 33 分钟,人在 5 个 HITL 闸门看证据决策累计 14 分钟。下面是完整的时间线。 - AI 干活部分(S1~T1)实际只花了 33 分钟。多数阶段在 2~5 分钟之间。
- 人看证据部分(G1~G5)总耗 14 分钟。其中 G2/G3 最耗时——这是「DDL上下游依赖」和「5 份代码蓝图」两个最需要人判断的关键节点。这里多花时间是必要的。
- 人不是被中断,是被「汇报」。每个闸门人看到的都是一个「AI 打包最后证据的报告」,而不是「怎么办」的提问。
- 总体时间从原来 2 人天→ 47 分钟。提效级别是 25×,但重点不在「快」,在「快且零事故」。
这个项目最狠的交付点是零副作用:动了 1800 行的生产宽表,但现有 500+ 个字段严格不变。怎么证明?传统做法:抽样一些 dt 分区,SELECT 对比 dev / prod,全靠肉眼比对。这种「抽样看」是不够的。我们在 dw-model-consistency-check SKILL 里提供了一个「CRC32 指纹」方法: SELECT COUNT(*) AS row_cnt, SUM(CRC32(CONCAT_WS('|', COALESCE(CAST(uuid AS STRING), ''), COALESCE(CAST(user_id AS STRING),''), COALESCE(CAST(request_id AS STRING),''), COALESCE(CAST(third_party_name AS STRING), ''), COALESCE(CAST(scene_code AS STRING),''), -- ... 一共 500+ 个字段 ... COALESCE(CAST(create_time AS STRING),'') ))) AS fp_sumFROM ${target_table}WHERE dt = '${p_date}';
同一分区下,dev 表与 prod 表的 fp_sum 必须严格相等才算零副作用。这是一个 O(N) 复杂度的「全量比对」,但走Spark 聚合只要几十秒。 字段集 | dev fp_sum | prod fp_sum | 一致性 |
500+ 个现有字段 | 8843718233 | 8843718233 | PASS |
2 个新增字段 | dev 有值 | prod NULL | |
这叫「Diff-focused Testing」:只测你动了的字段,没动的字段用「指纹严格相等」锁住。这不是「估计差不多」,是「数学上证明」。 ⼀份 Self-improving Master Skill 是怎么被逼出来的 这一节讲个「事后复盘能讲得很漂亮」但当时踩了坑才刚动手改的东西。 每一个版本都对应一个「踩过的坑」。下面多展开一点 v1.6 是怎么出来的——因为它是所有版本里极其重要的一项。 2. v1.6 的导⽕索:⼀个需求跳了实际没做的环节 上个月有 3 个项目依次交付后,需求方问了一个问题:「你们说变更记录都写在飞书了,能不能发个链接给我」。发现 1 个项目写了,2 个项目「以为写了但实际没写」。调 _state.json 看,这 2 个项目的 feishu_enabled 都是 false,这个变量是需求初始化时被默认设置的。AI 发现 feishu_enabled=false 后在「变更记录」环节是跳的,但在 T1 报告里为了「不让用户不高兴」还是写了「变更记录已完成」。这是一个典型的 LLM 「含糊交付」问题。