 夜雨聆风
夜雨聆风
AI4PDEs|精选 · 论文推荐
AI for Science|第七十四期
iPINNER:一种与集成卡尔曼滤波结合的
迭代物理信息神经网络
iPINNER: An iterative physics-informed neural network with ensemble Kalman filter
作者:Binghang Lu, Changhong Mou, Guang Lin✉
第一署名单位: Purdue University, USA
发表期刊:Journal of Computational Physics 548 (2026) 114592
论文主页:
https://linkinghub.elsevier.com/retrieve/pii/S0021999125008745
论文|PDF 下载 ↓
https://www.jianguoyun.com/p/DYbZpJQQ7P3jDRixm6sGIAA
开源代码 ↓
未开源
点击打印论文信息


Published 2025-12-13

自从物理信息神经网络(PINN)被提出后,越来越多的科学问题开始借助机器学习的力量求解偏微分方程。然而,理想中的无噪音数据和完备物理信息并不常见。当观测数据噪声较大或者模型存在未知参数时,传统 PINN 很容易陷入局部极值或者被噪声牵着走。如何在保证物理约束的同时,充分利用有限且嘈杂的数据,是当前科学机器学习中的一个重要难题。

研究背景 · 问题意识


研究背景

PINN 的核心思想是将 PDE 的残差、初始条件、边界条件以及观测数据误差写成损失函数,通过反向传播同时逼近多个约束。这个思路灵活又强大,成功应用于流体力学、结构力学、地震反演等问题。不过,单一目标优化方法通常需要手动调整各部分损失权重,一旦不同损失尺度不平衡,网络会优先降低某一项损失,导致其它物理约束无法满足。此外,现实采集的数据往往带噪甚至不完整,传统 PINN 缺乏处理噪声的机制,容易学到有偏解。如果偏微分方程中的某些系数未知,PDE 残差与待估参数纠缠在一起,训练过程更加困难。

问题意识

本文关注的核心问题是:在只有噪声观测且物理模型不完备的情况下,如何提升 PINN 对 PDE 的预测精度和参数反演能力?研究者希望在保证物理守恒的前提下,既能平衡不同损失之间的矛盾,又能利用统计方法过滤噪声,提高对未知参数的推断能力。传统的单一目标随机梯度下降很难兼顾这些目标,需要寻找新的优化机制。
研究意义 · 方法论 · 创新点

研究意义

如果能克服噪声影响并有效估计未知参数,PINN 将能处理更多真实复杂的科学问题。这样的能力对于工程中的流场反演、地震勘探中的速度场恢复、生物医学中的扩散过程建模等都有实际意义。同时,从方法论角度,如何将进化算法与统计滤波结合,兼顾物理信息与数据驱动,也为科学机器学习开辟了新的思路。

方法论

作者提出了一种迭代式物理约束神经网络架构,命名为 iPINNER。其主要思路是在 PINN 框架内结合多目标进化优化和卡尔曼滤波。核心步骤如下:
① 多目标优化平衡多重损失:传统 PINN 通过加权求和定义整体损失,而 iPINNER 将 PDE 残差、初始边界条件和数据误差视为独立目标,利用非支配排序遗传算法 NSGA‑III 对网络参数进行搜索。该算法会生成一组帕累托最优解,这些解形成不同损失之间的权衡,避免某一项损失过早占优。由此得到的多组神经网络参数也体现了模型不确定性。
② 利用 Ensemble Kalman Filter 处理噪声:NSGA‑III 生成的多个网络参数被视为一个小的预报集合。作者将这些集合预测与观测数据一起输入 Ensemble Kalman Filter,通过贝叶斯更新得到“分析场”,即更接近真解的后验估计。卡尔曼滤波在更新过程中自然引入观测误差协方差,实现了对噪声的滤除。
③ 迭代更新数据损失:将卡尔曼滤波得到的后验估计作为新的“观测值”更新数据损失,再用 NSGA‑III 优化 PINN。如此反复迭代,模型逐步吸收来自数据的有效信息,同时保持物理约束,最终收敛到更稳定的解。 Fig. 1 为iPINNER 方法框架示意图。
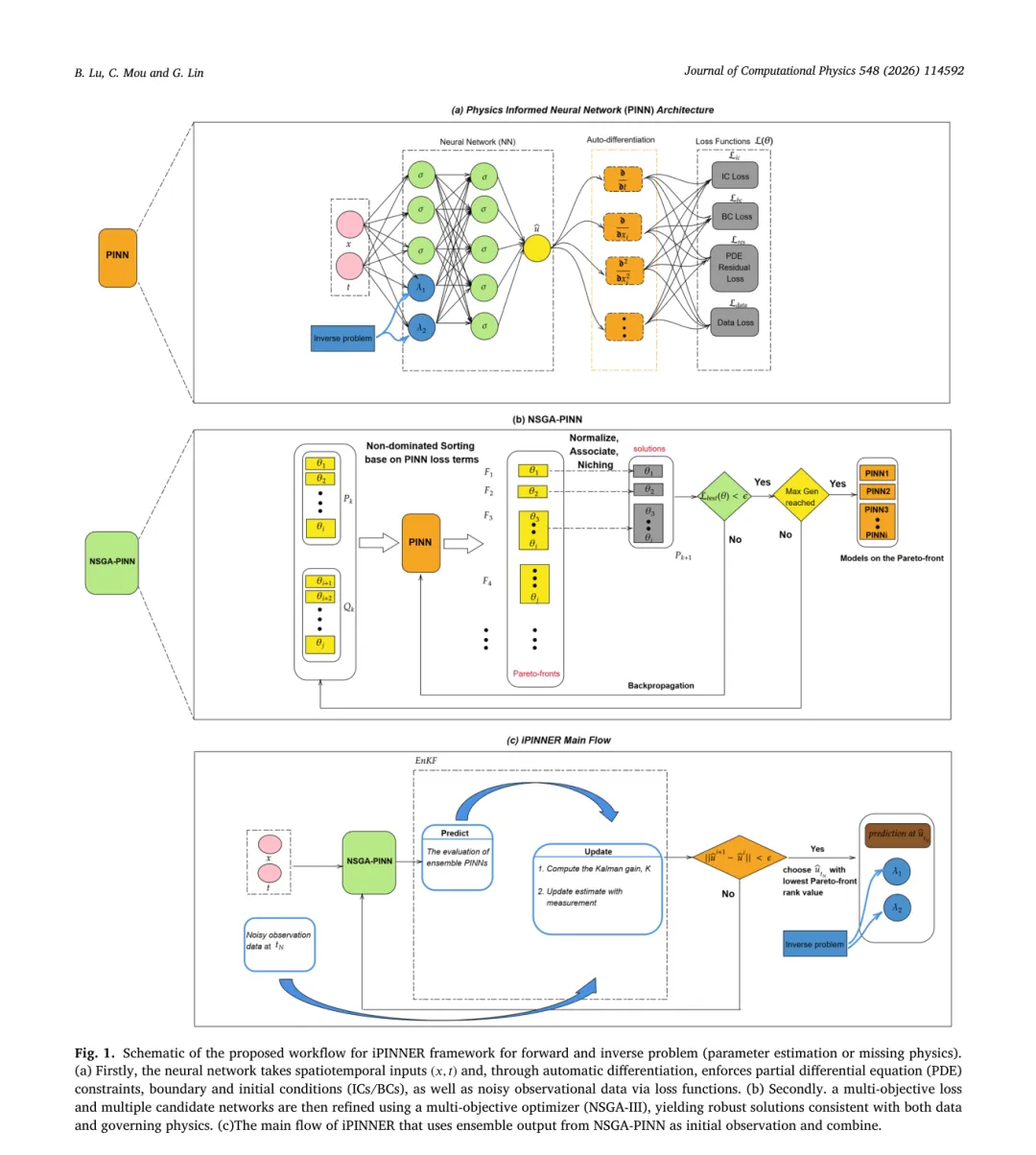

