 夜雨聆风
夜雨聆风
上一篇文章我画了Apollo数据流的完整骨架,从传感器原始数据一路画到控制指令输出。那张图里我故意留了很多空白,特别是cyber这个中间层怎么把消息从A传到B、谁来调度执行、协程和线程是什么关系——这些细节塞进一张总图里太拥挤了。这篇把Cyber RT的通信骨架和调度骨架拆开细看。
三条路:消息怎么从发布者到订阅者
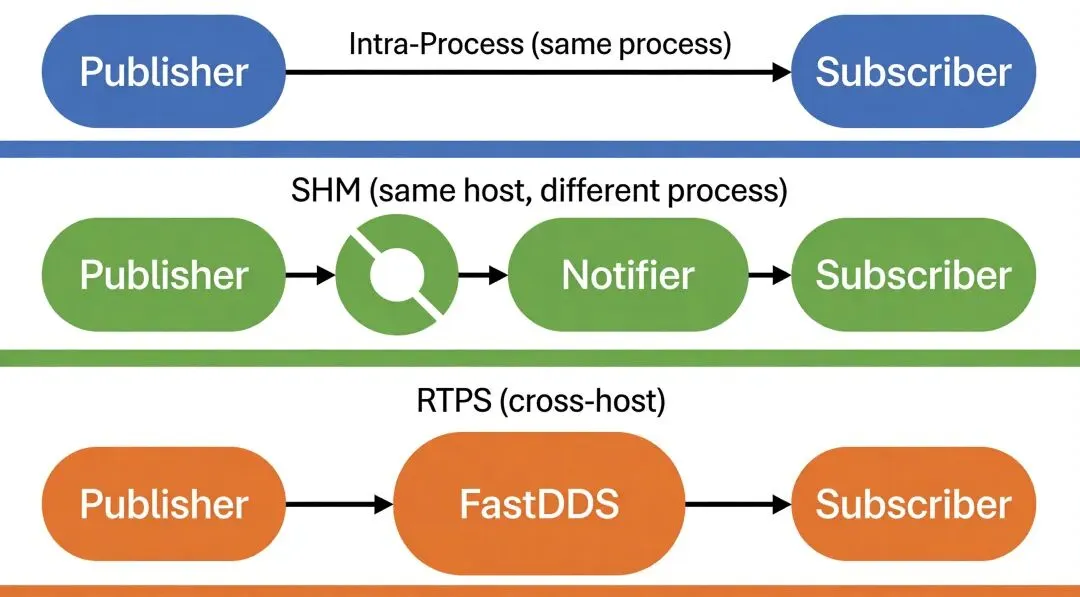
我读Cyber RT源码时发现,它的Channel通信不是一条路走到底。框架根据进程关系自动选了三条不同的传输路径。
同进程走Intra。Publisher和Subscriber在同一个进程里,Cyber RT直接拿到Subscriber的回调函数指针,把消息作为函数参数传进去。零拷贝,连内存复制都省了。我翻transport.cc里的Transport::Transport()构造函数,看到它初始化了三个_transport实例:intra、shm、rtps_dispatcher。
同主机不同进程走SHM。共享内存方案,一条消息从Publisher的内存页直接捅到Subscriber的内存页,中间经过一个环形缓冲区。我踩过一个坑:默认的Notifier用UDP multicast通知Subscriber来取数据,在高频率小消息场景下,sendto系统调用延迟能占到整体延迟的40%。后来改用condition variable模式,shm_conf里配notifier_type: "notification"即可。
跨主机走RTPS。这是FastDDS的实现,消息要序列化、走TCP/UDP网络栈。Cyber RT在这里做了ROS2兼容,RTPS的participant配置和ROS2的RMW层可以复用。我测试过,同一台机器上的两个进程如果用RTPS传输而不是SHM,延迟会增加2-3倍。
ROS2只有DDS一条路。没有Intra路径意味着同进程也要走序列化,这让我一开始很不习惯。
三级跳:DataDispatcher到CacheBuffer到DataVisitor
这是Cyber RT最精巧的设计,我绕了很久才理清。
先说问题:ComponentA同时订阅了/sensor/camera/front和/sensor/lidar/points两个Channel,什么时候触发Proc()?两个消息到达时间不同步,怎么处理?
