 夜雨聆风
夜雨聆风这是源码分析的第二个议题,Agent系统如何搭建,也是长时间在LatticeMind平台建设上的一些个人感悟。
写代码这件事本身从来不是难点,难的是把想法照进现实。就像《走向共和》里李鸿章建北洋水师——旁人只看见船坚炮利,唯有当局者知道:买船容易,成军难。搭建Agent系统亦如是。写几轮Prompt、调几个工具调用,那是"买船";真正难的,是定下调度章法、理清协作边界、筑牢容错机制——那才是"成军"。
当年晚清寄望铁甲舰重振海防,今日我们探索大模型赋能智能,二者的心境何其相似。张之洞百年前提出"中学为体,西学为用",放到今天看,正是"领域知识为体,模型能力为用"。
对"系统"二字的敬畏,远胜千行代码。
很多人第一次看多 Agent 项目,注意力会先落在“角色”上。
比如 MetaGPT 里有产品经理、架构师、工程师、数据分析师、 TeamLeader 。乍一看,它像是在把一个软件团队搬进代码里:有人写需求,有人做设计,有人写代码,有人负责调度。
但我读源码之后,最大的感受不是“角色拆得真细”,而是另一件事:
Agent 系统真正难的,不是起几个角色名,而是让这些角色能持续、稳定、有反馈地把任务往前推进。
一个 Agent 系统要跑起来,至少要解决五个问题:
第一,单个 Agent 怎么循环。
第二,复杂任务怎么拆解和记录状态。
第三,模型怎么可靠地调用工具。
第四,多个 Agent 之间怎么交接信息。
第五,谁来判断任务完成、失败、重试或者转派。
MetaGPT 的源码价值,不在于它给了一个唯一正确的答案,而在于它把这些工程问题都摆到了台面上。
这篇文章不做逐行源码解析,只借 MetaGPT 这个案例,聊聊 Agent 系统建设里真正值得关注的几个思路。
1. 先别急着加角色,先想清楚单个 Agent 怎么跑
一个 Agent 不是“给模型一段 prompt ,然后等它回答”。
如果它要完成一个真实任务,就必须有一个基本循环:
接收信息,理解当前状态,决定下一步动作,执行动作,再把结果写回上下文。
这个循环听起来简单,但它决定了 Agent 能不能持续工作。
如果没有这个循环, Agent 就只是一次性问答。它可以回答“怎么做”,但很难真的“做下去”。
比如一个工程任务里, Agent 可能要先读文件,再定位问题,再修改代码,再跑测试。如果测试失败,它还要看错误日志,重新判断下一步。
这里的关键不是模型多聪明,而是系统有没有给它一个继续推进的结构。
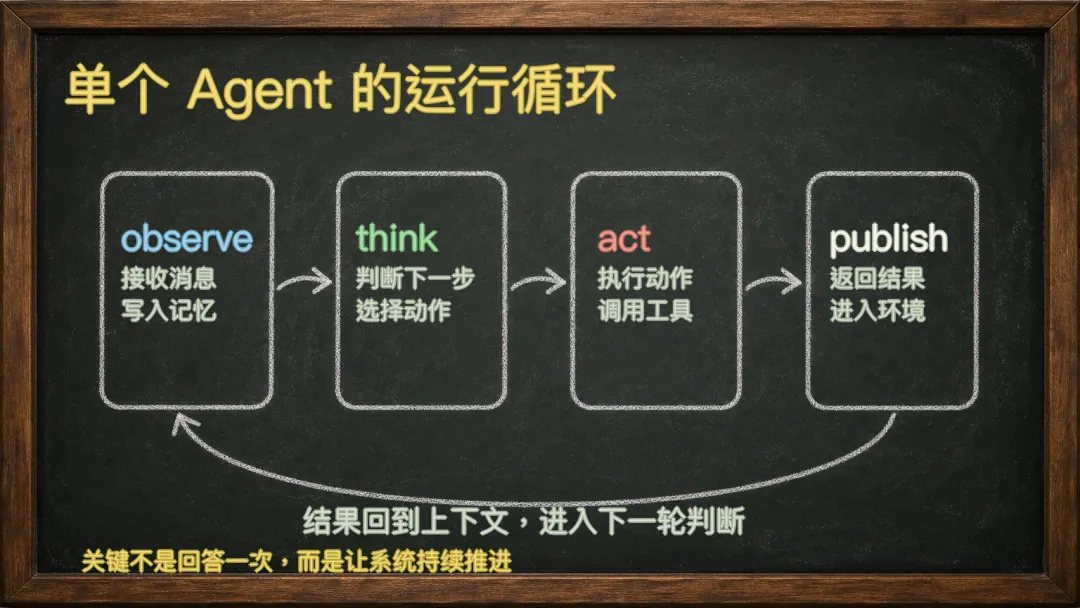
MetaGPT 里的角色运行机制,本质上就是在回答这个问题:
一个角色收到消息之后,如何观察上下文,如何决定下一步,如何执行动作,如何把结果发出去。
这给 Agent 系统设计提供了一个很直接的判断标准:不要一开始就堆角色。
先把单个 Agent 的循环做扎实。
它能不能看到新消息?
