 夜雨聆风
夜雨聆风
事情是这样的。
这两天 GitHub 上有个项目突然冲得很猛,叫 Headroom。
我一开始看到它的时候,第一反应其实不是「哇,又一个 AI 工具」。而是有点无语。
因为它解决的这个问题,太真实了。
你有没有那种体验,明明只是想让 AI 帮你看个日志、读一堆网页、分析几个 RAG 分片、总结一个代码搜索结果,结果上下文一下子就爆了。模型还没开始认真干活,token 先烧了一大截。
更烦的是,很多资料其实没有那么值钱。日志里一堆重复行,搜索结果里一堆噪声,JSON 里一堆字段,网页里一堆无关内容。
但你还是得整包塞进去。
然后看着 token 哗哗掉。
有时候我真的会想,不是哥们,我是让 AI 干活,不是让它先把垃圾桶翻一遍。
Headroom 做的事,就很像在 AI 吃资料之前,先给资料过一遍压缩机。
软件名称: Headroom
软件类型: AI Agent 上下文压缩层 / token 优化工具
适用场景: 日志分析、代码搜索、RAG、文件读取、工具输出、Agent 工作流
当前热度: GitHub 约 18.9k stars,本周热榜增长明显
测试来源: GitHub README / 官方文档 / Chrome
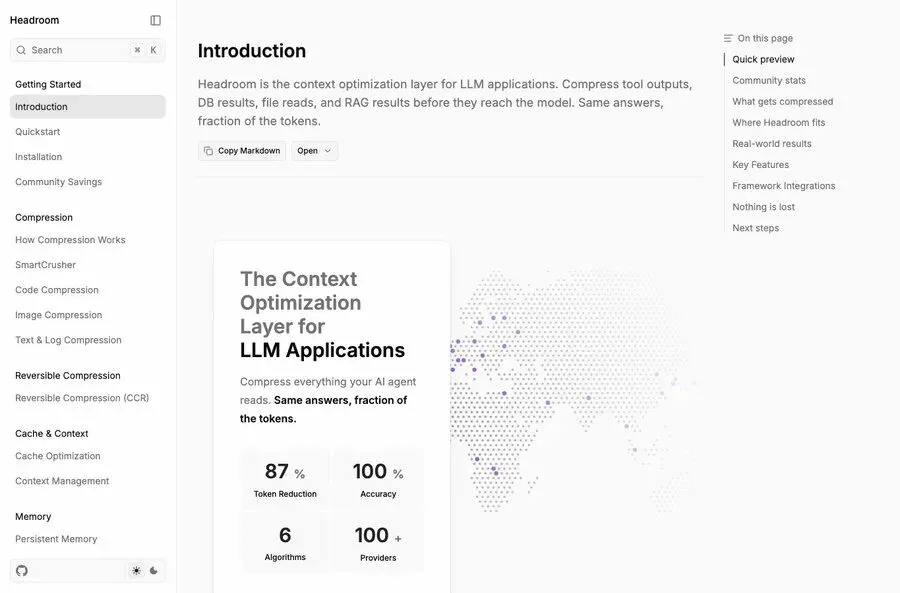
Headroom 的 README 里写得挺直接。
它是 The context compression layer for AI agents。
翻成人话就是,给 AI Agent 加一层上下文压缩层。
AI Agent 平时会读很多东西,工具输出、日志、RAG chunks、文件内容、历史对话、代码搜索结果。这些内容如果原封不动塞给 LLM,很容易又贵又乱。
Headroom 的思路是,在这些内容送进模型之前,先做一次压缩。官方 README 里写的是 60%-95% fewer tokens,也就是少用 60% 到 95% 的 token。
当然,这个数字要冷静看。它是官方给的测试结果,具体到你的项目、你的日志、你的资料,不一定每次都这么夸张。
但方向很对。
因为现在 AI 真正贵的地方,很多时候已经不是单次提问,而是 Agent 一边搜索、一边读文件、一边调工具、一边反复把大段上下文塞进去。
这块,才是真正的 token 黑洞。
Headroom 主要有几种用法。
你可以把它当成一个库,在 Python 或 TypeScript 项目里直接调用 `compress(messages)`。
你也可以把它当成代理,用 `headroom proxy --port 8787` 开一个本地代理,让请求先经过 Headroom,再发给模型服务。这个模式比较适合不想大改代码的人。
更骚的是,它还支持 Agent wrap。
README 里写了,可以用 `headroom wrap claude`、`headroom wrap codex`、`headroom wrap cursor` 这类方式,把 Claude Code、Codex、Cursor、Aider、Copilot CLI、OpenClaw 这些工具包起来。
