 夜雨聆风
夜雨聆风
点击“蓝字” 关注我们
1、LLM(大语言模型)
全称 Large Language Model,直译就是“大语言模型”,是所有大模型相关应用的开发基础,对应开发工作里的“核心服务”,我们所有的功能开发都是围绕它展开的。
通俗来讲,LLM 就像一个知识储备丰富但做事比较随性的大脑,经过海量的文本数据训练,它能够听懂自然语言、自主生成内容、完成基础逻辑推理。但它不会主动开展工作,需要我们人为引导、设定约束规则才能正常使用。
实战层面来看,我们日常开发用到的 GPT、文心一言、通义千问、DeepSeek-V2 等模型,都属于 LLM 的范畴。我们开发的对话机器人、文档分析、代码生成等各类AI应用,本质上都是借助 LLM 的原生能力,去解决不同场景的具体业务问题。
LLM 属于概率性组件,想要保证应用稳定运行,需要搭配容错、回退机制,它也是AI实现智能涌现的核心引擎。
2、Prompt(提示词)
Prompt 也就是提示词,对应的提示工程,是我们向 LLM 传递需求、引导模型输出预期结果的指令。放在传统开发里,它的作用类似“接口参数”,但灵活性更高,主要依靠自然语言的形式来表达需求。
简单来说,不管是让 LLM 写代码、总结文章,还是分析各类问题,你对模型说出的需求话语,就是 Prompt。优质的 Prompt 可以让 LLM 精准理解需求、少出偏差,输出内容更贴合预期;如果 Prompt 表述模糊,就很容易出现答非所问的情况。
在实际开发中,Prompt 并不是随意一句话就能胜任,它有着明确的设计标准,核心是表述清晰、结构完整、约束明确。比如“作为一名 Java 后端开发者,用 FastAPI 写一个简单的接口,要求返回 JSON 格式,包含状态码和数据字段”,就是一条合格的 Prompt。
Prompt 贯穿大模型应用开发的全过程,直接影响 RAG、Agent 等技术的落地效果,是开发者和 LLM 交互的核心桥梁。
3、Token(词元)
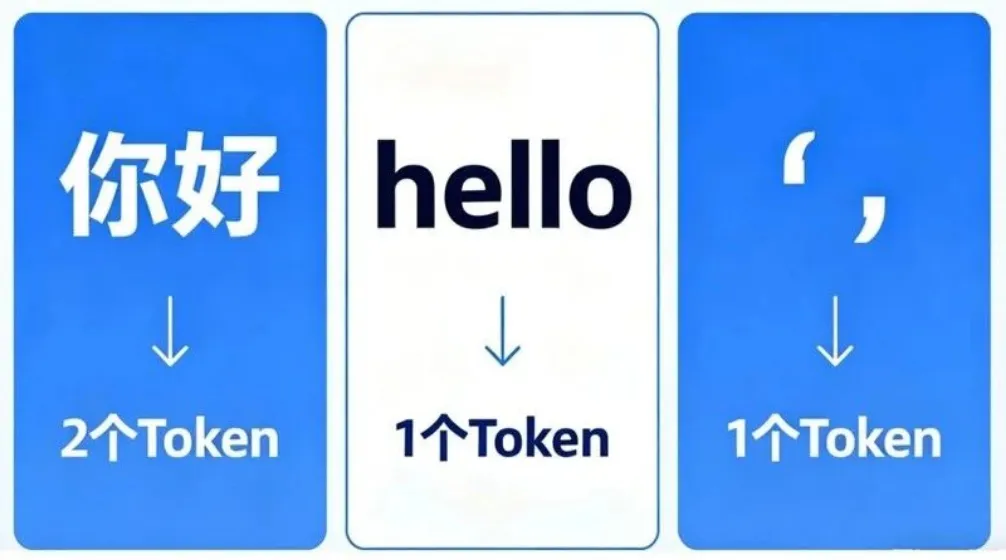