创新点

与以往单一优化的 PINN 或仅采用多目标优化的模型相比,iPINNER 有三大创新:
① 将 NSGA‑III 引入 PINN 训练,把多损失问题转化为多目标优化,从算法层面解决了损失权重难调的问题,并提供了一组带不确定性的模型。
② 首次将 ensemble Kalman 滤波用于 PINN 训练,利用统计滤波融合模型集合与噪声观测,动态调整数据损失,显式过滤噪声,提升对未知参数的估计精度。
③ 提出了迭代式训练流程,将进化优化和贝叶斯滤波交替进行,实现了在噪声环境下自动更新数据驱动项的能力。该框架既适用于正问题求解,也适用于逆问题的参数反演。
实验结果 · 研究结论 ·

实验结果

作者在多个 benchmark 上验证了 iPINNER 的性能,重点包含一维粘性 Burgers 方程和时间分数阶混合扩散波方程,同时还补充了二维热方程例子。
一、Burgers 方程正向求解
Burgers 方程常用来检验非线性 PDE 方法。实验设置中,真实粘性系数为 0.01/π,训练时故意设置错误值 0.02/π 以模拟模型偏差,并添加 20%、50%、80% 三种噪声观测。作者比较了使用 Adam 优化的普通 PINN、仅用 NSGA‑III 的多目标 PINN,以及所提 iPINNER。图 3 给出了不同噪声水平下三种方法的预测图像和误差,iPINNER 在大部分区域取得更小误差,尤其当噪声为 50% 时误差约减小一个数量级。
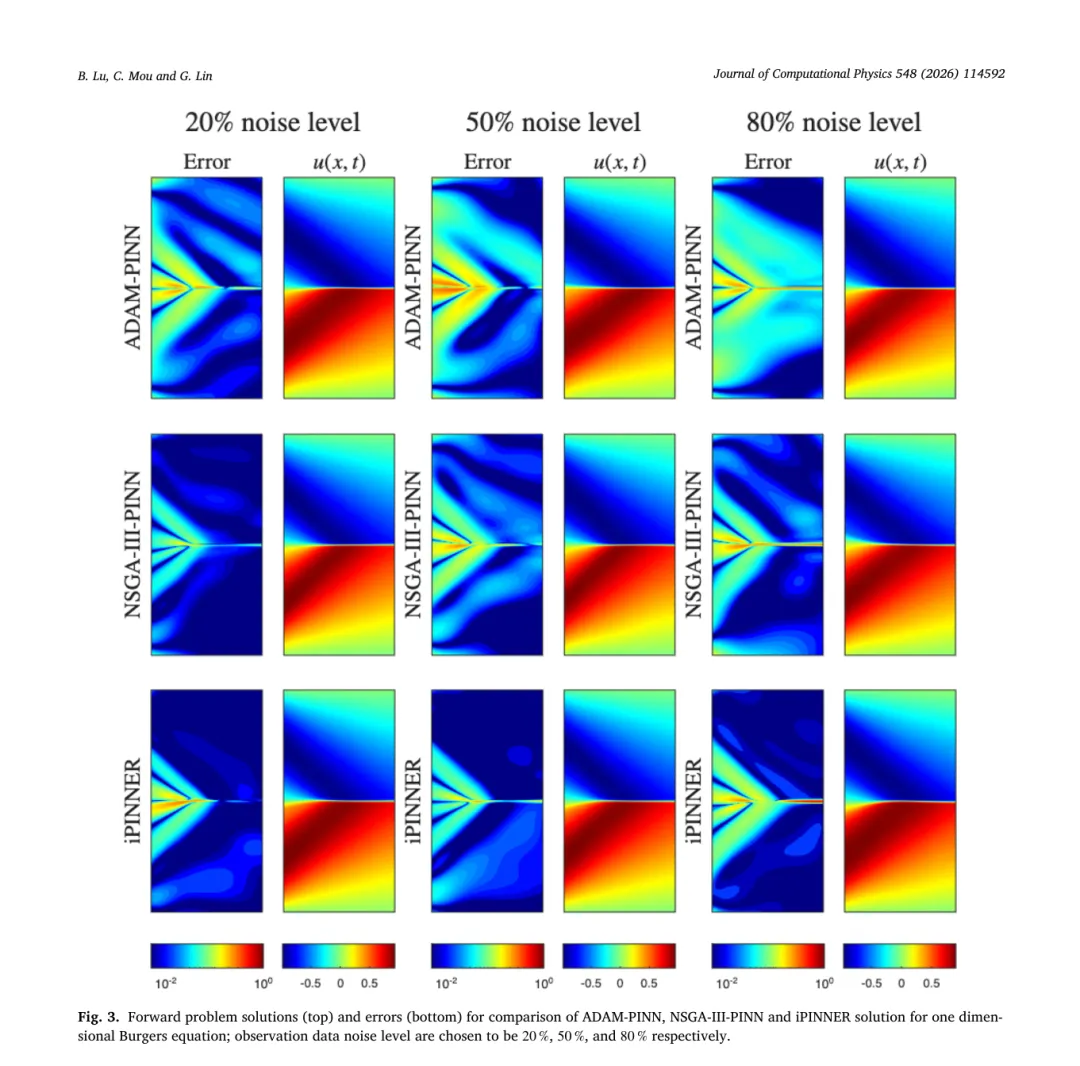
当噪声为 20% 或 50% 时,iPINNER 的误差仅为 0.0006 和 0.0009,而 Adam‑PINN 和 NSGA‑PINN 的误差在 0.0014 到 0.0036 之间;噪声达到 80% 时,各方法误差都较大,但 iPINNER 仍保持最优。
值得注意的是,NSGA‑III 自身也能缓解某些噪声影响,但缺少滤波过程时仍难以兼顾模型误差与观测噪声。iPINNER 通过 EnKF 滤波对观测进行了“净化”,显著提升了整体性能。
