 夜雨聆风
夜雨聆风AI搜索系统哪家强?六大搜索后端在事实性问答与文档相关性上的硬核对比Head-to-Head Benchmark: Six Search Backends on Factual QA and Document Relevance
当学术界需要数据而非口号来评估AI搜索能力时,一套开源、可复现的基准测试框架变得至关重要
2026年的AI应用开发领域,搜索能力已经从"锦上添花"演变为"基础设施"级别的刚性需求。然而,面对市场上十余种搜索API——从传统搜索引擎的API封装到AI原生搜索服务——开发者和研究者面临一个核心问题:如何客观、量化地比较它们的真实能力?
营销文案中的"最高准确率"、"最快速度"常常缺乏方法论支撑。两个系统在不同测试集上的表现可能截然相反,而商业白皮书中精心挑选的数据点往往无法反映全貌。
正是在这一背景下,Tavily开源的评估框架 tavily-search-evals 提供了一个值得关注的范式——不是单方面宣称自身优越,而是建立一个标准化的、可扩展的、透明的对比平台,让任何搜索提供商都能在同一个赛场上接受检验。
核心发现(基于开源评测数据) 在OpenAI SimpleQA事实问答基准上,Tavily以 93.3% 的准确率排名第一,领先第二名 Perplexity Search 7.38个百分点。 在动态文档相关性评估中,Tavily以 83.02% 的准确率排名第一,领先第二名 Perplexity Search 11.82个百分点。 六个参评系统在两个维度上的排名高度一致:Tavily > Perplexity Search > Google SERP > Brave Search > Exa Search。
一、为什么需要标准化的AI搜索评估框架
在深入数据之前,有必要先理解这套评估框架本身的设计哲学。一个可信的基准测试不是"跑几次选出最好的",而是需要满足一系列科学严谨性要求。
1.1 当前评估实践的痛点
AI搜索领域的评估长期以来处于相对混乱的状态。不同厂商使用不同的测试集、不同的评分方法、甚至不同的"准确率"定义。这种不可比性导致学术界和工业界难以形成共识。
具体而言,现有评估实践存在以下结构性问题:
- 测试集私有化
:许多评估基于厂商内部持有的数据集,其他方无法复现或验证 - 指标定义不统一
