 夜雨聆风
夜雨聆风平常我们看到的AI相关新闻,都在讲大模型的参数、Agent、Skill,价格之类的,往往忽略了最重要的数据。我们用AI时,已经明显感觉得AI总是胡说八道,生图或者视频时出现6个手指头的现象。说明了AI大模型训练语料有问题,数据质量参差不齐。
AI要赋能千行百业,产业应用要快速落地,那就必须有可以直接用来训练/微调/评测的靠谱数据集。
现在,国家也重视起来了,第一次专门给数据赋能AI发展做出系统性部署。六大专项行动,直指供给、流通、应用等关键环节。
实施方案对行业高质量数据集,也做了明确定义:经过采集、加工等数据处理,可直接用于开发和训练AI模型,能有效提升模型性能的行业数据的集合,包含行业通识和行业专识数据集。
01
「好数据有多难」
国数研究院的专家曾发文说了,AI正在加速从“可用”向“好用”迈进,高质量数据集作为大模型训练与应用的基础,直接决定AI发展的广度和深度。
我们平常刷短视频,看到那些人行机器人扭来扭去的,觉得现在科技发展很快了,但其实我们忽略了个问题,人形机器人能够在复杂的地形里站稳,走来走去的,需要有过无数遍、对高质量运动轨迹数据的训练。如果没数据的话,只能说是个玩具。
那,现在AI所需的数据,问题出现在哪里呢?
根据专业的调查报告显示,全国已建成高质量数据集超过11.6万个,总体量超过960PB,日均词元(Token)调用量突破140万亿。
其实,数据是有了,但仍有很多数据太过分散,没有统一起来,质量参差不齐,标准不统一,接口不规范,跟各个厂商的大模型匹配不上等。就感觉像厨房里一大堆的菜,厨神来了也要皱眉头,不知道怎么下锅。
当然,还有一部分本可公开的非秘密数据,人为的不愿意公开,多一事不如少一事的想法。
怎么把这些分散的数据,激活成标准化、高质量的数据集合,我想,这次的实施方案,也是想解决这个基础性问题。
02
「数据飞轮产品」
实施方案的总体基调就是:场景牵引数据、数据驱动模型、模型赋能应用、应用创造价值,要形成一个数据飞轮。
在IT信息化中,产品概念是非常重要的。
我们不能把数据当做库存去看待,要当产品去看,要打造良性循环的数据飞轮产品。
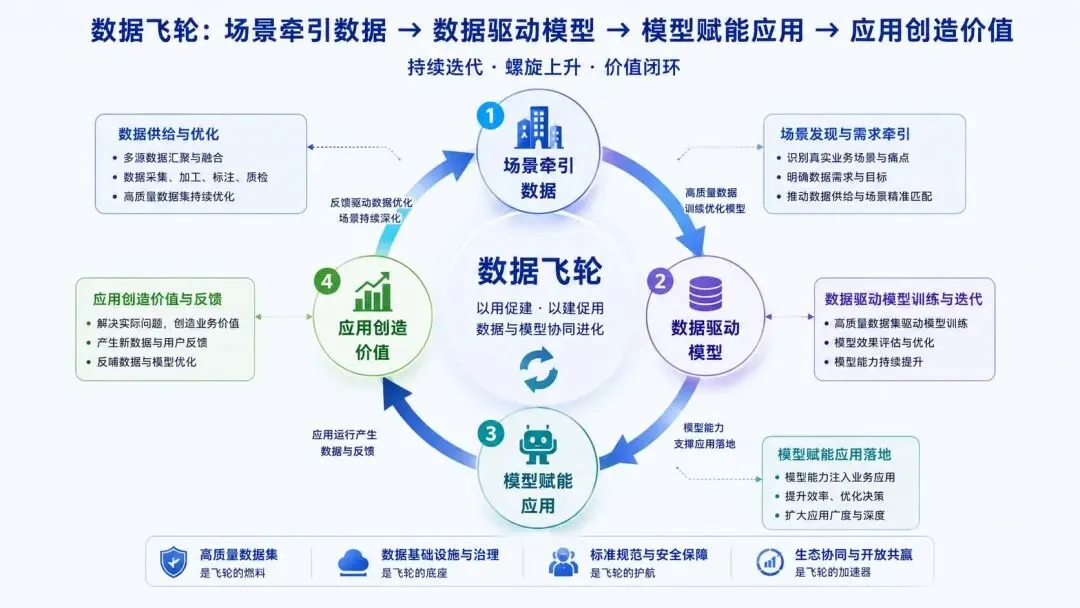
注:上图源于网络
时间计划表也写得很明确:到2028年底,建成一批覆盖重点领域、经过应用验证的行业高质量数据集,打造一批典型应用场景,培育一批创新型数据企业和专业人才,同时也把工具和标准形成出来。
所以,只是存储原始日志之类的数据,叫不上资产,能被AI大模型作为语料训练吃了,而且还能证明效能各方面有提升了,那数据才算有用。
03
「哪些行业先动」
六大专项行动中,我们先看看强基扩容行动。
我们都明白,哪些行业先动,就说明国家的钱和资源往哪里倾斜,机会财富就隐藏在那里。
实施方案也很明确,两部分,当然创新领域属于新赛道,相信更加吃香:
