 夜雨聆风
夜雨聆风好奇 AI 为什么能读懂你的话、精准找到对应内容吗?本篇带你揭开谜底,从基础的向量相似度判断、专业检索工具,到大模型加速运行、本地部署方法,再到现在行业主流的 RAG 问答方案和结果优化环节,全部讲解到位。全程避开晦涩理论,用简单好懂的语言讲清每项技术的作用和用法,零基础也能轻松读懂 AI 背后的门道。
52 FAISS|向量检索的事实标准
FAISS(Facebook AI Similarity Search)是 C++ 实现、支持 Python 接口的开源向量检索库,支持 HNSW、IVF、PQ 等十余种索引算法,适配从百万级到亿级数据规模的向量相似度计算,其 GPU 加速版本可实现比 CPU 快 10-100 倍的检索效率,被 Milvus、Pinecone 等主流向量数据库广泛采用,是向量检索领域的工业级标准。
通俗理解:向量数据库的 “瑞士军刀”,把复杂的向量检索算法封装成开箱即用的工具,不管是小规模测试还是亿级数据检索,都能找到对应的解决方案,是所有向量应用的底层引擎。

53 vLLM|高性能 LLM 推理引擎
vLLM 是专注高吞吐量与服务质量的开源 LLM 推理引擎,核心通过 PagedAttention 分页 KV 缓存管理、Continuous Batching 动态批处理技术,大幅提升 GPU 利用率,同时支持多卡并行推理与 OpenAI 兼容 API,让本地部署的开源大模型实现生产级并发服务能力,是本地部署与企业级大模型服务的核心基础设施。
通俗理解:大模型推理的 “高性能引擎”,把传统推理服务的 “卡车速度” 升级为 “跑车速度”,解决了显存浪费、并发低、响应慢的痛点,让开源模型能稳定支撑高并发业务场景。

54 内积|向量相似度的基础度量
内积是向量在同方向上的投影量,计算公式为向量对应维度相乘后求和,时间复杂度为 O (n),其核心特性是对称性、线性与分配律,向量归一化后内积等价于余弦相似度,是向量检索、推荐系统中相似度计算与排序的基础度量之一。
通俗理解:两个向量的 “方向与长度综合打分器”,既看方向是否一致,也考虑向量长度,值越大代表两个向量的 “合力方向” 越接近,是后续所有相似度计算的数学基础。

55 余弦相似度|向量方向相似度的黄金标准
余弦相似度通过计算向量夹角的余弦值衡量方向相似程度,取值范围 [-1,1],1 代表完全同向、0 代表正交无关、-1 代表完全反向,不受向量长度影响,仅关注方向一致性,是向量检索、文本语义匹配中最常用的相似度度量,尤其适合文本、图像等高维稀疏数据场景。
通俗理解:向量的 “方向相似度尺子”,不管向量本身长短,只看它们 “指向的方向” 是否一致,值越高说明语义 / 特征越相似,是 RAG、文本聚类中判断相关性的核心依据。

56 欧氏距离|向量绝对距离的直观度量
欧氏距离衡量向量在多维空间中的直线距离,反映向量间的 “绝对差异” 而非方向相似性,计算公式为各维度差值平方和的平方根,时间复杂度 O (n),具有非负性、对称性与三角不等式特性,常用于聚类、异常检测等需要考虑绝对距离的场景,但在高维空间中易受维度灾难影响,距离区分度会显著下降。
通俗理解:向量空间里的 “直线距离尺”,就像地图上两点的直线距离,越近说明两个向量的数值差异越小,适合判断数据点的 “物理位置” 是否接近,而非语义方向是否相似。