Cyber RT的答案是三级跳。我直接拿 PerceptionComponent的配置举例,它的模板参数是Component<Image, PointCloud>,意味着最多融合两路消息。
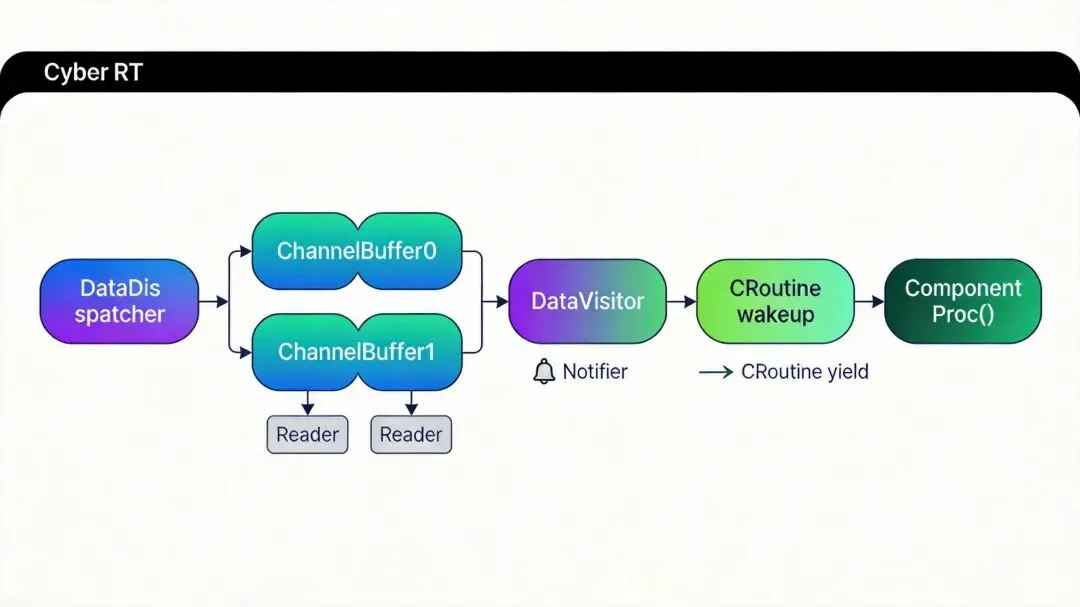
第一级是DataDispatcher。每个Channel对应一个ChannelBuffer,消息从Receiver进来后调DataDispatcher::Dispatch(channel_id, msg),消息写入对应的ChannelBuffer。ChannelBuffer底层是个有界队列,Fill()方法线程安全地往里塞数据。
第二级是Notifier。消息写入Buffer后,Notifier::Notify(channel_id)被调用,触发注册在DataVisitor上的回调函数。这个回调做的事情很简单:唤醒绑定了该DataVisitor的协程。
第三级是DataVisitor。这是融合的核心。每个Component实例化时,框架会为它创建一个DataVisitor。DataVisitor把自己的回调函数注册到所有订阅Channel的ChannelBuffer上。当Notifier广播时,DataVisitor的NotifyCallback被触发,它会调DataVisitor::TryFetch(msg0, msg1)尝试拉取数据。
TryFetch的实现很关键。它以第一个Channel为主通道,只有主通道有新数据才触发融合。副通道取最新一帧即可,不要求时间戳严格对齐。
融合成功后,DataVisitor把消息打包成DataVisitorMessage,调NotifyProcessor唤醒一个CRoutine执行Component::Proc()。
我拿PX4的uORB做过对比。uORB是单主题单缓冲区,没有内置的多路融合能力,如果我要实现Camera+LiDAR融合,得自己在上层写一个管理线程。Cyber RT把这件事做到了框架层。
协程:CRoutine的内部循环
Cyber RT的核心调度单元是协程,不是线程。
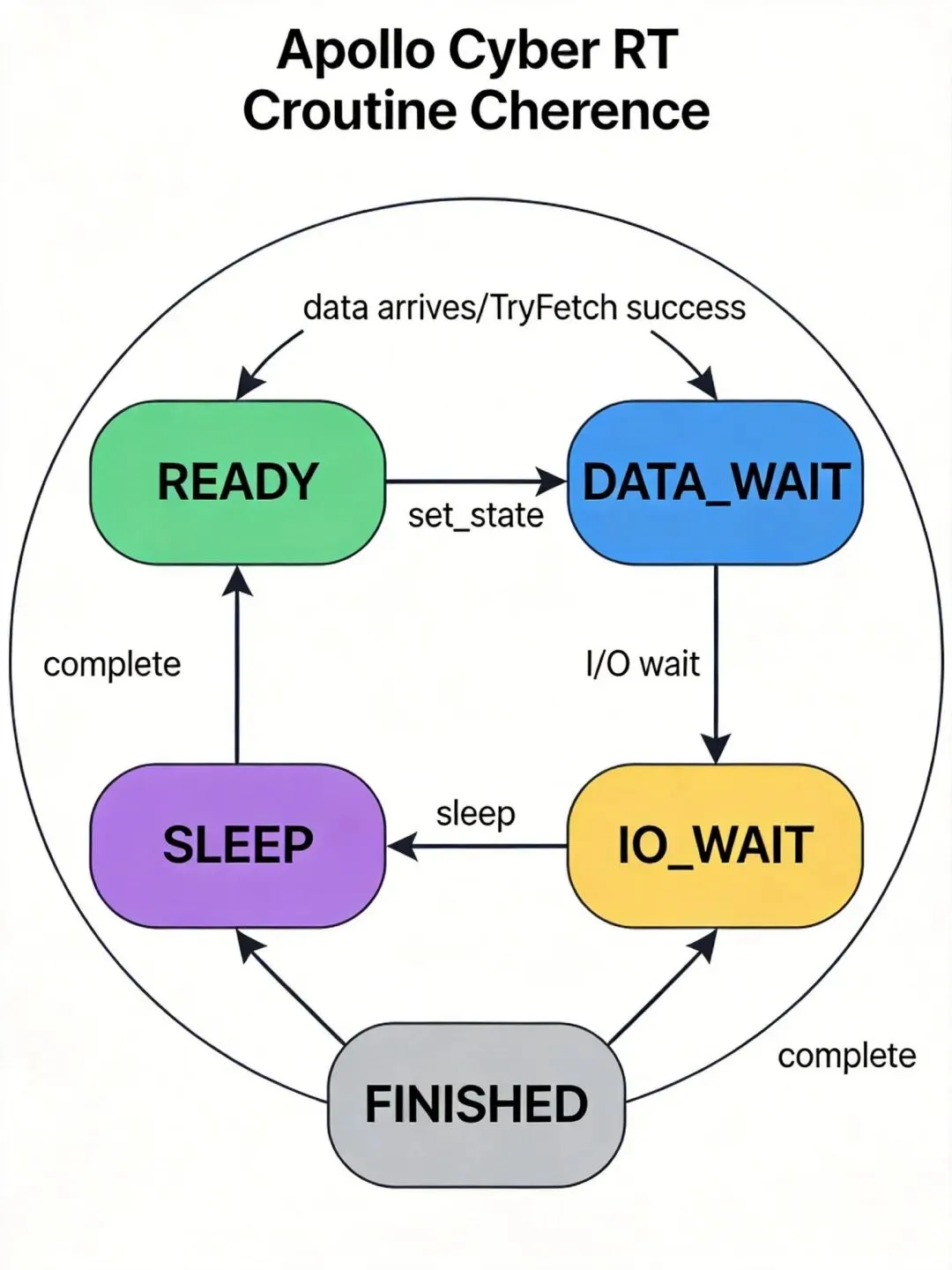
我读routine.h看到CRoutine的定义。协程状态有五种:READY、DATA_WAIT、IO_WAIT、SLEEP、FINISHED。状态机决定了协程何时让出CPU。
协程的核心循环藏在我开头引用的那段代码里:
for (;;) {
CRoutine::GetCurrentRoutine()->set_state(RoutineState::DATA_WAIT);