:"准确率"在不同场景下可能指精确匹配、语义相似度或人工评分,缺乏标准化 - 评估模型不一致
:使用不同的大模型作为评判者(judge model)会引入显著的评估偏差 - 超参数选择不透明
:每个系统是否被调至最优配置?搜索深度、结果数量等参数是否统一? - 样本量不足
:基于数十个样本得出的结论缺乏统计学意义
1.2 Tavily评估框架的方法论设计
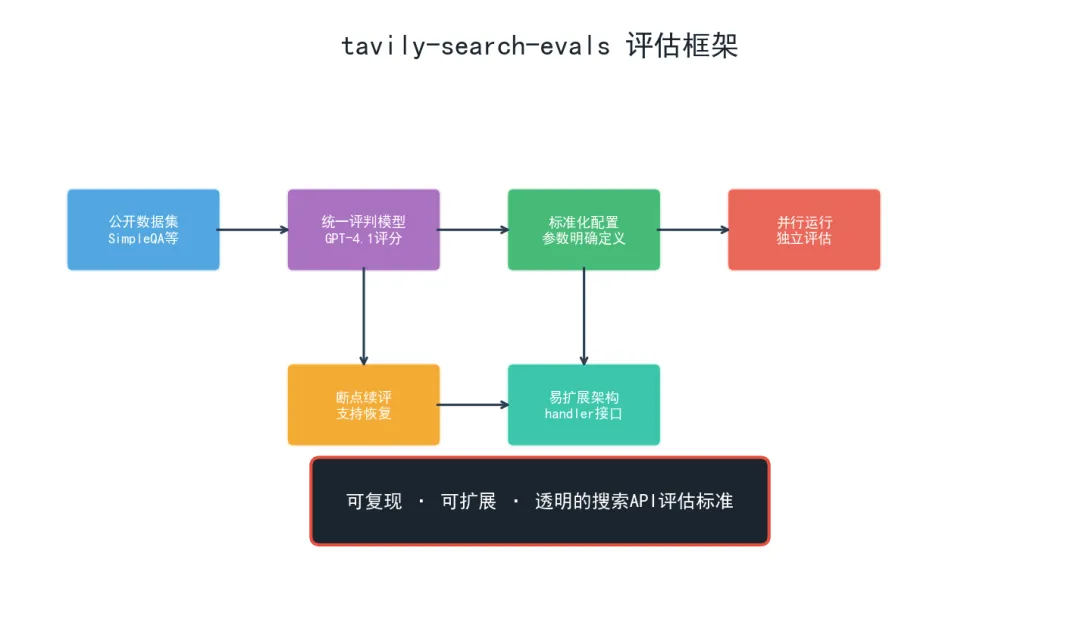
tavily-search-evals 仓库的设计意图非常明确:建立一个去中心化的、可复现的、可扩展的搜索API评估标准。其核心方法论特征包括:
框架设计原则: 1. 公开数据集:使用OpenAI SimpleQA等公开基准,确保任何人都可以独立复现 2. 统一评判模型:所有系统使用同一套GPT-4.1进行后处理和评分,消除评判者偏差 3. 标准化配置:每个提供商的搜索参数(深度、结果数等)在配置文件中明确定义 4. 并行运行:各系统独立并行评估,避免运行时状态相互干扰 5. 断点续评:支持从上次中断处恢复,便于大规模评测 6. 易扩展架构:新增搜索提供商只需实现handler接口,无需修改核心评估逻辑
这一方法论设计值得学术研究社区关注。它提供了一个可以借鉴的模板,用于在其他AI能力维度(如代码生成、多模态理解、长文本处理)建立类似的横向对比框架。
二、SimpleQA基准测试:事实性问答能力的横向对比
SimpleQA是OpenAI发布的事实问答数据集,由一系列具有确定性答案的短事实查询组成。它不考验模型的推理能力,而是纯粹测试系统从网络中检索准确事实并合成正确答案的能力——这正是搜索API的核心职责所在。
2.1 测试流程设计
为了确保评估的公平性和可复现性,tavily-search-evals采用了严格的测试流程:
- 数据集
:使用OpenAI SimpleQA完整问题集,覆盖历史、科学、地理、文化等多个知识领域 - 检索阶段
:每个搜索提供商对每个问题执行搜索,限制最多返回10篇文档 - 标准化处理
:各提供商返回的文档被重新格式化为统一结构 - 答案提取
:使用GPT-4.1基于检索到的文档提取预测答案 - 自动评分
:使用官方SimpleQA分类器对预测答案进行正确性判断 - 公平性保障
