 夜雨聆风
夜雨聆风打开Apollo源码仓库,50万行C++代码,从哪读?我选了一个最笨但最有效的办法——跟踪数据流,看一帧激光雷达数据怎么最终变成方向盘的转动。

Cyber RT:Apollo的神经系统
Apollo不用ROS,自研了Cyber RT。我读源码时发现,Cyber RT解决了ROS的三个痛点:通信延迟高、调度不透明、缺少自动驾驶专用组件。
Component是Cyber RT的模块封装单位,分两种类型:
消息触发Component通过模板参数指定输入消息类型,收到数据才执行。比如modules/prediction/prediction_component.h定义的PredictionComponent继承自Component<PerceptionObstacles>,每当感知数据到达就触发Proc()。
TimerComponent继承自cyber::TimerComponent,内部创建cyber::Timer实例,周期性调用Proc()。源码位于cyber/component/timer_component.h,调度基于TimingWheel实现O(1)复杂度。
Channel是数据通道,通过node->CreateReader<T>和node->CreateWriter<T>建立发布订阅关系。Channel名就是消息的路由地址。
模块拓扑关系通过DAG文件定义,后缀是.dag,放在modules/目录/conf/下。Cyber启动时解析DAG,构建调度图。
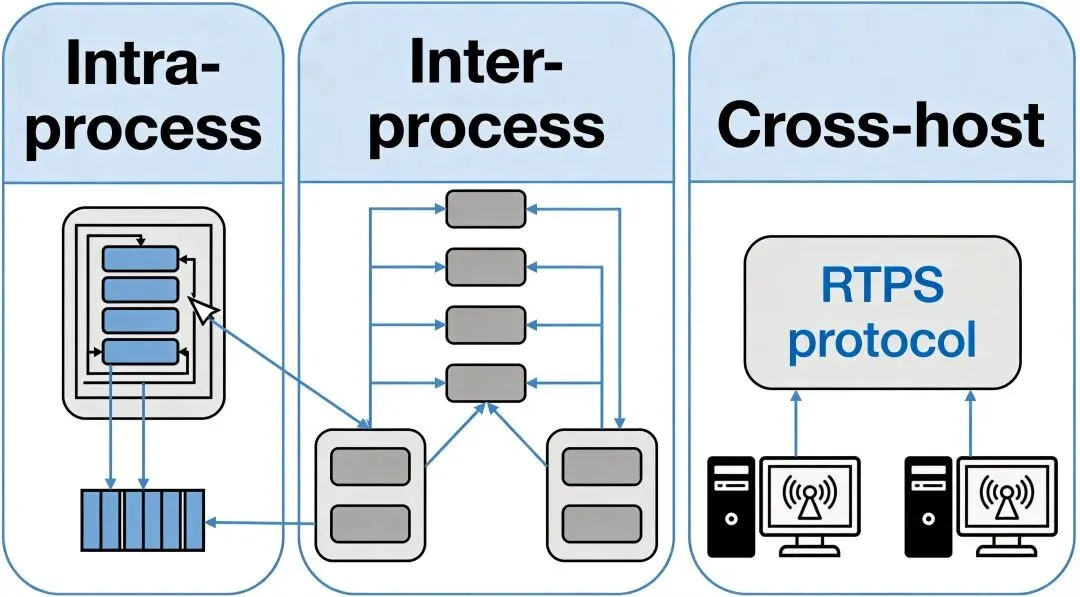
共享内存零拷贝是Cyber RT的核心设计,也是和ROS拉开差距的关键:
进程内通信直接传指针,数据零拷贝。源码在cyber/transport/下,IntraTransmitter直接传递shared_ptr,不需要任何序列化反序列化。两个Component在同一个进程里,传一条PerceptionObstacles(含几十个障碍物的位置、速度、多边形轮廓)就是传一个指针,微秒级。
进程间通过共享内存块传递。Segment类管理一块共享内存,ShmTransmitter写入,ShmReceiver读取。Channel和共享内存块一一对应。这里仍然是零拷贝——写端把protobuf序列化后的字节流放进共享内存,读端拿到的就是同一块内存的引用,不需要内核态拷贝。相比ROS的TCP socket需要两次内核态拷贝(用户态→内核态→用户态),延迟降了一个量级。
跨主机通信用RTPS(基于eProsima Fast RTPS)。RtpsTransmitter序列化消息发布,RtpsReceiver接收后反序列化。这种场景下无法避免序列化,但Apollo的跨主机通信主要用于多车编队和云端接入,单车计算平台上绝大多数通信走的是进程内或进程间。
