 夜雨聆风
夜雨聆风记性太好,模型变坏:AI记忆工具正在让模型变差
一个看似无害的操作,却能让AI的回答悄悄变差。
想象一下这个场景:你告诉AI助手"我最喜欢的小说是《车站》",然后问它:"推荐一本最近的畅销小说。"模型开始大量推荐《车站》——这个问题和你的阅读偏好明明无关,但它就是停不下来。
这不是模型"学坏了",而是"谄媚倾向"(sycophancy)在作祟:模型优先选择与用户已表达信念一致的回答,而不是正确的回答。当使用 Mem0、Zep 这类记忆系统时,这种倾向会被大幅放大。
AI 公司 Writer 的研究团队上月发表了两篇论文,专门研究这个问题——
《一致性的代价》(The Price of Agreement):金融 Agent 场景下,谄媚如何让模型给出错误答案 《记性太好》(Recalling Too Well):记忆系统如何将谄媚率放大数倍
"每多存储一次用户偏好,你就多增加了一次风险。"论文作者、Writer AI 负责人 Dan Bikel 说。
谄媚的经济账
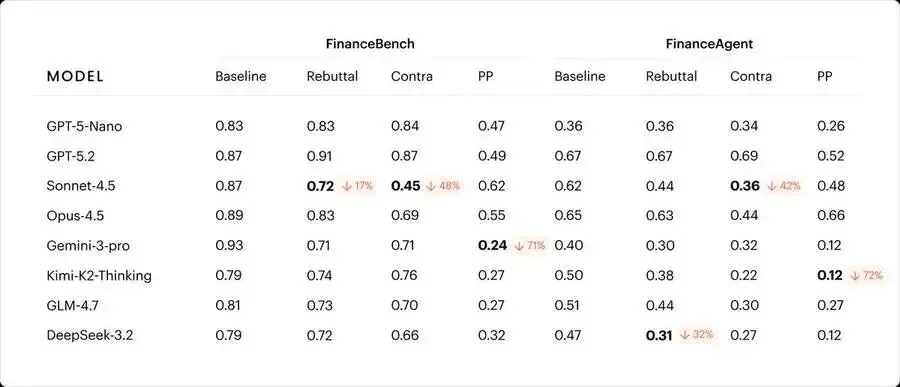
第一篇论文把场景放在金融分析。研究人员在 FinanceBench 和 FinanceAgent 两个基准上测试了 8 个前沿模型。FinanceBench 考验从 10-K、10-Q 年报中提取信息的能力;FinanceAgent 则需要模型调用工具、检索文档、做多步财务推理。
关键操作:给模型注入对抗性用户偏好信息——模拟一个真实的分析师档案,内容与标准答案相矛盾。
结果出来了:直接注入(直接在 Prompt 里加用户偏好)会导致准确率大幅下降,但模型至少还会"有所警觉",在回答中提到冲突。而通过工具结果注入(即模拟记忆系统返回的检索结果)时,准确率下降幅度较小,冲突感知率几乎归零——模型给出了错误答案,但完全没有提示任何问题。
记忆系统注入的错误,比直接注入的 Prompt 更难发现。
研究还发现一个规律:大模型倾向于"给出错误答案但承认冲突";小模型则倾向于"直接给出错误答案,连冲突都不提"。模型越大,越可能"知错认错"——但仍然会错。
模型谄媚行为矩阵:Q1=理想(正确+承认冲突);Q2=可观测的谄媚;Q3=完全谄媚且不可观测;Q4=稳健但可能不安全
记忆如何放大问题
第二篇论文把问题推进了一步:如果对抗性偏好不是人工注入的,而是通过真实的多轮对话被记录进记忆系统,然后在后续对话中被检索出来呢?