:各提供商的文档长度被标准化,确保没有因上下文窗口差异导致的不公平
2.2 六大搜索提供商性能排名
以下是SimpleQA基准上的完整评测结果。数据来源于tavily-ai/tavily-search-evals仓库的公开评测报告:
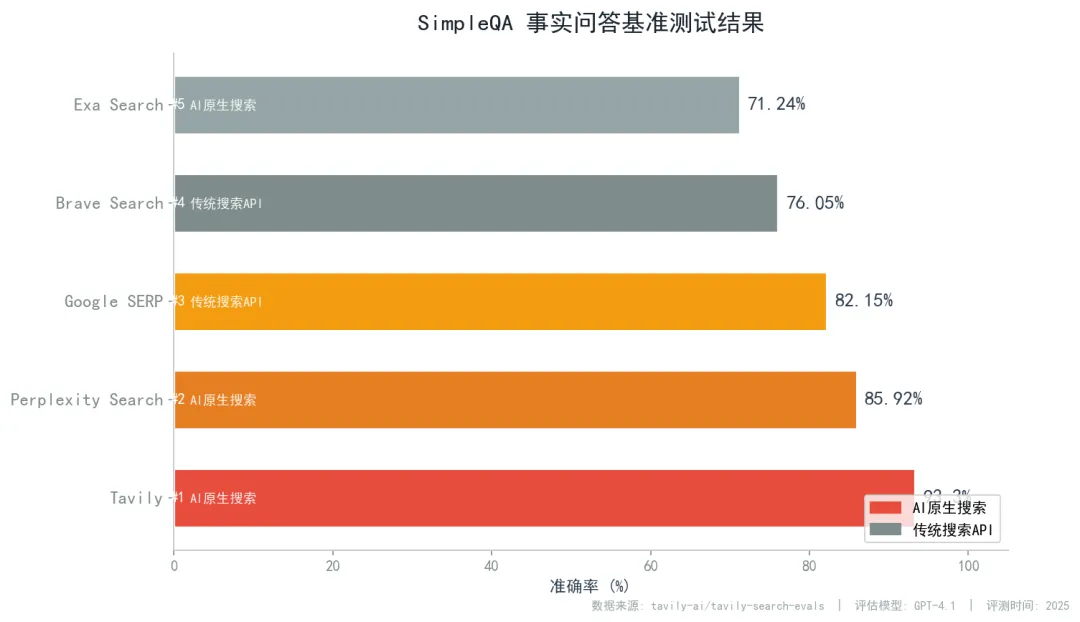
SimpleQA 事实问答准确率排名
Tavily
93.3%
Perplexity Search
85.92%
Google SERP (Serper)
82.15%
Brave Search
76.05%
Exa Search
71.24%
数据来源:tavily-ai/tavily-search-evals | 评估模型:GPT-4.1 | 评测时间:2025年
2.3 数据解读与差距分析
上述数据揭示了几个值得关注的现象:
现象一:AI原生搜索显著优于传统搜索引擎API。 Tavily(93.3%)和Perplexity Search(85.92%)均显著高于Google SERP(82.15%)和Brave Search(76.05%)。这一差距表明,将搜索结果从"人类可读的网页列表"重构为"机器可消费的结构化信息"并非锦上添花,而是直接影响最终答案质量的关键设计决策。
现象二:头部差距接近8个百分点,但尾部差距超过20个百分点。 Tavily与Exa之间的差距(22.06个百分点)远大于Tavily与Perplexity之间的差距(7.38个百分点)。这意味着在事实性问答这一特定维度上,市场存在明显的"第一梯队"和"第二梯队"分化。
现象三:传统搜索引擎API的表现令人意外。 Google作为搜索领域四十年的领导者,其SERP API在SimpleQA上的表现(82.15%)仅排在第三位,落后于两个AI原生搜索服务。这印证了本文开头提出的核心论点:为人类设计的搜索输出格式,并不是为AI消费而优化的。
三、文档相关性基准:搜索结果质量的深度评测
SimpleQA衡量的是"最终答案是否正确",而文档相关性基准衡量的是"返回的文档是否与查询真正相关"。两者是互补的:前者是端到端系统能力,后者是检索模块本身的质量。
3.1 评估方法
文档相关性评估采用动态数据集生成机制,而非静态题库:
