 夜雨聆风
夜雨聆风在构建真实的 AI 应用时,需要在不修改核心业务逻辑的情况下,为 AI 交互添加各种横切能力——例如记录每一次请求的日志用于调试分析、自动将对话历史注入上下文实现多轮聊天、对用户输入进行敏感词过滤以确保内容合规等。如果将这些逻辑一股脑地塞进业务代码,势必导致代码臃肿、难以维护、无法复用。
Spring AI 的 Advisors 机制,正是为了解决这些问题而设计的。它借鉴了 Spring AOP 和装饰器模式的设计思想,提供了一套可插拔、可组合的拦截器框架,让你能够在 AI 调用链中优雅地插入自定义逻辑。
7.1 什么是 Advisor
7.1.1 从 AOP 到 Advisor
Spring AOP 通过切面(Aspect)将日志、事务、安全等横切关注点从业务逻辑中剥离出来,实现了关注点的分离。Spring AI 的 Advisor 机制沿用了这一设计思想,并针对 AI 交互场景做了专门优化。
简单来说,Advisor 就是一个拦截器——在将请求发送给 AI 模型之前和执行模型返回之后,Advisor 都会有机会介入,对请求进行预处理或对响应进行后处理。
业务代码 → [Advisor 链] → AI 模型类似的拦截器设计在其他技术栈中也广泛存在。例如 Servlet 中的 Filter、Spring MVC 中的 Interceptor,以及 Spring AOP 的 @Around 通知——它们都基于责任链模式,允许在请求处理的前后插入自定义逻辑。
💡 类比理解:Advisor 之于 Spring AI,就像 Filter 之于 Servlet、Interceptor 之于 Spring MVC——都是横切关注点的优雅解决方案。
7.1.2 为什么需要 Advisor
在实际开发中,我们经常遇到以下需求:
记录日志:记录每次 AI 请求的输入和输出,便于调试和审计
对话记忆:将历史对话自动注入当前请求,实现多轮对话能力
内容安全:在请求发送前过滤敏感词,在响应返回前屏蔽不当内容
限流控制:防止 API 调用过于频繁导致费用超支
缓存处理:相同的问题直接返回缓存结果,减少 API 调用和成本
RAG 检索增强:在请求发送前从向量数据库检索相关文档并注入上下文
Spring AI 的 Advisor 机制就是为了统一应对这些横切需求而设计的。它让你可以:
解耦:将通用 AI 模式从业务逻辑中剥离
复用:一次编写,多处复用
组合:多个 Advisor 可按需组合,形成处理链
7.2 核心接口体系
7.2.1 Advisor 顶层接口
Spring AI 的 Advisor 接口设计遵循了清晰的分层结构,位于 org.springframework.ai.chat.client.advisor.api 包中。下面是完整的接口继承关系。
接口继承关系:
Advisor(顶层接口:定义 getName() 和 getOrder())
│
├── CallAdvisor(同步/非流式拦截器) ← 本章重点
│ │
│ └── CallAroundAdvisor(扩展:支持前置/后置处理,是 CallAdvisor 的增强形式)
│
└── StreamAdvisor(异步/流式拦截器)
│
└── StreamAroundAdvisor(扩展:支持流式场景的前置/后置处理)Advisor 是所有 Advisor 的基础接口,定义了两个核心方法:
publicinterfaceAdvisorextendsOrdered {
/**
* 返回顾问的唯一标识名称
*/
String getName();
// 继承自 Ordered,通过 getOrder() 控制执行顺序
}getName():返回顾问的唯一标识名称,便于调试和日志追踪getOrder():继承自Ordered接口,用于控制多个 Advisor 的执行顺序,数值越小优先级越高
⚠️ 关键提醒:所有自定义 Advisor 都必须实现
getName()方法,框架依赖这个标识进行顾问管理。