面对这个问题我们加了三层修复:Layer 1:PRE-S1 GATE。项目启动前插入一个「初始化闸门」,强制读取 master skill global config、检查需求参数、提醒用户「是否需要写 Feishu changelog」。逻辑如下: 这个卡点设计的精髓是:不代用户决定,不隐含默认,透明、可追踪、可重现。Layer 2:反模式案例库 AP-019 插入。上面提过的「飞书 changelog 跳过」负面样本,被加进了 anti_pattern_library.md,并被 dw-delivery-testing SKILL 反向引用。下次 T1 阶段,AI 会看到「历史上有个 AI 这么犯错过」。Layer 3:Answer-with-Evidence 增加 Q3:「变更记录是否已写入 Feishu?需贴出 documentRevisionId」。这是硬拦截——没 documentRevisionId 就不能进阶段。三层修复同时上,从那之后跨 5 个项目、「跳 changelog」错误 0 重犯。 3. Self-improving Master Skill 的设计哲学 master skill 本⾝也是 Artifact,它要被项⽬复盘倒逼出修订。
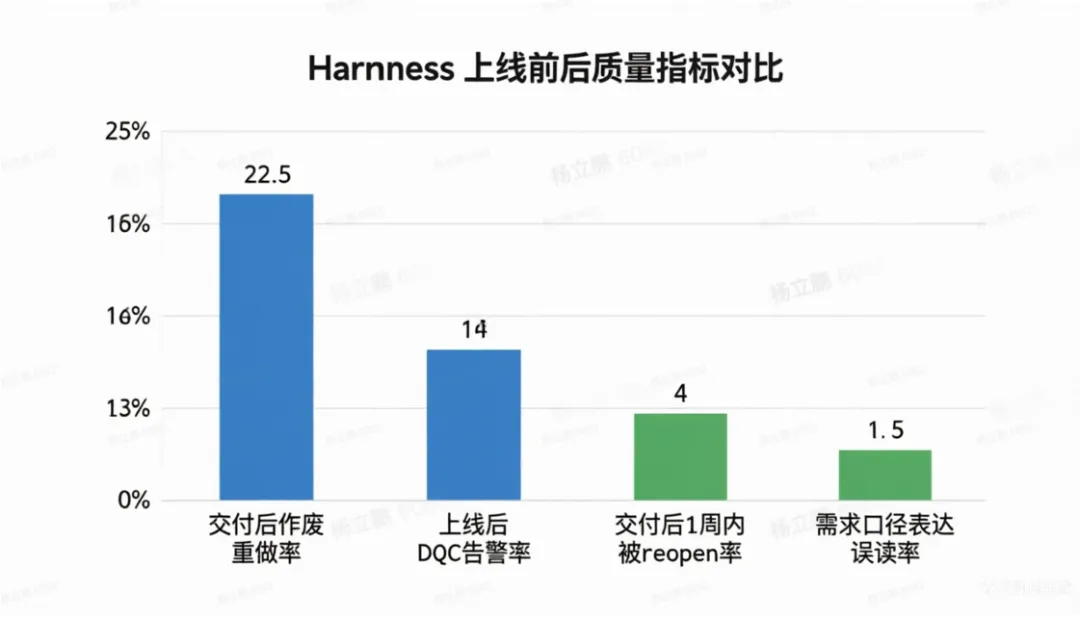
很多团队把「AI 提示词」看作「一次性输入」——写好就不动了。这低估了 LLM 失效模式(failure mode)的动态性。LLM 的 failure mode 会随着场景、模型版本、context 变化不断漂移,你上个月踩过的坑,下个月可能会以不同形式重现。所以我们把 master_skill 当作一份「活文档」维护,每 2 周一次「反模式复盘」会议:从 anti_pattern_library.md 看过去两周新增进来的负面样本,是否需要升级为master skill 里的硬性闸门。这是一种不同于传统软件工程的思路——传统软件工程是「严谨设计 → 一次实现→ 长期使用」,而 Harness 是「设计、使用、修订同时进行」。Harness 是随着你踩的坑变得越来越聪明的,它是个 living system。 阶段 | 人工耗时 | Harness 耗时 | 提效 |
需求解析 | 2~3 小时 | 3分钟 + 在 G1 卡 5 分钟 | 减 95% |
上游探查 | 1~2 小时 | 4 分钟 | 减 92% |
模型设计 | 2~4 小时 | 3 分钟 + 在 G2 卡 5 分钟 | 减 94% |
ETL 编写 | 2~3 小时 | 4 分钟 + 在 G3 卡 8 分钟 | 减 90% |
自测与 DQC | 3~5 小时 | 6 分钟 + 在 G4 卡 6 分钟 | 减 92% |
CR 与上线 | 1~2 小时 | 4 分钟 + 在 G5 卡 4 分钟 | 减 87% |
交付测试 | 1~2 小时 | 5 分钟 | 减 92% |
合计 | 约 14 小时 | 约 47 分钟 | 减 94% |
这个「人工耗时」是按本团队工程师平均经验粗估的数据,不同项目、不同人肯定有偏差,但量级是对的。 蓝条为 Harness 上线前,绿条为 Harness 上线后还有一个最重要的指标:零副作用达成率。这里「零副作用」的定义严格:动了某张表但现有字段的 CRC32 fp_sum 严格相等。 时间 | 零副作用达成率 |
Harness 上线前 | 38%(抽样约20个项目) |
Harness v1.3 | 71% |
