 夜雨聆风
夜雨聆风别再把 AI 当搜索框了:1 小时搭出行业操作系统,再把它封装成自己的 Skill
我越来越确定一件事。
大多数人虽然已经开始用 AI 了,但用法其实还停留在上一代。
问一个问题。
拿一个答案。
当下觉得很有启发。
过几天再遇到类似问题,再重新问一遍。
这样当然也有帮助。
但它解决的,本质上只是一次性的「信息获取」,并不能帮你积累真正可复用的认知资产。
今天这个时代,真正稀缺的不是信息。
信息早就过剩了。
真正稀缺的是:你能不能把零散的信息,整理成一套自己以后还能继续调用、继续扩展、继续自动更新的结构。
很多人进入一个新行业的方式,其实都差不多:搜一堆链接,看几篇报告,刷几个大号,收藏几十篇文章。忙了三天,感觉自己看了很多,但脑子里还是糊的。头部玩家是谁,不清楚。谁在赚钱,不清楚。产业链怎么跑,不清楚。真正的机会在哪,也不清楚。
问题不在于你不够勤奋。
问题在于,这套工作方式从一开始就没有设计成「会沉淀资产」的样子。
放在以前,这件事通常要一个研究员花几周时间慢慢拆。
但现在不一样了。
你手里那个 AI 编程工具,不管是 Codex、Claude Code,还是别的 agent,本质上都不只是一个会回答问题的聊天框。用对了,它更像一个不会下班的行业研究员、知识库维护员、情报分析员。
而且我觉得,这恰恰是它最被低估的能力。