7.2.2 CallAdvisor(同步拦截器)
CallAdvisor 是最常用的 Advisor 接口,适用于普通的“发一条消息 → 等待完整回复”的同步调用场景。
publicinterfaceCallAdvisorextendsAdvisor {
/**
* 处理 AI 请求的核心方法
*
* @param request 客户端请求对象,包含 prompt、options 等数据
* @param chain 责任链对象,用于调用下一个 Advisor
* @return AI 响应结果
*/
ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain);
}adviseCall 方法是实现自定义逻辑的核心入口。它的参数包括当前请求对象和责任链对象——你的代码可以在调用 chain.nextCall(request)之前执行预处理(如修改 Prompt、添加上下文、记录时间戳等),在 chain.nextCall(request)返回之后执行后处理(如记录响应日志、计算耗时等)。
提示:在 Spring AI 的早期版本中,
CallAroundAdvisor接口提供了更丰富的生命周期方法(如before和after),但在较新的 API 设计中,推荐直接使用CallAdvisor并通过adviseCall方法实现完整的环绕增强逻辑。
7.3 运行机制
7.3.1 核心数据结构
在编写 Advisor 时有几个核心数据对象:
ChatClientRequest:请求对象,包含了准备发送给 AI 模型的 Prompt、参数配置(如 temperature、maxTokens)等信息。Advisor 可以读取并修改这个对象,例如在 Prompt 中添加额外的系统消息。ChatClientResponse:响应对象,包含了 AI 模型返回的结果。Advisor 可以对响应进行校验、过滤或补充信息。CallAdvisorChain:责任链对象,通过调用它的nextCall(request)方法将处理权移交给链条中的下一个 Advisor。
7.3.2 请求/响应处理链
Advisors 的执行遵循责任链模式。当多个 Advisor 被注册到 ChatClient 时,它们会形成一个栈式处理链(Stack-based Chain) ,这个机制和 Spring AOP 的环绕通知内部原理基本一致。
整个处理流程有两个阶段:
┌─────────────────────────────────────────────────────────────────┐
│ 请求阶段(请求从链顶流向链底) │
│ Advisor 1(order=1)→ Advisor 2(order=2)→ ... → AI 模型 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 响应阶段(响应从链底流回链顶) │
│ AI 模型 → ... → Advisor 2(order=2)→ Advisor 1(order=1) │
└─────────────────────────────────────────────────────────────────┘请求阶段:从链顶到链底,
order值越小的 Advisor 越先执行响应阶段:从链底到链顶,
order值越小的 Advisor 反而越后执行最后一个 Advisor:由框架自动添加,负责实际调用 LLM
这种栈式结构的一个重要特点是,请求阶段和响应阶段的执行顺序是相反的。例如,假设我们有三个 Advisor 按照 order 值 1→2→3 的顺序排列,那么请求阶段会依次经过 Advisor 1、Advisor 2、Advisor 3 后再到达 AI 模型;而当模型返回响应后,响应会先经过 Advisor 3 处理,再依次经过 Advisor 2、Advisor 1 后返回到业务代码。这种“先进后出”的顺序,让前后对称的逻辑(如记录请求时间并计算耗时)可以优雅地实现。