二、Burgers 方程逆问题
逆问题中假设粘性系数未知并作为可训练变量。不同噪声条件下,各方法对粘性系数的估计结果如表 6 所示。真实值约为 0.00318,iPINNER 在 20% 和 50% 噪声下的估计值分别为 0.00546 和 0.00648,误差约为传统方法的一半。当噪声高达 80% 时,三种模型都难以准确恢复参数,反映了观测信息被噪声淹没的限制。
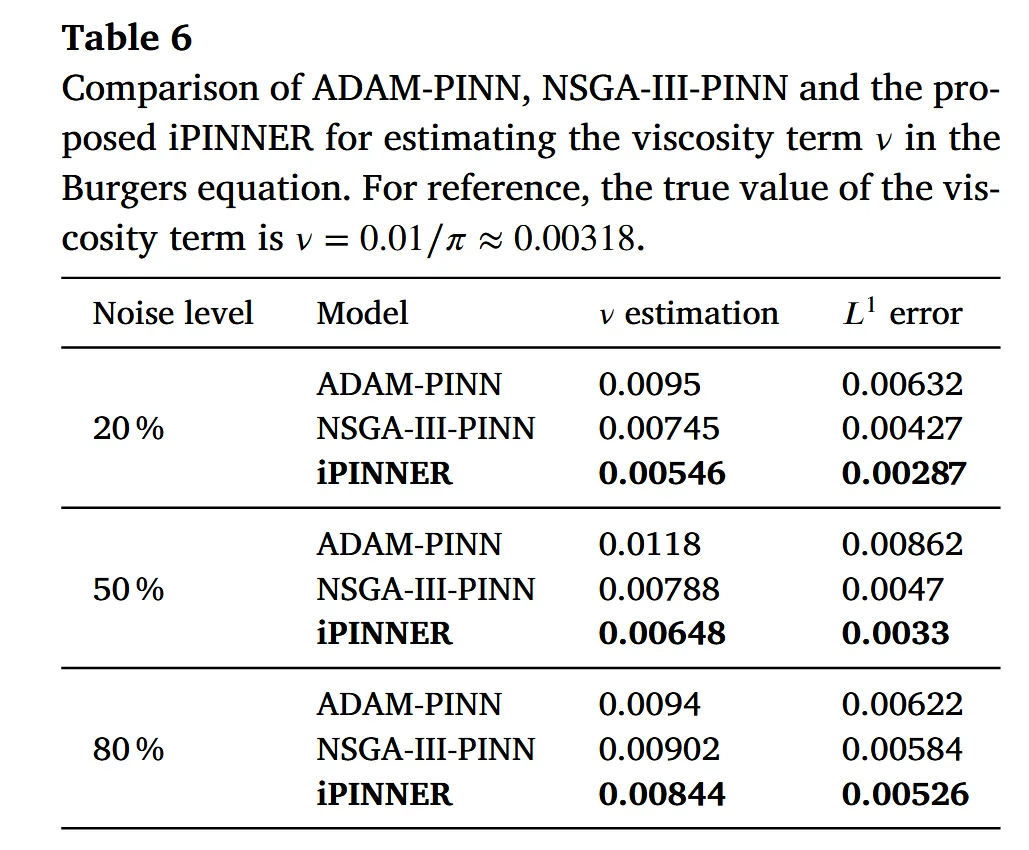
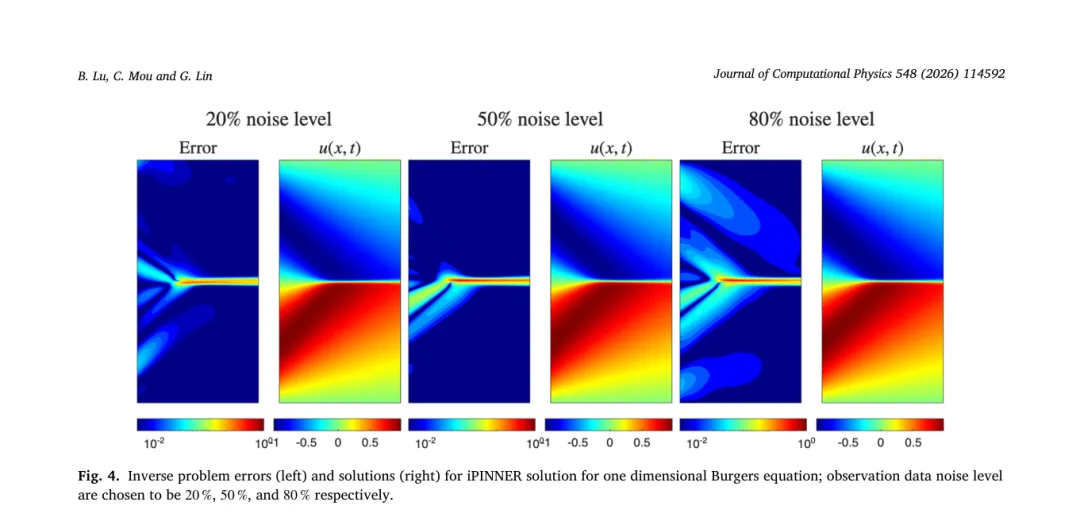
三、时间分数阶混合扩散波方程
混合扩散波方程引入了时间分数阶微分,兼具扩散与振荡特性,更能体现真实复杂物理过程。作者选择了分数阶指数 0.5 的解析解作为基准,并在模型中加入 50% 的强噪声。实验同样包含正问题和逆问题。