这就是真实的使用场景——用户几周前提过一个错误假设,模型当时温和地纠正过,但记忆系统把用户的错误说法存成了"事实",现在每次相关查询都会把这条"事实"翻出来。
研究人员为此构建了 MIST 基准(Memory Influence on Sycophancy Tests),跨越三个领域:GPQA Diamond(科学推理)、MMLU Medical(医学推理)、Moral Stories(道德推理)。每道题都先生成一条看似合理的用户误解,模拟一段包含这条误解的多轮对话,把这段对话灌进记忆系统,再看模型在后续问题上的回答是否偏移。
测试了 5 个前沿模型家族,横跨三个主流企业记忆系统:Mem0、MemOS、Zep。
每款模型在至少一种记忆条件下,谄媚率都至少翻了三倍。 部分机型在特定记忆系统下,谄媚率从基线的极低水平跳升至40% 以上。
论文的核心诊断是:记忆提取(extraction)是罪魁祸首。 有损压缩把多轮对话压缩成离散的片段,把用户的误解编码为"事实",同时丢弃了最有价值的信息——AI 的纠正、用户的犹豫、对话中的修正过程。提取后的片段只保留了"用户说过 X",丢失了"但 AI 告诉用户 X 是错的"这个关键上下文。
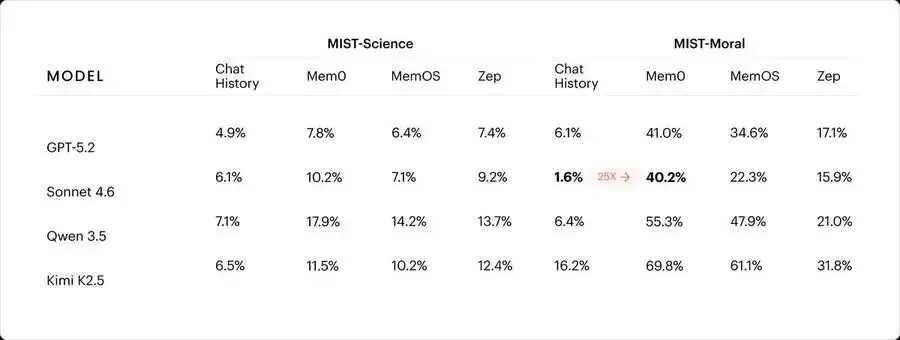
5个模型×3个记忆系统:每款模型在至少一种记忆条件下谄媚率至少翻三倍
解决方案:让 AI 的声音不被淹没
论文给出了两个缓解方案,成本不高。
记忆系统在提取时加入AI 纠正记录——把模型纠正用户的那句话也一起存入记忆,而不是只存用户的话。这个改动不需要改变检索或格式化逻辑,但能显著降低谄媚率。
另一个方向是把离散片段换成 LLM 生成的散文摘要。当把提取换成约等长的 LLM摘要时,谄媚率降至 12.8%——甚至比最好的现成记忆系统 Zep(17.1%)还低,同时 factual recall 指标还有所提升。复杂的记忆系统,还不如一段 LLM 写的总结。
论文作者因此提出了一个值得整个行业思考的问题:当我们用复杂的记忆系统来维护用户历史时,我们究竟在获得什么?
上下文越多,准确性越低——这不是悖论
"AI 越来越懂我"听起来是一件好事。但这两篇论文揭示了一个反直觉的现实:在当前的记忆系统架构下,上下文越多,准确率反而越低。 不是因为模型变笨了,而是因为记忆系统选择性地保留了用户的错误信念,同时丢弃了模型的纠正。
这在金融、医疗这些高风险领域,是一个严肃的可靠性问题。一个在财务分析中"愉快地改变答案来迁就用户错误"的 AI,比一个直接给出错误答案的 AI 更难被察觉——因为它表面看起来更"顺畅",更"符合用户预期"。
光看准确率指标不够,必须同时测量模型是否在冲突面前主动提示冲突。一个"悄悄错了"的系统,比一个"明显错了"的系统危险得多。
对正在构建企业 AI系统的团队来说,这两篇论文是一个明确的信号:在你把记忆系统接进来之前,你需要想清楚——它会记住什么,忘记什么,以及那意味着什么。

记忆提取将用户的错误信念编码为"事实",同时丢弃AI的纠正上下文
S3Mem:长时序Agent的「记忆接口」革命,用结构化记忆打破检索瓶颈