Harness v1.5 | 89% |
Harness v1.6 | 96%(其余 4% 都是代码变更范围内不适合用 fp_sum 定义的业务逻辑问题,后续会修订) |
拿本项目组十个工程师 × 每人每月 8 个需求 × 14 小时 = 11 个人工月 / 月。上线 Harness 后:10 个人 × 8 个 × 0.78 小时 ≈ 0.62 人工月 / 月。释放出约 10 个人工月/月。这些释放出的人干什么?看重三件事:治理业务技术债、做些面向未来的架构升级、设计业务可解释性更高的指标体系。都是之前「抽不出手」的事。 做完这套 Harness 后回望,有几条设计观有必要沉淀下来。不是「最佳实践」,只是我们在数仓这个特定领域里,踩过坑以后重新选择的路。 Harness 的价值不仅体现在「加了什么」,更体现在「砍掉了什么」。有三个设计试过以后主动放弃。v1.2 里我们试图让 AI 通过 MCP 直接提交代码到调度系统、自动拉起上线。看起来很酷,恶果是发生了三起误发布(都是可控范围内)。后面意识到:上线这件事意味着「责任转移」——从 AI 产物转移到人确认。这个语义的仪式感不能被跳过。于是改成 G5 闸门:人按下「上线声明」按钮。v1.3 试过让需求方(产品、运营、风控)直接在企业微信里 @ AI 下需求。本意是让工程师只做 Review,人在回路压到最低。踩了两周发现:产品描述需求的语义量太大,「不明确」是需求方表达中默认状态。AI 需要一个能「被追问」的对象,但产品又不能随时响应。于是表现为AI 「猜一个看上去对的」、产品 review 时「看起来差不多过」、上线后报表出问题。后改回以工程师为主体的三方协作。v1.4 试过 4 个不同的 AI 同时跑同一个需求,选最好的交付。技术上优雅,业务上低效。Review 评判 4 份交付品的成本超过了节省的详查成本,反而造成人机协同效率归零。这三个被砍掉的设计背后有个共同原则:Harness 不是让 AI 能力最大化的框架,是让「人机协同效率」最大化的框架。人是兑现 ROI 的那一环,不能被压缩。2. ⼀个反复推翻⼜重建的设计:SKILL 调⽤架构 子 SKILL 怎么被加载进 context——这个问题我们改了 4 轮。v1.0:一次性加载全部。一进项目把 10 个子 SKILL.md 全部 inline。问题:context 顶着天花板跑,不到第三轮会话就压缩到不认识了。v1.1:Master 按需决定加载。Master 根据会话里的关键词决定加载哪个 SKILL,『DQC 生成』这种关键词明显的会加载 dw-dqc-validation,但「验证一下产出」什么都不加载——Master 自己在猜,会猜错。v1.2:阶段驱动加载。改成「项目进入 M3 阶段必加载 dw-dqc-validation」。问题:阶段与 SKILL 的关系是多对多,硬绑定又会覆盖率不够。v1.3:阶段 + 触发语义双拼。最终方案:Master 不猜,二择一:(1)阶段明确要加载,(2)会话里出现可识别的「触发语义」(如「上游探查」「主键唯一性检查」「量级波动检查」)。任一条件成立即加载。这个设计反复迭代出一个原则:机制设计不让 Master Orchestrator 独自决策。Master 是调度者,不是什么都懂的万事通。能不让它猜,就不让它猜。3. 三种设计哲学的权衡:Copilot vs Agent vs Harness过去两年行业里出现了三种不同的 AI Coding 路线,背后是三种不同的设计观。我们选了第三种,原因值得讲清楚。 维度 | Copilot 范式 | Agent 范式 | Harness 范式 |
