 夜雨聆风
夜雨聆风智见AI
大鹏注
OpenAI 这份报告真正想表达的是:Codex 已经从程序员工具,开始变成知识工作者的工作系统。
我保留了原文的主线和关键数据,只做了必要的中文化表达和术语解释。报告里的关键数据图也同步保留

OpenAI《The Next Era of Knowledge Work》报告封面
OpenAI 在 2026 年 6 月 2 日发布了一份报告,标题叫《The Next Era of Knowledge Work》。副标题更直接:Codex 如何帮助人们处理现代工作的复杂性。
这份报告的开头给了三个数字:

OpenAI 报告核心数据:500 万周活、6 倍增长、知识工作者采用速度超过开发者 3 倍
Codex 每周活跃用户已经达到 500 万。自 2 月桌面应用发布以来,周活增长超过 6 倍。更关键的是,知识工作者采用 Codex 的速度,已经超过开发者的 3 倍。
OpenAI 还把增长最快的任务类型写在同一页:数据分析、研究、知识产物。
这几个词很重要。它们都不是传统意义上的「写代码」。它们更接近我们日常做的事:读资料、查行业、写报告、做 PPT、处理表格、整理客户反馈、把一个复杂问题变成可以交付的东西。
知识工作的痛点,不是不会写,而是上下文太碎
报告用了一段历史背景解释知识工作。
农业时代,人主要处理土地和作物。制造业时代,人主要处理机器和产品。到了今天,发达经济体里大量劳动都变成了知识工作:分析、代码、文档、设计、系统、决策和沟通。
OpenAI 引用了一个判断:美国超过 40% 的劳动人口,大约 7200 万人,主要在和信息打交道。
但问题也从这里开始。
现代人可以更快地产出文档、消息、仪表盘、模型和 PPT。可与此同时,人也花了大量时间找上下文、核对不同版本、等别人回复、把信息从一个系统搬到另一个系统。