下面这套方法,是我现在进入任何陌生行业时,都会先跑一遍的底层流程。需要的东西很简单:一个能联网、能写文件、能持续执行任务的 AI agent,加一个 Obsidian 当仓库。
第一步:别急着问结论,先让它把骨架搭出来
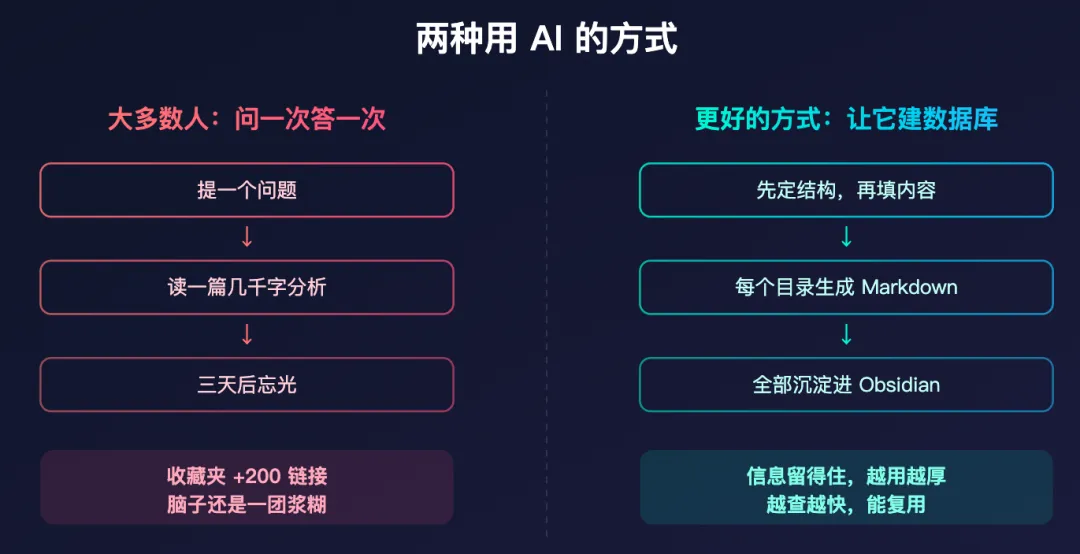
大多数人一上来就问结论。
比如你想了解美国减肥补充剂行业,就直接问:「这个行业怎么样?」「现在值不值得做?」AI 很快就能给你一篇几千字分析。你看完当下会很爽,觉得自己好像懂了。
但这种懂,往往只是一种短暂的错觉。
因为你拿到的是一块一块的信息切片,而不是一个能长期复用的结构。你只能靠大脑临时记住它。过几天,一散就没了。
所以我现在会反过来:先不让它下结论,而是先让它建数据库。
我通常会直接丢一句:
帮我建立一个「美国减肥补充剂行业」数据库。先输出完整目录结构,再为每个目录创建对应的 Markdown 文件,全部适合导入 Obsidian。
它先做的,不是分析,而是搭一棵树。比如:
Weight-Loss-Supplement/├── 品牌├── 产品├── 关键词├── 社区├── 红人├── 竞品├── 商业模式├── 供应链├── 政策法规├── 趋势
这一步特别重要。
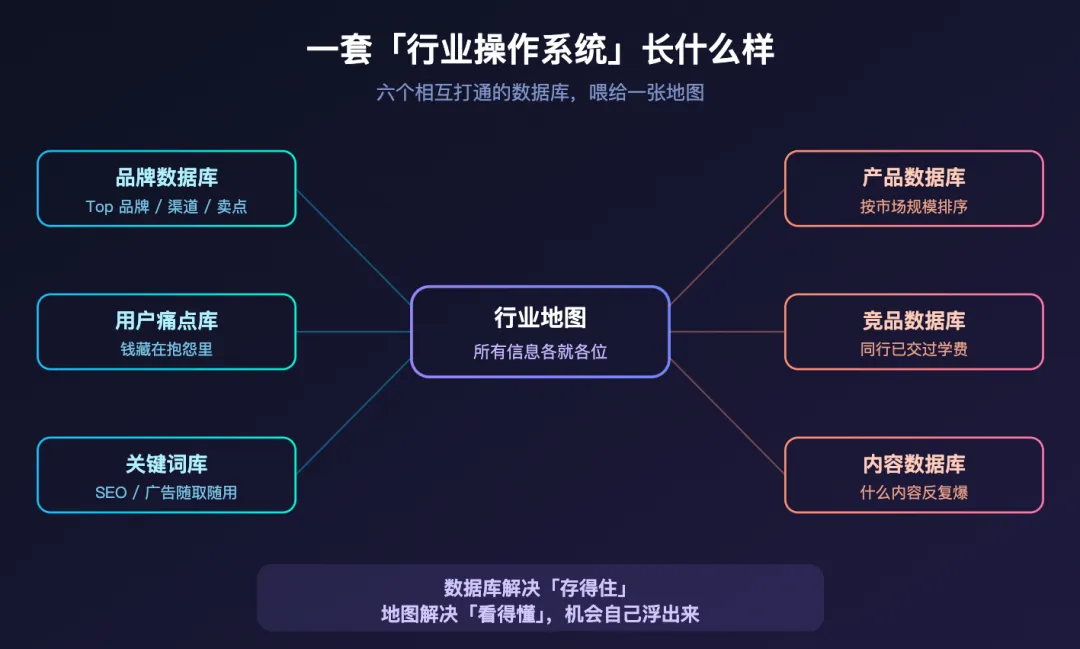
因为你其实是在给整个行业建一套「信息索引」。只要骨架立住,后面的信息就不再是乱飞的碎片,而是都有地方可挂。
接下来怎么填?
