 夜雨聆风
夜雨聆风点击蓝字
关注要点AI Subscribe for More


本篇报告将连载发布,针对数据中心直接液冷系统的核心挑战,进行研究与分析。
欢迎加入数据中心产业交流群,可扫码咨询要点AI工作人员!


随着人工智能(AI)和高性能计算(HPC)对芯片算力需求的爆发式增长,直接液体冷却(DLC,Direct Liquid Cooling)已成为解决高密度GPU散热问题的主流技术。然而,DLC系统在数据中心的规模化应用仍处于早期阶段,行业标准尚未完善,在安装和运营环节面临着诸多独特挑战。其中,技术冷却系统(TCS,Technology Cooling System)的污染防控、跨厂商保修责任界定以及GPU功率瞬变的热响应问题,是当前数据中心运维人员最常遇到且影响最为严重的三类问题。
01
安装阶段:防止TCS污染的
复杂性与应对指南
TCS作为直接连接服务器冷板与冷却液分配单元(CDU,Coolant Distribution Unit)的封闭循环系统,承担着将GPU产生的热量高效传递至设施水系统(FWS,Facility Water System)的核心功能。与FWS不同,TCS回路中的冷却液直接流经服务器内部微米级的冷板通道,任何微小的污染物都可能引发灾难性后果,因此防止TCS污染是安装阶段最关键的质量控制环节。
1.1
TCS污染的严重危害
与污染物类型
TCS污染物主要分为有机污染物和无机污染物两大类,二者通过不同机制对系统造成不可逆损害。有机污染物主要指细菌、真菌、藻类等微生物及其代谢产物,无机污染物则包括金属离子、金属碎屑、塑料颗粒、灰尘、盐类结晶等。
无机污染物的危害最为直接且剧烈。金属碎屑和塑料颗粒会物理堵塞冷板的微通道,导致冷却液流量急剧下降,换热效率大幅降低,进而引发GPU局部过热甚至永久性烧毁。同时,悬浮在冷却液中的硬质颗粒会以高速冲刷TCS回路的所有内表面,造成冷板、CDU热交换器和管道的磨蚀损伤,大幅增加系统泄漏风险。金属离子则会引发电化学腐蚀,当不同电化学电位的金属在冷却液中形成原电池时,会加速阳极金属的溶解,不仅破坏管道和组件的结构完整性,溶解的金属离子还会在系统其他部位重新沉积,形成二次堵塞和局部腐蚀。
有机污染物的危害具有隐蔽性和累积性。微生物会在 TCS回路的停滞区域(如未使用的分支管线、管道死角、阀门腔体)大量繁殖,其代谢产物会改变冷却液的pH值,使原本呈弱碱性(pH8-9.5)的冷却液变为酸性或强碱性,大幅加速金属材料的腐蚀速率。同时,微生物形成的生物膜会附着在热交换表面,形成额外的热阻,降低CDU和冷板的换热效率。此外,死亡的微生物菌体也会成为有机碎屑,进一步加剧冷板的堵塞风险,形成“污染-腐蚀-更严重污染”的恶性循环。
1.2
TCS污染的主要产生机制
与安装阶段来源
TCS污染的产生源于四种核心机制:结垢、腐蚀、微生物形成和盐类结晶。结垢是指悬浮颗粒在系统特定部位的累积;腐蚀是金属表面与冷却液发生化学反应产生金属离子;微生物形成是微生物在适宜环境下的繁殖;盐类结晶则是冷却液中溶解的盐类因温度或浓度变化析出晶体。这四种机制相互作用,共同加剧了TCS系统的污染程度。