也就是说,它盯上的不是普通聊天框。
它盯的是正在干活的 Agent。
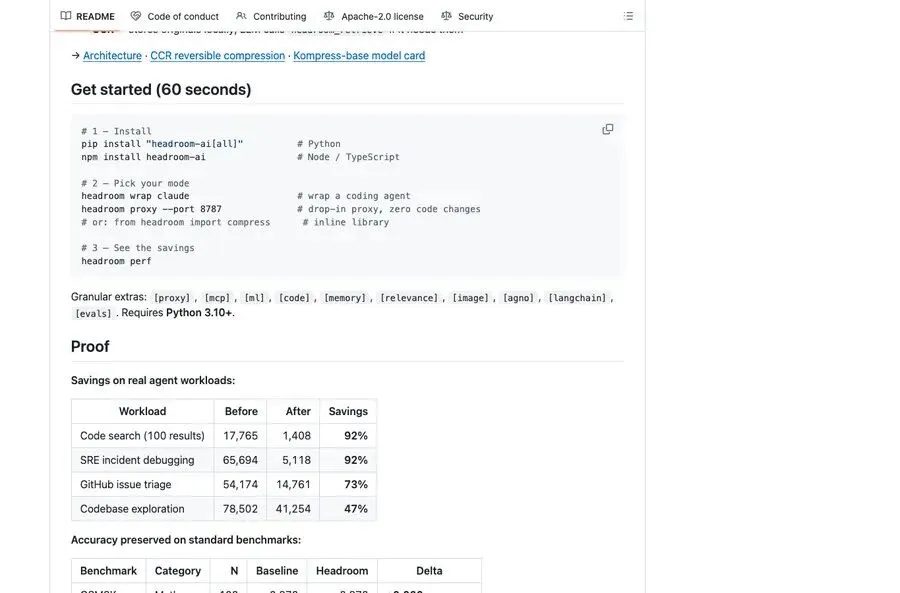
README 里放了一组真实 Agent 工作负载的测试。
代码搜索 100 个结果,从 17,765 token 压到 1,408,节省 92%。
SRE 事故调试,从 65,694 token 压到 5,118,也是 92%。
GitHub issue triage,从 54,174 token 压到 14,761,节省 73%。
代码库探索,从 78,502 token 压到 41,254,节省 47%。
我看到这里的感觉是,这玩意儿最适合的不是那种「你问一句,我答一句」的轻量场景。
它更像是给重度 AI 工作流准备的。
比如你让 Agent 去扫一个仓库,让它看一堆 issue,让它读几十个日志文件,让它基于 RAG 找资料。以前这些内容可能直接往模型里塞,现在 Headroom 先帮你筛一遍、压一遍、存一遍。
用人话讲,就是少让 AI 看废话。
我尽量不讲得太技术。
Headroom 里面有几个核心东西。
一个叫 ContentRouter,负责判断这段内容是什么类型。是 JSON、代码、普通文本,还是别的东西。
然后它会把不同内容交给不同压缩器,比如 SmartCrusher 处理 JSON,CodeCompressor 处理代码结构,Kompress-base 处理文本。
还有一个挺重要的设计,叫 CCR,可逆压缩。
意思是原始内容不会直接丢掉,而是存在本地。如果模型真的需要原文,可以再通过工具取回来。
这个设计我觉得比单纯压缩更靠谱。
因为最怕的不是压缩不够狠,而是压缩完把关键细节压没了。日志里那一行 FATAL,代码里那一个边界条件,issue 里那一句关键复现步骤,少了就全完了。
所以可逆这件事很重要。
它不是把信息烧掉,而是先折叠起来。
坦率地讲,如果你只是偶尔打开 ChatGPT 问两句话,这个工具大概率不是刚需。
你可能感觉不到它的价值。
但如果你是下面几类人,就很值得看。
第一类,经常用 Claude Code、Codex、Cursor 跑项目的人。你让 Agent 看代码库、读文件、分析报错,token 消耗会非常快。Headroom 这种工具能不能省钱另说,至少方向是对的。
第二类,做 RAG 或知识库的人。很多 RAG 项目最大的问题不是找不到资料,而是找回来的资料太脏、太长、太碎。先压缩再喂模型,是个很自然的思路。
第三类,经常处理日志、工单、issue、搜索结果的人。尤其是 SRE、开发、客服、产品调研这类场景,原始资料往往又长又乱,AI 直接吃很浪费。
第四类,AI 爱好者。你可能暂时用不上,但它代表了一个趋势,AI Agent 时代,大家不只会卷模型,也会卷上下文工程。
README 里的安装很简单。
Python 可以这样装。