它能不能记住刚刚做过什么?
它能不能根据工具反馈调整下一步?
它什么时候应该继续,什么时候应该停?
这些问题没想清楚,加再多角色也只是多个模型在同时说话。
2. 复杂任务不能只靠上下文,要有任务状态
很多 Agent 系统一开始会把所有东西都塞进上下文:用户需求、历史对话、工具返回、执行结果、下一步计划。
短任务还能凑合,复杂任务很快就会乱。
原因很简单:上下文不是任务管理系统。
一个真实任务通常有目标、步骤、依赖关系、当前进度、执行结果和是否完成。只靠自然语言聊天记录,模型很容易忘记已经完成了什么,也容易重复执行同一件事。
MetaGPT 里一个很重要的设计点是:任务状态应该被结构化保存。
比如一个数据分析任务,可以拆成加载数据、清洗数据、分析数据、建模、可视化。每一步都有自己的输入、输出和完成状态。
在 MetaGPT 的源码里,这部分可以理解成两层结构:一层是整体计划,一层是计划里的单个任务。
整体计划保存的是“这个任务系统现在走到哪里了”:
单个任务保存的是“这一小步具体要做什么”:
有了这套结构,系统就能知道任务目标、任务列表、当前进度、依赖关系和执行结果。 Planner 要做的,就是生成或修改计划、找到当前任务、处理执行结果,并在任务完成后推进到下一步。
这样系统就不只是“看起来有计划”,而是真的知道:
现在做到哪一步。
前一步的结果是什么。
下一步依赖哪些任务。
当前任务是否已经完成。
如果没有任务状态, Agent 很容易出现几种典型问题:
重复做已经完成的事。
跳过关键步骤。
遇到错误后不知道回到哪里。
多个角色交接时说不清当前进度。
所以做 Agent 系统,计划不是写在 prompt 里的装饰品,而应该是系统里真实存在的状态。
这也是我从 MetaGPT 源码里看到的一个重要思路:
任务拆解和任务推进,应该从“模型随口说的计划”,变成“系统可维护的状态机”。
3. 工具调用不是一句“让模型用工具”就够了
Agent 要真正执行任务,离不开工具。
读文件、写文件、查资料、跑命令、执行代码、调用浏览器、生成图表,这些都不是模型自己完成的,而是系统工具完成的。
模型负责判断该用什么工具,系统负责真的执行工具。
中间必须有一层清晰的协议。
MetaGPT 里的一个典型做法是:让模型输出结构化命令,再由系统解析命令,映射到真实工具函数,执行后把结果写回上下文。
这件事背后的重点不是 JSON 本身,而是“协议边界”。
比如当 Agent 需要读一个文件、再跑一条测试命令时,模型输出的不是自然语言里的“我去读文件”,而是一组结构化命令:
这段命令里真正重要的是两个字段:
系统拿到这段 JSON 后,不是直接相信模型“已经执行了”,而是会解析命令,再通过类似 tool_execution_map 的映射表找到真实函数。
可以把它理解成这样:
所以完整链路不是“模型说了算”,而是:模型选择命令,系统校验和执行命令,执行结果再写回上下文,供下一轮判断使用。
一个可靠的工具调用链路至少要回答:
模型能看到哪些工具?
每个工具需要哪些参数?
模型输出的命令格式不对怎么办?
工具执行失败怎么办?
执行结果怎么反馈给下一轮判断?
如果没有这些约束,所谓工具调用就会变成一种很脆弱的文本约定。
模型可能写错工具名,参数可能不完整,执行结果可能没有被保存,下一轮模型也不知道刚才到底发生了什么。
所以 Agent 系统里的工具调用,不能只停留在“给模型一份工具列表”。
更关键的是让工具调用形成闭环:
模型选择工具,系统执行工具,结果进入上下文,模型基于结果继续判断。
这个闭环一旦稳定, Agent 才有可能处理开放任务。
比如修 bug ,不是一次工具调用能解决的。
它往往是读代码、定位问题、修改文件、跑测试、看错误、再修改。每一步都依赖上一步的反馈。
这类任务真正需要的,就是工具反馈驱动的循环。
4. 多 Agent 协作的核心不是“分角色”,而是“交接”
多 Agent 系统最容易被误解。
很多人会以为,多 Agent 就是多设几个角色:产品经理、架构师、工程师、测试、运营。
但角色只是表层。
真正难的是交接。
一个角色做完事情,结果怎么交给下一个角色?
下一个角色如何知道自己要基于什么继续?
调度者如何判断上一个角色已经完成?
如果成员失败了,是重试、换人,还是回到用户那里确认需求?
