 夜雨聆风
夜雨聆风
6月8日全球AI新闻
Agent走向可管理舰队,
OpenAI 芯片二号人物加入Anthropic,
DeepSeek 登顶 Ramp
01
今日最重要的 5 个信号
信号 1:OpenAI 公开说"聊天已死",消费级 AI 正在向 agent 和企业端转身

"Chat is dead" 是 OpenAI 内部一位资深员工的概括,不是官方 slogan,但方向很清楚:把 ChatGPT 从"问答聊天机器人"重做成集成编程(Codex)、图像生成和第三方应用(Canva、Booking.com)的"超级应用"。值得注意的是触发点——据 FT,Codex 自 2 月推出桌面端以来周活增长约 6 倍至 500 万以上,且多数是付费用户。换句话说,这次转身不是"理念升级",而是被一个真正赚钱的 agent 产品反向拉动的。对创业者来说,这条信号比任何模型跑分都重要:消费端流量的尽头,越来越被当成通往企业付费的入口,而不是终点本身。

信号 2:Agent 从"单个助手"走向"可管理的舰队",并开始自己写代码
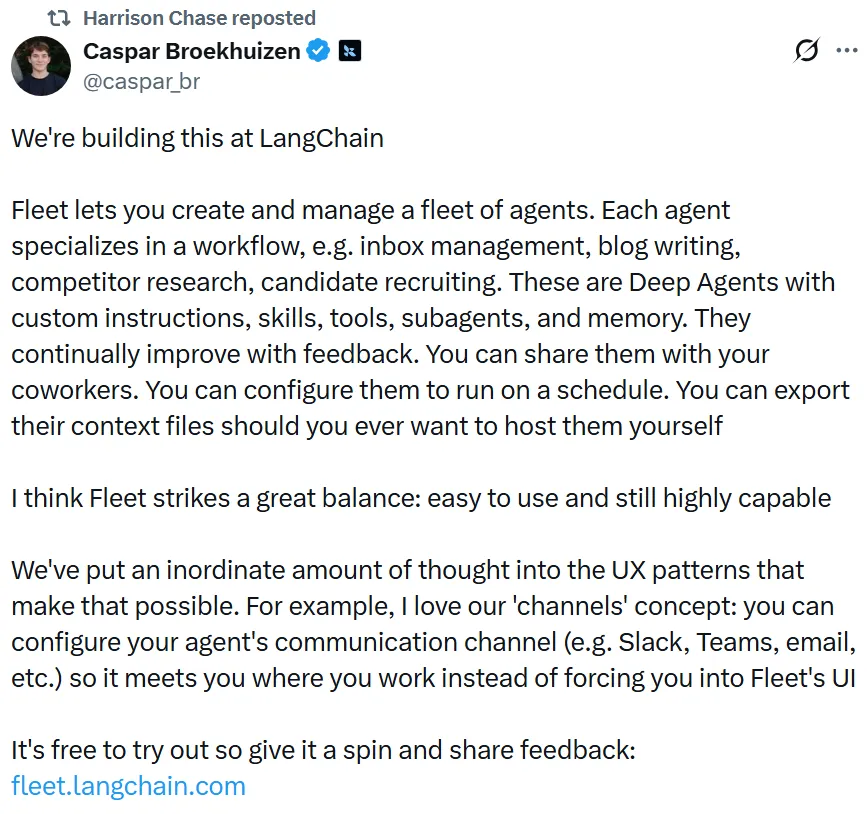
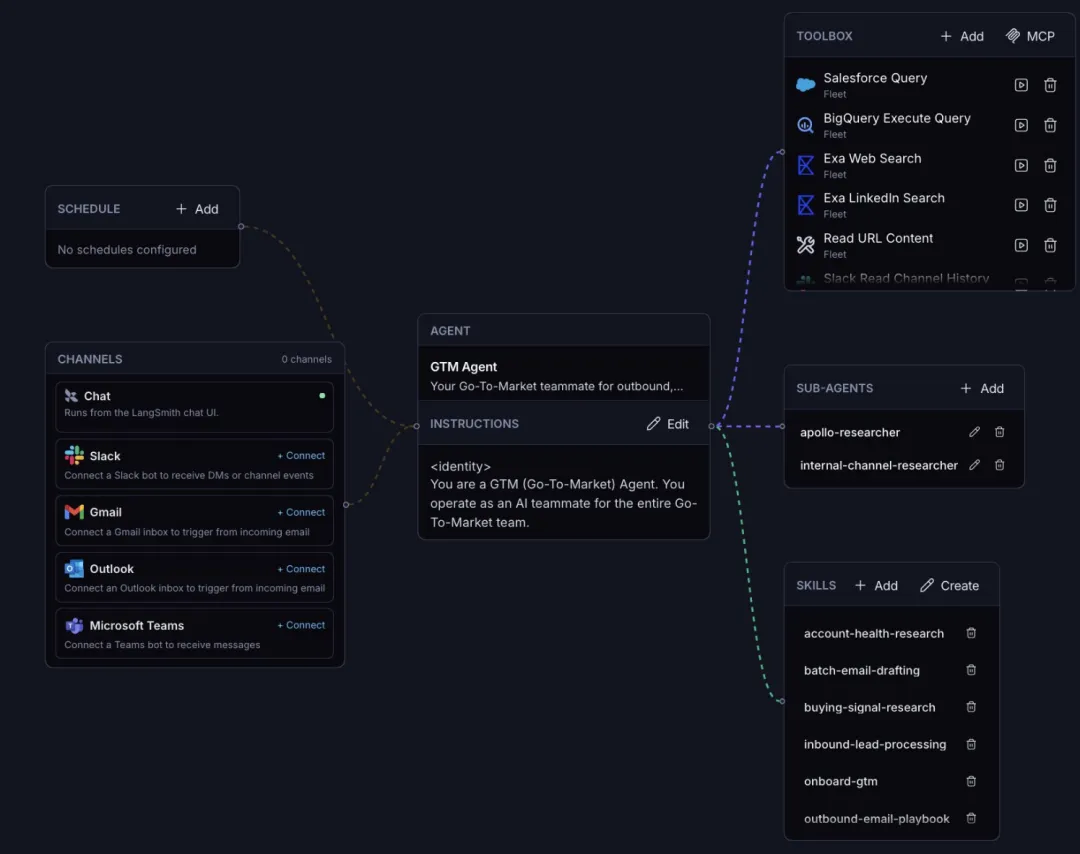
过去半年大家在比"单个 agent 能不能完成任务",这 24 小时的信号是:竞争点正在上移到"怎么管理一群 agent"和"agent 怎么自主决定动作"。LangChain Fleet 把 agent 当成"同事"来管理(按工作流分工、配置沟通渠道、排期运行);Perplexity 则更激进,让模型在沙箱里自己写 Python 检索代码,而不是调用固定 API。这两件事指向同一个方向——agent 的"控制平面"正在从人写死的流程,让位给模型自己编排。这对工具厂商是个提醒:未来护城河可能不在"我家 agent 多聪明",而在编排、权限、沙箱和可观测性这套"运行体系"。

