 夜雨聆风
夜雨聆风最近这两年,AI火了,网工圈也跟着卷了起来。大家都在聊大模型、聊GPU,当然也少不了一个绕不开的话题:数据中心网络到底该怎么搭,才能扛得住AI训练的海量流量?咱们这篇文章就来详细展开讲讲。
先聊聊背景。在过去的十多年里,Spine-Leaf架构(也就是大家常说的Clos网络)一直是数据中心网络的不二之选。
这套架构设计精巧,端到端路径开销基本对等,靠着ECMP(等价多路径)做负载分担,不管你有多少条流,哈希算法总能把它们打散到不同的链路上。对传统的微服务、东西向流量那些短小精悍的老鼠流来说,这套机制简直严丝合缝。
可问题在于,现代AI大模型的分布式训练,吃网络的方式跟以前完全不一样。
GPU之间跑的是AllReduce、AllGather这类集合通信。这些操作会产生大量长时间持续的大象流,而且它们往往在同一时刻被触发,扎堆往网络上冲。
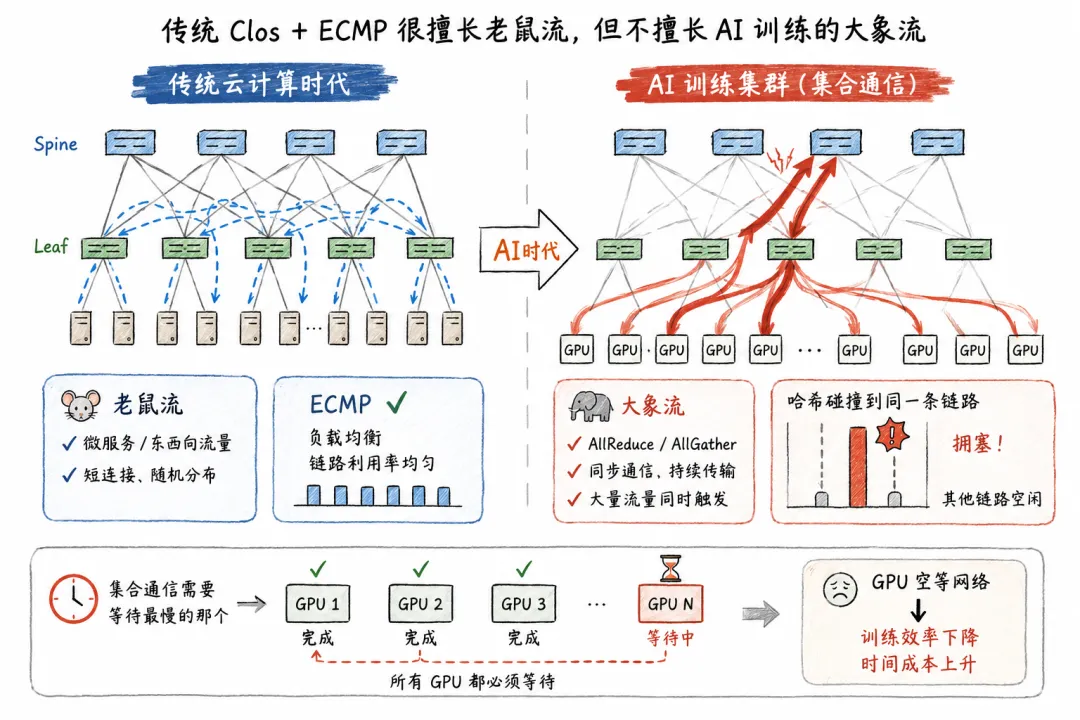
大家可以想象一下这个场景:上千个GPU同步开始交换梯度数据,多条巨型流被哈希算法凑巧撞到了同一条链路上。结果就是一条道堵得水泄不通,旁边的车道空空荡荡。ECMP毕竟不是交通指挥员,它不会思考,只会机械地计算哈希值。
在AI训练里,这种负载不均造成的后果很严重,一个链路的拥塞就会拖慢整个同步过程。毕竟在集合通信里,所有参与者必须等最慢的那个完成任务,整个训练步长才能继续往下走。最后的结果就是GPU在那儿干等着网络把数据送过来,算力白费,时间成本蹭蹭涨。