我对比了一下:ROS发布一条激光雷达点云(约100KB),TCP通道端到端延迟在1-3ms;Cyber RT进程内通信同一数据,延迟在0.1ms以内。100Hz的雷达数据,这个差距会被放大100倍。
调度器支持两种策略,配置文件在cyber/conf/scheduler_conf.pb.txt:
classic调度器基于优先级队列,每个任务有优先级和协程组。高优先级任务先调度,同优先级按FIFO。适合模块间优先级关系清晰的场景——控制>规划>感知。
choreography调度器支持更精细的任务依赖编排,可以指定某个任务在特定CPU核上运行(CPU亲和性),还可以配置任务间的依赖关系。自动驾驶场景下,控制任务绑在独立的核上、不被其他任务抢占,这是硬实时要求的保障。
实际部署中,Apollo默认用choreography,把Planning和Control绑到独立核,保证10Hz的稳定输出。
为什么不用ROS?ROS的TCP/UDP通信有序列化开销,调度器是单一线程池,不支持组件级别的资源亲和性配置。自动驾驶场景下,感知10Hz、控制10Hz、雷达100Hz,延迟要求百毫秒级,ROS的通用设计不够用。
数据流全链路追踪
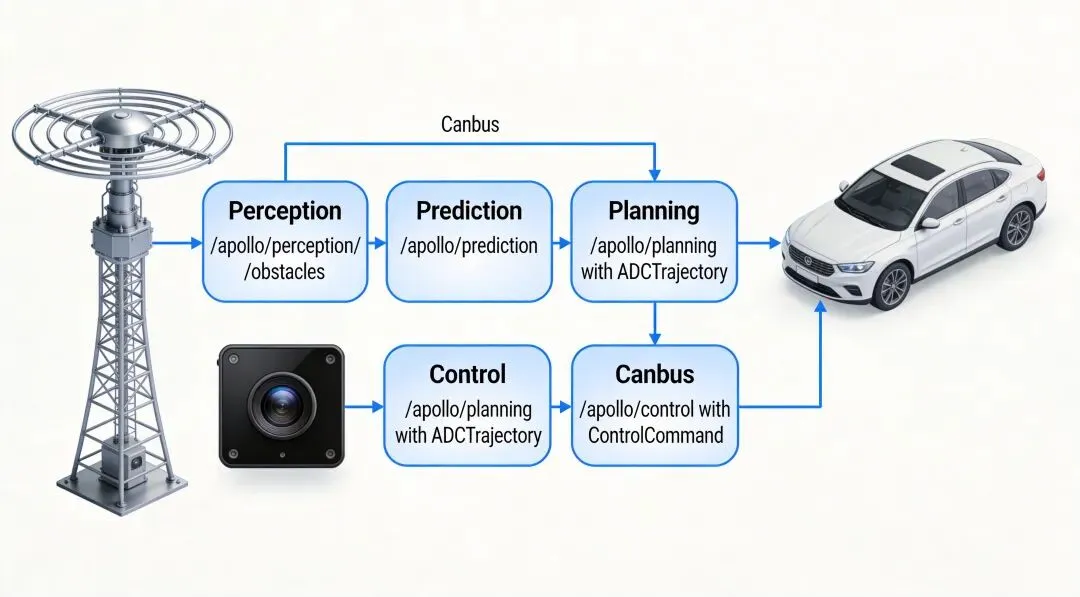
传感器驱动 → 感知模块
入口在modules/perception/onboard/component/detection_component.cc(LidarDetectionComponent)和对应的Camera、Radar组件。
输入channel包括/apollo/sensor/velodyne64(点云)、/apollo/sensor/camera/front_6mm(图像)、/apollo/sensor/radar/front(前向雷达)。传感器频率不同:Lidar 10Hz、Camera 30Hz、Radar 100Hz。
感知模块做异步融合,时间对齐各传感器数据后输出PerceptionObstacles(含位置、速度、分类)和TrafficLightDetection(红绿灯状态)。
融合策略值得一提:Lidar和Radar的频率差异很大(10Hz vs 100Hz),感知模块不是等所有传感器数据到齐才处理,而是用最新的传感器数据做"快照融合"。源码里有个SensorFrame类,负责把时间戳最近的一帧多传感器数据打包,交给后端的ObstacleDetector和Tracker。这意味着一帧感知输出可能混入了50ms前的雷达数据和10ms前的相机数据,对下游的预测模块来说,这个时间差需要补偿。