报告引用麦肯锡全球研究院的数据:普通知识工作者每周大约 28% 的时间花在处理邮件上,近 20% 的时间花在寻找内部信息,或者寻找能帮忙的同事。
现代办公室的真实状态就是这样:工具越来越多,信息越来越散。
邮件、协作文档、表格、看板、CRM、知识库、聊天工具、SaaS 应用,每一个工具都解决了一个局部问题,也制造了新的割裂。真正要用的信息,可能藏在收件箱、文件夹、聊天记录、评论、权限、仪表盘、工单、会议纪要和自己的记忆里。
OpenAI 把这种成本拆成三类:
- 搜索:在混乱系统里找到相关输入,比如文件、条款、数据集、消息、专家。
- 协调:在团队、工具、格式之间移动信息和决策。
- 验证:让工作成果能被接受,并经得起现实检验。
这三个词,基本覆盖了知识工作者每天最累的地方。
知识工作的真实成本:上下文太碎带来的搜索、协调和验证负担
Codex 的定位:把 AI 放到具体问题旁边
报告里有一个比喻很关键。
过去,电力真正提升工厂效率,并不是因为工厂简单把蒸汽机换成电动机。真正的变化发生在工厂重新设计之后:把电动机放到每一台机器旁边,让生产流程围绕新的能力重构。
OpenAI 认为,知识工作也在等这样的「工厂重构」。
过去的软件降低了中间产物的生产成本。邮件让通信变便宜,于是邮件变多了。文档让起草变便宜,于是草稿和审阅轮次变多了。结果是,文档和工具越来越多,注意力越来越少。
Codex 的意义,是把 AI 放到每一个需要解决的问题旁边。
它可以找输入、协调流程、生成交付物、检查质量,也可以推动必要的审批。它不止帮人写出一个文件——它让人在碎片化的数字组织里,把分散的信息拼成能运转的系统。
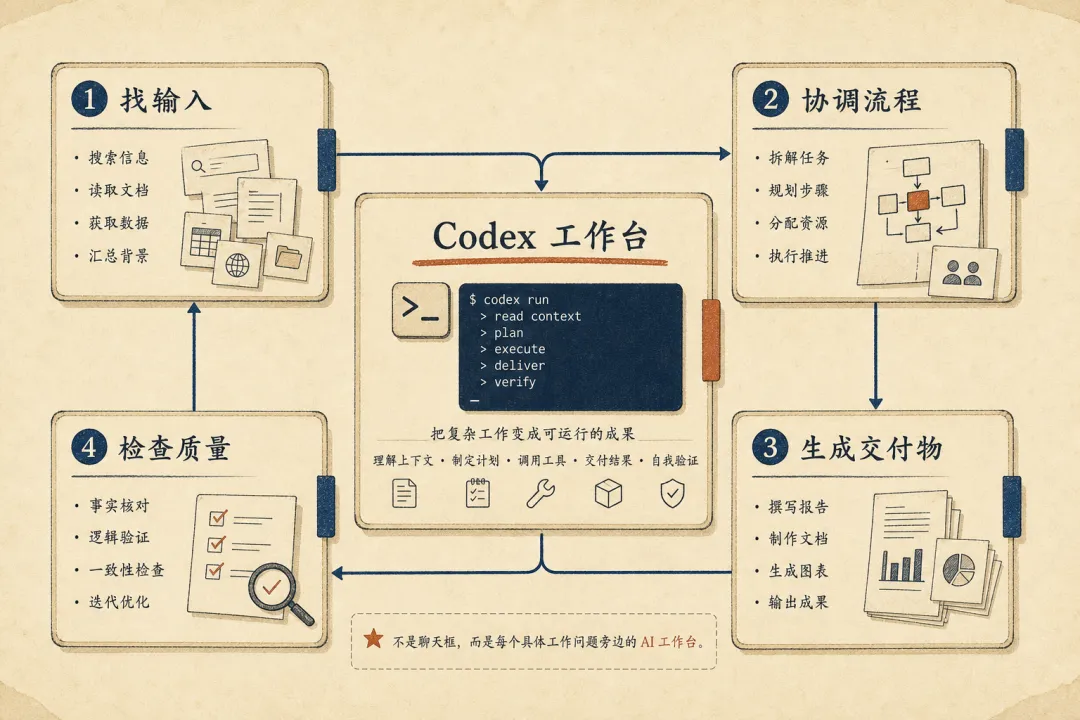