在安装阶段,TCS污染的具体来源主要包括以下六个方面:第一,材料不兼容,使用了电化学电位差异过大的金属组件,引发电偶腐蚀并持续产生金属离子;第二,使用了与冷却液不兼容的螺纹密封剂,密封剂与冷却液发生化学反应释放颗粒或改变冷却液的化学性质;第三,TCS组件在制造过程中残留的金属切削屑、塑料颗粒、焊剂和灰尘;第四,安装过程意外中断导致冷却液长时间停滞,为微生物繁殖提供了理想条件;第五,操作人员不规范的操作,如未戴手套接触组件、使用非无尘擦拭布、在多尘环境中进行精密组装;第六,在连接新服务器时,未冲洗长期停滞的分支管线,将管线内积累的污染物带入主回路,直接污染服务器冷板。
1.3
防止TCS污染的
核心实施指南
针对TCS污染的复杂性和高危害性,本文提出了一系列严格的安装阶段防控指南,核心原则是从源头减少污染产生,并通过系统化的流程控制消除已产生的污染物。
首先,采用模块化安装策略,限制单个TCS回路的规模。将大型DLC系统划分为多个独立的小型TCS回路,每个回路服务不超过10-20%的液冷服务器。这样即使某个回路发生污染,也只会影响少量服务器,大幅降低故障损失。同时,小型回路更容易进行彻底的冲洗和净化,也能减少因分支管线过长导致的冷却液停滞问题,从根本上降低微生物滋生的风险。
其次,严格执行全面的冲洗和净化程序。在连接CDU和服务器之前,必须对整个TCS主回路和分支管线进行高压、大流量冲洗,去除制造和安装过程中残留的所有碎屑。冲洗完成后,需对系统进行干燥空气吹扫,彻底排除回路中的所有空气,因为空气不仅会影响冷却液流动,还会为好氧微生物提供生长条件。在服务器安装前,还需对每个分支管线进行单独冲洗,确保停滞管线内的污染物被完全清除,避免其进入服务器冷板。
第三,在系统首次注液前添加适量的专用杀菌剂。杀菌剂能有效抑制冷却液中细菌、真菌和藻类的生长,从源头预防有机污染。需要注意的是,杀菌剂的种类和添加量必须严格符合IT设备厂商的要求,避免使用会与冷却液或系统材料发生反应的产品,同时要定期检测冷却液中的杀菌剂浓度,及时补充。
第四,避免长时间的安装停滞。如果安装过程必须中断超过一周,应启动TCS回路的循环泵,让冷却液保持流动并通过在线过滤器持续过滤,防止微生物在停滞的冷却液中繁殖。同时,应将所有未连接的管线端口用密封帽密封,防止灰尘和湿气进入系统内部。
此外,还有一些辅助措施能进一步提升污染防控效果:优先在洁净度达标的环境中进行组件预组装,减少外界灰尘的引入;尽可能采用焊接方式连接管道,减少螺纹接头的使用,从而降低密封剂污染和泄漏风险;焊接完成后,需对焊接区域进行钝化处理,恢复其抗腐蚀性能,并进行彻底清洗;检查所有钎焊和焊接接头,清除残留的焊剂,防止焊剂进入冷却液造成污染;详细记录所有安装和调试过程,包括环境温度、湿度、压力、冲洗时间和冷却液样本,以便在出现污染问题时快速追溯来源。最后,应与IT设备、CDU和冷却系统供应商密切合作,验证安装流程的合规性,必要时要求供应商提供抗菌包装或充氮运输的组件,防止运输过程中的污染。
02
运营阶段:两大核心挑战
与解决方案
DLC系统的安装完成只是其生命周期的开始,长期稳定的运营才是发挥其性能优势的关键。由于DLC技术相对较新,数据中心运维团队普遍缺乏相关经验,在运营阶段面临着厂商保修职责不清和GPU功率瞬变响应不足两大核心挑战。
2.1
厂商保修职责边界模糊的
挑战与应对
DLC系统与传统风冷系统的本质区别在于服务器与冷却基础设施之间的直接物理耦合。这种耦合使得任何一个环节的故障都可能影响多个组件,而由于行业标准尚未完善,不同厂商的保修条款之间往往存在重叠和冲突,导致故障发生时出现责任推诿,延误维修并增加运营成本。