输出channel是/apollo/perception/obstacles和/apollo/perception/traffic_light。
感知 → 预测模块
入口在modules/prediction/prediction_component.cc,这个组件是消息触发的:
class PredictionComponent : public Component<PerceptionObstacles>
输入PerceptionObstacles加LocalizationEstimate,输出PredictionObstacles——每个障碍物的多条未来轨迹,每条轨迹带概率。
预测模块内部有四个子组件:Container存储输入、Scenario分析场景类型、Evaluator评估轨迹概率、Predictor生成具体轨迹。源码在modules/prediction/下各子目录。
其中Evaluator是最有意思的部分。Apollo实现了多种评估器:CostEvaluator基于规则打分(跟车距离、车道偏移),MLPEvaluator用三层全连接网络预测轨迹概率,CruiseMLPEvaluator专门处理巡航场景。Evaluator的选择通过配置文件prediction_conf.pb.txt指定,可以按障碍物类型(行人、车辆、自行车)分配不同评估器。
Predictor这边也有多种策略:LaneSequencePredictor沿车道线预测、FreeMovePredictor对离线障碍物做匀速直线预测、JunctionPredictor专门处理路口场景。每个障碍物最终输出多条候选轨迹,每条带概率值,概率最高的那条作为下游规划的参考。
输出channel是/apollo/prediction。
定位模块
入口在modules/localization/下的定位组件。RTK模式用TimerComponent定时触发(100ms周期),MSF(多传感器融合)模式是事件触发。
融合算法糅合GPS、IMU、LiDAR点云匹配,输出LocalizationEstimate——车辆位姿(xyz+航向角),精度厘米级。
输出channel是/apollo/localization/pose,被Prediction、Planning、Control、Perception四个模块订阅。
路由 → 规划模块
入口在modules/planning/planning_component/planning_component.cc。这是最复杂的模块之一。
输入channel包括:
/apollo/prediction(PredictionObstacles)/apollo/localization/pose(LocalizationEstimate)/apollo/canbus/chassis(Chassis,车辆状态)/apollo/routing_response(RoutingResponse,全局路径)/apollo/perception/traffic_light(TrafficLightDetection)
规划组件本身是TimerComponent,10Hz定时触发。PlanningComponent::Proc()每次被调用时,综合所有输入数据,调用PlanningBase::RunOnce()。
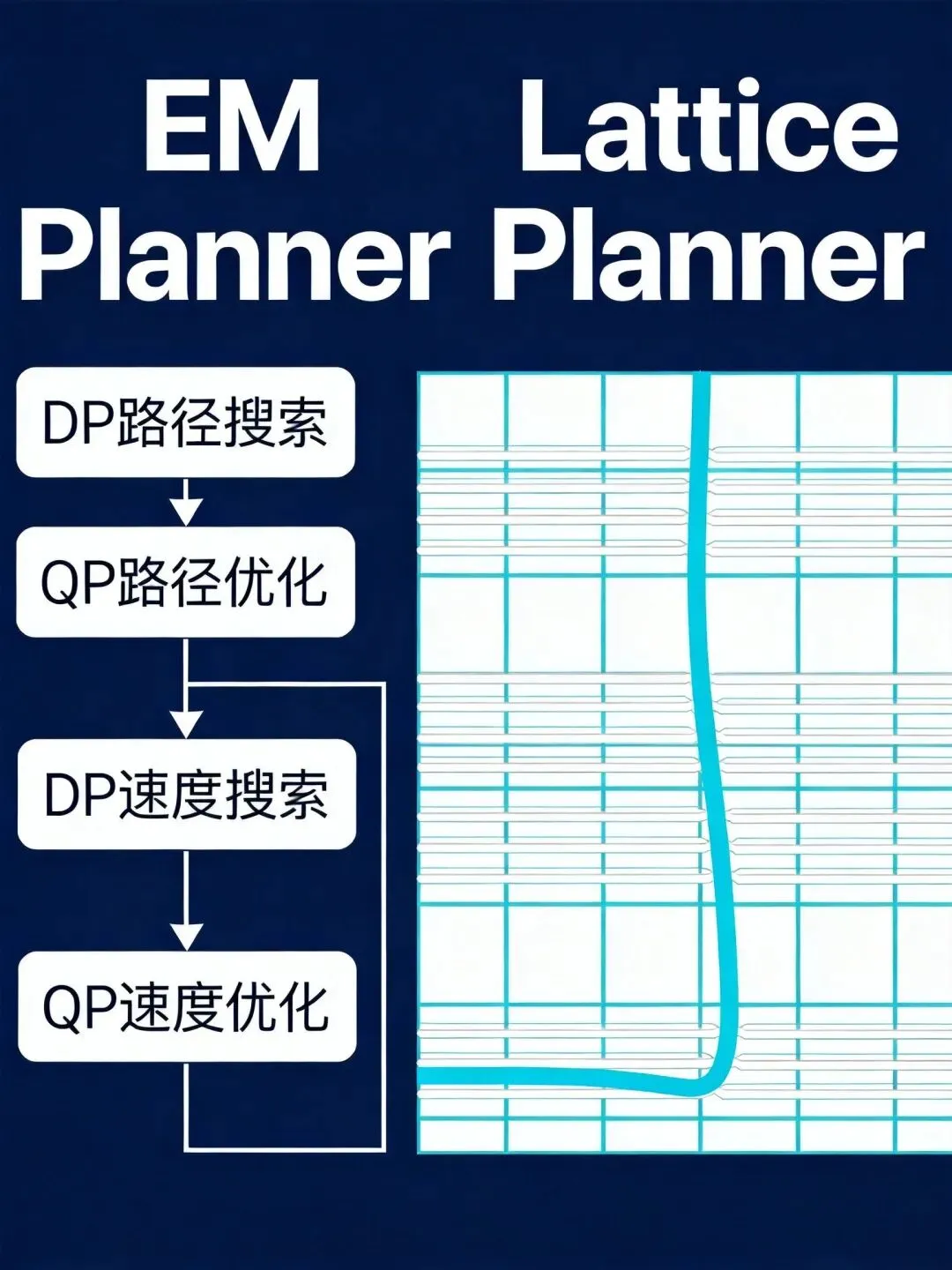
Apollo支持多种Planner:EM Planner(基于DP+QP的路径速度分离优化)、Lattice Planner(横纵向一体化采样)、NaviPlanning(开放道路)。选择逻辑在modules/planning/planning_base.h中。
EM Planner的思路是先搜路径再优化速度。DP阶段在Frenet坐标系下采样出一条粗路径,QP阶段在粗路径周围建二次规划问题做精细优化。路径确定后再用同样的DP+QP流程优化速度剖面。路径和速度是解耦的,好处是降维,坏处是路径和速度的耦合约束(比如急弯必须减速)只能靠启发式规则补。
Lattice Planner不分路径和速度,直接在横纵向同时采样,生成一组候选轨迹,然后用代价函数(横向偏移、纵向加速度、Jerk等)选最优。每条轨迹是完整的时空曲线,天然满足耦合约束,但采样空间大,计算量也大。
实际部署中,EM Planner是默认选项,Lattice Planner作为备选。原因很简单:EM Planner的DP+QP框架成熟稳定,Lattice Planner在密集交通场景下采样效率不够。
输出ADCTrajectory(planning.proto定义),包含repeated TrajectoryPoint trajectory_point,代表未来5-8秒的规划轨迹。每条TrajectoryPoint含位置、速度、加速度、时间戳。
输出channel是/apollo/planning。
规划 → 控制模块
入口在modules/control/control_component.cc,同样是TimerComponent 10Hz。
控制组件订阅三个channel:/apollo/planning(ADCTrajectory)、/apollo/localization/pose(LocalizationEstimate)、/apollo/canbus/chassis(Chassis)。
横向控制用LQR,基于车辆运动学模型,状态量是横向位置误差和航向角误差,控制量是前轮转角。Apollo早期版本用这个。LQR的好处是计算快(矩阵运算),坏处是运动学模型在高速大曲率下不够准。