- 数据集生成
:使用开源工具 tavily-web-eval-generator 动态生成测试集 - 评估工具
:QuotientAI提供的专业相关性评估平台 - 预置测试集
:datasets/document_relevance_dynamic_test_set.json - 核心优势
:支持领域特定或实时主题评估,比静态数据集更能反映生产环境
动态数据集的引入是一个重要的方法论创新。传统的静态基准测试面临"数据污染"风险——如果测试集在训练或调优过程中被模型"见过",评估结果将失去意义。动态生成机制通过持续更新测试内容来缓解这一问题。
3.2 文档相关性评测结果
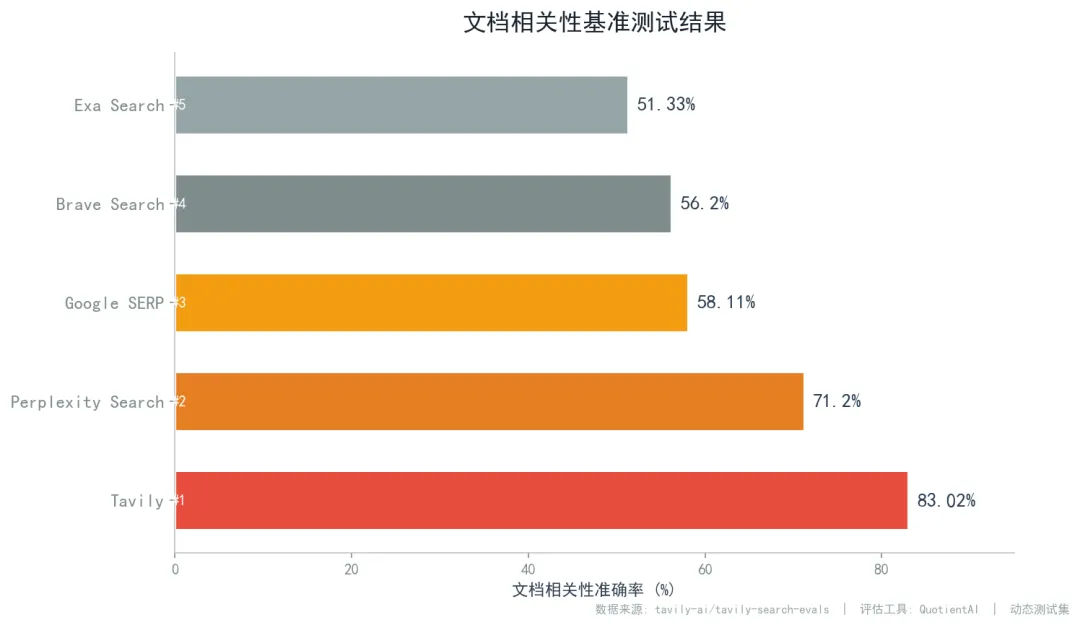
文档相关性准确率排名
Tavily
83.02%
Perplexity Search
71.2%
Google SERP (Serper)
58.11%
Brave Search
56.2%
Exa Search
51.33%
数据来源:tavily-ai/tavily-search-evals | 评估工具:QuotientAI | 动态测试集
3.3 两个维度的对比分析
将SimpleQA和文档相关性的结果并列观察,可以发现一些有趣的模式:
关键发现:排名的高度一致性。 两个独立的评估维度——事实问答准确率和文档相关性——产生了几乎完全一致的排名。这一发现具有重要统计学意义:它表明各搜索系统的能力差异是系统性的而非维度特定的,即一个系统在检索层面的弱点会同时影响其问答能力和相关性表现。
另一个观察:Google SERP在文档相关性上的跌落。 在SimpleQA上,Google SERP(82.15%)与Perplexity Search(85.92%)的差距仅为3.77个百分点。但在文档相关性上,这一差距扩大到了13.09个百分点。这说明Google的强项在于"最终的答案合成"(得益于其强大的搜索后处理管线),但在"原始文档的相关性匹配"上并不占优。
四、系统层面的能力差异分析
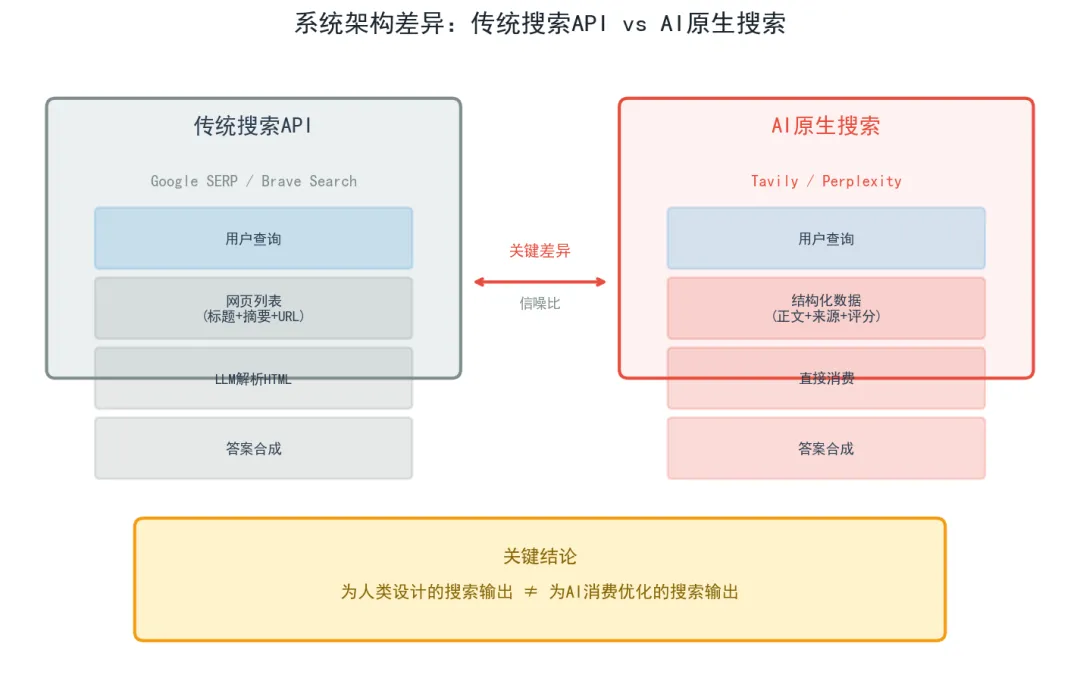
数据告诉我们"谁更强",但没有告诉我们"为什么"。本节尝试从系统设计的角度解释这些性能差异的来源。