保修职责模糊的问题主要体现在以下七个典型场景:第一,服务器内部发生漏液时,无法明确是服务器冷板本身的质量问题、CDU压力控制不当、还是安装过程中的接头连接问题;第二,CDU过滤器的更换周期和维护流程与服务器厂商的推荐不一致,运维人员无论遵循哪一方的要求,都可能面临另一方拒绝保修的风险;第三,安装承包商在施工过程中引入的缺陷(如管道焊接不良、密封剂使用错误)导致服务器损坏,责任在承包商、CDU厂商和服务器厂商之间难以界定;第四,长期的材料兼容性问题导致系统腐蚀和服务器损坏,无法确定是CDU厂商的材料选择不当还是服务器厂商的冷板材料不符合要求;第五,同一CDU为多个不同厂商的服务器提供冷却,而不同厂商对冷却液压力、温度和流量的要求存在差异,调整参数以满足某一厂商的要求可能导致其他厂商的保修失效;第六,两个相互配合的组件(如快速接头的公头和母头)分别来自不同厂商,且具有相互冲突的扭矩规格,遵循任一规格都可能导致另一厂商拒绝保修;第七,冷却液降解导致冷板结垢和损坏,但冷却液厂商和服务器厂商对“降解冷却液”的定义和检测标准不一致,无法确定责任归属。
针对上述问题,本文提出了以下核心应对指南:
第一,在系统规范阶段就提前厘清所有保修条款。在采购和设计阶段,就应仔细审查所有TCS组件(包括CDU、管道、阀门、快速接头、冷却液和服务器)的保修条款,识别其中的矛盾和模糊之处,并与相关厂商进行澄清,形成书面的责任界定文件。特别要明确漏液、腐蚀、污染和维护操作等关键场景的责任划分,以及故障发生后的响应流程和赔偿机制。
第二,将不同厂商的IT设备隔离在各自的TCS环路中。为每个厂商的服务器配置独立的TCS回路,每个回路的温度、压力和流量参数都严格按照该厂商的要求设置。这样可以避免因参数冲突导致的保修问题,同时在发生故障时也能快速定位责任方,大幅减少厂商之间的推诿。
第三,明确系统安装商、冷却系统厂商和IT厂商在运营和维护中的职责。签订三方服务协议,明确各方负责的维护内容、响应时间和故障处理流程。例如,明确CDU的日常维护由冷却系统厂商负责,服务器内部冷板的检查和更换由IT厂商负责,而管道和阀门的维护由安装商负责。同时,建立统一的故障上报和处理平台,确保所有问题都能得到及时响应。
第四,统一所有厂商的TCS运行参数要求。与所有IT供应商协商,确定一个共同的TCS供水温度、流量和压力范围,然后调整FWS系统的参数以满足这一范围。这样可以减少不同厂商之间的参数冲突,简化系统控制,同时也能降低因参数调整导致的保修风险。
第五,与所有厂商共同审核TCS维护程序。制定统一的维护手册,明确过滤器更换周期、冷却液检测频率和指标、管道冲洗流程等关键维护步骤,并确保所有厂商都认可该手册,避免因维护操作不当导致保修失效。同时,指定专门的负责人负责冷却液健康状态的监控和维护,定期检测冷却液的pH值、电导率、颗粒浓度和微生物含量,建立完整的冷却液健康档案。
此外,还应定期循环冗余或备用回路中的冷却液,防止微生物滋生;维护好FWS回路,保持其水质清洁,以延长CDU热交换器的使用寿命;在系统投入运行前,使用实际服务器的阻抗数据进行详细的流量分布分析,确保每个服务器都能获得足够的冷却液流量,避免因流量不均导致的局部过热和保修纠纷。
2.2
