 夜雨聆风
夜雨聆风Agent 行业最爱讲的故事就是「长期记忆」——它记得你的偏好,它会从失败中学习,它越用越懂你。但这些能力从来没有被严格测量过。现在,Continual Learning Bench(CL-Bench)来了:它用六大类序列化任务、配对的 stateless 基线和一个叫「Gain」的核心指标,把「Agent 是否真的能从经验中学习」变成了一道可以打分的考题。更炸裂的是,第一批榜单结果显示:花大价钱搭建的复杂记忆系统,表现竟然不如最朴素的上下文学习方案。
每个 Benchmark 都在假装 Agent 没有记忆
先问一个问题:你用的 AI 助手,今天帮你查了一个数据库的 schema,明天你再问类似的问题,它还会从头摸索一遍吗?
如果答案是「会」,那它就是一个很贵的一次性答题机器。
这恰恰是当前所有主流 Benchmark 的默认假设。MMLU、HumanEval、SWE-bench……每一道题都是独立的。上一题做完,清空上下文,下一题重新开始。模型的状态永远是 stateless。
可现实世界里部署的 Agent 恰恰相反。
它在你的代码库里连续修 bug,在同一个数据库里反复查询,在同一个交易流程里连续决策。如果每次都从零开始,那所谓的「长期 Agent」,不过是在循环调用一个强模型而已。
"Benchmarks today make a core assumption: models are stateless. Once they complete a task, they move on to the next as if the first never happened."
「今天的 Benchmark 有一个核心假设:模型是无状态的。完成一个任务后,它们就开始下一个,仿佛第一个从未发生过。」