4.1 AI原生搜索 vs 传统搜索API
数据中最显著的分化发生在AI原生搜索(Tavily、Perplexity)与传统搜索API(Google SERP、Brave)之间。这一分化的技术根源在于结果表征的根本不同:
传统搜索API返回网页列表(标题+摘要+URL),优化人类阅读体验。LLM需要额外消耗Token解析HTML结构、提取正文、过滤噪声。
AI原生搜索返回预处理的结构化数据(清洗后的正文、来源、时间戳、相关度评分),LLM可直接消费。信息密度高,噪声低。
在SimpleQA测试中,这一差异直接影响了GPT-4.1从检索文档中提取正确答案的能力。当输入文档信噪比更高时,提取准确率自然更高。
4.2 Tavily 的差异化设计
为什么Tavily能在两个维度上均领先?其技术优势可能来自以下几个设计决策:
- 专有的实时索引系统
:Tavily维护独立于主流搜索引擎的索引,针对AI消费场景优化了内容发现和入库速度 - 面向AI的后处理管线
:HTML净化、实体识别、摘要生成、引用标注等多阶段处理,输出可直接被LLM消费 - Advanced模式的多源交叉验证
:对同一事实在多个来源间进行交叉验证,不一致的结果被标记 - 智能缓存与查询理解
:针对高频查询的缓存命中和语义层面的查询意图理解
4.3 Exa 的相对弱势
值得注意的是,Exa Search作为同样定位"AI原生"的搜索服务,在两个维度上均排名最后。这提醒我们:"AI原生"这一标签本身并不能保证性能。具体实现细节——索引质量、后处理管线、查询理解能力——才是决定因素。
评估的警示意义:当厂商使用"AI原生"、"为LLM设计"等营销术语时,学术界和开发者社区应当要求可验证的数据支撑,而非仅凭标签做判断。开源基准测试框架的价值正在于此。
五、工程维度对比:延迟、成本与Token效率
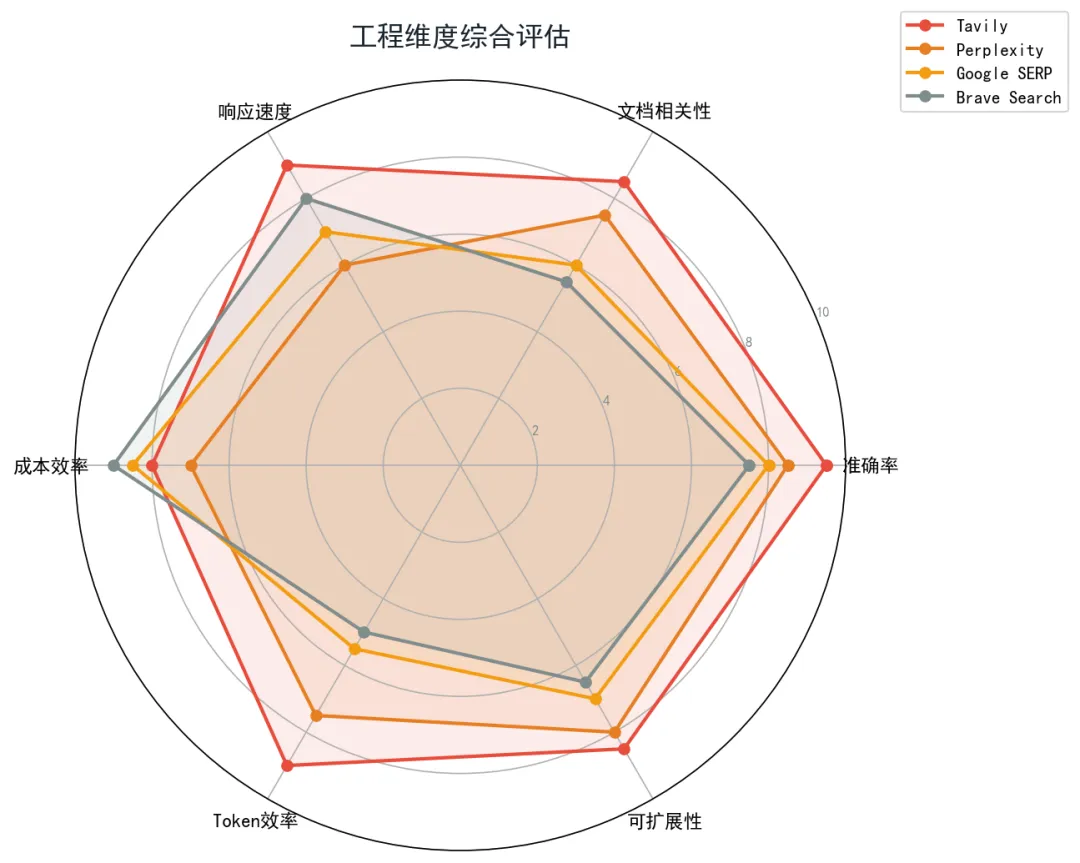
除了准确率和相关性,生产环境中还需要考虑延迟、成本和Token效率等工程指标。
5.1 响应延迟
Tavily官方公布的P50响应延迟为180ms。作为对比:
Google Custom Search API 的典型延迟在 300-800ms 之间 Bing Search API 的典型延迟在 500-1500ms 之间 Perplexity API 的延迟因搜索深度不同,通常在 1-3 秒之间