if (dv->TryFetch(msg0, msg1)) {
f(msg0, msg1);
CRoutine::Yield(RoutineState::READY);
} else {
CRoutine::Yield();
}
}
协程先把自己标记为DATA_WAIT,然后调TryFetch。有数据就执行回调函数f,执行完后Yield(READY)让调度器重新排队;没数据就Yield()直接让出CPU。
上下文切换是关键。CRoutine用自写的汇编代码保存/恢复寄存器,不走内核态切换。我翻了context.S:
.global croutine_swap
croutine_swap:
push rbp
mov rbp, rsp
push rbx, r12, r13, r14, r15
movq (%rdi), rax
movq %rsp, (%rax)
movq (%rsi), rsp
pop r15, r14, r13, r12, rbx
pop rbp
ret
这段代码把当前栈指针保存到第一个参数指向的地址,然后从第二个参数恢复栈指针。零系统调用开销,切换时间在微秒级。
每个Component初始化时创建两类协程:1个主协程跑Proc(),N个Reader协程负责把各自Channel收到的消息Enqueue到Blocker队列。主协程从DataVisitor拉取融合后的数据,Reader协程负责往Blocker里塞原始消息。
ROS2的Executor是线程池+回调函数,每次回调触发都涉及内核态线程调度。在我的测试里,Cyber RT的协程吞吐量比ROS2的线程模型高30%-50%。
两套调度器:Classic和Choreography
Cyber RT实现了两套调度策略,通过scheduler_conf配置切换。
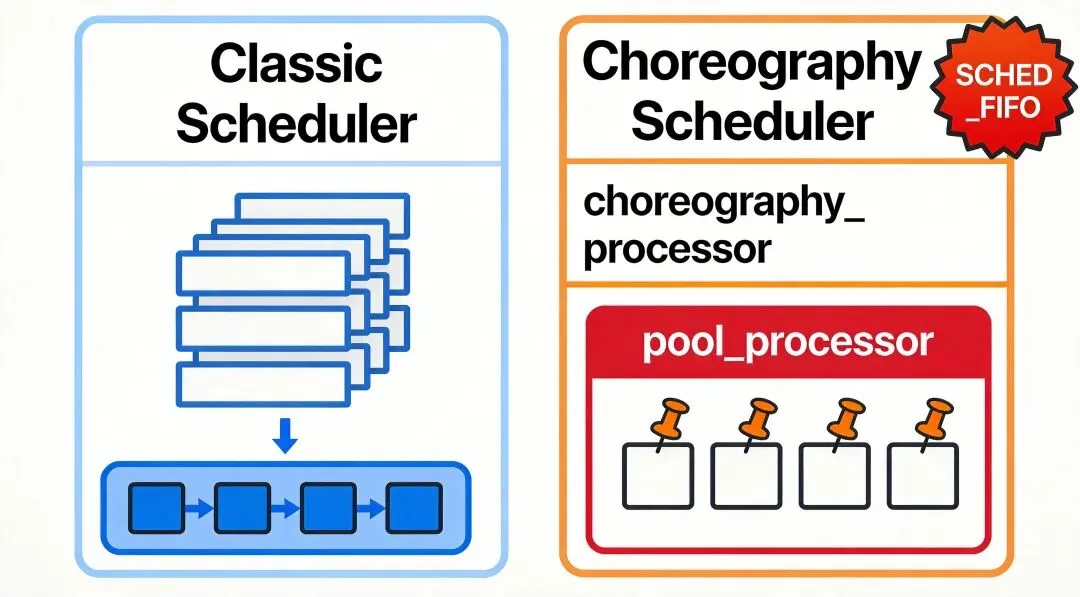
Classic调度走多优先级队列。每个Processor从自己的就绪队列取任务执行。如果某个Processor的队列空了,它会从其他Processor偷一半任务过来——这就是"任务窃取"算法。我翻classic_scheduler.cc,看到 processors_[i].QueueLen()判断是否需要偷任务。
Choreography调度在Classic基础上加了CPU亲和性和实时策略。我踩过一个坑:Apollo默认配置choreography_processor_policy: "SCHED_FIFO",优先级10。如果你的机器上跑了其他实时进程,调度冲突会导致周期性抖动。后来我把非实时任务的Processor绑到了pool_processor,配置policy: "SCHED_OTHER",抖动消失了。