信号 3:国产与开源模型,正在变成别人系统里的"基础设施"
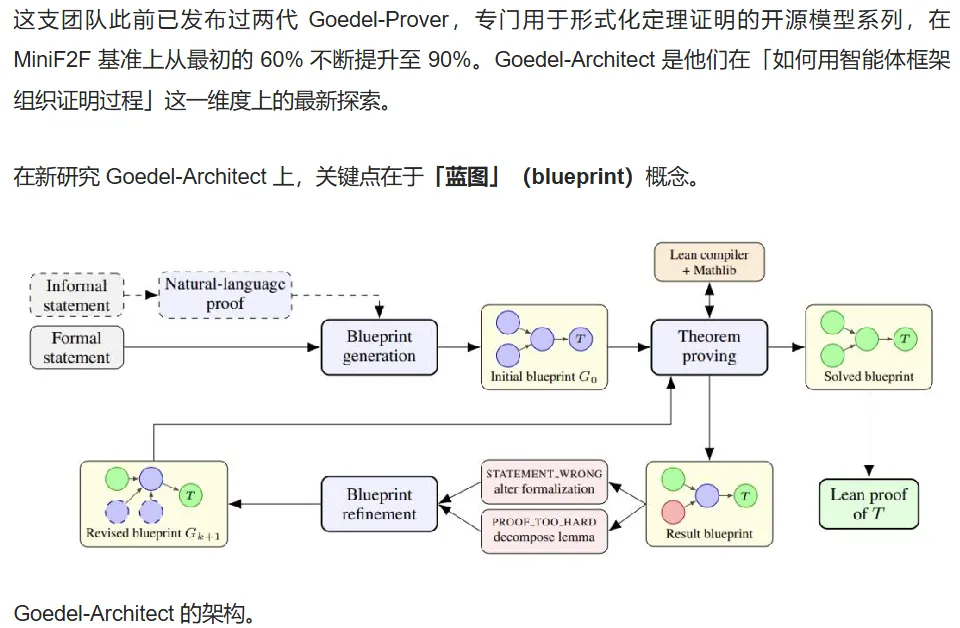
开源/国产模型的角色,从"自己玩的便宜替代",变成"嵌进别人产品里的零件"。普林斯顿团队的形式化证明智能体框架用的核心模型是开源的 DeepSeek-V4-Flash;Ramp 的企业支出数据显示 DeepSeek 成了 6 月最热门的新增软件供应商;Gemma 4 进了 llama.cpp 主线、Reachy mini 在本地跑 Gemma 4 + Qwen3-TTS。需要泼一点冷水:Ramp 自己的经济学家也提醒,企业把数据直接发给中国模型存在安全顾虑。所以这条信号的正确读法不是"国产模型赢了",而是"成本和开放权重正在把它们推进供应链,安全与合规会成为下一个争夺点"。

信号 4:prompt injection 仍是 agent 绕不过去的"阿喀琉斯之踵"

当所有人都在加速给 agent 联网、给它权限的时候,OpenAI 的动作反而是给 ChatGPT 加一个"锁定模式"——关掉联网、Deep Research 和 Agent Mode。这本身就说明了问题:报道明确指出,锁定模式只是堵住数据外泄链条的最后一步,并不能根治 prompt injection,后者仍是一个未解难题。这是我最想提醒产品同行的一点——agent 能力越强、接触的数据和工具越多,攻击面就越大。在企业落地 agent 时,"它能做什么"和"它在被诱导时会做什么"必须当成两个独立问题来评估。