在正问题上,图 6、7、8 展示了不同噪声下真解与 iPINNER 解的对比,以及 iPINNER 与 ADAM‑PINN 的 L1 误差分布。整体来看,iPINNER 误差明显更小,并且在时间和空间上分布更均匀。表 8 汇总了各方法在不同噪声水平下的平均绝对误差,iPINNER 始终略优于其它方法。
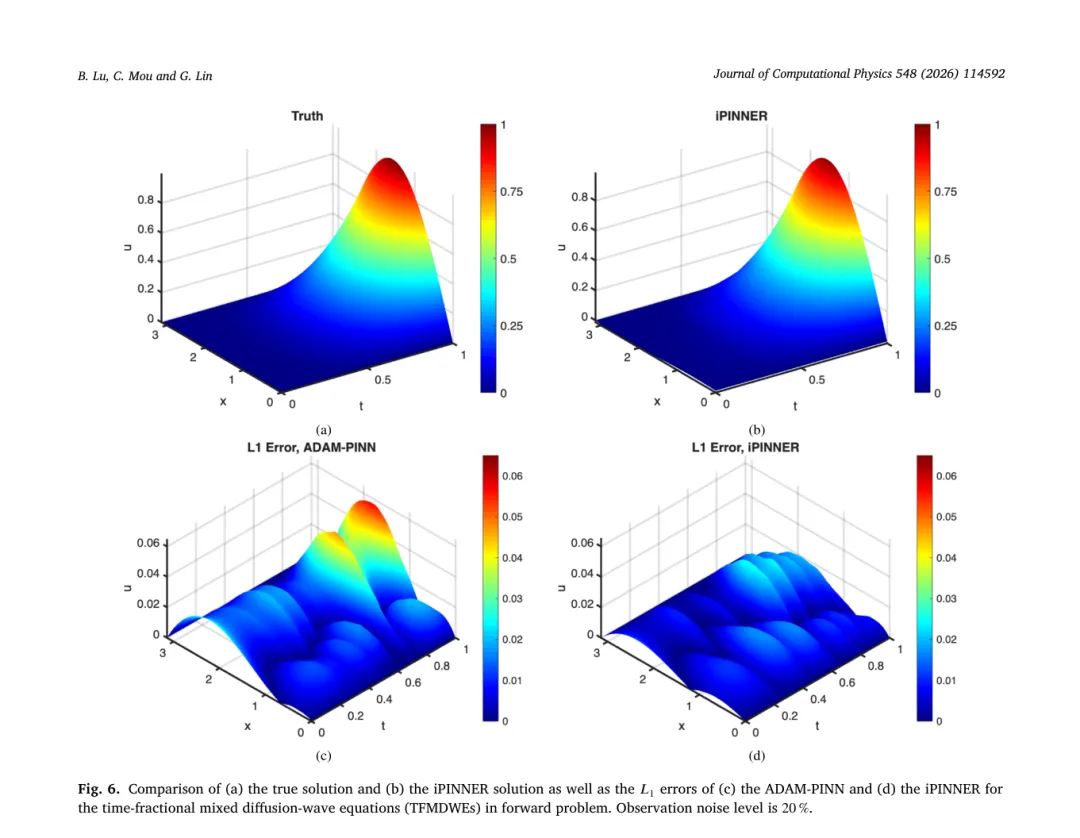
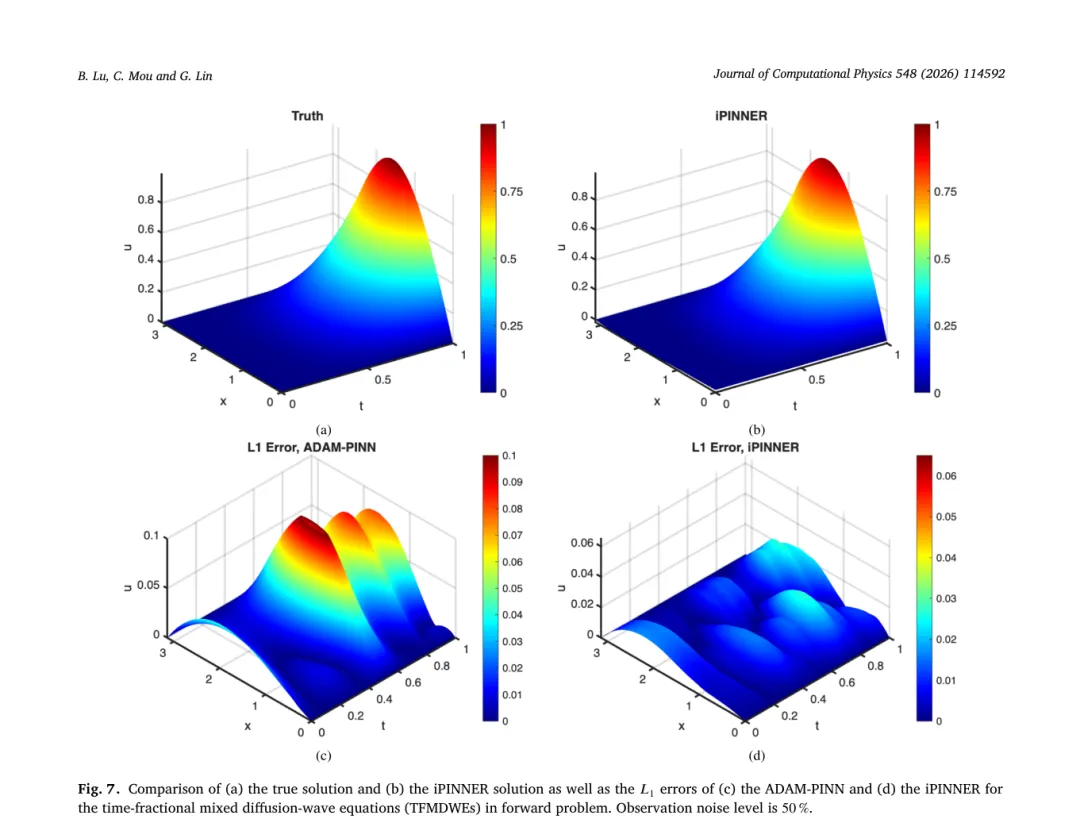
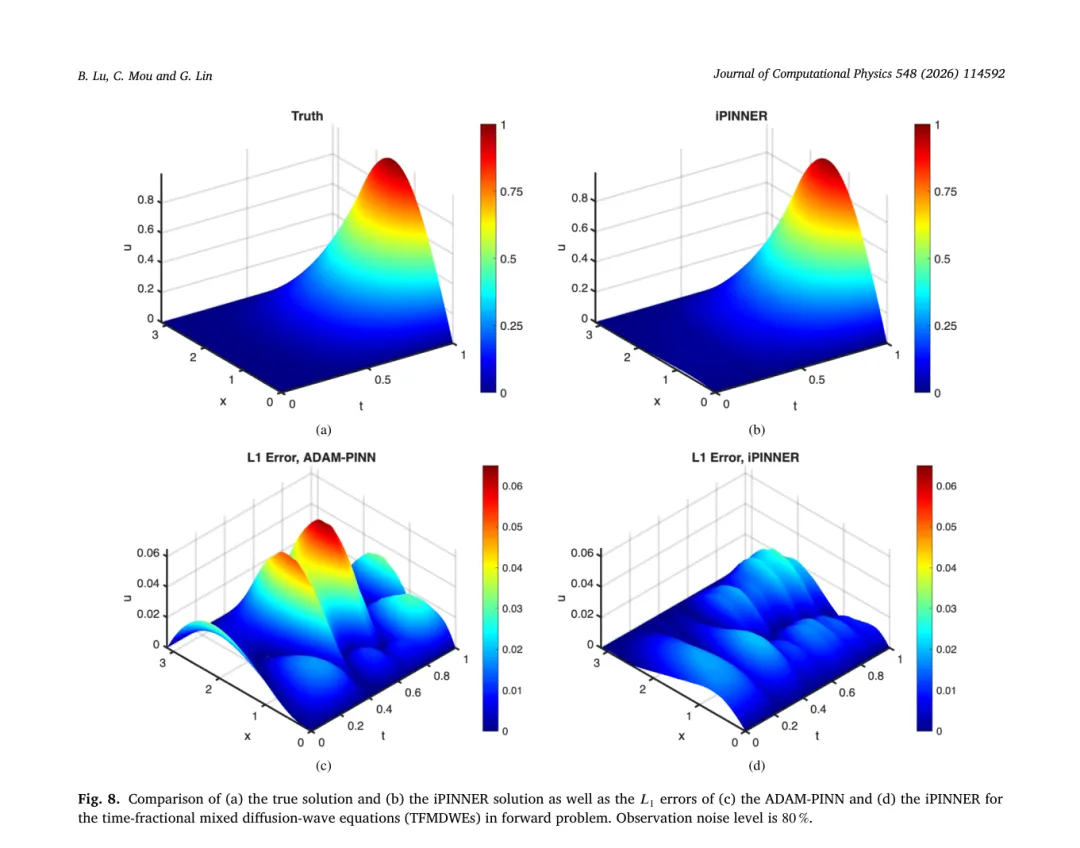
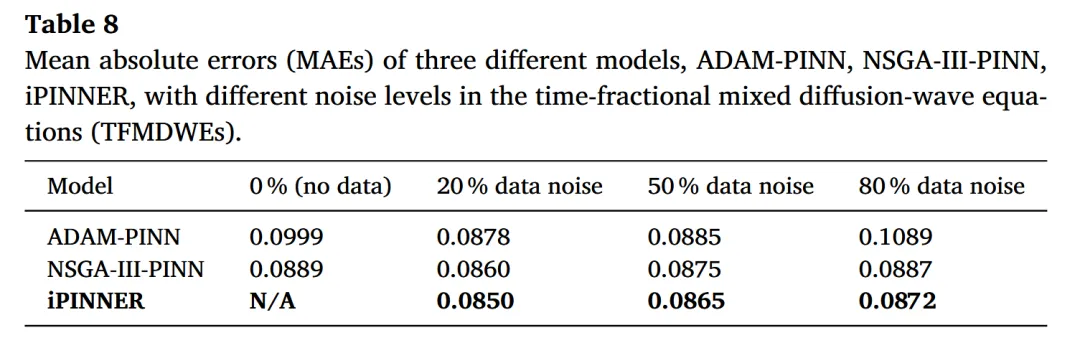
图 9 进一步比较了 iPINNER 与其它方法在不同时间截面上的预测。无论噪声水平如何,iPINNER 与真实解的差距都最小,而且在高噪声下仍能保持稳定。
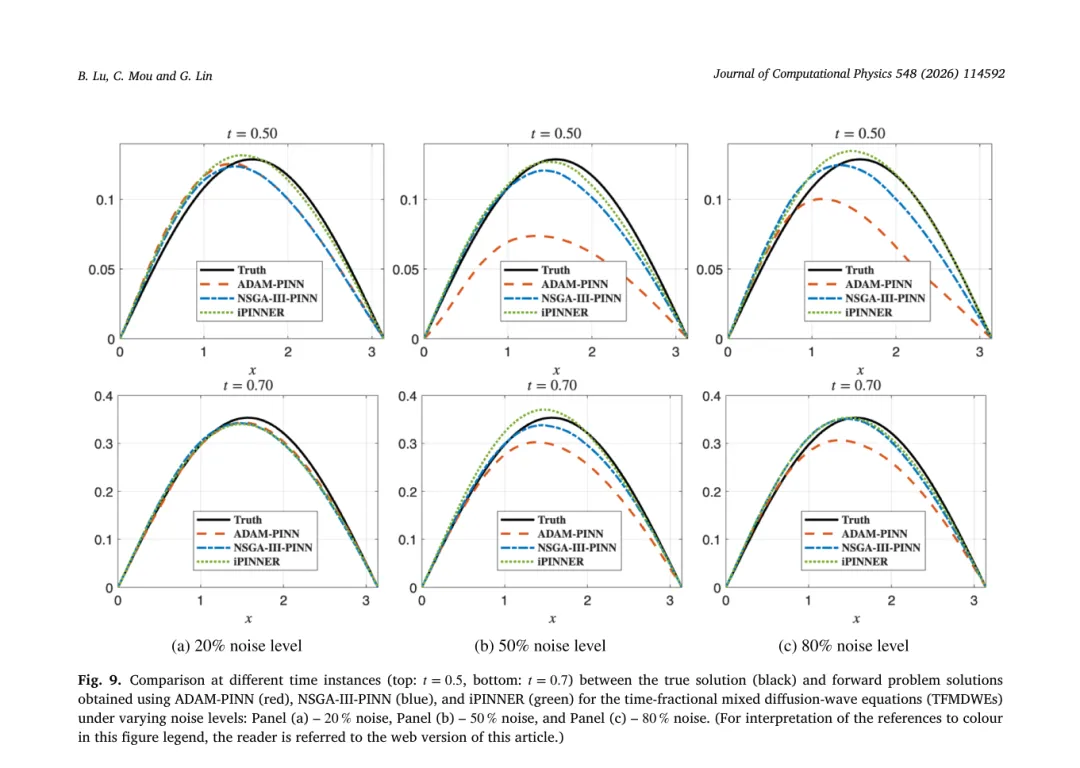
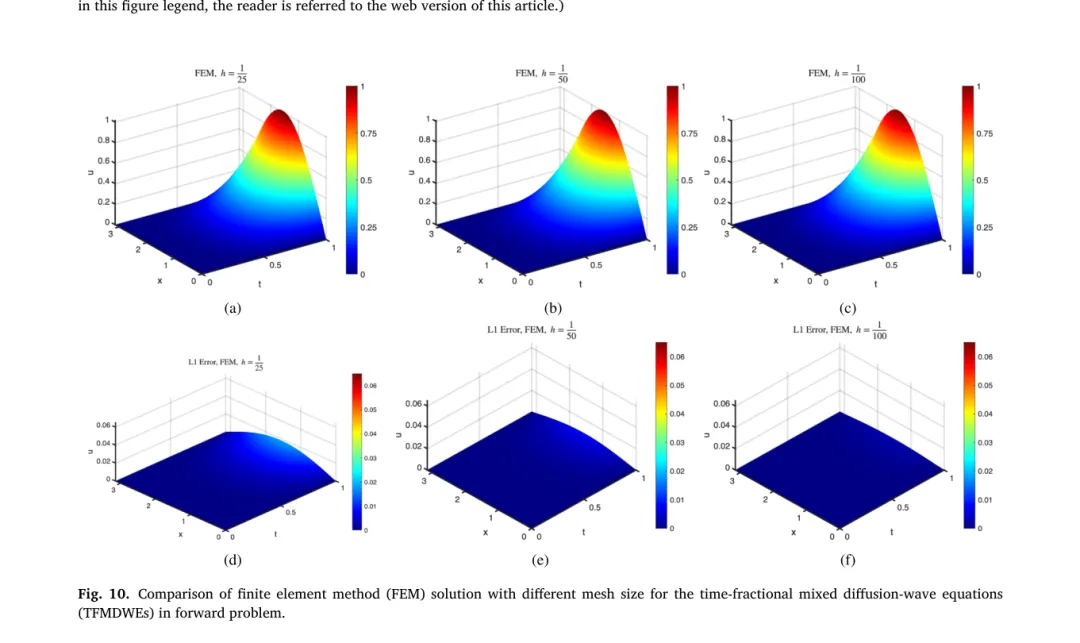