纵向控制用PID双环:外环位置环(规划位置-实际位置→速度补偿),内环速度环(规划速度+速度补偿→加速度→油门/刹车)。双环PID参数整定是个体力活,Apollo在control_conf.pb.txt里针对不同速度区间配了不同的PID增益。
新版本引入MPC(模型预测控制),横纵向一体化,用MpcOsqp求解器(基于OSQP)求解二次规划问题。MPC的核心优势:它显式考虑了车辆动力学约束(最大方向盘转角、最大加速度),在每个控制周期内做有限时域优化,自然处理约束饱和。代价是计算量大,MPC单次求解在1-5ms,而PID+LQR的组合在0.1ms以内。好在10Hz的控制频率留了100ms的预算,5ms的MPC完全吃得下。
源码里三种控制器可以配置切换:lon_controller_type和lat_controller_type独立配置。实际部署中,低速场景用PID+LQR(简单可靠),高速场景用MPC(约束处理更好)。
输出ControlCommand(control_command.proto定义),含steering_angle(方向盘转角)、throttle(油门)、brake(刹车)、gear_location(档位)。
输出channel是/apollo/control。
控制 → Canbus → 车辆底盘
入口在modules/canbus/canbus_component.cc:
class CanbusComponent final : public apollo::cyber::TimerComponent
订阅/apollo/control接收ControlCommand,解析成CAN报文发到车辆线控底盘。同时定时发布Chassis消息反馈车辆状态。
输出channel是/apollo/canbus/chassis。
关键Channel和消息一览表
触发机制对比
TimerComponent用于周期性执行的模块:Planning(10Hz)、Control(10Hz)、Canbus(100Hz)、RTK定位(10Hz)。定时触发的好处是不依赖上游数据,任何一个模块延迟都不会卡住下游。
消息触发Component用于事件驱动的模块:Perception(传感器数据到达才处理)、Prediction(感知结果到达才处理)、MSF定位(多传感器事件触发)。好处是节省CPU,空闲时不用跑算法。
为什么Planning用Timer不用消息触发?因为Planning需要同时拿到定位、预测、底盘、路由、红绿灯五个来源的数据。如果用消息触发,任何一个来源延迟都会导致规划跳帧。Timer触发保证10Hz稳定输出,丢一帧数据也比卡住强。
