 夜雨聆风
夜雨聆风我们都在聊 AI,聊 Agent,聊 RAG。但一个事实被忽略:AI 吃得进的数据,远远不够。
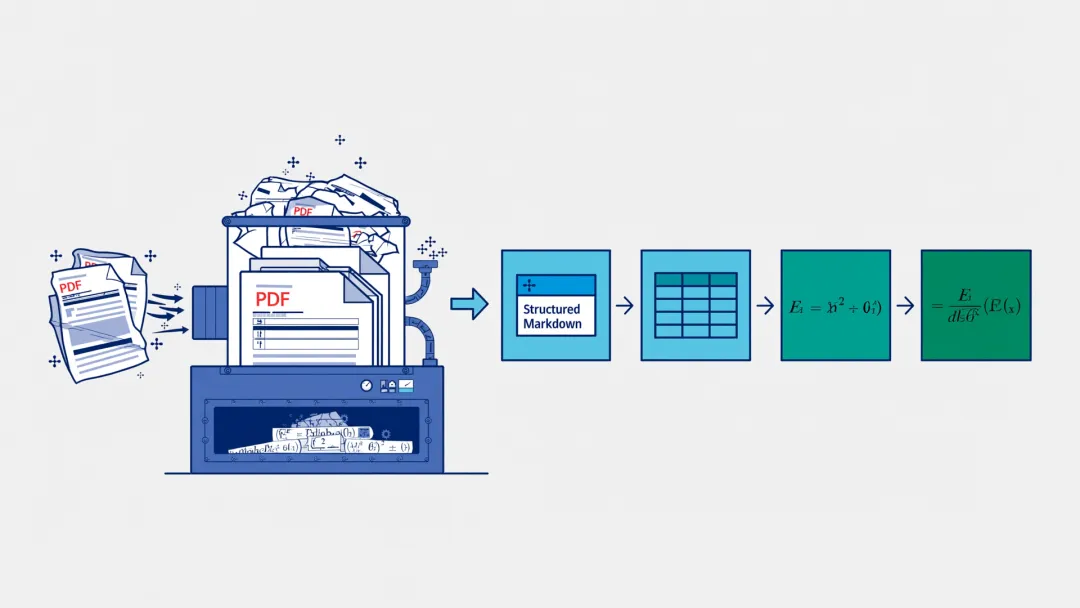
你的 PDF 合同、扫描版论文、带表格的财务报表——这些不是机器 readable 的数据。它们需要被"翻译"。
MinerU 做的事,就是翻译。
OpenDataLab 开源的项目,GitHub 星标近 3 万。上线八个月,增长速度在这个领域里不算普通。
它能把 PDF、Word、PPT、Excel、图片、网页 URL——一键解析为 Markdown 和 JSON。
表格还原成 CSV/HTML。公式转成 LaTeX。脚注、参考文献、多栏排版——全部保留上下文关联。
这是 RAG 数据准备环节,最省力的解法。
为什么 MinerU 不一样
市面上 OCR 工具不少。但大多数只做一件事:把图片变成文字。
MinerU 做的不是 OCR。它做的是文档结构理解。
先看布局。识别标题、段落、表格、图片区域的位置。再对每个区域做针对性处理。
文本区域——直接提取或 OCR。表格区域——结构化还原。公式区域—— LaTeX 输出。
这套流程叫 pipeline 后端,基于 DocLayoutYOLO 布局检测 + PaddleOCR 的组合。
传统 OCR 是盲人摸象。MinerU 先看全局,再局部处理。
两种后端,怎么选
MinerU 支持两种解析后端:
Pipeline 后端——传统 CV 规则 + OCR 引擎组合。2-5 秒/页,支持批量并行,GPU 6GB 就能跑。适合扫描件、常规文档。性价比最高。
VLM 后端——视觉语言模型。0.5-1 秒/页,sglang 加速 20-30 倍。适合学术论文、古籍、杂志、复杂多栏排版。语义理解能力更强。
怎么选?
扫描件、常规文档 → Pipeline。
高度复杂的学术论文、古籍 → VLM。
对格式还原精度要求极高(存档、出版)→ VLM。
如果你不确定,先试 Pipeline。不够再换 VLM。

三种使用方式
MinerU 提供了三种入口,覆盖不同场景:
1. 开源部署(免费)
git clone https://github.com/opendatalab/MinerU.git
cd MinerU
uv pip install -e .[core]支持 Windows、Linux、Mac。CPU 8GB 内存就能跑。GPU 推荐 6GB+ 显存。
安装完,命令行一行指令就能解析文档。
2. 桌面客户端(无编程)
官网下载客户端,安装后拖放文件,或者输入 URL,点击确认。
图形界面,无需编程,无需登录。
适合不想折腾命令行的人。
3. 在线 API(批量处理)
官网 https://mineru.net 提供 API 服务。填写问卷申请通过后免费试用。
支持 URL 和本地文件的批量解析。算力调度持续优化,多并发大量文档处理更高效。
适合企业场景、自动化流水线。
具体场景举例
场景一:RAG 数据准备
你有一个知识库,里面 500 份 PDF 文档。传统做法:人工提取、手动整理、格式不统一。
MinerU 批量解析,统一输出 Markdown。表格、公式自动处理。直接接入 RAG 数据处理流。
省的时间,比你自己算的要多。
场景二:化学论文提取
MinerU 支持化学论文解析。分子检测识别、化学反应提取、全局分子关联。
输出结构化数据,为科研类 Agent 和数理大模型提供标准输入。
这不是通用 OCR 能做到的。
场景三:Agent 接入
MinerU 原生支持 MCP 协议、OpenClaw 等主流 Agent 框架。
加入开源社区,共建 Agent Skills 与 MCP 插件生态。
文档解析不再是 Agent 的前置门槛。
几个关键判断
MinerU 不是 OCR 工具,是文档解析引擎。
这个区别很重要。OCR 只提取文字。MinerU 提取文字 + 结构 + 语义关联。
开源免费部署,在线 API 免费试用。
这个组合在国内开源工具里不算常见。既有自部署方案,又有云端方案。
GitHub 星标近 3 万,八个月增长。
这个数字说明两件事:需求真实,产品匹配需求。
用 MinerU 之前,先想清楚
你处理什么类型的文档?
扫描件?常规 PDF?学术论文?化学论文?
不同类型,选不同后端。
你有多少文档需要处理?
几十份?几百份?上千份?
不同数量,选不同入口。
命令行?客户端?API?
先想清楚这两个问题,再动手。
结论
大模型时代,数据准备比模型训练更耗时间。
MinerU 解决的是数据准备环节中最难的部分——复杂文档解析。
开源、免费、多入口。Pipeline 后端性价比高,VLM 后端精度更强。
如果你在做 RAG、Agent、知识库——MinerU 值得试。
试了再决定要不要深入。不需要犹豫。