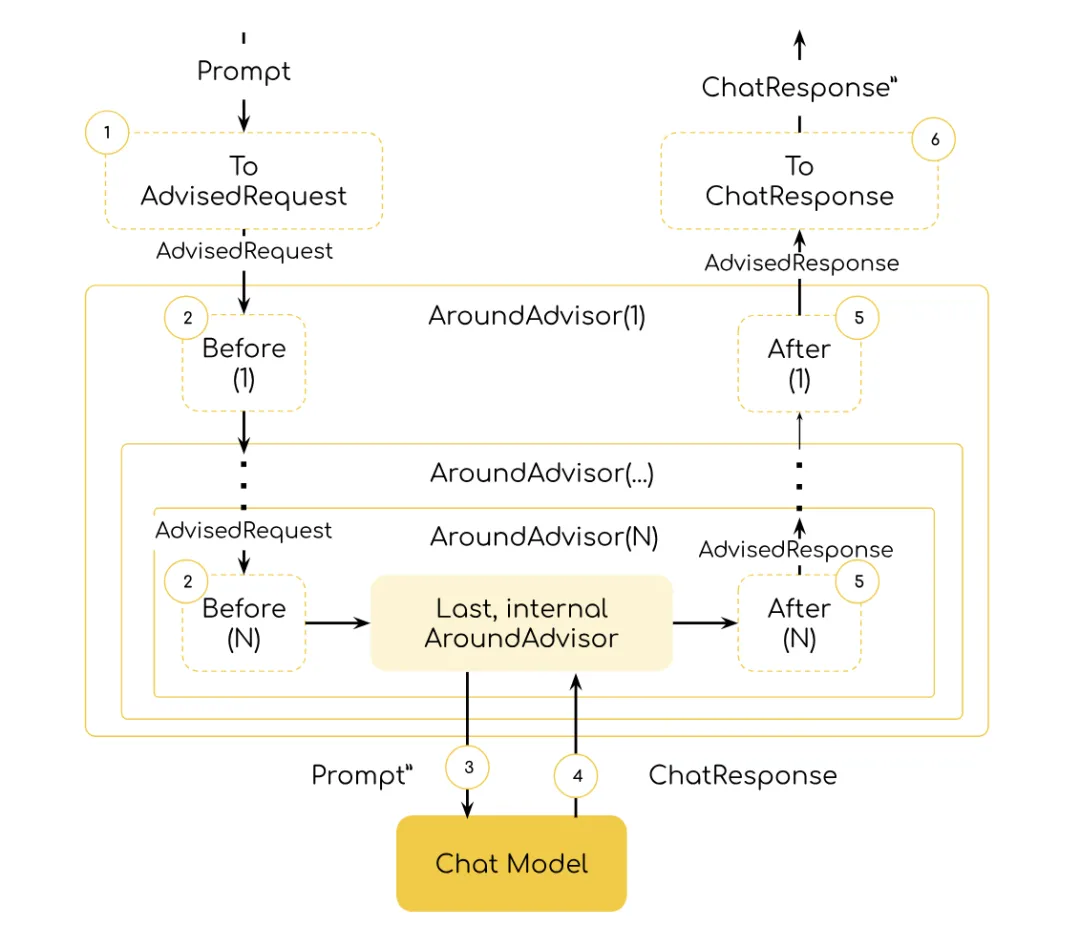
7.3.3 执行顺序实践
在真实项目中,通常需要同时使用多个 Advisor,例如同时启用日志记录、对话记忆和敏感词过滤。多个 Advisor 的执行顺序由 getOrder() 方法的返回值控制。
配置多个 Advisor:
@Configuration
publicclassAdvisorConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel) {
// 执行顺序:
// 1. 日志记录(order=100)→ 2. 记忆管理(order=200)→ 3. 敏感词过滤(order=300)→ AI 模型
return ChatClient.builder(chatModel)
.advisors(
newSimpleLoggerAdvisor(100), // order=100,最先执行
newMessageChatMemoryAdvisor(memory, "conv-123", 200), // order=200
newSensitiveWordAdvisor(300) // order=300,最后执行
)
.build();
}
}多个 Advisor 的执行顺序遵循以下规则:
数值越小,优先级越高,越先执行
**最后一个 Advisor(由框架自动添加)**负责调用 LLM 建议使用
Advisor.DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER等常量作为参考基准合法范围在
Integer.MIN_VALUE到Integer.MAX_VALUE之间
以下是执行顺序示例:
请求阶段:日志(100) → 记忆(200) → 敏感词(300) → AI 模型
响应阶段:AI 模型 → 敏感词(300) → 记忆(200) → 日志(100)⚠️ 关键要点:请求阶段的顺序和响应阶段的顺序正好相反。如果日志顾问先于敏感词顾问处理请求,那么在响应阶段,敏感词顾问会先于日志顾问处理响应——这也是为什么日志顾问能记录完整的响应内容。
执行顺序最佳实践:
内置的一些 order 常量参考:
Ordered.HIGHEST_PRECEDENCE | -2147483648 | |
Advisor.DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER | ||
Ordered.LOWEST_PRECEDENCE | 2147483647 |
7.4 Advisor分类
Spring AI 提供了一些内置的 Advisor,覆盖了日志记录、聊天记忆、RAG 检索等常见场景。
7.4.1 SimpleLoggerAdvisor:日志记录
SimpleLoggerAdvisor 是调试阶段的“利器”。它能够在每一次 AI 调用时,自动打印请求和响应的完整内容,帮助开发者快速了解 AI 模型的输入输出情况。
使用示例:
@RestController
@RequestMapping("/advisor")
publicclassAdvisorDemoController {
privatefinal ChatClient chatClient;
publicAdvisorDemoController(ChatClient.Builder builder) {
this.chatClient = builder
.defaultAdvisors(newSimpleLoggerAdvisor()) //添加日志
.build();
}
@GetMapping("/chat-with-log")
public String chat(@RequestParam String msg) {
return chatClient.prompt()
.user(msg)
.call()
.content();
}
}