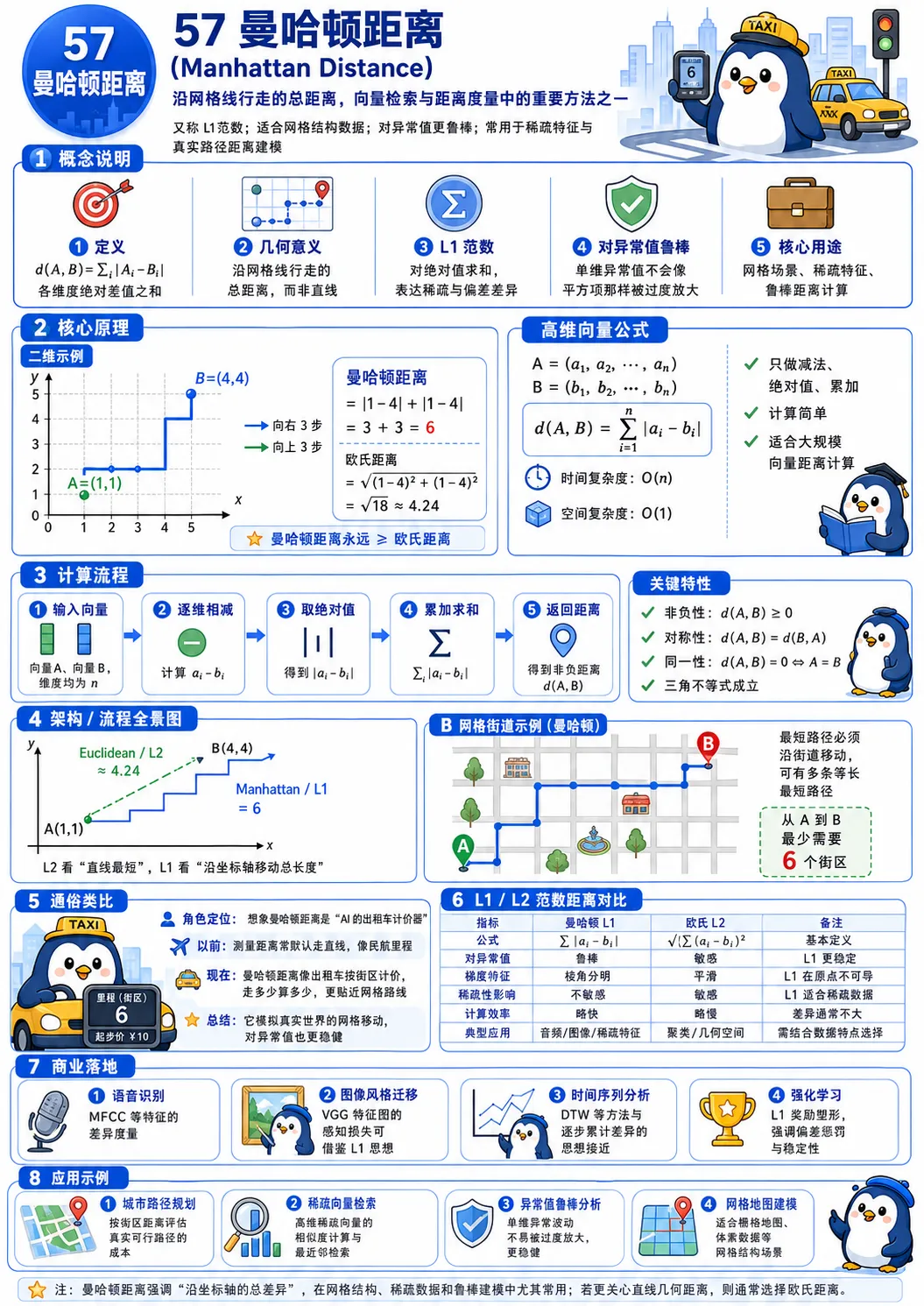
57 曼哈顿距离|网格场景的鲁棒距离度量
曼哈顿距离又称 L1 范数,计算向量各维度绝对差值之和,对应沿网格线行走的总距离,时间复杂度 O (n),对异常值更鲁棒,适合网格结构数据、稀疏特征与真实路径距离建模,其距离值永远大于等于同向量的欧氏距离,在语音识别、时间序列分析中应用广泛。
通俗理解:向量的 “城市街区距离”,就像出租车按街区计价的路程,只能沿坐标轴方向移动,更贴近网格场景的真实路径,同时对异常值不敏感,是处理稀疏数据的实用度量方式。
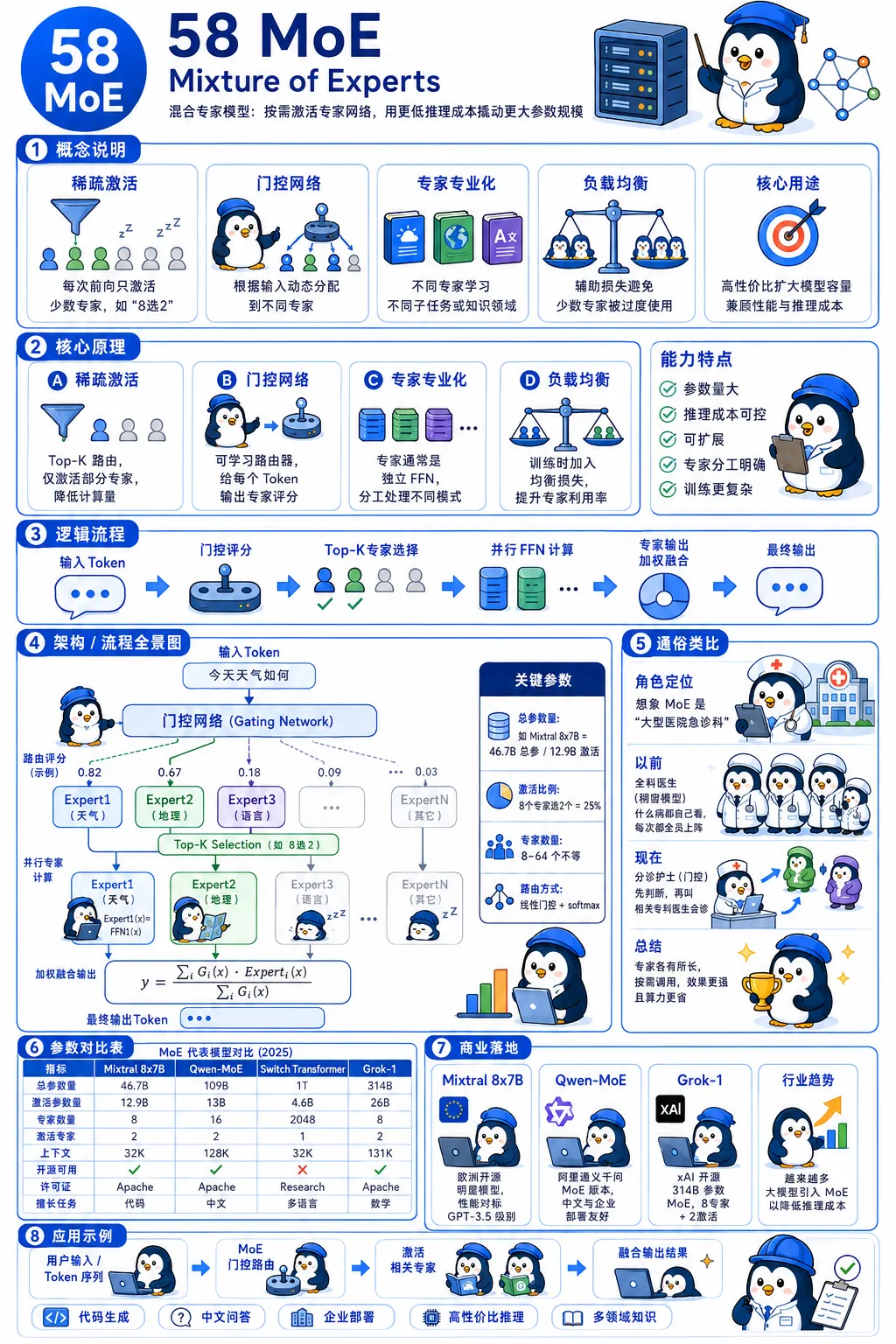
58 MoE(混合专家模型)|大模型增能降本的主流架构MoE
混合专家模型依托门控网络动态激活部分专家子网络,可大幅扩充模型总参数量、强化能力,同时有效控制单次推理的算力开销。它具备稀疏激活、智能路由、专家分工、负载均衡四大核心特性,主流落地模型包含 Mistral Mixtral 8x7B、Qwen-MoE、Google Switch Transformer 等,广泛应用于开源大模型与企业级 AI 服务部署。
通俗理解:就像医院分诊接诊,不再依靠一位全科医生处理所有问题,而是由分诊系统匹配对应专科医生,按需调用专业能力,实现整体能力升级的同时,大幅降低运配的搜索方式,
59 语义搜索|向量时代的智能检索范式
核心流程为用户 Query 向量化→向量数据库相似度检索→结果重排序→返回 Top-K 文档,能理解同义词、口语化表达与语义关联,解决传统关键词检索 “字面匹配但语义不符” 的问题,是 RAG、企业知识库、推荐系统的核心能力。
通俗理解:搜索引擎的 “语义大脑”,不再局限于文字完全一致,能读懂 “AI 手机” 和 “iPhone 15 Pro Max” 的语义关联,让搜索从 “找字” 升级为 “找意思”,是大模型时代信息检索的核心范式。