既然ECMP靠不住,那就别让流量随机乱跑了,给它分分道,这就是Rail-optimized架构的核心思路。
怎么分呢?很简单,给每块网卡分配一个固定的“车牌号”。
在8卡GPU服务器里,Rail-optimized的做法是,把所有服务器的第0号网卡划到Rail 0,所有第1号网卡划到Rail 1,依此类推,Rail 0的网卡只跟Rail 0的Leaf交换机相连。
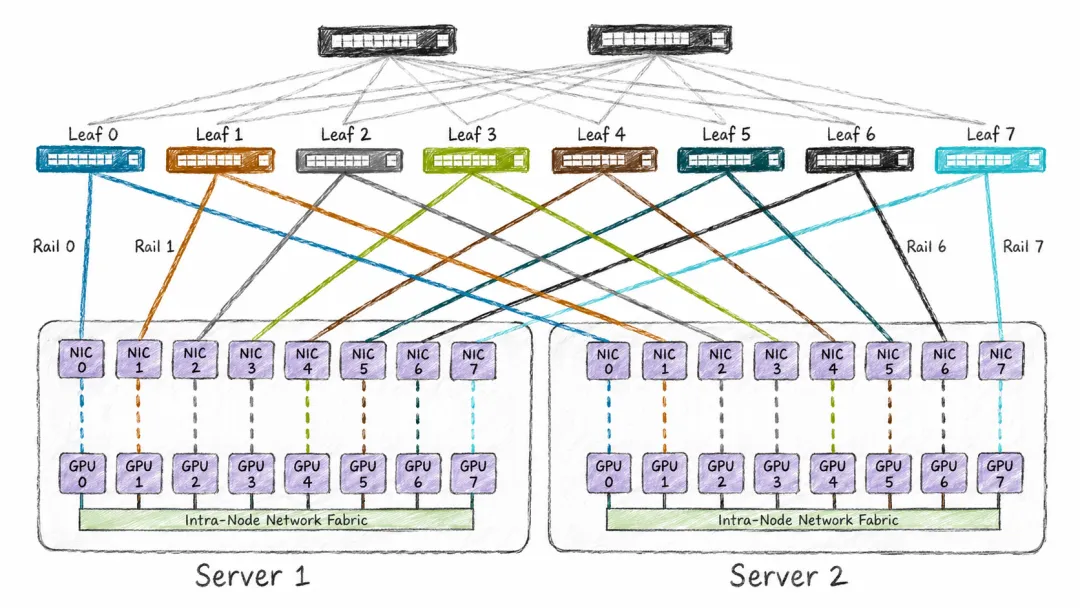
这样一来,逻辑关系就清晰了,Rail 0就像一条专属的高速公路,负责承载所有第0号网卡之间的通信。数据走哪条路不再是哈希随机的结果,而是提前约定好的。
这么设计有两个明显的好处。一是路径可预期,相同Rank的GPU之间的流量路径固定,延迟波动小,训练过程更稳定。二是故障和拥塞被隔离了,每个Rail是独立的故障域,一个Rail出问题不会拖垮整个集群。这点在RoCE环境里尤其重要,PFC(优先级流控)造成的队头阻塞是出了名的头疼,一个Rail出问题,至少不会连累别的。
说白了,Rail-optimized不是要把Clos推翻重来,而是在这个框架上做了一层“规训”。网络还是那张Clos网络,只是流量的走法被提前规划好了。
既然Rail-optimized好用,那能不能再往前走一步,直接把Spine交换机砍了?