▲ CL-Bench 官方发布博客开篇就直接点破:现有评测体系默认模型不会学习
这个断层,CL-Bench 要补上。
一个公式,撕开 Agent「学习」的真假
CL-Bench 的核心设计极其精巧:序列化任务 + 配对 stateless 基线。
什么意思?它不给你一道孤立的题。它给你一串任务实例,每个任务由多个 instance 组成。早期实例会暴露数据库结构、代码仓库约定、对手策略、数据模式。如果你的系统真的在「学习」,后续实例就应该做得更快、更准。
然后是关键一刀:同一个系统,同一道题,做两遍。
第一遍,带着之前所有的经验和记忆做。第二遍,清空一切,从零做。
两次得分的差值,就是Gain。
Gain = 带经验的得分 - 从零开始的得分
正值,说明经验确实帮了忙。零,说明你的记忆系统白搭了。负值?那更惨——你的 Agent 不仅没学到东西,还被历史信息带偏了。
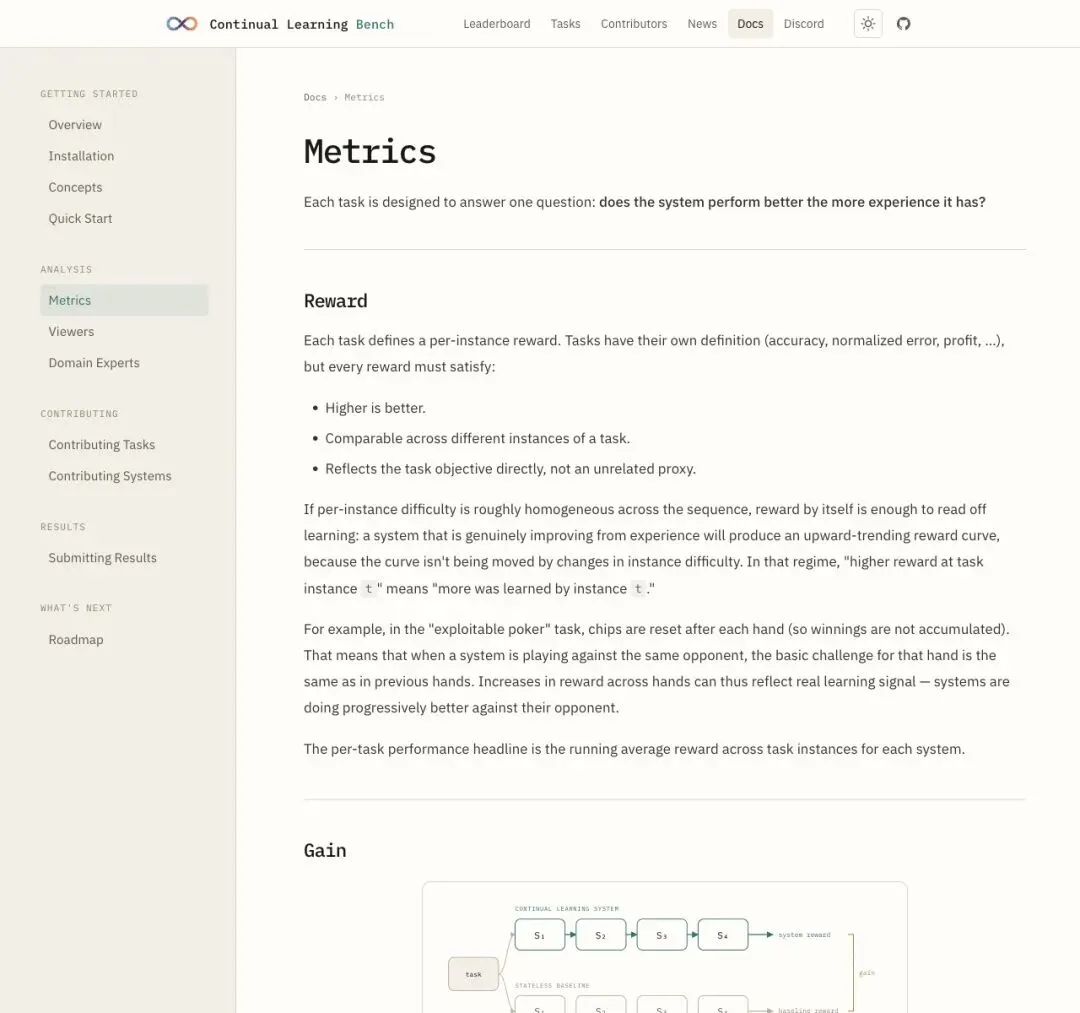
▲ 官方指标文档:每个任务回答一个问题——「系统拥有更多经验后,表现是否变好了?」
"Does the system get better because of what it has experienced?"
「系统会因为它经历过的事情而变得更好吗?」
这句话看起来简单,但在 AI 评测史上,之前从来没有人这样问过。
六大「连环考场」,招招戳中 Agent 的软肋
CL-Bench 准备了六类任务,每一类都不是简单的问答,而是需要跨实例积累可复用信息的连环挑战。
Database Exploration(数据库探索):Agent 面对一个完全未知的 SQLite 数据库,通过探索性查询回答自然语言问题。刁钻的是,schema 会在实例之间漂移——你上次摸清楚的表结构,这次可能变了。系统要学会哪些约定是稳定的,哪些在变化。