信号 5:上层叙事的水面之下,是芯片人才、算力账单这些"不性感但致命"的成本

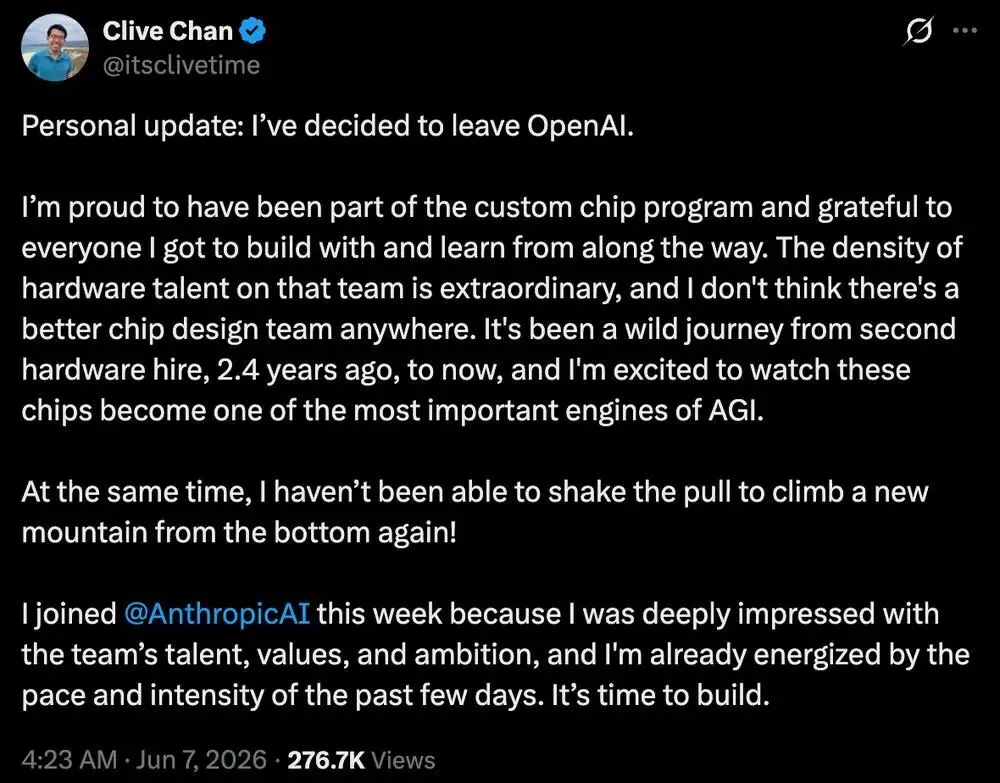
模型跑分是给外界看的,真正决定胜负的往往是水下的东西。这一天里,Anthropic 挖走了 OpenAI 自研芯片项目的"二号员工"Clive Chan(两家都在筹备 IPO,Anthropic 据报道在考虑自研芯片);36氪那篇关于视频模型的文章则戳破了"AI 烧钱 = 买 GPU"的简化叙事——光是视频和特征数据的存储、以及数据进出带宽,每月就能到几十万美元量级。连开发者社区都在抱怨"浏览器 agent 把我的 API 预算吃光了"。对投资和创业判断而言:未来一年,谁能把人才、算力和单位 token 成本这三件事管好,可能比谁多发一个模型更重要。

01
二、AI 企业官宣:哪些官方动态值得看?
1. Perplexity:"Search as Code"——让模型自己写检索代码

一句话概括:Perplexity 用"Search as Code"架构,让 agent 在沙箱里自己写 Python 检索流水线,而不是调用固定搜索 API。
核心内容:
三层架构:推理模型作"控制平面"决定检索策略 → 安全沙箱执行代码 → Agentic Search SDK 暴露底层检索原语。
官方数据:在一个 CVE 研究任务上 token 用量减少约 85%;在长程网页研究基准 WANDR 上比次优系统高约 2.5 倍。
该能力已并入 Perplexity 的 Agent API,并成为其 agent 平台"Computer"的默认检索方式。
为什么重要:这是"工具调用"范式的一次重要演进——从"模型选 API"到"模型写代码",可能显著降低复杂检索任务的 token 成本。
我的判断:方向上很有说服力(让模型自己做过滤和去重,确实能省 token)。但这些都是 Perplexity 第一方基准,缺少独立第三方复现;WANDR 也是较新的基准,任务定义和污染风险都需要外部验证。建议把它当成"值得跟踪的架构趋势",而不是"已被证实的客观最优"。

2. OpenAI:给 ChatGPT 加"锁定模式",正面承认 prompt injection 没解决

一句话概括:ChatGPT 新增"Lockdown Mode",可关闭联网、Deep Research 和 Agent Mode,以降低 prompt injection 导致的数据外泄风险。
核心内容:
锁定模式通过禁用对外动作,让攻击者更难完成数据窃取。
报道明确:它只堵住外泄链条的"最后一步",并不能阻止 prompt injection 本身。
prompt injection 仍被定性为一个"未解决的问题"。
为什么重要:这是头部厂商以产品形态公开承认"agent 安全是减法题,不是加法题"——有时最稳妥的防御是让 agent 少做事。
我的判断:对正在做企业 agent 的团队,这是一个很现实的范式参考:与其追求"全能联网 agent",不如按数据敏感度分级,给高敏感场景默认收紧权限。能力和攻击面是一体两面,这一点这次被官方动作直接印证了。