Codex 工作台:把 AI 放到找输入、协调流程、生成交付物和检查质量旁边
OpenAI 在报告里举了 GroundVue 的例子。这个团队帮助政府机构从公开会议里学习经验。政府会议的信息分散在视频、网站和地方平台里,过去需要很多研究人员和技术人员花几天到几周整理。GroundVue 用 Codex 找到难以触达的公共信息源,并搭建持续收集和整理的系统,把大量分散公共信息变成可用的机构知识。
这个例子和国内很多场景很像:政策研究、行业调研、招投标资料、客户访谈、培训案例库,本质都是同一种问题。
不是没有信息。
是信息太散,没人有时间把它们变成可用的判断。
知识工作者正在变成 Codex 的新增量
报告里最值得看的一组数据,是用户结构变化。
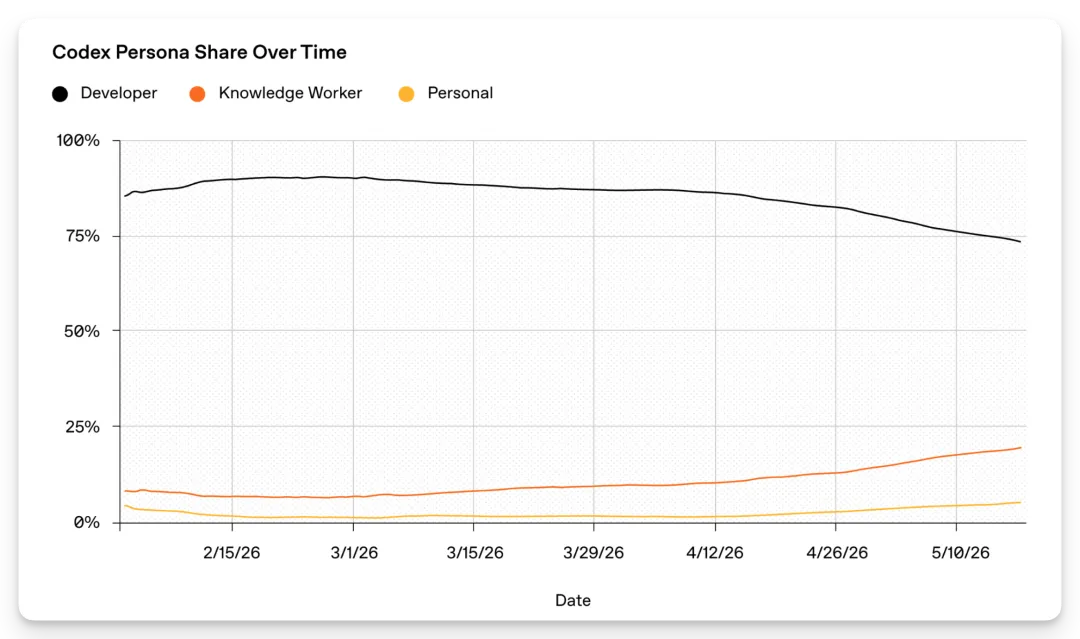
Codex 用户结构变化:知识工作者和个人用户占比正在提升
OpenAI 说,知识工作者现在约占 Codex 用户的 20%,并且采用速度超过开发者的 3 倍。这里面包括产品和项目管理、设计、研究、学术等角色。
个人用户也超过 5%,增长速度超过开发者的 4 倍,使用场景包括兴趣和创作、教育和自学、个人财务、娱乐。
Codex 的使用边界已经开始模糊。
开发者会用 Codex 做知识产物。知识工作者也会用 Codex 做代码实现和工程操作。
产品经理可以自己搭一个仪表盘,不必等另一个团队排期。研究人员可以自己写数据清洗脚本,不必把任务转给工程团队。设计师可以自己做原型。管理者可以做一个内部工具,每周自动整合文件并生成报告。
这就是报告里最核心的变化:最接近问题的人,开始拥有构建工具的能力。
知识工作者用 Codex 做什么
OpenAI 给了一张任务分布图。