Token 是 LLM 处理文本的最小单位,对标传统开发中的“字节”,主要用来统计输入、输出的文本总量,同时也是大模型 API 计费的核心依据。通俗来说,一个 Token 可以是单个汉字、一个英文单词,也可以是一个标点符号。
举个例子,“你好”对应 2 个 Token,“hello”对应 1 个 Token,中文逗号“,”也对应 1 个 Token。实际开发中,必须重点关注 Token 限制,每一款 LLM 都有固定的上下文长度,也就是最大支持 Token 数量。
比如普通版 GPT-4 的上下文长度为 8k Token,一旦超出这个范围,模型就会丢失前文信息,出现内容断层的问题。
除此之外,Token 消耗数量越高,API 调用的成本就越高,因此在日志分析工作中,我们需要重点追踪 Token 消耗情况,以此优化应用的运行成本和运行性能。
4、RAG(检索增强生成)
全称 Retrieval-Augmented Generation,直译是“检索增强生成”,是目前大模型应用开发中最常用的核心技术之一,核心作用是为 LLM 补充参考资料,从根源上避免模型捏造虚假信息。
大家可以简单理解,LLM 的训练数据有固定截止时间,自带的知识存在时效性局限,而且很容易凭空编造不存在的信息,也就是行业常说的模型幻觉。
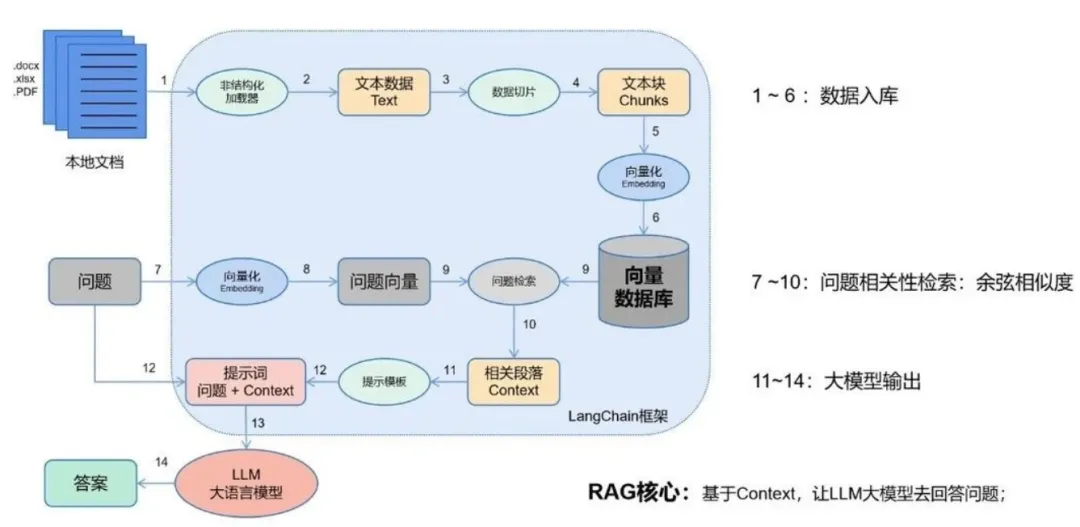
而 RAG 就相当于给 LLM 搭建了一个专属知识库,用户提出问题后,系统会先从专属知识库中检索匹配的相关资料,再让 LLM 依托真实资料生成回答,相当于让模型开卷答题。
在实际开发中,企业知识库搭建、产品咨询、文档分析等场景的AI应用,基本都离不开 RAG 技术。
它既能解决 LLM 知识滞后、回答不准确的问题,还不用投入高额成本对模型做微调,只需更新知识库内容,就能让模型快速掌握全新知识,是企业级大模型应用的标配技术,这项技术的落地效果,主要依靠向量数据库实现高效检索。
5、Embedding(嵌入)
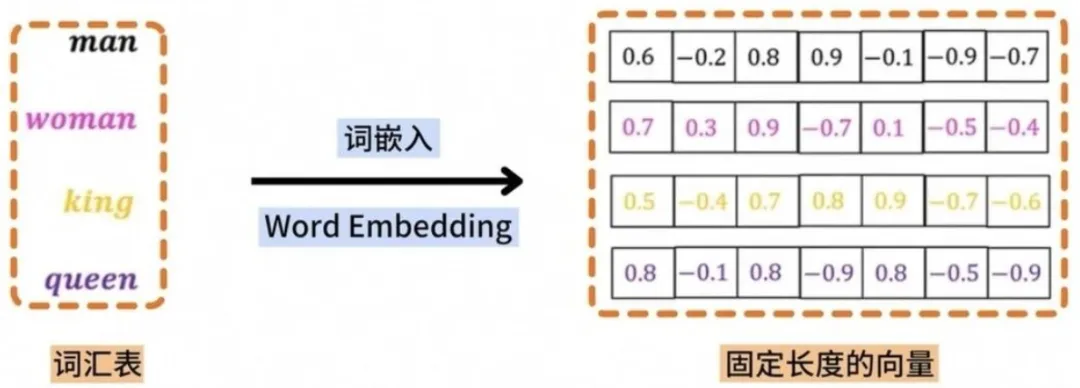