1、重点领域:科学研究、工业制造、农业农村、智慧能源、交通运输、金融服务、医疗卫生、教育教学、电子商务、人力资源、文化旅游、应急管理、气象服务、绿色低碳、公共安全、城市治理、住房建设、自然资源、社会信用等;
2、创新领域:低空经济、具身智能、智能驾驶、智慧海洋、生物制造等创新领域。
做法上有两个抓手很重要:
1、先列出清单:梳理行业数据资源底数和应用场景,把数据资源清单和数据集需求清单列出来。没有清单,后面全是拍脑袋。
2、链主带头:链主单位用联合体方式,把上下游资源整合起来,还鼓励向行业开放数据集和服务,帮助中小企。如果这条落地了的话,就可以解决很多中小企业最大的痛点问题(高质量数据问题)。(PS:怎么感觉这个像先富带后富呢)
04
「标注潜在机会」
再看看标注攻坚行动,这个也比较接地气的。
做过AI数据标注工作的,应该都理解,拉人头标框框,都是体力活。
现在,实施方案也明确说了,标注要转型升级,从体力活升级为专业活,向人机协同、专家深度的模式转变。
以后,值钱的标注岗位工作,不再是整天盯着电脑屏幕,重复点击的那种体力活,而是懂流程、懂工具、懂行业知识的人,带着模型去做。
如果是做职业培训、做数据服务、做行业咨询的,相信这里面将会有很多的赚钱机会。
05
「数据换钱」
其实,我们普通老百姓看这类政策,最关心想问的是,这跟我们有什么关系?能赚钱吗?
当然了,价值释放行动也说了,培养付费观念共识,构建以词元(Token)为基础的可量化、可定价的数据价值体系。
现在,我们的行业各种数据,被同行写一个爬虫程序,一下子就爬得光溜溜的了,全部数据都拿走了,别说有没有回报,甚至都还不知道被爬了。
有些大模型利用蒸馏技术,减少了真实数据训练,也成了敏感不说的话题。当然有些人认为是不耻的。
实施方案说了,要做词元交易。这种模式有点像预付费卡或者按流量计费。
我们的核心数据,不再需要一次性打包售卖,而是像卖流量包那样,而且数据还可以像房子、汽车拿去银行做抵押贷款。
数据将成为一种无形的信息资产,当我们手里有核心数据的时候,就可以赚到大钱了,这或许将会改变我们做数据生意的逻辑。
有点像以前的土地拍卖,谁能提前看懂了机遇、规则,谁先买一大块地囤起来,后面就发大财了。
最后想说,我们不要只关注大模型的自身技术的发展,结合现在国家政策指向,看清数据方向。
1、如果是企业的技术主管。不要跟风去部署什么私有化大模型,留意着所在行业的那张需求清单什么时候出来;看能不能接入公共数据授权运营或链主牵头的联合体;先把内部数据做成可审计、可脱敏、可版本管理的数据集产品,并提升数据质量。
2、如果是个打工牛马。不想在这个AI发展浪潮中被淘汰,就不要只满足于用大模型分析数据、做PPT、写总结、生图生视频了。可以尝试研究细分行业的数据标注,了解垂直行业数据怎么打标、怎么筛选,相信将来,会比大模型训练师值钱。
 感谢您读到这里,不如关注一下?👇
感谢您读到这里,不如关注一下?👇
中国东盟AI中心 & 南A中心,你都了解我们在东南亚的布局吗