pip install "headroom-ai[all]"Node / TypeScript 可以这样装。
npm install headroom-ai如果你想包一层 Claude Code,可以试试。
headroom wrap claude如果你想开一个本地代理,可以用。
headroom proxy --port 8787然后用 `headroom perf` 看节省情况。
当然,我还是那句话,别上来就把生产环境接进去。
先拿一个无关紧要的小项目测一下。比如丢一堆日志、丢几个搜索结果、丢一份长文档,看看压缩后回答质量有没有明显下降。
省 token 是好事。
但别为了省 token,把答案省傻了。
我一直觉得,AI Agent 现在有两个很现实的问题。
一个是看不见。
所以昨天那个 Agent-Reach 会火,因为它给 Agent 接外部信息源,让 AI 能读推特、看 B 站、搜小红书。
另一个是吃太多。
所以 Headroom 这种项目会火,因为它盯上了 Agent 干活时最容易失控的一件事,上下文越来越肥,token 越烧越快。
这两个项目放在一起看,其实很有意思。
一个负责让 AI 看到更多世界。
一个负责别让 AI 被世界撑死。
大时代啊,朋友们。
以前我们聊 AI,聊的是模型参数、推理能力、谁比谁聪明。现在慢慢开始聊输入源、上下文压缩、记忆层、工具调用、Agent 之间共享状态。
这说明一件事,AI 真的从玩具,开始往工作流走了。
工具越接近工作流,越不会只拼「聪明」。它还要便宜、稳定、可控、能回溯、能接上现有系统。
Headroom 就是这个方向里的一个小切口。
不一定完美,但值得收藏。
如果你问我,这个项目普通人要不要马上装。
我会说,不急。
如果你只是日常聊天,先收藏就行。
但如果你已经在用 Claude Code、Codex、Cursor 做项目,或者正在折腾 RAG、知识库、自动化 Agent,那这个项目值得认真看一下。
因为 token 这个东西,平时不显眼。
但真到重度使用的时候,它会变成成本,变成速度,变成上下文长度,变成一次任务到底能不能跑完。
AI 太费 token 这件事,未来一定会被越来越多人感受到。
Headroom 做的,就是在这个问题真正爆出来之前,先把压缩层放到桌面上。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧。
也欢迎把这篇收藏起来。
说不定哪天你的 AI 开始疯狂吃 token 的时候,就想起来它了。
GitHub 项目: https://github.com/chopratejas/headroom
官方文档: https://headroom-docs.vercel.app/docs
PyPI: https://pypi.org/project/headroom-ai/
npm: https://www.npmjs.com/package/headroom-ai
老湿提醒: 官方数据很好看,但实际节省比例要看你的资料类型和任务。先小项目测试,再接正式工作流。