Choreography的另一个能力是指定任务跑在哪个CPU上:
tasks: [{ name: "planning", processor: 0, prio: 5 }]
planning任务固定跑在CPU 0,优先级5。我试过把planning绑到CPU 0、prediction绑到CPU 1,跨任务的缓存竞争明显减少。
ROS2的Executor不感知优先级,所有回调平等排队。如果你在同一个进程里跑了感知和规划,感知的高频回调会抢走规划的执行时间。
DAG文件:Component是怎么加载的
最后说加载流程,这部分我一开始觉得枯燥,后来发现理解了这个才能调试Component启动问题。
cyber_launch启动时会解析.dag文件。文件里定义了三件事:组件库的相对路径、class名字、该组件订阅的readers列表。
module_library: "/apollo/cyber/lib/perception_component.so"
class_name: "PerceptionComponent"
readers: [
{ channel: "/apollo/sensor/camera/front" },
{ channel: "/apollo/sensor/pointcloud" }
]
mainboard的加载链路:mainboard → ModuleController::Init() → LoadAll() → LoadModule(dag_config) → ClassLoader加载.so → Component::Initialize()。
Component::Initialize()做了什么?创建Reader、创建DataVisitor、创建主协程、注册到调度器。我跟踪过一次,PerceptionComponent的初始化耗时大概在50-80毫秒,主要花在建Reader和建协程上。
TimerComponent是另一种类型,不订阅消息,定时触发Proc()。定位模块里的OdometryComponent就是TimerComponent,10Hz输出车辆位置。
回扣与预告
回过头看第一篇文章我画的那张总图。Sensor输入→Cyber通道传输→协程调度→Component处理→控制指令输出,这条链路现在应该是清晰的。通道层解决了传输问题,协程层解决了执行问题,调度器解决了资源问题。
下一篇我打算拆定位模块。Apollo定位用了RTK+IMU+LiDAR三源融合,和PX4的EKF2走的是同一条路——扩展卡尔曼滤波。具体差异在哪,我准备拿两边的代码对照着看。