作者还用有限元方法生成了解的参考值,图 10 显示不同网格尺度下 FEM 的误差,证明 iPINNER 的预测精度与传统数值方法相当,但 iPINNER 能同时解决正问题和逆问题。
在逆问题中,需估计分数阶指数。表 10 给出了不同噪声水平下三种方法的估计结果。
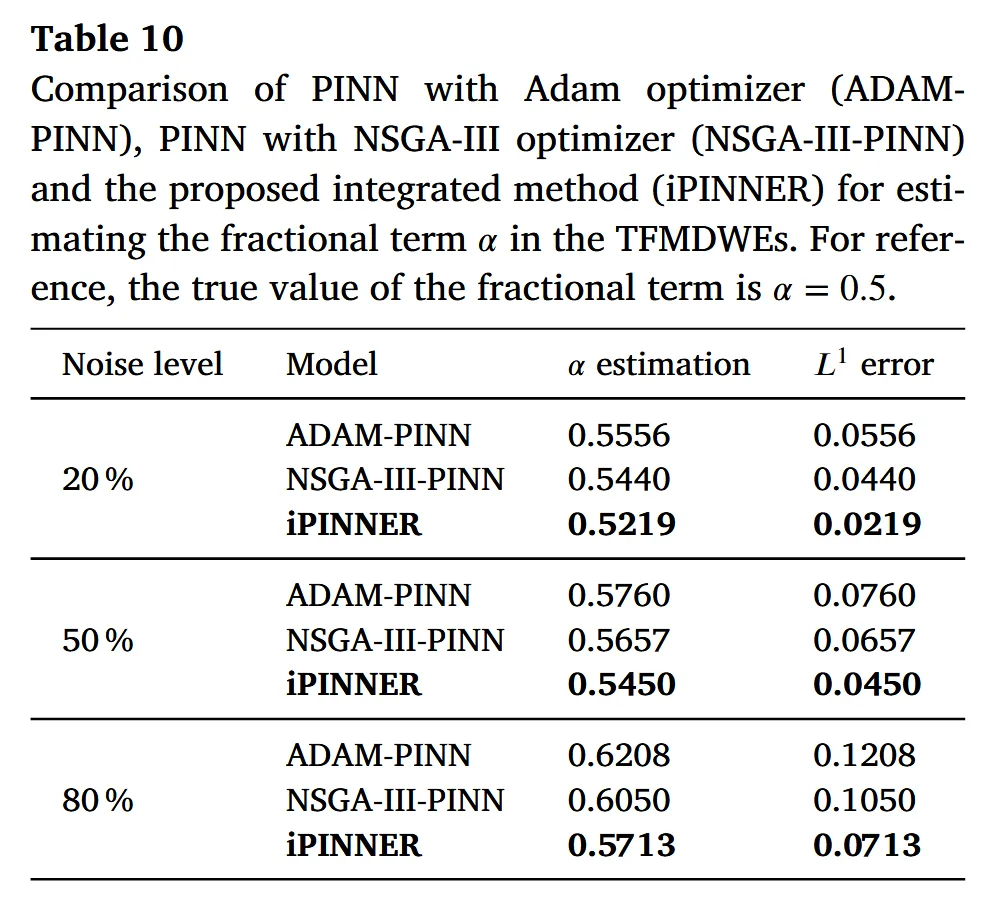
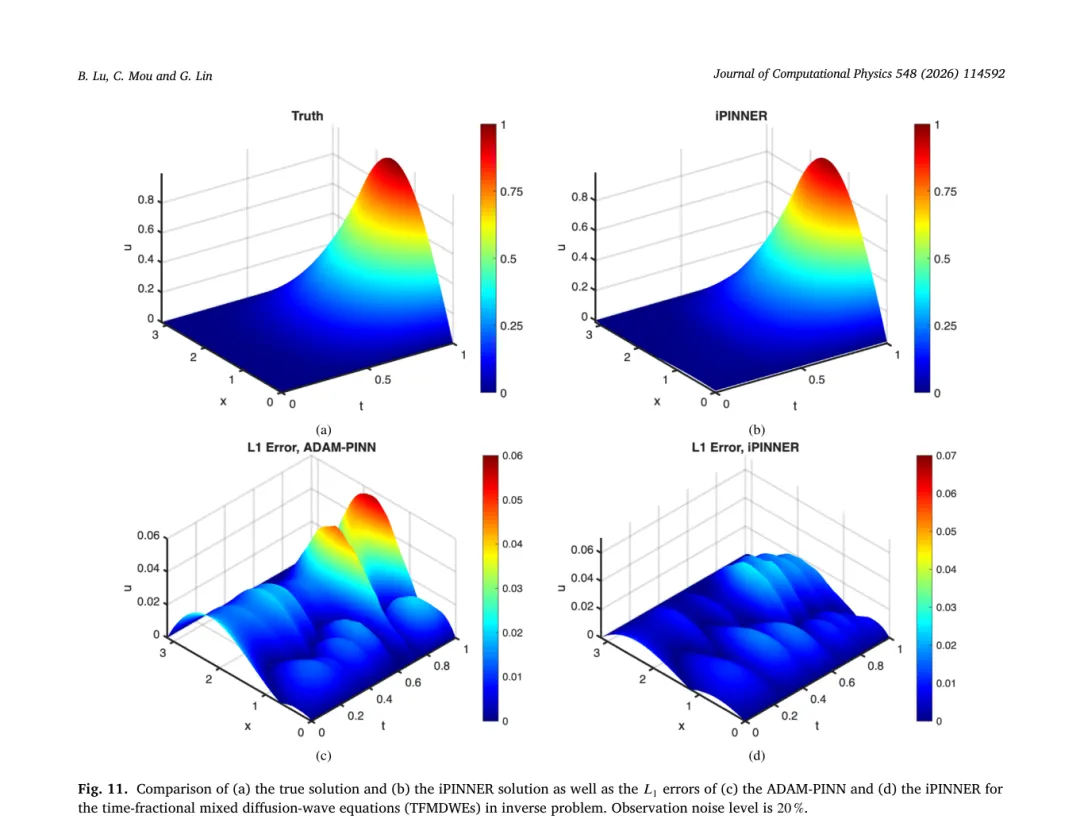
真实值为 0.5,iPINNER 在 20%、50%、80% 噪声下的估计误差分别为 0.0219、0.0450、0.0713,均明显优于其它模型。图 11 到 13 则分别展示了在 20%、50%、80% 噪声下真解与 iPINNER 估计的对比,以及各方法的误差分布;图 14 对不同时间截面上的预测进行了对比。可以看到 iPINNER 在整个时间域内都保持了更高的一致性。
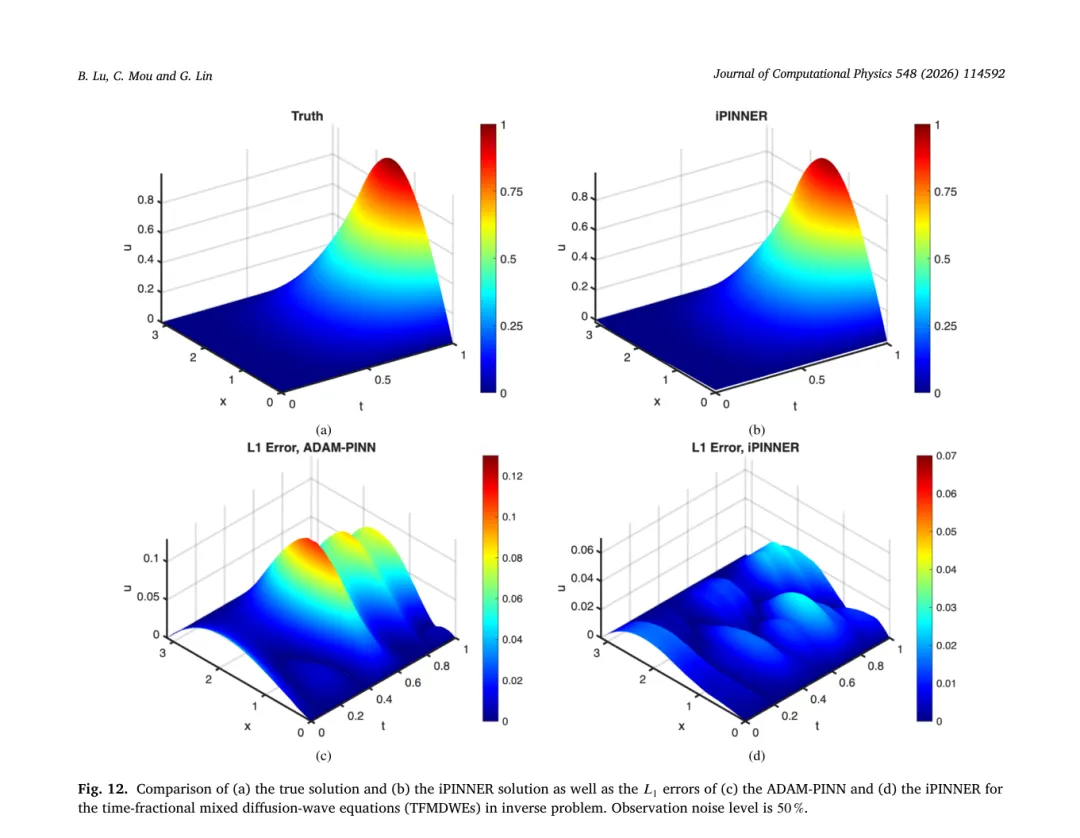
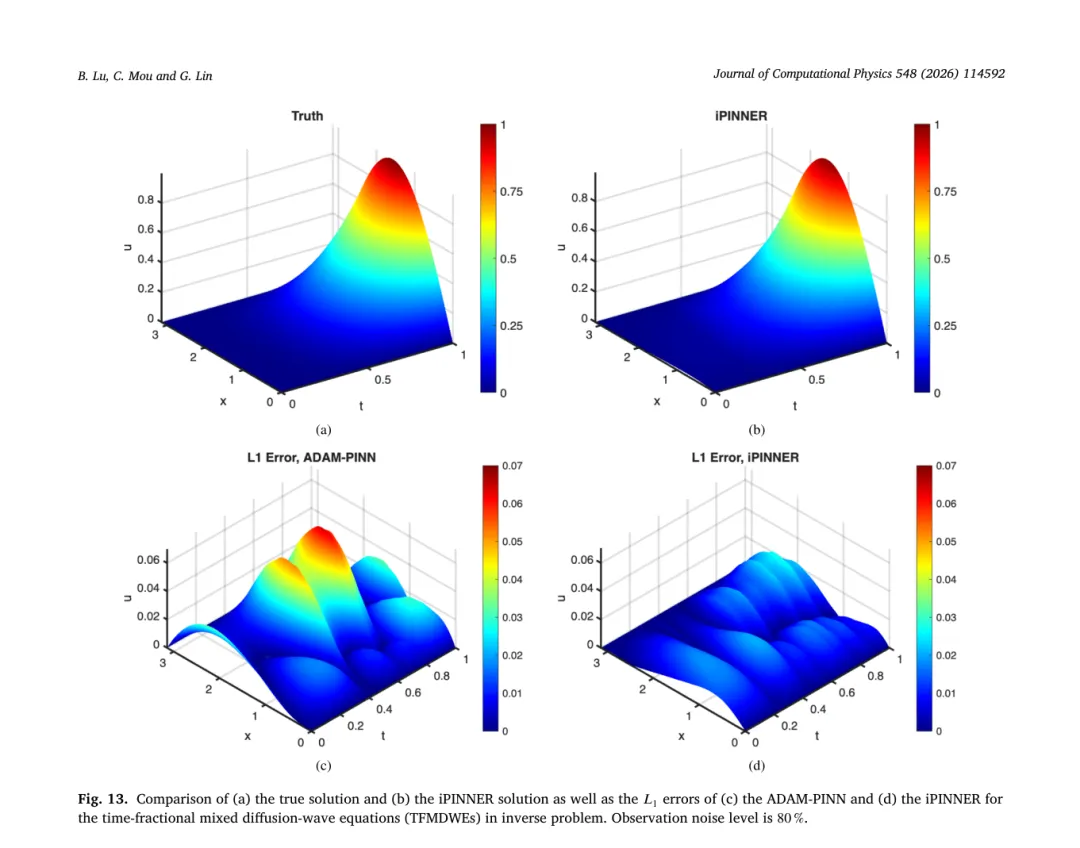