Codebase Adaptation(代码库适应):在一个共享代码库里连续解决 GitHub issue。不仅看你能不能修好 bug,还看你用了多少次 bash 交互。如果第五个 issue 还像第一个一样到处 grep,你就没学到任何东西。
Exploitable Poker(可利用的扑克):对手有固定但有漏洞的策略。你的 Agent 能不能从一手手牌的结果中推断弱点,逐步调整策略实现盈利?这考的是最纯粹的博弈学习能力。
还有 Sales Prediction(销售预测)、Cohort Studies(队列研究)、Blind Spectrum Monitoring(盲频谱监测),每一个都模拟真实 Agent 的工作场景:环境可交互,反馈可观察,经验可以带走——但也可能带来干扰。
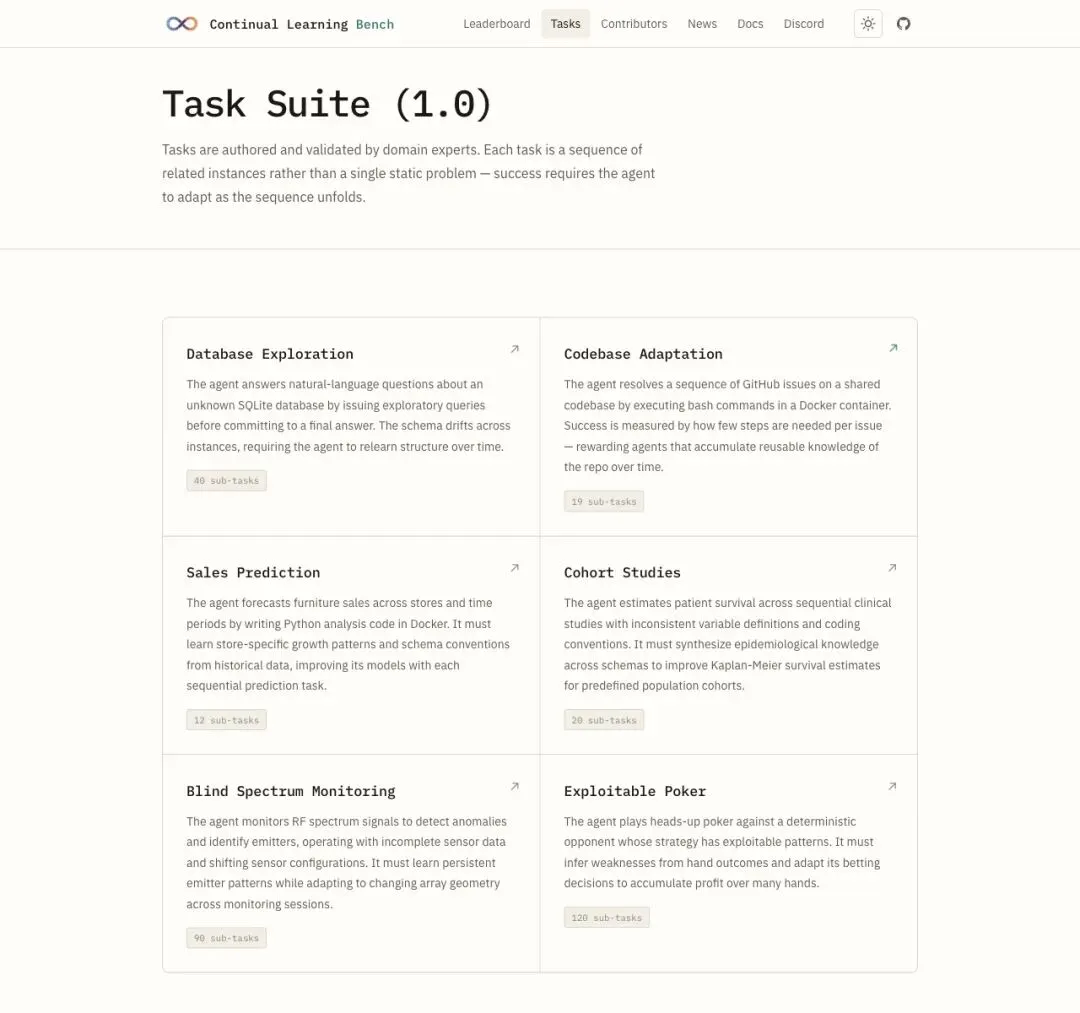
▲ CL-Bench 六大任务套件,覆盖从数据库到扑克博弈的多种 Agent 场景
这些任务不保证「记住越多越好」。恰恰相反,它们考验的是系统有没有能力分辨什么该记、什么该忘。
榜单出来了,结果让整个 Agent 行业尴尬
第一批排行榜已经公布。排在前列的是 ICL·Claude Sonnet 4.6(Reward 0.223,Gain 0.254,成本 $30.43)、ICL·GPT-5.4(Reward 0.201,Gain 0.201,成本 $18.39)和 Claude Code·Sonnet 4.6。
Mem0、ICL Notepad、Codex、ACE 等记忆增强系统也被纳入了比较。
然后是那个令人窒息的发现。
官方博客的原话:
"Vanilla in-context learning systems are among the best we have looked at."