需要指出的是,延迟与准确率之间存在权衡关系。Tavily的180ms可能是/basic搜索深度的延迟,而/advanced模式下的延迟会更高。同理,Perplexity较长的延迟可能与其深度推理过程有关。
5.2 Token 效率
Token效率是一个常被忽视但实际影响巨大的指标。当搜索结果注入LLM上下文窗口时,低信噪比的输入意味着:
更多Token被无关内容消耗,缩短了有效上下文长度 模型注意力被分散,可能遗漏关键信息 每次API调用的成本上升(按Token计费)
基于SimpleQA和文档相关性的结果可以间接推断Token效率:在文档相关性上排名更高的系统(Tavily 83.02% vs Exa 51.33%),其返回文档的平均信息密度也更高,因此每Token的信息价值更大。
5.3 成本考量
Tavily的定价策略包括免费层(1000次/月)和付费层(按比例计费)。Perplexity和Exa也提供类似的定价模式。Google Custom Search API有每月免费配额(100次),超出后按查询计费。
对于学术研究场景,成本敏感度通常低于工业应用。但如果研究涉及大规模数据集(数万甚至数十万次搜索调用),成本将成为不可忽视的因素。开源评估框架允许研究者在有限的预算内选择最优的搜索后端。
六、学术评估方法论的启示

tavily-search-evals 的设计对更广泛的AI评估研究提供了几个方法论层面的启示。
6.1 评判者一致性(Judge Consistency)
该框架使用统一的GPT-4.1作为评判模型,这是一个明智的设计选择。在AI评估中,评判者的一致性是结果可信度的前提。如果使用不同模型评判不同系统,评估结果将混合"系统性能差异"和"评判者偏好差异",难以分离。
然而,这一设计也引入了潜在的评判者偏差:GPT-4.1可能对某些类型的答案有系统性偏好。更严谨的评估可以考虑使用多个评判模型并报告一致性分数。
6.2 动态基准 vs 静态基准
文档相关性评估采用动态数据集生成机制,这是对传统静态基准的重要补充。静态基准的优势是可复现性强,劣势是容易被污染。动态基准的优势是更能反映真实场景,劣势是不同时间点的评测结果可能不完全可比。