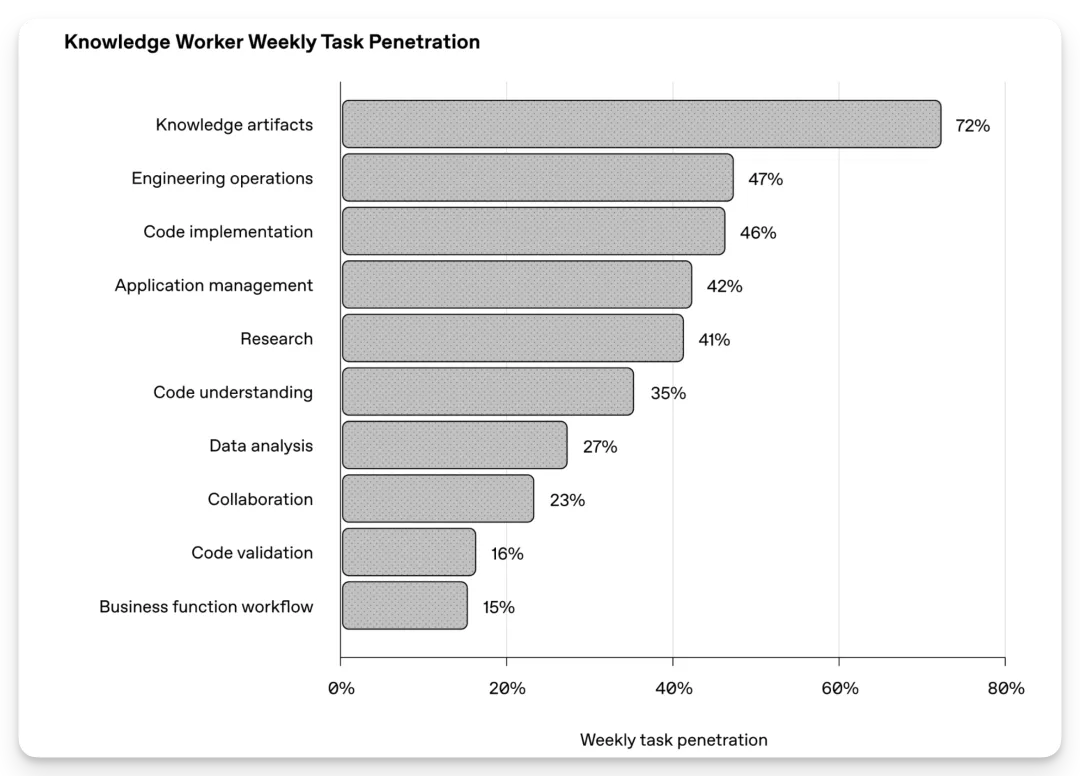
知识工作者每周使用 Codex 的任务分布:知识产物、工程操作、代码实现和应用管理
每周有 72% 的知识工作者在用 Codex 生产知识产物,包括报告、备忘录、合同、图片、音频、视频、PDF 和表格。
后面的任务也很有意思:
- 工程操作:47%
- 代码实现:46%
- 应用管理:42%
- 研究:41%
- 数据分析:27%
- 协作:23%
这张图很值得反复看。
它说明 Codex 对知识工作者的价值,不是单点写作,也不是问答总结。它正在变成一套工作台:产出文档,处理数据,写脚本,做研究,检查应用——有时候这几件事同时在跑。
报告还提到一个行为变化:越来越多人开始并行运行多个 Codex 任务。大约 50% 的用户一天里会在某个时刻同时运行多个 Codex 任务,而 4 月中旬这个比例还不到三分之一。
用户角色正在变。
人不再只是一件事一件事地亲手做。人开始变成工作流的编排者:一个任务检查数据集,一个任务起草脚本,一个任务组装报告,一个任务检查应用。
我一直说,未来最重要的能力,不是「会不会用 AI 聊天」——是「会不会领导 Agent 干活」。
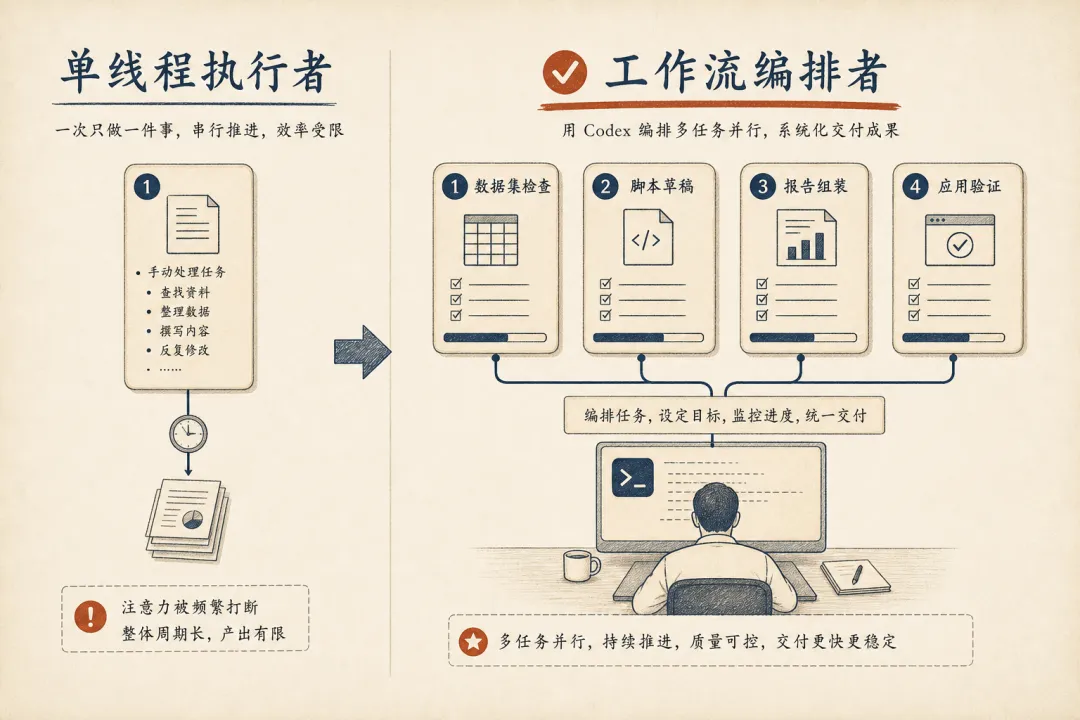
从单线程执行者到工作流编排者:同时调度多个 Codex 任务
增长最快的是数据分析、研究和知识产物
OpenAI 单独列了知识工作者增长最快的任务类型。
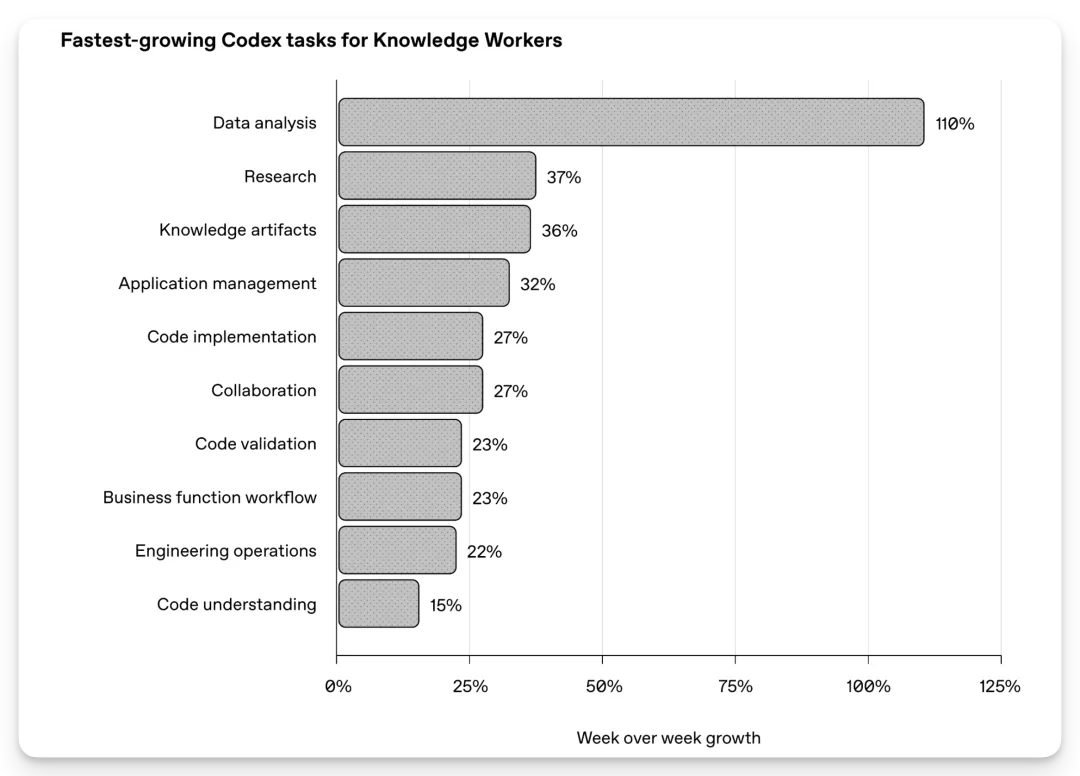
知识工作者增长最快的 Codex 任务类型:数据分析、研究和知识产物
数据分析周环比增长 110%。研究增长 37%。知识产物增长 36%。