实现“语义检索”Embedding 即“嵌入”,简单来说,就是把文本、图片等无法直接被计算机识别的非结构化数据,转换成计算机可以读取识别的数值向量,也就是一串专属数字,这也是 RAG 技术能够实现语义检索的核心前提。
通俗举例,我们平时搜索“苹果手机”,传统搜索方式只会机械匹配关键词,而经过 Embedding 处理后,模型能够识别出“苹果手机”和“iPhone”指代的是同一种事物,因为两者转化后的数值向量相似度极高、距离极近。
它可以精准捕捉内容的深层语义特征,让检索不再局限于关键词匹配,大幅提升检索精准度。落地开发中,搭建 RAG 应用时,需要提前把知识库中的所有文档、用户的各类提问,统一转化为 Embedding 向量,再通过向量数据库完成存储和检索工作。
目前常用的 Embedding 模型主要有 OpenAI 的 text-embedding-ada-002、国产的通义千问 Embedding 等,它是打通非结构化数据和大模型交互的关键纽带。
6、向量数据库
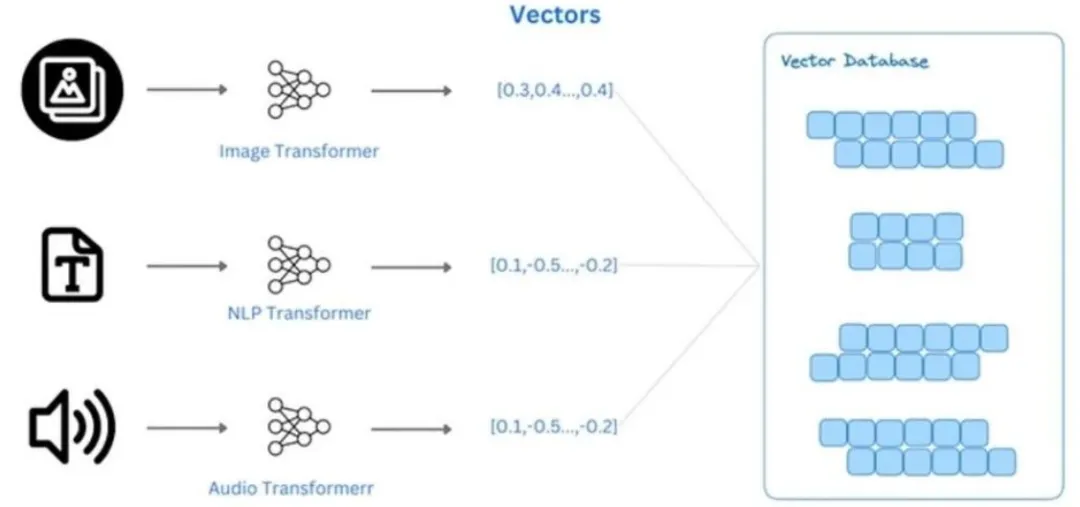
向量数据库是专门用来存储和管理 Embedding 向量的数据库,和传统开发使用的 MySQL、Redis 数据库不一样,它的核心优势是高效计算向量相似度,核心作用是快速匹配并调取和用户提问最相关的知识库资料。
可以通俗理解,如果把每一个 Embedding 向量都看作一个专属坐标,那向量数据库就相当于一张完整地图,能够快速定位出和当前坐标相似度最高的其他坐标,也就是匹配出和用户问题最贴合的知识库内容,完美解决了传统数据库无法高效完成语义相似性检索的行业痛点。
在实际开发中,只要做 RAG 应用开发,就必须搭配向量数据库,业内常用的类型包括 Pinecone、Milvus、Chroma、FAISS 等。
向量数据库的性能好坏,直接决定了 RAG 检索的速度和准确率,既是大模型应用中知识存储与检索的核心载体,也是 Agent 记忆模块实现的重要支撑。
7、Function Calling(函数调用)
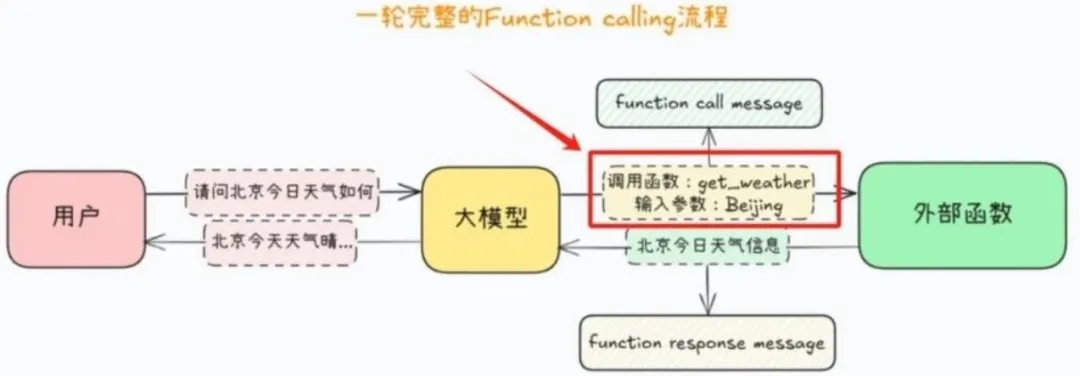