调用接口后,控制台会输出类似以下的日志信息(需要将日志级别设置为 DEBUG):
2026-06-01T11:24:12.129+08:00 DEBUG 36908 --- [spring-ai-tutorial] [nio-8080-exec-2] o.s.a.c.c.advisor.SimpleLoggerAdvisor : request: ChatClientRequest[prompt=Prompt{messages=[UserMessage{content='你好', metadata={messageType=USER}, messageType=USER}], modelOptions=OpenAiChatOptions: {"streamUsage":false,"model":"qwen3.6-plus","temperature":0.7}}, context={}]
2026-06-01T11:24:17.344+08:00 DEBUG 36908 --- [spring-ai-tutorial] [nio-8080-exec-2] o.s.a.c.c.advisor.SimpleLoggerAdvisor : response: {
"result" : {
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"annotations" : [ { } ],
"index" : 0,
"id" : "chatcmpl-1d28f1fd-7c62-9731-b554-d2e68605ac39"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!有什么我可以帮你的吗?"
}
},
"metadata" : {
"id" : "chatcmpl-1d28f1fd-7c62-9731-b554-d2e68605ac39",
"model" : "qwen3.6-plus",
"rateLimit" : {
"requestsLimit" : null,
"requestsRemaining" : null,
"tokensLimit" : null,
"tokensRemaining" : null,
"requestsReset" : null,
"tokensReset" : null
},
"usage" : {
"promptTokens" : 11,
"completionTokens" : 212,
"totalTokens" : 223,
"nativeUsage" : {
"completion_tokens" : 212,
"prompt_tokens" : 11,
"total_tokens" : 223,
"prompt_tokens_details" : { },
"completion_tokens_details" : {
"reasoning_tokens" : 199
}
}
},
"promptMetadata" : [ ],
"empty" : false
},
"results" : [ {
"metadata" : {
"finishReason" : "STOP",
"contentFilters" : [ ],
"empty" : true
},
"output" : {
"messageType" : "ASSISTANT",
"metadata" : {
"role" : "ASSISTANT",
"messageType" : "ASSISTANT",
"finishReason" : "STOP",
"refusal" : "",
"annotations" : [ { } ],
"index" : 0,
"id" : "chatcmpl-1d28f1fd-7c62-9731-b554-d2e68605ac39"
},
"toolCalls" : [ ],
"media" : [ ],
"text" : "你好!有什么我可以帮你的吗?"