这里的知识产物主要包括 Google Docs、Word 文档、报告、备忘录、合同,以及图片、音频、视频等多媒体资产。报告还提到,使用 PDF 和电子表格的用户增长超过 50%。
研究场景里,常见的是网页搜索、内部知识搜索、市场研究、公司研究、行业研究、竞争对手研究、市场规模和定位分析。
这部分对知识 IP、培训师、顾问尤其重要。
很多人以为 AI 的价值是帮自己「写得快一点」。但从这份报告看,真正增长最快的是更底层的能力:把资料查清楚,把数据处理好,把材料变成可交付成果。
写作只是最后一公里。
调研、分析、验证、结构化、把材料变成可复用的东西——这些才是真正拉开差距的地方。
小团队为什么会被放大
报告里还有两个案例很值得研究。
Proaction 是一个 5 人创业公司,服务对象是车队管理客户。客户的数据分散在车联网系统、维护平台、表格和组织记忆里。它的联合创始人用 Codex 把客户对话变成定制方案、工作流原型和可运行 Demo。
这让销售、客户发现、产品开发被连到一起。客户还没签合同之前,他们就能更快做出贴近客户真实运营方式的方案。
另一个案例来自数学教授 Taiyo Inoue。他用 Codex 自动化维护 Canvas 学习管理系统里的课程信息,包括作业、日历、材料和通知。这个流程每周节省 4 到 5 小时。他把省下来的时间重新投入课堂,设计更多协作解题活动。
这两个例子说的是同一件事:Codex 不是帮你省力气。它把低价值、重复、碎片化的工作压下去,让你把精力放回真正值得做的事上。
OpenAI 给政策制定者的建议
报告最后转向政策层面。
OpenAI 的观点是:国家和组织如果能让更多人接触这些工具,并教会他们负责任地构建和委派任务,就会获得更多生产力收益。
它提出了四点建议。