3. 研究 / 中国 AI:用开源 DeepSeek-V4-Flash 做形式化数学证明

一句话概括:普林斯顿团队提出名为 Goedel-Architect 的智能体框架,用开源模型 DeepSeek-V4-Flash 生成可被 Lean 编译器验证的形式化证明。
核心内容:
背景:2026 年 5 月 20 日 OpenAI 宣称其内部推理模型推翻了埃尔德什 1946 年提出的"单位距离猜想";陶哲轩在斯坦福演讲称数学正进入"证明过剩时代",瓶颈从"生成证明"转向"验证证明"。
思路:让 AI 生成 Lean 可机器检验的完整证明,难度远高于自然语言推导;Goedel-Architect 用智能体框架来逼近这一目标,核心模型是国产开源的 DeepSeek-V4-Flash。
36氪标题中的"500 倍成本优势/刷新多项纪录"是对该智能体系统效果的概括。
为什么重要:它把"开源模型 + agent 框架"这条路径,推到了数学这种最讲严格性的领域,也呼应了信号 3——开源模型正成为别人研究系统里的核心零件。
我的判断:这里要分清三件事:OpenAI 的埃尔德什结果(5 月 20 日,属背景,不在本次 24 小时窗口)、陶哲轩的判断(观点)、以及普林斯顿这篇用 DeepSeek-V4-Flash 的论文(本次的新信息)。"500 倍成本优势"是媒体概括,具体口径、对比基线和是否有独立复现都需查阅论文原文,不宜直接当结论引用。最稳的读法是:形式化证明 + 开源模型,是一个证据正在积累、但远未盖棺定论的方向。

01
三、科技名人动态:他们今天说了什么?
1. Harrison Chase(LangChain):用 Fleet 管理一支 agent"舰队"

一句话概括:LangChain Fleet 让你创建并管理一支各有专长的 agent 舰队(收件箱管理、写博客、竞品调研、招聘等)。
核心内容:这些是带自定义指令、技能、工具、子 agent 和记忆的 Deep Agents,可随反馈改进、可与同事共享、可排期运行、可导出上下文自托管;"channels"概念让 agent 接入 Slack/Teams/邮件,在你工作的地方找你。
为什么重要:它代表 agent 产品化的下一步——从"一个聊天助手"到"一组可治理的数字同事",UX 重心转向管理、协作与可移植性。
我的判断:这是厂商主张,目前是"免费试用"阶段,实际的长任务稳定性、权限边界和失败模式都还需要真实使用来检验。方向对,但"能演示"和"能稳定干活"之间,往往隔着最难的那段路。

01
四、Benchmark / Research:模型能力出现了什么变化?
1. 一项研究:为什么大模型能学会小模型学不会的技能

一句话概括:小模型学不会稀有任务,是因为高频任务不断覆盖已学内容;提高目标任务在训练数据中的出现频率,可能比单纯把模型做大更有效。
核心内容:研究用 400 万到 40 亿参数的模型,刻画了这一"覆盖"机制,并给出一个实用解法——增加目标任务的数据频率。
为什么重要:它把"能力来自规模"这个直觉,细化成"能力来自数据频率与覆盖的平衡",对预算有限、做不起超大模型的团队尤其有价值。
我的判断:这是该研究在受控参数区间(4M–4B)内的结论,能否线性外推到前沿规模仍需验证。但它的工程启示很具体:与其盲目堆参数,不如先审视数据配比,针对性提升目标能力的样本占比。