}
} ]
}一般以下场景可以使用:
开发阶段调试 Prompt 效果 生产环境审计请求/响应(注意数据脱敏) 排查 AI 调用异常问题
💡 提示:在生产环境中使用日志顾问时,应当注意对敏感信息(如用户个人信息)进行脱敏处理,避免日志泄露。
7.4.2 MessageChatMemoryAdvisor:对话记忆
默认情况下,AI 模型是无状态的——每次请求都是独立的,模型记不住你上一轮说了什么。MessageChatMemoryAdvisor 解决了这个问题,它能够自动保存和加载对话历史,并将历史消息以独立消息的形式插入到当前请求的 Prompt 中。
基本使用:
@RestController
@RequestMapping("/advisor")
publicclassAdvisorDemoController {
privatefinal ChatClient chatClient;
publicAdvisorDemoController(ChatClient.Builder builder) {
// 创建内存存储仓库
InMemoryChatMemoryRepositoryrepository=newInMemoryChatMemoryRepository();
// 创建基于消息窗口的记忆实现,设置保留最近10条消息
ChatMemorychatMemory= MessageWindowChatMemory.builder()
.maxMessages(5) // 保留最近5条消息
.chatMemoryRepository(repository)
.build();
// 创建记忆顾问,指定记忆模块
MessageChatMemoryAdvisormemoryAdvisor= MessageChatMemoryAdvisor.builder(chatMemory)
.build();
this.chatClient = builder
.defaultAdvisors(newSimpleLoggerAdvisor(), memoryAdvisor) // 添加日志顾问和记忆顾问
.build();
}
@GetMapping("/chat-with-memory")
public String chatWithMemory(@RequestParam String msg,
@RequestParam(required = false, defaultValue = "user001") String sessionId) {
return chatClient.prompt()
.user(msg)
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, sessionId)) // 动态添加sessionId
.call()
.content();
}关键对象:
然后我们在使用时,注意动态的绑定用户的sessionId,从而将不同用户数据分开。
7.4.3 其他常用 Advisor
还有一些其他的可以参考
QuestionAnswerAdvisor | ||
SafeGuardAdvisor | ||
ToolCallAdvisor | ||
VectorStoreChatMemoryAdvisor |
7.4.4 自定义 Advisor
当内置 Advisor 无法满足需求时,还可以开发自己的 Advisor。比如以敏感词过滤为例,实现一个完整的自定义 Advisor。
实现一个自定义 Advisor 只需要三步:
创建类实现
CallAdvisor接口重写
getName()和getOrder()方法在
adviseCall方法中实现前置/后置逻辑
完整代码示例:
package com.springai.guide.advisor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.CallAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.core.Ordered;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.Generation;
import org.springframework.ai.chat.prompt.Prompt;
import java.util.List;
import java.util.stream.Collectors;
/**
* 敏感词过滤顾问
* 在请求发送前检查用户输入,若包含敏感词则阻止请求;在响应返回后检查模型输出,若包含敏感词则脱敏处理。
*/
publicclassSensitiveWordAdvisorimplementsCallAdvisor {
privatestaticfinalLoggerlog= LoggerFactory.getLogger(SensitiveWordAdvisor.class);
// 敏感词列表(实际使用时可以从配置中心或数据库动态加载)
privatestaticfinal List<String> SENSITIVE_WORDS = List.of("密码", "信用卡号", "身份证号");
// 脱敏字符
privatestaticfinalStringMASK="***";
// 执行顺序,值越小越靠前
privateintorder= Ordered.HIGHEST_PRECEDENCE + 100;
publicSensitiveWordAdvisor() {}
publicSensitiveWordAdvisor(int order) {
this.order = order;
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
// ========== 前置处理:检查用户输入 ==========
StringuserInput= extractUserText(request);
// 检查是否包含敏感词
StringfoundWord= containsSensitiveWord(userInput);
if (foundWord != null) {
log.warn("敏感词过滤: 检测到敏感词 [{}], 请求被阻止", foundWord);
// 直接抛出异常或返回空响应来阻止请求
thrownewIllegalArgumentException("输入包含敏感信息: " + foundWord + ", 请修改后重试");
}
// ========== 调用下一个顾问(最终到达 AI 模型) ==========
ChatClientResponseresponse= chain.nextCall(request);
// ========== 后置处理:对模型输出进行脱敏检查和记录 ==========
StringaiResponse= extractContentFromResponse(response);
StringsafeResponse= maskSensitiveWords(aiResponse);
if (!safeResponse.equals(aiResponse)) {
log.info("敏感词过滤: 检测到响应中包含敏感词");
log.debug("原始响应: {}", aiResponse);
log.debug("脱敏后响应: {}", safeResponse);
}
return response;
}
/**
* 检查文本是否包含敏感词,返回第一个匹配的敏感词
*/
private String containsSensitiveWord(String text) {
return SENSITIVE_WORDS.stream()
.filter(text::contains)
.findFirst()
.orElse(null);
}
/**
* 从 ChatClientResponse 中提取响应内容
*/