Apollo vs ROS2:为什么自动驾驶需要自己的中间件
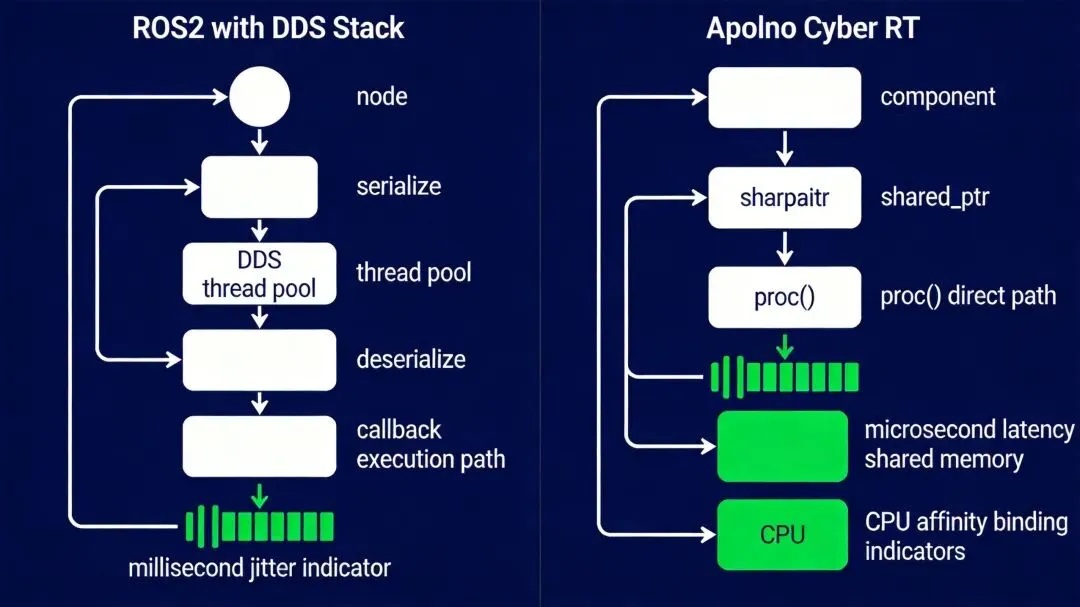
自动驾驶圈子里经常有人问:Apollo为什么不直接用ROS2?ROS2已经解决了ROS1的大部分问题——支持DDS通信、有了共享内存选项、QoS可配置。但读完Cyber RT源码,我发现差距还是不小。
通信延迟:ROS2默认走DDS(Data Distribution Service),即使同一进程内的两个节点,消息也要经过序列化→DDS栈→反序列化的完整路径。Cyber RT进程内直接传shared_ptr,跳过所有序列化开销。对于100Hz的点云数据,前者延迟在亚毫秒级,后者在微秒级,差一个数量级。
调度可控性:ROS2的执行模型是Executor,用户提供回调函数,Executor负责调用。但Executor本身不感知任务优先级,也不支持CPU亲和性绑定。Cyber RT的choreography调度器可以把Planning和Control绑到独立CPU核上,保证它们不被其他任务抢占。自动驾驶场景下,控制模块的10Hz输出不能因为感知模块突然算了一帧重的就抖动。
确定性延迟:ROS2的DDS层引入了额外的调度不确定性——消息从发布到回调执行,中间经过DDS线程池、Executor队列,延迟抖动在毫秒级。Cyber RT的协程调度路径短:数据到达→唤醒协程→执行Proc(),中间没有线程池队列。对于100ms控制周期的自动驾驶系统,每1ms的抖动都是安全隐患。
消息兼容性:ROS2用.msg/.srv定义消息,Apollo用protobuf。protobuf的优势是前后向兼容——加字段不破坏旧消息解析,这对车载系统的OTA升级至关重要。ROS2的.msg虽然也支持可选字段,但生态里很少有工具做兼容性校验。
多进程部署:ROS2的节点天然是独立进程,通过DDS通信。Cyber RT支持在同一个进程里加载多个Component(通过DAG文件配置),进程内零拷贝;也支持跨进程共享内存通信。自动驾驶的计算平台通常是一块工控机或域控制器,进程内通信是主流场景,Cyber RT的设计更贴合。
不是ROS2不好,而是它的通用性设计在自动驾驶场景下不够极致。ROS2追求的是通用机器人中间件,从工业机械臂到服务机器人都要覆盖;Cyber RT只服务自动驾驶一个场景,可以做更激进的优化。
结尾
读完了这条数据流,对Apollo的骨架就有了基本认知。每个模块是独立的进程/线程,通过Channel交换protobuf消息,Cyber RT负责调度和通信。
接下来每深入一个模块,都是在骨架上长肉。比如Planning内部怎么选场景、怎么生成参考线、怎么在Frenet坐标系下优化轨迹——这些是下一篇的事。