「最朴素的上下文学习系统,是我们评测过的最好方案之一。」
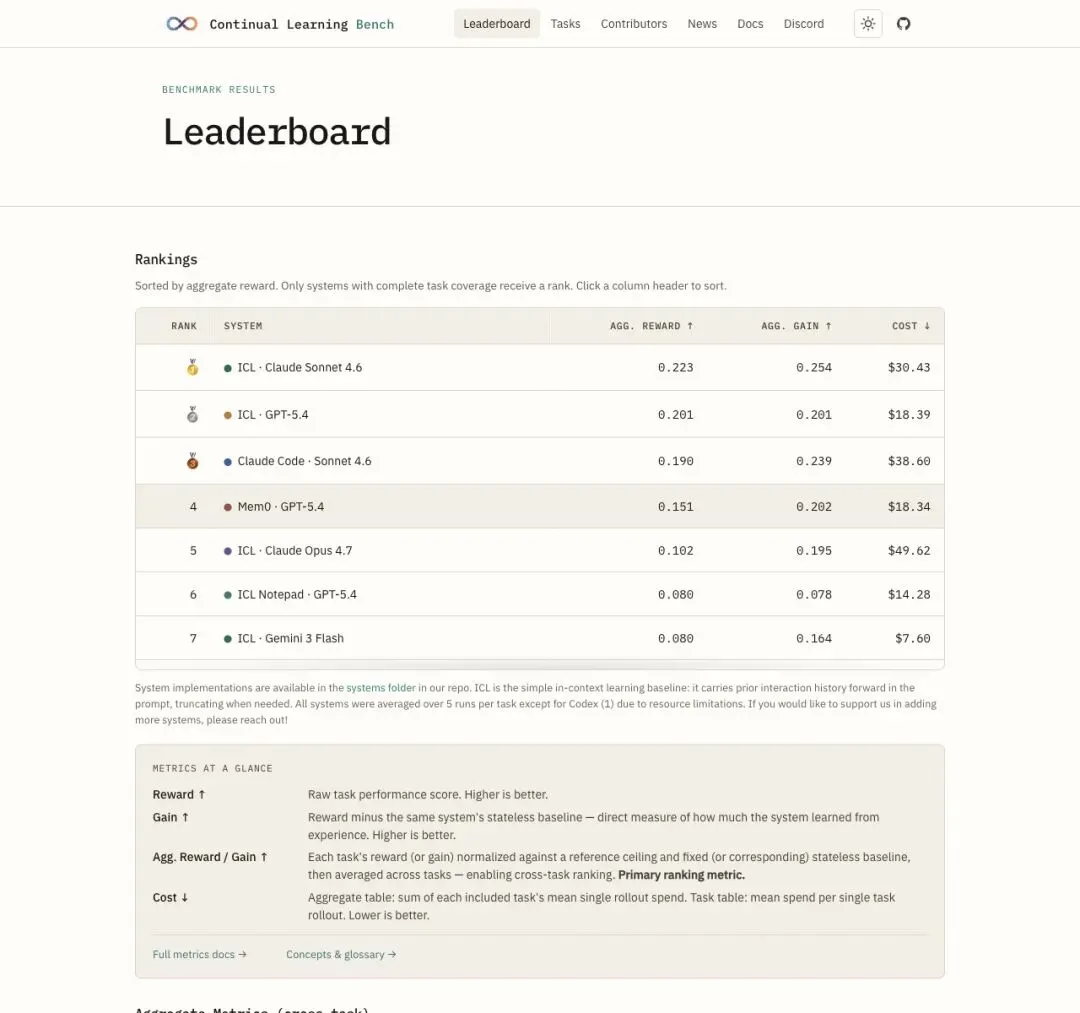
▲ CL-Bench 首批排行榜:ICL·Claude Sonnet 4.6 领跑,简单 ICL 方案力压复杂记忆系统
翻译一下这句话的潜台词:那些花了几个月搭建 memory module、long-term profile、self-improvement pipeline 的 Agent 产品,在这张考卷上,可能还不如「把历史上下文一直带着走」这个最笨的办法。
这对过去半年疯狂鼓吹「Agent 记忆」的创业公司来说,简直是当头一棒。
学习不是免费的,CL-Bench 连账单都替你算好了
榜单还有一列数据很扎眼:Cost。
为了复用经验,系统可能保存更长的上下文、调用额外的检索系统、运行总结器或反思器。每一步都在烧 token、加延迟。
如果 Gain 很小,而成本翻了一倍,那你的 Agent 就是在用两倍的钱,做差不多的事。
CL-Bench 本质上测的是学习收益率——不只是你学到了什么,而是你为学习付出了多少代价,以及这个代价是否值得。
这在以前的 Benchmark 里从未出现过。
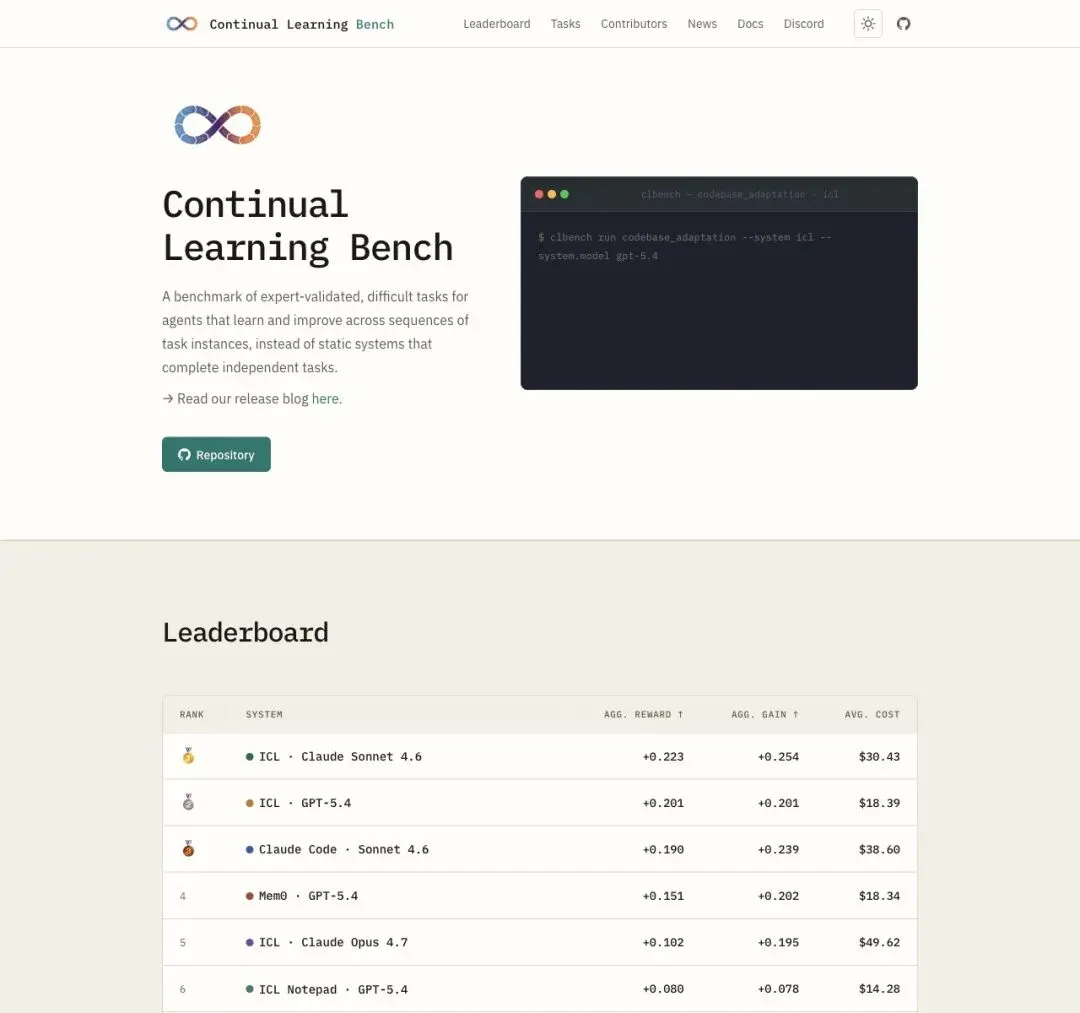
▲ CL-Bench 官方主页:专为「能学习和改进的 Agent」设计的评测基准
Agent 评测的分水岭
CL-Bench 的出现并非孤例。arXiv 上的相关论文 AgentCL 同样在追问:Agent 在单个任务上花了大量推理时间,但一次交互中获得的经验,有多少被后续任务真正用上了?