MetaGPT 的多角色协作里,有一个很重要的设计点:不同角色之间不是共享一个脑子,而是通过消息传递产物和状态。
这更接近真实团队。
产品经理写完 PRD ,不是把自己的记忆共享给架构师,而是交付一份文档。
架构师基于这份文档做设计,再把设计交给工程师。
工程师根据需求和设计写代码,最后再汇报结果。
这里的关键不是“谁叫什么角色”,而是每一次交接有没有带上足够的信息。
一个比较可靠的交接消息,至少应该包含这些信息:
比如一个成员完成 PRD 后,发回来的不应该只是“我完成了”,而应该更像这样:
这类消息看起来很普通,但它决定了下游角色能不能接得住。
如果这些信息不清楚,多 Agent 只会放大混乱。
一个角色理解一半,另一个角色再补一半,最后系统看起来很热闹,但没有稳定产出。
所以设计多 Agent 系统时,我会先问一个问题:
这个任务真的需要多个角色吗?
如果只是读文件、改代码、跑测试,一个工程型 Agent 可能就够了。
如果任务天然需要不同专业交付物,比如需求文档、系统设计、代码实现、数据分析,那多 Agent 才有意义。
多 Agent 不是为了显得高级,而是为了让不同交付物有清晰边界。
5. 调度者不是“老板”,而是系统里的状态维护者
在多 Agent 系统里,调度者很关键。
但调度者不应该只是一个“看起来像老板”的角色。
它真正要做的是维护全局状态。
谁在做什么?
当前任务做到哪一步?
哪个成员已经完成?
下一步该交给谁?
成员返回的信息是否足够?
任务是否需要重试、重置、替换,还是应该结束?
MetaGPT 里的 TeamLeader 展示了另一种思路:调度者本身也应该是一个可运行的 Agent 。
它不是只在一开始分配任务,而是持续读取成员反馈,更新团队计划,然后决定下一步。
这点非常重要。
很多Agent demo 只做到了“分发任务”,没有做到“持续调度”。
它们能把任务派出去,但不知道成员完成得怎么样;能启动多个角色,但不知道什么时候应该推进;能生成很多文本,但缺少一个判断任务状态的中心。
真正的调度者至少要有三个能力:
第一,能维护团队级计划。
第二,能理解成员反馈。
第三,能决定下一步动作。
在 MetaGPT 的思路里,调度者推进任务也不是一句自然语言“继续下一步”。
它更接近输出一组调度命令:先标记当前任务完成,再把下一步任务发给对应成员。
这段 command 背后的含义可以拆成两步:
所以调度者真正维护的是“团队级状态”:谁完成了什么,下一步依赖什么,信息应该交给谁。
这也是多 Agent 系统和普通工作流编排的差别。
普通工作流更像固定流水线,适合稳定任务。
Agent 调度更适合开放任务,因为它需要根据反馈不断调整路径。
6. 固定流程和动态 Agent 要分开
读 MetaGPT 源码时,还有一个很现实的点:并不是所有流程都应该交给动态 Agent 。
有些流程是稳定的。
比如 OCR 后抽字段,再生成表格;或者按固定模板生成报告。这类任务步骤明确、输入输出明确,固定流水线反而更可靠。
有些任务则是不确定的。
比如读一个陌生代码库、修一个没有明确原因的 bug 、分析一份未知数据、根据执行结果不断调整方案。这类任务很难提前写死路径,更适合动态 Agent 。
所以 Agent 系统设计里,一个重要原则是:
稳定流程固定化,不确定流程 Agent 化。
可以简单按这个表判断:
能用普通程序解决的,就不要强行让模型参与。
只有当路径依赖观察结果、工具反馈和中间判断时, Agent 才真正有价值。
这也是很多 Agent 项目容易走偏的地方。
它们把所有步骤都交给模型,结果系统变得不可控、成本更高、错误更多。
更好的方式是把系统拆成两层:
底层是确定性的工具和流程。
上层是负责判断、选择和调度的 Agent 。
模型不应该替代所有程序逻辑,而应该站在适合它的位置上。
7. 从 MetaGPT 回到 Agent 系统建设
读 MetaGPT,别只抄角色表。
真正值得借鉴的,是它背后的工程化设计:
单个 Agent 要有运行闭环,不是单次调用,是感知-思考-行动-反馈的完整循环。
全局要有状态管理,任务进度、上下文、依赖关系必须可追踪,否则 Agent 一定会迷路。
工具调用要有标准化协议,参数校验、异常处理、结果回传必须规范,不然就是失控。
多 Agent 要有消息交接机制,上下文怎么传、信息怎么交,没有标准就是鸡同鸭讲。
要有全局调度者,判断完成、失败、重试、转派,不然就是一次性分发,听天由命。
要划清流程边界,哪些固定、哪些灵活,边界不清就是简单问题复杂化。
角色名字都是皮,这六条才是骨。
骨架搭对了,叫什么角色都能用。骨架不对,抄再多角色表,也只是个看起来像那么回事的聊天机器人,不是能交付结果的 Agent 系统。
这才是 MetaGPT 源码里真正的核心价值。