GPU功率瞬变导致的
过热风险与管控措施
AI训练任务的特点是GPU负载呈现高度的间歇性和同步性。在训练过程中,集群中所有GPU的功率消耗会同时快速上升和下降,形成剧烈的功率瞬变。这种瞬变对DLC系统的热响应能力提出了极高的要求,是运营阶段最容易被忽视但潜在风险最大的挑战之一。
根据本文引用的研究数据,GPU在AI训练过程中,每秒约发生4次功率峰值,峰值功率可达到其热设计功率(TDP,Thermal Design Power)的150%以上,每次峰值持续约50毫秒。虽然每次瞬变的持续时间很短,但由于热量在固体中的传播速度远慢于电能的传播速度,GPU产生的瞬时热量无法及时通过冷板传递到冷却液中,会导致GPU温度急剧升高。
本文通过建模分析了GPU在不同功率和冷却液温度下的温度变化(图6)。在稳态运行(100% TDP,700W)时,GPU的平均温度约为 78℃。当GPU功率飙升至150% TDP(1050W)并持续50毫秒时,GPU温度会在短时间内上升约10℃,最高达到91℃,这一温度已经接近大多数GPU的安全工作上限。如果DLC系统的热响应速度不足,或者冷却液温度设置过高,GPU温度可能会超过安全阈值,导致GPU自动降频以降低功耗,从而延长AI模型的训练时间;在极端情况下,还可能导致GPU永久性硬件损坏。
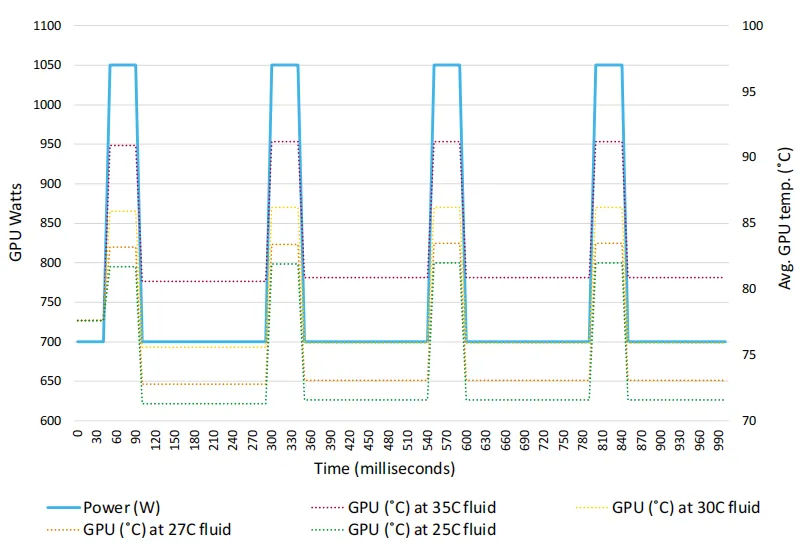
图6.在不同TCS温度下,
模拟了GPU在700W至1050W
不同功耗范围内的温度变化
需要注意的是,目前尚无公开的确凿证据表明GPU功率瞬变一定会导致硬件损坏,但不同GPU型号和封装结构的热特性存在差异,且DLC系统的设计和运行参数也会显著影响瞬态温度表现,因此这一风险必须得到足够的重视。
针对GPU功率瞬变的过热风险,本文提出了以下管控措施:
第一,通过软件对GPU进行功率限制。这是最直接有效的方法,可以强制GPU的功率不超过其TDP,从根本上消除功率瞬变。但这种方法会降低GPU的计算性能,导致AI训练时间增加,因此通常只在系统出现严重过热问题时作为临时解决方案使用。
第二,建立全面的系统测试和监控计划。在系统投入正式运行前,应使用典型的AI训练工作负载对单个TCS回路进行压力测试,逐步提高GPU的利用率,同时监控所有服务器的GPU温度、CDU的进出口温度、压力和流量。特别要注意同一回路中不同服务器之间的温度差异,因为流量分配不均可能导致部分服务器的GPU温度显著高于其他服务器。测试完成后,应保存系统的基准数据,以便在后续运行中对比分析异常情况。
第三,适当降低TCS冷却液的供水温度。这是提升系统瞬态热响应能力最有效的方法。根据热传递原理,GPU与冷板之间的温度差(deltaT)越大,热量传递的速度就越快。例如,如果GPU的平均温度为90℃,冷板的平均温度为40℃,deltaT为50℃;将冷板温度降低至35℃,deltaT将增大至55℃,换热速率将提升约10%。降低冷板温度最直接的方式是将FWS的供水温度降低相应的幅度,同时保持TCS和FWS的流量不变。需要注意的是,降低冷却液温度会增加制冷系统的能耗,因此需要在系统安全性和能效之间进行权衡。
第四,适当提高TCS回路的冷却液流量。增加流量可以降低冷板的平均温度,提升换热效率。但这种方法的效果不如降低冷却液温度明显,且会增加CDU泵的能耗,因此通常作为辅助措施使用。