Function Calling 也就是函数调用,是 LLM 的核心原生能力之一。简单来说,就是 LLM 解析完用户需求后,能够自动调用提前设置好的外部函数、接口或工具,完成具体操作,再根据外部工具的执行结果,生成最终的回答内容。
通俗来讲,LLM 擅长思考分析、生成内容,但没办法直接落地实操。比如查询实时天气、调取数据库数据、发送邮件这类实操操作,都需要依靠 Function Calling,让 LLM 像开发调用接口一样,触发外部工具完成对应操作,再将执行结果反馈给 LLM,形成完整的任务闭环。
在实战开发中,自动查订单、批量生成报表等智能助手类应用,核心都依赖 Function Calling 能力。它打破了 LLM 只能独立思考、无法联动实操的局限,让大模型能够对接各类业务系统和第三方工具,是实现AI自主完成各类工作的基础。
目前市面上的主流大模型都原生支持这项能力,也可以通过 MCP 协议实现跨模型的通用函数调用。
8、Agent(智能体)
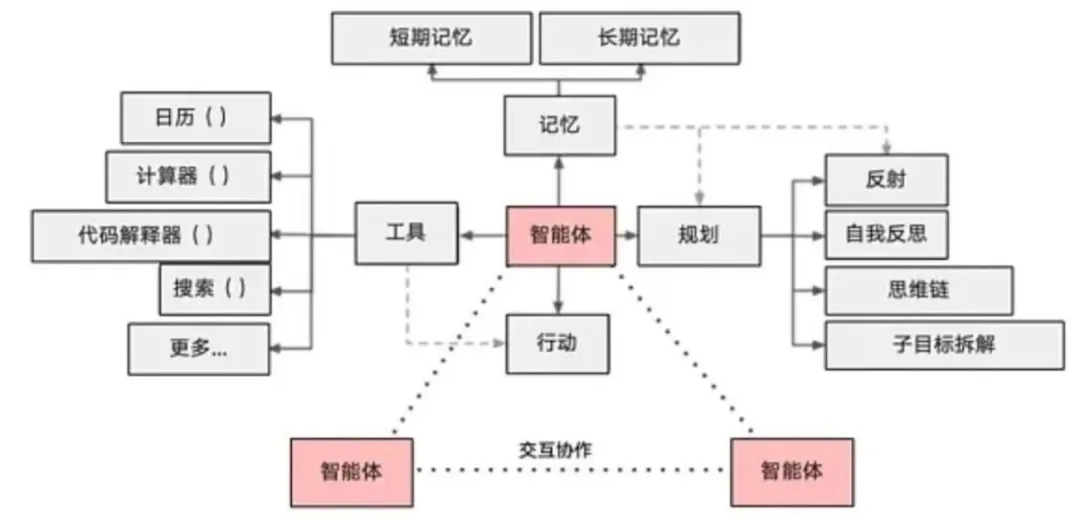
Agent 即智能体,是大模型应用的高阶落地形态。它的核心逻辑是依托 LLM,融合记忆、自主规划、工具调用等多项能力,独立完成各类复杂任务,相当于一个能够自主思考、主动执行工作的AI打工人。
举个通俗的例子,你让 Agent 完成“撰写大模型应用开发文章、匹配配图、排版优化、发布至公众号”的全套任务,它会自主拆解出分步流程:先写文案、再匹配配图、接着完成排版、最后执行发布,同时自动调用对应的文案生成、图片处理、公众号对接工具,全程无需人工干预。
Agent 整合了 LLM、RAG、Function Calling 等多种核心技术,让大模型从简单的问答交互,升级为可以自主执行复杂任务的高阶形态。从行业实战来看,Agent 是2026年大模型应用开发的热门赛道,常用开发框架包含 LangChain、LangGraph、MetaGPT、CrewAI 等。
自动工单处理、智能数据分析、批量代码生成等复杂场景的开发,借助 Agent 能够大幅提升工作效率。其核心架构主要包含规划、记忆、工具调用、自我反思四大模块,是多项AI技术融合的高阶应用形态。