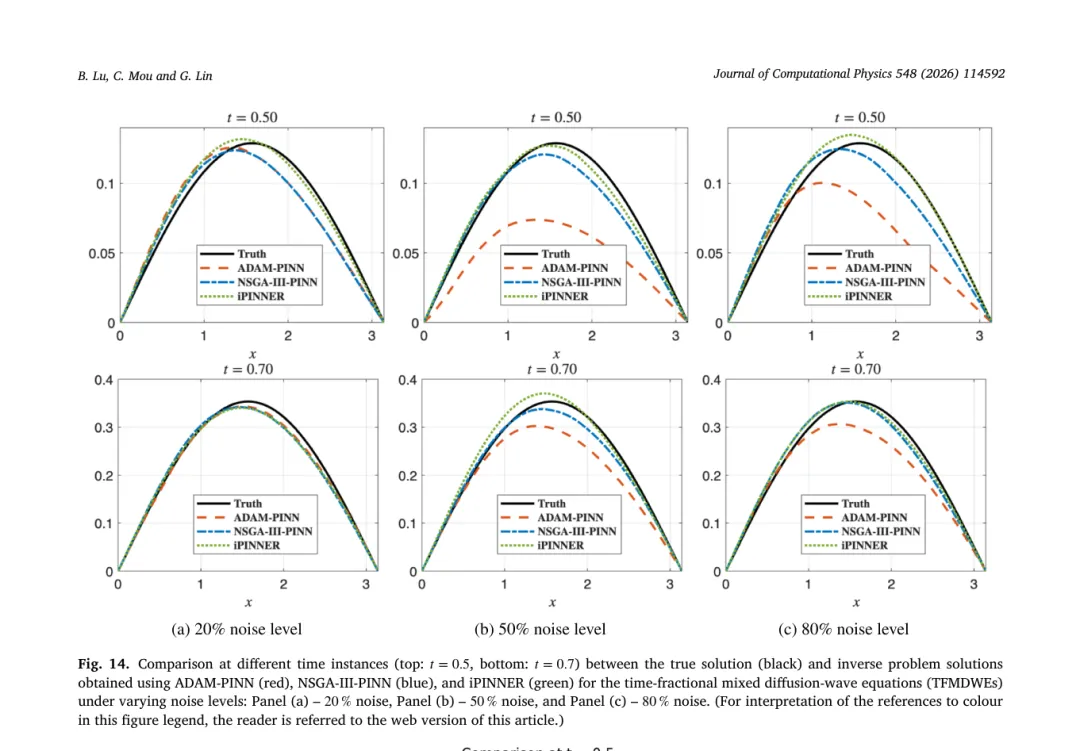
四、二维热方程测试
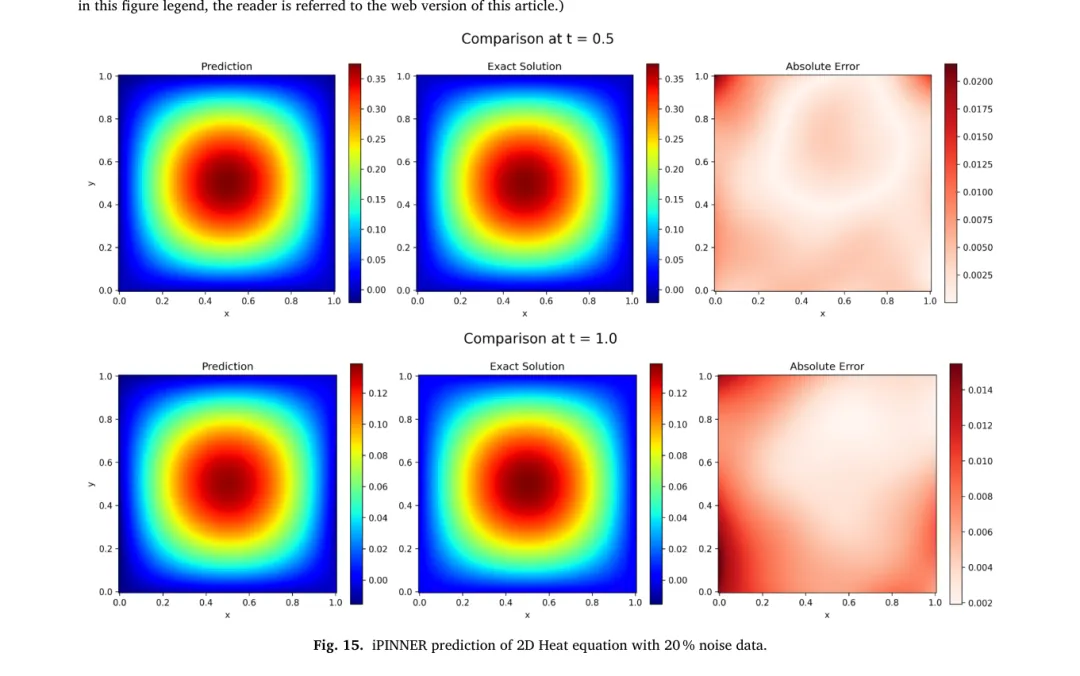
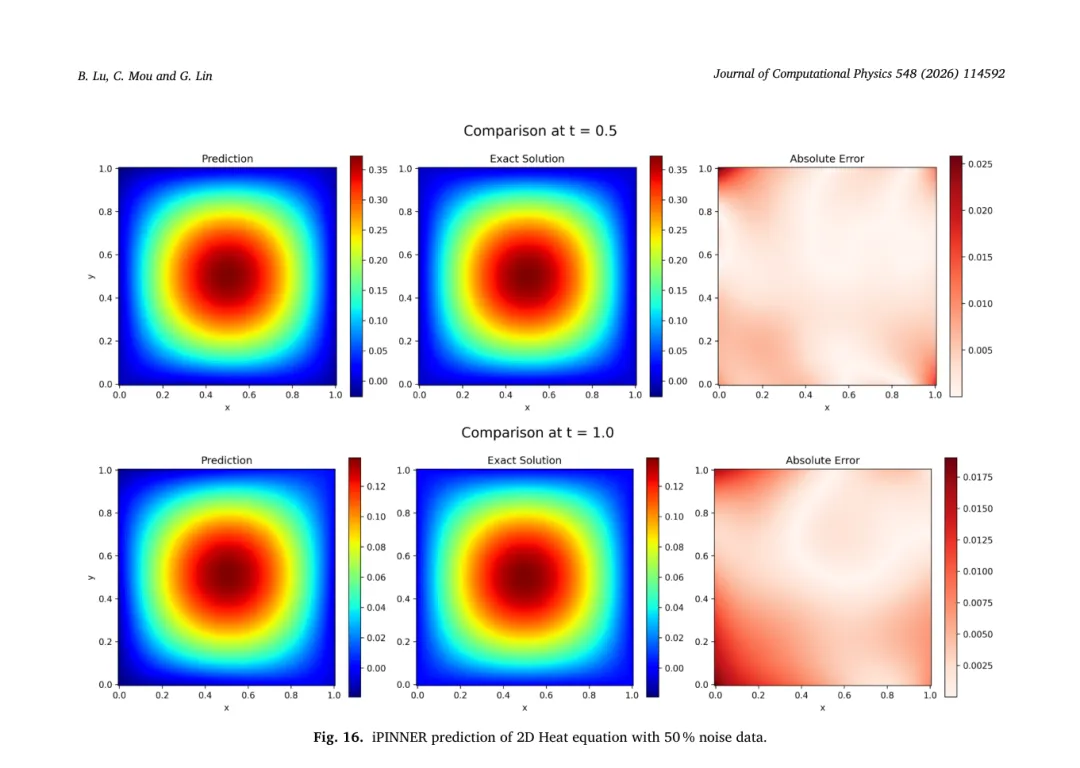
为了展示方法的通用性,作者还测试了二维单位方域上的热方程。该方程有已知解析解,可用于评估模型在更高维度上的表现。实验在 20% 和 50% 两种噪声下采样观测点,比较传统 PINN 与 iPINNER 的结果。图 15、16 分别展示了两种噪声条件下 iPINNER 预测的温度场和对应真解,右侧为 L1 误差分布。
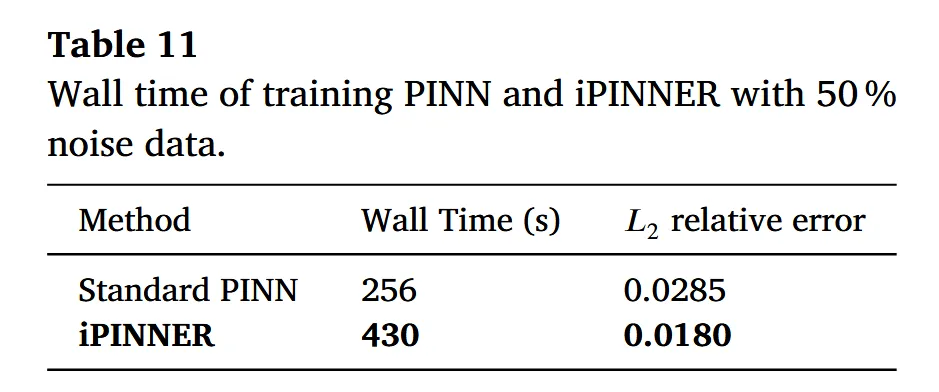
表 11 给出了训练耗时与相对误差:iPINNER 在 50% 噪声时的 L2 相对误差约为 0.018,而普通 PINN 为 0.0285。虽然 iPINNER 耗时更长,但精度提升明显。