先填品牌。
让它去整理头部品牌,统一字段:品牌名、官网、主打产品、价格带、渠道、体量、核心卖点、创始人背景、社媒账号。这样以后你遇到一个新品牌,不是临时去搜,而是直接往已有结构里补。
再填产品。
让它按市场规模给产品类型排个序,比如 Fat Burner、食欲抑制、GLP-1 辅助、代谢加速、纤维类、肠道健康。然后每一类继续往下拆:成分、用户评价、优点、缺点、爆款品牌、市场空间。拆到这里,AI 才算真正开始理解这个行业的供给侧。
再填痛点。
这一块往往最值钱。
因为用户的钱,很多时候就藏在抱怨里。你让它去扒 Reddit、社区评论、平台讨论,把高频抱怨、高频需求、高频疑问、用户目标都归出来。像「减肥反弹」「没效果」「副作用大」「太贵」「很难坚持」这种,一旦整理出来,很多机会其实已经摆在桌面上了。
最后填关键词。
这一步特别容易被忽略,但后面做 SEO、内容、广告都会用到。让它把 Google、Amazon、Reddit、YouTube、TikTok 上的关键词捞回来,分成商业词、信息词、对比词、测评词、购买意图词。以后你做内容和投放,不是重新想,而是直接调用。
跑完这一轮之后,你原来脑子里那团模糊的印象,才第一次开始长成系统。
我现在越来越喜欢用一句话来概括这一步:
数据库解决「存得住」,地图解决「看得懂」,流程解决「能复用」。
这三件事,缺一不可。
第二步:不要猜行业怎么赚钱,直接拆已经赚到钱的人
很多人进入新行业以后,第一反应是找产品、找供应链、找素材、找流量入口,从零开始摸。
但更快的方式,往往不是自己重新摸,而是先看那些已经跑通的人到底怎么跑的。
说白了,同行已经替你交过学费了。
你不需要再完整重演一遍摸索过程。你真正要做的,是把他们的增长路径、转化路径、内容路径拆出来。
如果你研究的是 Shopify 独立站,我一般会直接把头部品牌的网址丢给 AI:
分析这个 Shopify 站,输出导航结构、产品分类、Collection 结构、商品标签体系、Footer、Blog 结构、SEO 结构、Landing Page 结构,并整理成 Markdown 报告。
很多人觉得这类分析很细碎。
但真正有价值的,恰恰就是这些细节。
导航栏很重要。
因为导航栏不是装饰,它通常就是老板脑子里的经营顺序。用户先进来看什么、再看什么、最后被推向什么,这里面常常藏着利润款、引流款和转化款的排序逻辑。
Collection 也很重要。
因为 Collection 往往比单个产品更能反映成交路径。你把几个头部品牌的 Collection 摆在一起,会发现很多结构非常相似。相似不是巧合,而是因为这些路径已经被验证过。
商品标签更值得看。
这个地方很多人根本不会碰,但价值极高。标签其实是在告诉你:用户是怎么搜索的,平台是怎么理解产品的,推荐系统是怎么组织和分发内容的。你如果把足够多商品标签整理出来,其实拿到的是一个行业级标签体系。
SEO 结构也一样。
很多人做 SEO,上来先写文章。其实顺序经常反了。应该先研究头部玩家在写什么。把他们的标题和选题结构归一遍,你会很快发现:真正能带流量的主题,高度集中;真正能带订单的词,也高度集中。
把几个竞品拆完之后,你看到的就不再是某一家公司的运营方式,而是整个行业的一套赚钱结构。
很多人都知道「要研究竞品」,但大多数人没有真的把竞品研究变成结构化资产。
差别就在这里。
第三步:把内容也当成数据库,而不是当成灵感池
很多人研究行业时,还是更习惯盯产品、盯供应链、盯网站、盯广告。
但今天这个时代,内容本身就是供给系统的一部分。
流量决定订单。
内容决定流量。
而内容结构,决定了流量能不能稳定复现。
所以进入一个行业之后,我一定会做的一件事,就是建内容库。