对于学术研究而言,理想的方案可能是混合使用:静态基准用于纵向比较(同一系统不同版本),动态基准用于横向比较(不同系统同一时间点)。
6.3 开源评估框架的社区价值
Tavily选择将评估框架开源,这一决策本身就值得肯定。它允许:
第三方独立验证评测结果 社区贡献新的搜索提供商handler 研究者在自己的领域数据集上复用评估方法 持续改进评估方法论(如引入新的评判指标)
这种开放性对于建立AI搜索领域的"公共评估基础设施"至关重要。
七、局限性与评估偏差讨论

任何基准测试都有其适用范围和局限。对tavily-search-evals的批判性审视同样重要。
7.1 已知局限
- 语言覆盖偏置
:SimpleQA以英语为主,评测结果对非英语场景的推广性有限 - 领域覆盖有限
:事实问答只是搜索能力的子集,无法反映创意写作、代码搜索、多跳推理等场景 - 评判模型局限
:GPT-4.1虽然强大,但在某些边缘案例上仍可能出现评判错误 - 超参数调优空间
:每个提供商的最优配置可能未被完全探索 - 时间敏感性
:搜索结果的性能可能随时间波动(索引更新、内容变化)
7.2 潜在的评估偏差
需要警惕几种可能的评估偏差:
- 开发者效应
:Tavily开发自己的评估框架,在超参数选择和问题定义上可能存在隐性偏向 - 幸存者偏差
:评测只包含当前流行的搜索API,可能遗漏新兴但表现优异的系统 - 任务选择偏差
:SimpleQA侧重短事实查询,对长文本理解、多文档综合等能力反映不足
对学术界的建议:在使用任何基准测试结果指导研究或工程决策时,应当同时考虑测试的覆盖范围、方法论局限性和潜在的偏置来源。单一基准的领先不意味着全面优越。
八、未来展望:AI搜索评估的演进方向
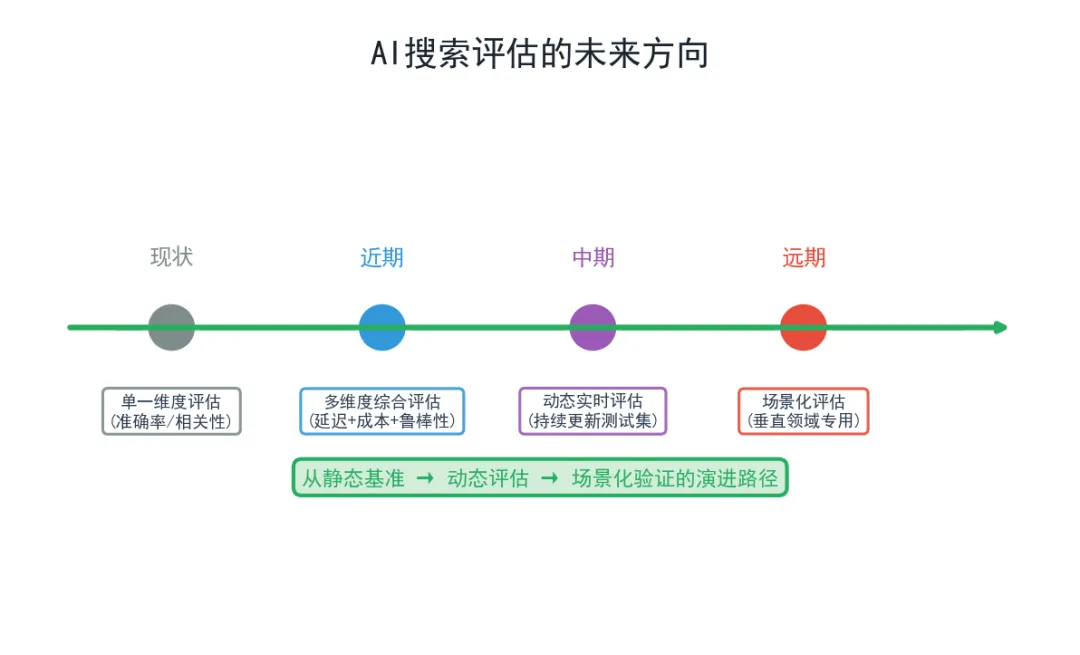
基于当前的技术趋势和评估实践,我们可以预见AI搜索评估领域的几个演进方向:
8.1 多语言评估基准的建立
当前评测以英语为主导,但AI应用正在全球范围内普及。建立覆盖中文、日语、阿拉伯语、印地语等主要语言的多语言评估基准,将是下一阶段的重要工作。
8.2 多模态搜索评估
随着多模态大模型的发展,搜索不再局限于文本。图像搜索、视频内容检索、跨模态关联("根据图片找相关论文")等新场景的评估标准亟待建立。