第五,及时更新服务器和GPU的固件、驱动程序。厂商经常会发布固件和驱动更新,优化GPU的电源管理和热管理算法,从而降低功率瞬变的幅度和频率,提升系统的热稳定性。
第六,在系统投入运行后的前几个月内,持续监控GPU和系统的温度变化。通过长期的数据分析,建立系统的热特性模型,预测不同负载下的GPU温度表现,及时发现潜在的热问题。同时,密切关注行业动态和厂商发布的相关技术公告,了解最新的解决方案和最佳实践。
03
结论与后续行动建议
直接液体冷却技术是解决AI和HPC高密度散热问题的必然选择,但其在数据中心的规模化应用仍面临着安装和运营阶段的诸多挑战。TCS污染防控是安装阶段的核心质量控制点,直接关系到服务器的长期安全运行;厂商保修职责界定和GPU功率瞬变响应则是运营阶段需要重点关注的问题,直接影响系统的可用性和运维成本。这些挑战的产生,本质上是由于DLC技术尚处于发展早期,行业标准尚未完善,产业链各方的协作机制还不成熟。
为了成功部署和运营DLC系统,数据中心运营者应采取以下关键后续行动:
第一,与专业的设计公司、冷却系统厂商和系统集成商合作,使用成熟的行业参考设计作为起点。成熟的参考设计已经经过了充分的验证和优化,能够大幅降低设计风险,缩短项目周期。同时,专业的集成商拥有丰富的DLC系统安装和调试经验,能够有效避免常见的安装错误,确保系统质量。
第二,与IT供应商进行深度协作,获取精确的IT设备冷却需求。这是设计可靠、高效DLC系统的最重要前提。在确定服务器型号后,应向IT供应商索取详细的冷却参数,包括推荐的冷却液温度、流量、压力、化学性质、冷板材料、快速接头规格、过滤要求、热捕获率以及服务器的最大功耗等。这些参数将直接决定TCS系统的设计方案,任何参数的偏差都可能导致系统性能不达标或出现安全问题。
第三,建立并维护详细的受液材料清单(Wetted Materials List)。受液材料是指TCS回路中所有与冷却液接触的材料,包括CDU热交换器、管道、阀门、快速接头、密封件和服务器冷板等。应从ASHRAE和OCP等行业组织发布的标准材料清单开始,然后与各服务器厂商确认哪些材料与他们的冷板不兼容,逐步缩小清单范围。尽可能在整个TCS回路中使用相同或电化学电位相近的材料,以降低电偶腐蚀的风险。同时,应建立材料注册表,记录所有使用的材料信息,并在系统升级或维护时及时更新。
总之,虽然DLC系统在安装和运营阶段面临着诸多挑战,但通过遵循行业最佳实践,与产业链各方密切合作,建立完善的流程和体系,这些挑战都是可以有效应对的。随着行业标准的不断完善和技术的不断成熟,DLC系统将在数据中心得到越来越广泛的应用,为AI和HPC的持续发展提供坚实的基础设施支撑。
来源:公开信息,要点AI整理
提示:原创文章未经允许,请勿转载
免责申明:本文中所含内容乃一般性信息,包含的价格及观点仅供贵方参考,要点AI不对任何方因使用本文内容而导致的任何损失承担责任。

要点AI专注于人工智能在能源与工业领域的技术研发与应用,着力破解行业核心瓶颈与落地需求。我们通过数据赋能与深度洞察,协同产业伙伴系统研判人工智能在能源和工业系统的机遇与挑战,加速清洁能源转型。同步驱动AI算法模型、全栈技术在能源工业场景的创新研发,构建覆盖软件、硬件及系统解决方案的技术生态体系。

你们点点“分享”,给我充点儿电吧~