关键不是研究一个账号,而是一次性研究足够多账号。
如果你只是盯着几个大 V 刷,每天看,看半年,最后大概率也只是形成一些模糊印象。你会觉得某些内容好像总在爆,但你说不清到底是什么在重复发生。
真正有效的做法,是让 AI 一次性整理一大批账号。比如 YouTube、X、TikTok、Instagram、Newsletter 各抓一批,统一整理出:账号名、粉丝量、更新频率、主内容方向、变现方式。
然后继续往下拆:最近 90 天点赞最高的、评论最高的、转发最高的、播放最高的内容各是什么。
这时候你会发现一个特别有意思的现象:
爆款往往不是随机事件,而是重复结构。
同样的选题会反复爆。
同样的内容框架会反复爆。
同样的标题模式会反复爆。
一次爆,可能是运气。
十次爆,大概率就是规律。
但光统计还不够。
更重要的一步,是给内容分类。
我自己一般会分成五类:
- 曝光型内容
:观点强、争议大、容易传播,适合抢注意力。 - 涨粉型内容
:清单型、资源型、推荐型,适合建立“以后还值得关注”的预期。 - 收藏型内容
:SOP、模板、工作流、步骤拆解,生命周期长。 - 转化型内容
:结果展示、案例展示、收益展示,不一定最爆,但最接近变现。 - 人设型内容
:故事、经历、踩坑、复盘,让用户记住你这个人。
你一旦按这个方式去看内容,就会慢慢从「刷内容的人」变成「研究内容结构的人」。
这两者看上去只差一点点,结果差得非常远。
第四步:把数据库往上提一层,长成知识地图
很多人学不会一个行业,不是因为信息太少,而是因为信息太多。
今天一个新工具,明天一个新案例,后天一个新模型。收藏夹越来越大,脑子越来越乱。因为这些信息彼此之间没有位置,也没有连接。
数据库只能解决存储。
真正解决理解的,是地图。
也就是说,你得让 AI 帮你把一个行业画成一张能解释结构的图。
比如你研究 AI 行业,不应该只是一串工具清单,而应该先长成这样:
AI/├── 基础模型├── 编程├── Agent├── 工作流├── 视频├── 语音├── 搜索├── 基建 / GPU
这张图一旦出来,很多原本看起来毫不相关的产品,就有了位置。
接着再往下拆。
Agent 可以继续拆成记忆、规划、工具调用、RAG、评估、多智能体。
编程 可以继续拆成 Cursor、Claude Code、Codex、Cline 等具体方向。
你拆到第二层、第三层,才会真正开始看懂:这些产品为什么存在,解决什么问题,属于哪个赛道,未来会往哪里走。
然后再给每个节点建立知识卡片:overview、公司、工具、趋势、机会。
以后你研究到一个新东西,不再是随手收藏,而是直接挂到对应节点下面。
这一步带来的变化非常大。
因为从这一刻开始,你不是在积累「知识点」,而是在建立「知识坐标系」。
更进一步,当地图建起来以后,你还可以让 AI 基于这张图继续扫描:哪些领域竞争最激烈,哪些领域增长最快,哪些领域内容供给不足,哪些地方有创业机会。
到这里,你研究的已经不是信息,也不是知识点,而是机会分布。
第五步:把一次性调研,改造成持续进化的情报系统
如果你只做前面四步,其实已经很厉害了。
但还不够。
因为行业是会持续变化的。
今天有效的信息,三个月后可能已经过时;今天的头部账号,半年后可能没了;今天的热门产品,一年后可能已经没人买。
所以真正重要的,不是建出一个静态资料夹,而是让这套库自己长大。
这里最关键的一步,是把工作方式从搜索模式切到订阅模式。
搜索模式是:有问题再去搜,搜完关闭,下次重来。
订阅模式是:先把信息源建立起来,让新信息持续进入数据库,再自动归类、自动汇总、自动沉淀。
所以我现在进入任何行业,第一件事不是急着看内容,而是先问:这个行业的核心信息源到底有哪些?