01
五、产品与生态:值得跟进的更新
1. DeepSeek 登上 Ramp 6 月趋势软件供应商榜首
一句话概括:基于 Ramp 的企业支出数据,DeepSeek 成为 2026 年 6 月最热门的新增付费软件供应商,反映美企对更便宜 AI 的需求。
为什么重要 / 我的判断:这是用"真金白银的企业支出"而非声量来衡量采用度,比社交媒体讨论更硬。但 Ramp 首席经济学家同时警告——把数据直接发给中国模型存在安全风险。成本驱动是真的,安全顾虑也是真的,两者会同时塑造接下来的企业选型。

2. Reachy mini:本地近实时运行,并能接入 MCP

一句话概括:小型机器人 Reachy mini 在 1.8.0 版本可本地近实时跑通"语音到语音",并支持接入 MCP 工具。
为什么重要 / 我的判断:它在本地组合了 Gemma 4 E4B QAT + Parakeet + Qwen3-TTS,说明"端侧多模态 + 工具调用"正在变得可触达。这是单个开发者的体验分享,属于线索而非普遍能力证明;但它和 Gemma 4 进 llama.cpp 一起,勾勒出"边缘智能体"逐渐成形的轮廓。

3. Gemma 4 MTP 合并进 llama.cpp
一句话概括:Gemma 4 的 MTP(多 token 预测)已正式并入 llama.cpp,配合 QAT 可实现更轻量、更快的本地部署。
为什么重要 / 我的判断:llama.cpp 是本地推理的关键底座,主线支持意味着 Gemma 4 在端侧的可用性显著提升。具体加速幅度依硬件而定,原文未给统一数字,需要社区实测;但这类"底座级"更新,往往比一次模型发布更能决定开源生态的走向。

4. 36氪:视频模型巨大的"隐形成本"
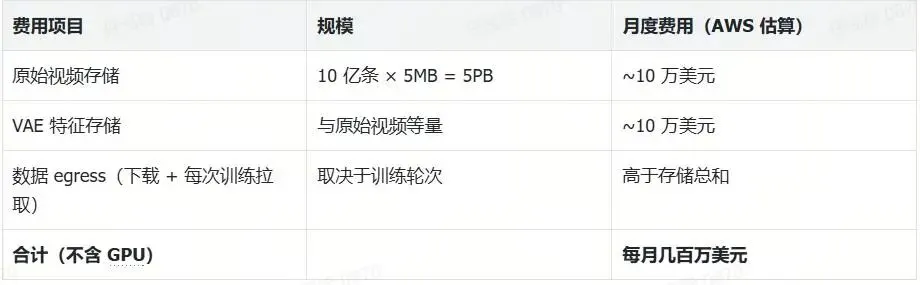
一句话概括:训练视频大模型,被低估的不是 GPU,而是数据存储与进出带宽——光存储就可能每月几十万美元。
为什么重要 / 我的判断:文章引用前 xAI 研究员 Ethan He 的说法(他三个月从零搭出 Grok Imagine):10 亿条视频需约 5PB 存储,叠加 VAE 特征数据后达数十 PB,月存储费超 20 万美元,还有可观的数据进出费。这是一个很好的提醒——评估一家视频/多模态公司的"烧钱效率",不能只看 GPU 账单。文中数字属受访者口径,应视为量级参考而非精确财报。

5. Notion 恢复对 Anthropic 模型的访问

一句话概括:周末 Notion 因 Anthropic 模型性能下降短暂停用全部 Anthropic 模型,约 12 小时后恢复。
为什么重要 / 我的判断:Notion 称 Opus 4.7/4.8 出现"性能降级"导致失败率上升。但其产品负责人随后公开反驳——很多人转发是想把它解读成"模型质量问题"。这条提醒我们:上游模型抖动会被下游产品放大,而"服务降级"和"模型变笨"是两回事,传播中很容易被混为一谈。
完



OpenProduct
分享超级个体AI工具
和学习者一起成长
创作不易,一起“点赞”三连↓