private String extractContentFromResponse(ChatClientResponse response) {
ChatResponsechatResponse= response.chatResponse();
if (chatResponse != null && !chatResponse.getResults().isEmpty()) {
return chatResponse.getResults().getFirst().getOutput().getText();
}
return"";
}
/**
* 对文本中的敏感词进行脱敏
*/
private String maskSensitiveWords(String text) {
Stringresult= text;
for (String word : SENSITIVE_WORDS) {
result = result.replace(word, MASK);
}
return result;
}
/**
* 从 ChatClientRequest 中提取用户输入文本
*/
private String extractUserText(ChatClientRequest request) {
Promptprompt= request.prompt();
// 从 Prompt 中获取 UserMessage 并拼接文本
return prompt.getInstructions().stream()
.filter(msg -> msg instanceof UserMessage)
.map(msg -> ((UserMessage) msg).getText())
.collect(Collectors.joining(" "));
}
@Override
public String getName() {
return"sensitiveWordAdvisor";
}
@Override
publicintgetOrder() {
returnthis.order;
}
}关键部分包括:
前置处理:
extractUserText()从请求中提取用户输入,调用containsSensitiveWord()检查是否包含敏感词。如果匹配,立即返回错误响应,阻止后续调用链。链接调用:
chain.nextCall(request)是责任链的精髓,它将请求传递给下一个 Advisor。如果这是链条中的最后一个 Advisor,框架会负责调用 AI 模型。后置处理:AI 模型返回响应后,调用
maskSensitiveWords()对输出内容中的敏感词进行脱敏处理,然后构建新的响应对象返回。
7.5 实战:构建带完整增强的智能问答
将本章内容整合起来,做一个综合示例:一个同时具备日志记录、对话记忆和敏感词过滤能力的智能问答接口。
完整代码实现:
@RestController
@RequestMapping("/api/advisor-demo")
publicclassAdvisorCompleteDemoController {
privatefinal ChatClient chatClient;
publicAdvisorDemoController(ChatClient.Builder builder) {
// 创建内存存储仓库
InMemoryChatMemoryRepositoryrepository=newInMemoryChatMemoryRepository();
// 创建基于消息窗口的记忆实现,设置保留最近10条消息
ChatMemorychatMemory= MessageWindowChatMemory.builder()
.maxMessages(5) // 保留最近5条消息
.chatMemoryRepository(repository)
.build();
// 创建记忆顾问,指定记忆模块
MessageChatMemoryAdvisormemoryAdvisor= MessageChatMemoryAdvisor.builder(chatMemory)
.order(200)
.build();
this.chatClient = builder
// 执行顺序:日志(100) → 记忆(200) → 敏感词(300) → AI 模型
.defaultAdvisors(newSimpleLoggerAdvisor(100), memoryAdvisor, newSensitiveWordAdvisor(300)) // 添加日志顾问和记忆顾问
.build();
}
@GetMapping("/chat")
public ResponseEntity<ApiResponse<String>> chat(@RequestParam String msg) {
longstartTime= System.currentTimeMillis();
try {
Stringresponse= chatClient.prompt()
.user(msg)
.call()
.content();
longduration= System.currentTimeMillis() - startTime;
return ResponseEntity.ok(ApiResponse.success(response, duration));
} catch (Exception e) {
// 敏感词过滤等场景可能抛出异常
return ResponseEntity.badRequest()
.body(ApiResponse.error(e.getMessage()));
}
}
}响应封装改为:
// ========== 响应封装 ==========
publicrecordApiResponse<T>(
int code,
String message,
T data,
long timestamp,
long duration
) {
publicstatic <T> ApiResponse<T> success(T data) {
returnnewApiResponse<>(200, "success", data, System.currentTimeMillis(), 0);
}
publicstatic <T> ApiResponse<T> error(String message) {
returnnewApiResponse<>(500, message, null, System.currentTimeMillis(), 0);
}
publicstatic <T> ApiResponse<T> success(T data, long duration) {
returnnewApiResponse<>(200, "success", data, System.currentTimeMillis(), duration);
}
publicstatic <T> ApiResponse<T> error(int code, String message) {
returnnewApiResponse<>(code, message, null, System.currentTimeMillis(), 0);
}
}测试效果如下:
# 正常问答
curl "http://localhost:8080/api/advisor-demo/chat?msg=你好,请介绍一下Spring"
# 正常返回
# 测试敏感词过滤
curl "http://localhost:8080/api/advisor-demo/chat?msg=我的密码是123456"
# 返回:输入包含敏感信息,请修改后重试
# 测试记忆能力
curl "http://localhost:8080/api/advisor-demo/chat?msg=我叫张三"
curl "http://localhost:8080/api/advisor-demo/chat?msg=我叫什么名字?"