比如:
哪些 YouTube 频道最值得盯 哪些 X 账号最值得盯 哪些 Newsletter 最值得订 哪些 Reddit 社区最值得跟 哪些 Blog 最值得长期看
把这些源头整理好之后,后面很多事情就可以自动化了。
比如让它:
每周统计竞品新增了哪些产品、页面、关键词、博客内容。 每天整理哪些内容涨得最快,自动归档到趋势库。 每周输出一份行业周报,汇总产品变化、爆款内容、融资动态、趋势信号。 定期更新行业地图,把新节点、新机会补进去。
做到这一步,你的 Obsidian 就不再是一个堆笔记的地方,而是一套真正活着的情报系统。
大多数人获取信息的路径是:搜索 → 阅读 → 遗忘。
而你建起来的路径是:信息源 → 数据库 → 地图 → 情报系统 → 机会发现。
这才是我觉得 AI 编程工具最被低估的一面。
它不只是帮你快一点,而是帮你把一次性的输入,变成长期复利的认知资产。
真正拉开差距的一步:把整套流程,封装成你自己的 Skill
讲到这里,前面的思路其实已经完整了。
但如果只做到这一步,每进入一个新行业,你还是得重新敲一大串指令:帮我建库、帮我输出目录、帮我建 Markdown、帮我整理竞品……
一次两次没问题。
十次之后,你一定会烦。
所以我觉得真正拉开差距的一步,不只是会用这些工具,而是:把你最常重复的流程,封装成你自己的 Skill。
以后不用再打一大串 prompt。
一句 /industry-db 减肥补充剂,整套流程就能跑起来。

这件事听上去很像高级玩法,但实际上比很多人想象得简单。
一个 Skill,本质上就是一个文件夹,里面放一个核心说明文件。
最常见的结构大概是这样:
212223industry-db/├── SKILL.md├── scripts/
其中真正必须的,通常只有 SKILL.md。
放哪儿呢?
如果你用 Claude Code,一般放在 ~/.claude/skills/,或者项目里的.claude/skills/。如果你用 Codex,一般放在 ~/.agents/skills/,有些环境也兼容~/.codex/skills/。
更重要的是:SKILL.md 已经不只是某一个工具私有的小功能,而是跨工具的开放标准。 这意味着你写出来的很多能力,不一定只能绑定在某一家工具上。
SKILL.md 里,最关键的其实就两件事
它本质上是一个带 frontmatter 的 Markdown。
最小版本可以写成这样:
# Industry Database Skill当用户给你一个行业名时,按下面步骤执行:1. 输出完整目录结构。2. 创建对应 Markdown 文件,适合导入 Obsidian。3. 至少包含:品牌、产品、痛点、关键词、竞品、内容、趋势、机会。4. 所有结论都附来源链接。
你会发现,它并不复杂。
真正关键的,主要就两个字段:
name:对应你以后要触发它的命令名。 description:这是整个 Skill 最值钱的部分,它决定 AI 在什么场景下会自动想起该调用它。
换句话说,description 不是可有可无的简介,而更像一段「调用说明」。
你写得越清楚,AI 越知道什么时候该用它。
而 --- 下面的正文,其实就是把你原来每次都要重打一遍的长 prompt,正式固化成了一套可长期复用的工作流说明。
原来你是在反复临时调用能力。现在你是在把能力资产化。
如果你今天就要开始,先做这 3 个 Skill
我不建议一上来就做十几个。
先做三个最有价值,也最容易复用的就够了:
- 行业建库 Skill
:给一个行业名,自动产出目录树、品牌库、产品库、痛点库、关键词库。 - 竞品拆解 Skill
:给一个网站或品牌名,自动输出导航、Collection、标签、SEO、内容结构分析。 - 周报汇总 Skill
:每周把新增产品、爆款内容、融资新闻、趋势变化汇总成一份 Markdown 周报。
这三个一旦跑顺,你其实已经不只是「用 AI 提高效率」,而是在搭一套最小可用的行业情报基础设施。
Skill、slash command、AGENTS.md,到底怎么分
很多人刚接触这些东西的时候,最容易混在一起。
你可以先记一个最粗暴但很实用的区分:
- Skill
:封装一整套可复用工作流。重点是「这类任务以后会反复出现」。 - slash command
:封装一个你想手动点一下才触发的动作。重点是「它像按钮」。 - AGENTS.md / CLAUDE.md
:放长期规则。重点是「每次都要遵守」。
说白了:
如果你定义的是能力模块,用 Skill。
如果你定义的是手动按钮,用 slash command。
如果你定义的是长期规则,用 AGENTS.md 或 CLAUDE.md。
这个边界一旦想清楚,你后面搭工作流会顺很多,也不容易越配越乱。
附录:如果你真想自己搭,Claude Code 和 Codex 分别怎么做
讲完思路,最后补一点真正能落地的实操。
很多人看到这里会问:那我今天到底从哪开始?