▲ AgentCL 论文指出:Agent 的经验复用远不如预期
一个趋势已经很明确了:Agent 评测正在从「一次性答题能力」转向「跨 episode 的迁移、抗干扰和状态管理」。
过去「continual learning(持续学习)」这个词更多出现在模型训练阶段,讨论的是灾难性遗忘。现在问题变了——部署后的 Agent,如何在不重新训练的情况下,从环境互动中提炼可复用经验?
非参数记忆、上下文压缩、notepad、episodic memory、skill library、workflow reflection……所有这些技术,即将被放到同一张实验桌上,用 Gain 指标一刀切开真假。

▲ DAIR.AI 的 Omar 等研究者已在社区讨论 CL-Bench 的意义
从「演示时代」到「核算时代」
回到最初的问题:你的 Agent 真的越用越聪明吗?
很多 Agent demo 看起来确实像在学习——它记得你的偏好,能总结上次失败,还会把经验写进记忆。但没有配对的 stateless 基线做对照,你根本无法判断:它是真的学会了,还是只是更贵了、更慢了、还更容易被历史噪声带偏了?
CL-Bench 提出了一种全新的衡量方式:评估 Agent 的长期价值,不只看它第一次回答有多聪明,而要看它的经验转化率——experience-to-gain conversion。
Agent 行业正在从演示时代进入核算时代。
能学习的 Agent 才有未来,但「能学习」这三个字,从今以后得拿数据来证明。
— END —