一是现代化工作流,并用真实结果衡量效果。公共机构应该用 Agent 提升行政效率、改进软件系统、搜索和核对记录、支持科学研究、更快交付公共服务。衡量标准应该是普通人能理解的结果:等待时间更短、表单更少、审批更快、福利发放更好、行政成本更低、政府响应更快。
二是把 AI 素养变成核心劳动力技能。政府应该通过学校、社区学院、公共机构、图书馆和雇主合作,为一线工作者提供动手训练——让人带着真实工作流学,而不是干讲概念。
三是把工作者放在 AI 采用的中心。最接近工作的人,往往最知道哪里可以被 AI 改善。护士知道哪些表单拖慢护理,社工知道福利发放卡在哪里,教师知道行政工作如何挤压教学时间。
四是更新公共采购。政府不应该只购买软件许可证,而应该购买能解决实际运营问题的 AI 工具。试点要有隐私、安全、审计和人工监督,也要允许在安全沙盒里测试,再把能实际降低积压和负担的方案扩大。
这份报告对我们真正有用的地方
这份报告对国内知识工作者最有价值的地方,是它帮我们确认了一件事:
Codex 的主战场已经不只在代码里。
它正在进入调研、数据分析、报告、PPT、课程、客户方案、内部工具、组织知识管理这些更广泛的知识工作场景。
普通知识工作者真正要学的,是三件事:
- 怎么把分散上下文交给 Agent 处理。
- 怎么把一次工作变成可复用流程。
- 怎么从执行者变成多个工作流的编排者。
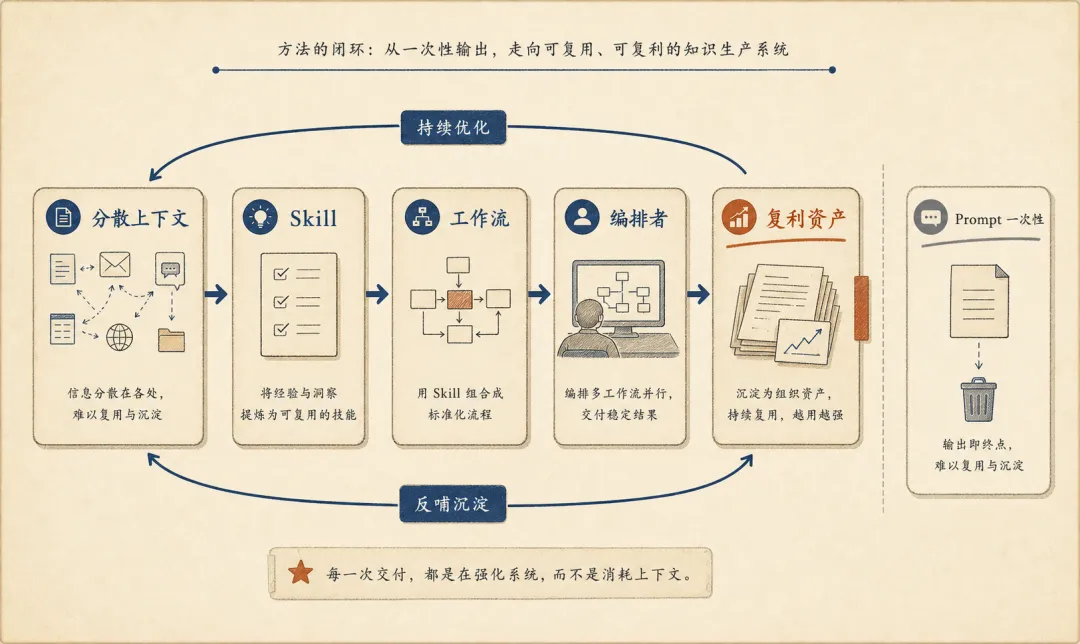
从上下文到复利资产:Skill、工作流和编排能力的积累路径
这也是我为什么更关注 Skill、Memory、Context Engineering,而不是单条 prompt。
Prompt 是一次性的。工作流才会产生复利。
这份 OpenAI 报告,其实是在给这个判断背书。
Codex相关文章