其实分三层就够了。
1. 长期规则,放进 AGENTS.md / CLAUDE.md
这类文件适合放「每次都要遵守」的东西,比如:
文章默认存到哪个目录 配图默认放到哪个目录 输出格式、命名规范、写作风格 你的固定流程和注意事项
如果你用 Claude Code,项目级规则一般写在 CLAUDE.md。
如果你用 Codex,项目级规则一般写在 AGENTS.md。
它们的作用都很像:不是帮你完成某一次任务,而是让工具长期按你的工作习惯做事。
2. 高频流程,放进 Skill
如果一套动作你每周都要跑很多次,就不要每次重写 prompt 了,直接做成 Skill。
Claude Code 常见路径:
~/.claude/skills/industry-db/SKILL.md项目内也可以放:
.claude/skills/industry-db/SKILL.mdCodex 常见路径:
~/.agents/skills/industry-db/SKILL.md有些环境也兼容:
~/.codex/skills/industry-db/SKILL.md最小模板可以直接抄这个:
---name: industry-dbdescription: | 为某个陌生行业搭建结构化调研数据库。 当用户说要研究行业、梳理赛道、盘点竞品、整理关键词或建立行业地图时使用。---# Industry Database Skill当用户给你一个行业名时,按下面步骤执行:1. 先输出完整目录结构。2. 创建对应 Markdown 文件,适合导入 Obsidian。3. 至少包含:品牌、产品、痛点、关键词、竞品、内容、趋势、机会。4. 所有结论都附来源链接。
这已经足够做出第一版。
后面你再慢慢往里加字段、加脚本、加模板就行。
3. 手动动作,放进 slash command
不是所有东西都适合做 Skill。
像「生成周报」「发布草稿」「统一改标题」这种你希望明确手动点一下再执行的动作,更适合做 slash command。
在 Claude Code 里,项目级自定义命令通常放在:
.claude/commands/比如:
.claude/commands/weekly-report.md最小示意可以这样写:
---description: 生成行业周报---
它更像一个你自己做的按钮。
一个最实用的起手顺序
如果你今天就要开始搭自己的系统,我建议顺序是这样的:
先在 CLAUDE.md或AGENTS.md里写清目录、命名和输出规则。再做第一个 Skill,把最常重复的长 prompt 固化掉。 最后补 1 到 2 个 slash command,把高频手动动作按钮化。
这个顺序比较稳。
因为你先把规则层定住,再把能力层和按钮层补上,系统不会乱。
最后
这篇文章真正想说的,其实只有两层。
第一层:别再把 AI 只当成问答工具。
让它替你建数据库、拆竞品、整理内容、画地图、做周报。这样你得到的,就不再是一堆零散答案,而是一套越来越厚的认知系统。
第二层:别停在“会用”,要走到“会造”。
把你最常重复、最有价值的那几套流程,亲手封装成自己的 Skill。这样你积累的,就不只是笔记,不只是提示词,而是一套真正属于你的工作流资产。
未来真正的竞争力,可能不在于你比别人多知道了多少信息。
而在于:你有没有一套别人没有的认知结构,以及一套能持续帮你维护这套结构的工具。
如果你现在还把 AI 当成高级搜索框,我很建议你试一次:别先问结论,先让它替你搭骨架。
等你把第一套流程封成自己的 Skill 之后,你会明显感觉到,自己和工具的关系已经变了。