9、微调(Fine-tuning)
微调,就是针对已经训练完成的通用预训练 LLM,使用特定领域的专属数据集做二次训练,让模型更加适配细分业务场景,相当于给通用型的AI大脑做专项技能培训。
通俗解释,通用 LLM 覆盖的知识领域广、适配场景多,但针对金融、医疗、法律等专业细分领域,回答的精准度、专业性会有所欠缺。而微调就是利用行业专属数据,比如金融合同、医疗病历、法律文书等,让模型专项学习对应领域的专业知识和表述风格,输出内容会更贴合具体业务需求。
在实际开发中,如果 RAG 技术已经无法满足业务的高精度需求,比如专业领域深度问答、固定风格内容生成等场景,就需要用到微调。
但微调的成本和技术门槛都比较高,行业通用做法是优先通过 RAG 优化效果,只有 RAG 无法达标时,再启动微调。微调是大模型定制化落地的核心方式之一,和模型蒸馏共同组成了大模型优化的核心路径。
10、模型蒸馏(Model Distillation)
模型蒸馏,简单来说,就是把体积大、结构复杂的大模型(教师模型)所具备的核心知识,迁移到体积小、运行高效的小型模型(学生模型)中。
核心目的是保留模型核心能力的同时,缩小模型体积、降低推理运行成本,相当于给笨重的大型AI大脑做精简瘦身,让它能够适配更多设备的运行环境。
通俗来讲,我们常用的 GPT-4、文心一言等主流大模型,整体体积大、推理速度慢、调用成本高,没办法部署在手机、边缘设备等资源有限的终端上。
而模型蒸馏就像提炼精华,完整保留大模型的理解、生成等核心能力,同时对模型进行压缩精简,让小型模型既能保证输出效果,又能实现快速推理、降低使用成本。
实战开发中,手机APP内置AI助手、边缘设备本地化AI应用等场景,都必须用到模型蒸馏技术。
它有效解决了大模型部署难、成本高、推理慢的痛点,和微调技术形成互补,微调主打模型定制化适配,蒸馏主打模型轻量化落地,是大模型适配各类终端场景、实现规模化落地的关键技术。目前常用的蒸馏方式主要包含知识蒸馏、量化蒸馏等。
来源:互联网摘抄
版权归原作者所有,如有侵权,请联系删除。

扫|码|关|注