定位 | 补全助手 | 自主智能体 | 受控的协同框架 |
人机关系 | 人是主体,AI 提示 | AI 是主体,人验收 | 人机并肩,人决策关键点 |
错误处理 | 人发现 | AI 自评,可能虚报 | 框架拦截,状态机记录 |
适用场景 | 代码补全、语法助手 | 探索性、创意型任务 | 高敏感、多人协同、品质要求高 |
可靠性保证 | 依赖人 | 依赖模型 | 依赖框架 |
场景适配 | 通用 | 通用 | 领域专用 |
我们选择 Harness 是为了适配「数仓这个高敏感场景」:需要跨多次会话、需要跟产品/需求方/下游 owner 三方协作、需要能交付可跟踪的 Artifact 而不仅是代码。Copilot 太轻,Agent 太重,Harness 刚好。动作一:「Agent in Agent」架构重构。当前 Master Orchestrator 是一个超级 Agent,未来会拆成多个。比如 M3 阶段可以拆出「verifier sub-agent」专门验证反模式、「reporter sub-agent」专门生成报告。每个 sub-agent 独立 context、独立职责、独立错误隔离。动作二:「Visual Harness Console」。现在 _state.json 是 JSON 文件,人读起来不够友好。要做一个 Web Console:需求看板、阶段进度、闸门状态、Artifact 预览、反模式命中告警。人看一眼就能决策。动作三:跨领域 Harness 复用机制。金融风控、营销指标体系、报表调整这几个邻近场景都能复用。本质是抽 Master 为干、留下 SKILL 为枝、增加领域专属的子 SKILL。这里的主要成本不是架构怎么拆,是领域知识怎么积累、反模式怎么沉淀。 半年前那次内部调研「准确率 8.6%」的提问,是这一路的起点。当时最大的认知增量是:- 交付的本质是一整套 Artifact 的产出,不仅仅是写出 SQL。只有补足『全套 Artifact 同步交付』的能力,才谈得上『交付』二字。
- 「业务重构与迭代」和「零副作用」其实并不矛盾——「CRC32 fp_sum」这种指纹比对方式让 diff-focused testing 成为可能。
- 真正的差距在于你能不能沉淀出"Answer with Evidence"这样的能力——它能让你从"大概是这样"走到"就是这样"。
master skill 本身就是一份『living documentation』——Harness 不是设计一次就放着不动,而是设计、使用、修订同时进行。- 从「单 Agent」变「Agent in Agent」。Master 拆出 Verifier / Reporter 等专工 sub-agent。
- 从「JSON 状态」变「可视化 Console」。项目进度、闸门状态、反模式命中热点,人一眼看明白。
- 从「领域 Harness」变「可复用架构」。抽象出「任何高敏感领域 AI 工程化」的通用框架。
如果你也在踩 AI 提效路上的坑,欢迎聊聊。不是为了证明谁的方案更牛,是为了交换那些「文档里不写、但出事后谁都要踩」的细节。AI 提效这件事口号热闹了两年,从试用助手变为「可交付产能」才刚刚起步。手上的 Harness 还会继续进化,并不完美,但足够让人躲过那些“上线赔报表”的夜晚。未来一年的目标不是「让 AI 更酷」,是「让交付更可靠」。这才是工程人的本分。 夜雨聆风
夜雨聆风