8.3 长期一致性评估
当前基准测试多为单时间点快照。对于需要持续信息摄入的应用(如学术研究追踪、市场监测),搜索系统的时间一致性——即在不同时间对同一查询返回稳定且逐步更新的结果——同样重要。
8.4 领域特定评估
通用基准难以覆盖所有专业领域。生物医学、法律、金融、材料科学等领域需要各自的专业评估数据集和方法论。
九、结语:数据驱动的AI搜索选型
回到本文的核心问题:如何在众多搜索API中做出理性选择?
本文提供的答案是:不要只听营销文案,要看可复现的数据。tavily-search-evals 框架的价值不仅在于它给出的排名,更在于它提供了一种方法论模板——公开数据集、统一评判、透明配置、可扩展架构。
对于学术界而言,这种数据驱动的评估文化尤为重要。我们的研究依赖于可靠的信息获取,而可靠的信息获取又依赖于对搜索系统能力的客观认知。
对于工业界而言,基准测试数据为技术选型提供了量化的依据,帮助团队在质量、成本和延迟之间做出符合自身场景的权衡。
每日办公小技巧技巧:用基准测试框架快速评估适合你的搜索API 如果你正在为一个具体项目选择搜索后端,与其逐一试用,不如借助开源评估框架做一个"迷你基准测试": 1. 从tavily-search-evals仓库fork一份评估代码 2. 用你项目中的真实查询样本替换部分测试问题(10-50个即可) 3. 运行评估脚本,对比各候选API在你的实际场景上的表现 4. 关注两个指标:平均准确率 + 失败案例的分布模式 这种方法只需要一两个小时,却能给出比"看文档+凭感觉"可靠得多的选型依据。记住:别人的最佳实践不一定是你的最佳实践,只有基于自己数据的评估才是可信的。
BenchmarkSimpleQAAI搜索对比评估框架RAG评测开源基准
参考来源:Tavily开源评估框架 tavily-search-evals https://github.com/tavily-ai/tavily-search-evals https://openai.com/index/introducing-simpleqa/ https://docs.quotientai.co/ 本文发布于 2026年6月5日
原文参考: https://github.com/tavily-ai/tavily-search-evals