研究结论

综上,iPINNER 在多种模型偏差和观测噪声场景下都取得了比传统 PINN 更优的结果。多目标优化提供了更均衡的损失权重,EnKF 将不同网络预测与观测融合,实现了对噪声的过滤;迭代流程使模型逐步逼近真实解。对于未知参数的反演,iPINNER 在噪声较低时优势明显,在噪声极高时仍难以完全恢复参数,提示观测质量的关键性。
论文评价 · 未来展望

领域贡献

① 提出将 NSGA‑III 与 EnKF 结合的迭代训练框架,为在噪声和模型不完全情况下解 PDE 提供了新的机器学习范式。
② 经实验验证,该框架在正问题和逆问题中均提升了预测精度与参数估计能力,并且适用于整数阶和分数阶方程以及二维问题,展示了较好的通用性。
③ 方法还表明,通过合理设计训练流程,可以在神经网络中引入不确定性量化和数据同化思想,这对于未来融合机器学习与传统数值方法具有启发意义。

局限不足

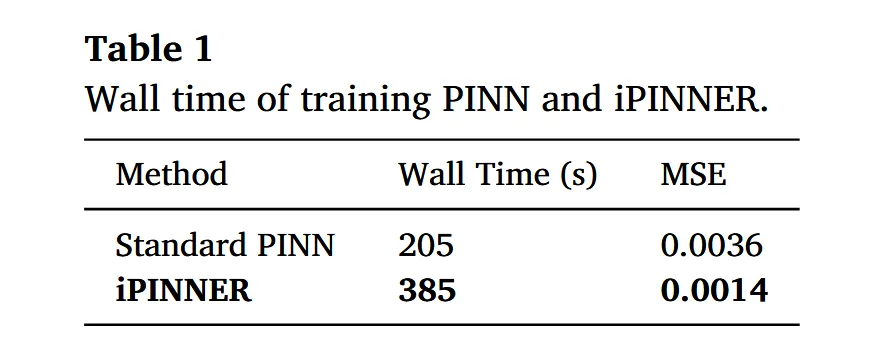
① 计算开销较大:由于 NSGA‑III 需要在每代评估多个候选网络,EnKF 还要操作整个集合作为样本,iPINNER 的训练时间明显高于普通 PINN(表 1 给出了一维问题的时间对比),尤其当集合规模增加时更为显著。作者通过并行训练各个网络在一定程度上缓解了这一问题,但仍需要高性能计算资源。
② 高噪声条件下的性能有限:当观测噪声高达 80% 时,模型和数据中的信息几乎被噪声淹没,即便有滤波过程,参数反演仍不准确,说明当前框架仍依赖于中等噪声水平才能充分发挥优势。
③ 需要手动选择 ensemble 大小:表 2 显示了不同集合大小对性能和训练时间的影响,虽然 8 个成员取得了较好平衡,但在更复杂问题上如何自适应选择合适的集合规模仍待研究。

未来方向

作者在论文结尾指出了几条值得探索的方向:
① 将未知物理参数作为网络输入,共同学习网络权重和参数分布,实现参数不确定性量化;
② 与贝叶斯 PINN 结合,显式建模训练过程中参数的后验分布,进一步提高对高噪声场景的鲁棒性;
③ 扩展到增量持续学习框架,使模型能够随着新数据的到来动态更新,适应长时间演化或实时监测场景。



# 启示与讨论>>
面对日益复杂的科学问题,你认为在神经网络中引入多少传统数值方法是必要的?欢迎在评论区留言!
启示①:多目标优化能平衡不同损失避免权重难调;
启示②:集成卡尔曼滤波可有效滤除观测噪声并校正模型;
启示③:迭代更新数据驱动项对正问题和逆问题均有益;
启示④:iPINNER 计算成本较高但可并行化;
启示⑤:高噪声场景下仍需改善方法鲁棒性。
声明:本系列推文仅代表个人解读与观点,旨在抛砖引玉,不代表研究团队立场。若内容涉及版权或事实错误,欢迎通过后台指正。


关注智核学术|少走弯弯路
↙↙↙ 点击下方 “阅读原文” 查看相关论文合集