60 Ollama|本地 LLM 运行的入门级工具
Ollama 是让用户通过一条命令就能在本地运行开源大模型的工具,支持自动下载模型、INT4/INT8 量化优化、OpenAI 兼容 API,同时提供命令行交互与性能优化能力,让用户无需复杂配置即可在本地部署 Llama 3、Qwen、Mistral 等主流模型,是学习、实验与本地私有部署 LLM 的首选工具。
通俗理解:本地跑大模型的 “一键启动器”,不用折腾环境配置,一条命令就能下载、运行、对话开源模型,还能通过 API 接入应用,是体验和学习大模型的 “入门神器”。

61 RAG|解决大模型幻觉的核心架构
RAG(Retrieval Augmented Generation)是结合向量检索与大模型生成的技术架构,核心流程为用户 Query 向量化→向量数据库检索 Top-K 相关文档→文档与 Query 拼接成 Prompt→大模型生成答案,通过引入外部知识库信息解决大模型知识过时、幻觉、信息不准确的问题,是当前 LLM 企业落地的主流应用架构。
通俗理解:大模型的 “外挂知识库 + 事实核查官”,让 AI 回答前先去你的专属知识库找依据,再结合模型能力生成答案,既解决了模型知识有限的问题,又大幅降低了回答错误的概率,是企业落地 AI 应用的 “标配方案”。

62 Rerank|提升 RAG 检索精度的二次精排步骤
Rerank(重排序)是在向量检索初筛结果上进行二次精排的关键步骤,核心通过 Cross-Encoder 模型对 Query 与候选文档进行精细相关性打分,再按分数重新排序,能解决向量检索 “召回多但精度不足” 的问题,是提升 RAG 答案质量、降低幻觉的重要环节,主流实现包括 BGE-Reranker、Cohere Rerank 等模型。
通俗理解:RAG 检索的 “专业评委打分环节”,向量检索先选出 100 个候选文档,再由重排序模型逐一审定相关性,筛选出最贴合 Query 的 Top-10 送入大模型,让最终答案更精准、更贴合用户真实需求。