# AI 能够记住之前输入的名字7.6 常见误区与最佳实践
7.6.1 ❌ 误区一:忘记调用 chain.nextCall()
自定义的Advisor没有调用 chain.nextCall()
// ❌ 错误示例
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
preProcess(request);
return ChatClientResponse.from(...).build(); // 没有调用 chain.nextCall(),后续Advisor和 AI 模型都不会执行!
}✅正确做法:必须调用 chain.nextCall(request),并返回其响应结果:
public ChatClientResponse adviseCall(ChatClientRequest request, CallAdvisorChain chain) {
request = preProcess(request); // 前置处理
ChatClientResponseresponse= chain.nextCall(request); // 必须调用!
return postProcess(response); // 后置处理
}7.6.2 ✅ 最佳实践速查表
| 单一职责 | 每个<font style="color:rgb(1, 1, 1);">Advisor</font> 只干一件事(比如只记录日志,或只处理记忆),不要在一个 Advisor 里写几千行代码。 |
| order 取值 | |
| 响应修改 | ChatClientResponse.from(response).content(newContent).build() 构建新响应对象 |
| 请求阻止 | chain.nextCall() |
| 会话隔离 | conversationId,不同用户使用不同 ID |
| 调试辅助 | Advisor 的 getName() 返回有意义的标识,便于日志定位 |
| 数据共享 | AdvisorContext 在多个 Advisor 之间传递数据(例如:请求 ID、权限信息等) |
| 性能考量 | AdvisorContext 中,供下游顾问复用 |
| 异常处理 |
7.7 本章小结
在本章中,我们全面深入地学习了 Spring AI 的 Advisor 机制:
核心概念:Advisor 是基于责任链模式的拦截器框架,用于为 AI 交互添加横切关注点,类似于 Spring AOP 但专为 AI 场景优化
工作原理:形成栈式处理链,请求阶段从高优先级到低优先级执行,响应阶段顺序相反
接口体系:
Advisor(顶层)→CallAdvisor(同步拦截,最常用)→ 自定义实现内置 Advisor:
SimpleLoggerAdvisor:自动打印请求和响应日志MessageChatMemoryAdvisor:自动管理多轮对话历史(必须显式指定 conversationId)QuestionAnswerAdvisor、SafeGuardAdvisor、ToolCallAdvisor等自定义开发:实现
CallAdvisor接口,在adviseCall中编写前/后置逻辑综合实战:构建了集日志、记忆、敏感词过滤于一体的完整示例
Advisor 机制的强大之处在于它的可插拔性和可组合性。你可以在项目中灵活组合官方提供的 Advisor,也可以自定义实现符合业务需求的专属Advisor。掌握了 Advisor 机制,你将能够构建更加健壮、功能丰富的 AI 应用。
下一章,将系统学习 Spring AI 的聊天记忆机制——包括记忆存储策略、记忆窗口管理以及如何将记忆持久化到数据库。
参考来源
Spring AI 官方文档:Advisors Framework Supercharging Your AI Applications with Spring AI Advisors