这就是Rail-only。它的思路更激进,不同Rail之间不需要Spine做全互联,跨Rail的通信通过服务器内部的高带宽互联(比如NVSwitch)来转发。也就是说,跨Rail的流量本质上是在服务器内部绕了一圈再出去。
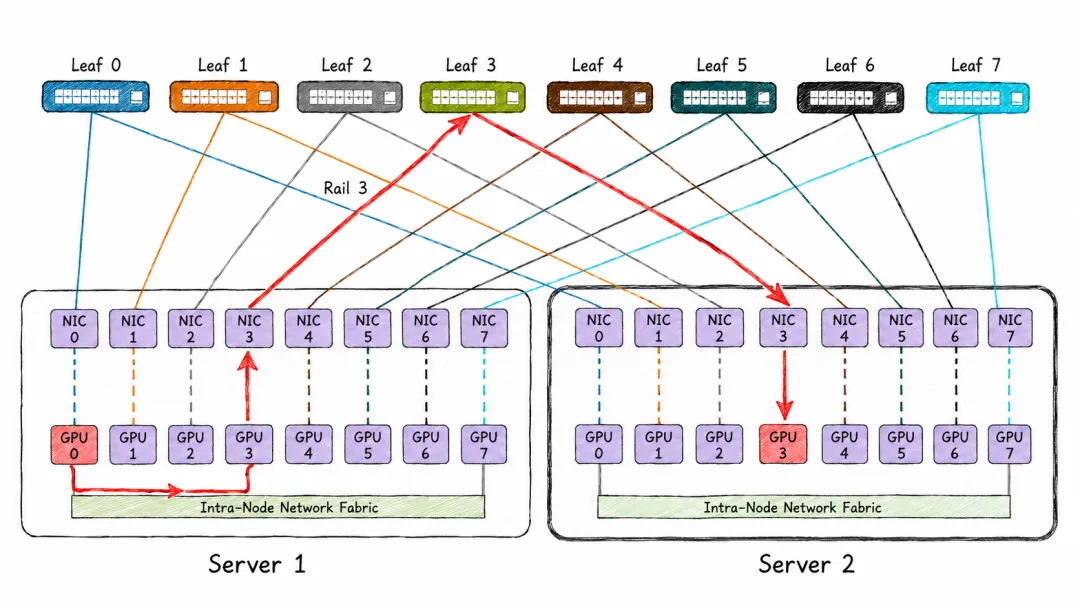
砍掉Spine层最大的好处,就是省钱。
MIT的研究人员早就算过这笔账,和传统的全互联Clos网络相比,Rail-only能把网络成本降低38%-77%,功耗降低37%-75%。对于动辄几万张GPU的集群来说,这可不是一笔小数目。
不过有得必有失。Rail-only牺牲了网络的全互联灵活性,相当于把宝押在了AI训练的通信模式足够可预测这个前提上。如果哪天业务变了,或者跑的是MoE这类需要频繁All-to-All通信的模型,这套架构就没那么舒服了。
所以目前Rail-only更多还是停留在研究和实验室阶段,真正在产线上大规模铺开的案例还不多。
Rail-optimized思路很好,但真落地的时候,麻烦事儿也不少。
首先,网络不再是负载无关的了。以前Clos架构下,网络只管转发,上层跑什么业务跟你没关系。现在Rail-optimized把网络和通信库(如NCCL)紧紧绑在了一起,NCCL必须感知到下面的Rail拓扑,才能正确地把通信任务调度到对应的路径上。这就要求网络团队和算法团队坐到一张桌子上商量,两边都得懂对方在说什么。
其次,故障处理没那么随意了。传统Clos网络里一条链路坏了,ECMP自动把流量切到别的路,多数情况下上层业务无感知。但在Rail架构下,每个Rail是独立的,一个Rail里的链路断了,整个集群的通信模式都要重新规划。恢复的时间窗口和复杂度都上了一个台阶。
还有,调参的坑更深了。PFC、ECN这些参数在Rail架构下的调优难度不比以前低。RoCE本身就脆弱,稍微配错一个参数就可能引发全网PFC风暴。
回过头来看,Rail-optimized的出现不是什么偶然。它反映了数据中心网络发展的一条主线,从通用化走向业务适配。
以前做网络设计,追求的是对上层业务透明,你负责计算,我负责转发,各管各的。但现在情况变了。在大规模AI训练这个场景里,网络不再是计算之外的附属品,而是分布式系统的一个有机组成部分。网络的拓扑结构、拥塞控制策略、甚至转发路径的选择,都在深刻影响着上层计算的效率。
Clos不会消失,它依然是最稳健的基础框架。只是在AI这个新的算力引擎面前,网络工程师需要跳出只管连通性的舒适区,开始理解GPU的Rank、理解集合通信的算法、理解并行策略对流量分布的影响。
说白了,未来的网络工程师可能要半只脚踏进AI算法的门了。不过话说回来,网工这个职业,过去三十年哪天不是在跟着业务的需求变呢?从路由交换到SDN,从云原生到AI Infra,变的是技术栈,不变的是解决问题的本事。
Rail-optimized不是终点,它只是这场变革的一个注脚。 下一个十年,还有更多有意思的东西等着我们去折腾。
参考:
Phil Gervasi, Rail-Optimized Networking for AI Training Workloads
