最近在一个AI 共创群里,大家在讨论一个共同的痛点:用 AI 做事,代码类不容易出错,但其他东西好不好,完全要看人的判断力和审美。AI 每次产出一大堆,人看完都不容易。更要命的是,AI 现在的默认状态是——你写出什么垃圾它都给你好评,刚开始写第一行代码就说你打败 99% 的人。讨论到最后,有人问:这个问题两年内能不能解决?如果不能,第一代 AI 就要泡沫化了。我想把这场讨论整理一下,顺便把我自己这一年用 AI 的真实经验复盘一遍。不讲方法论,只讲我看到的结构。---
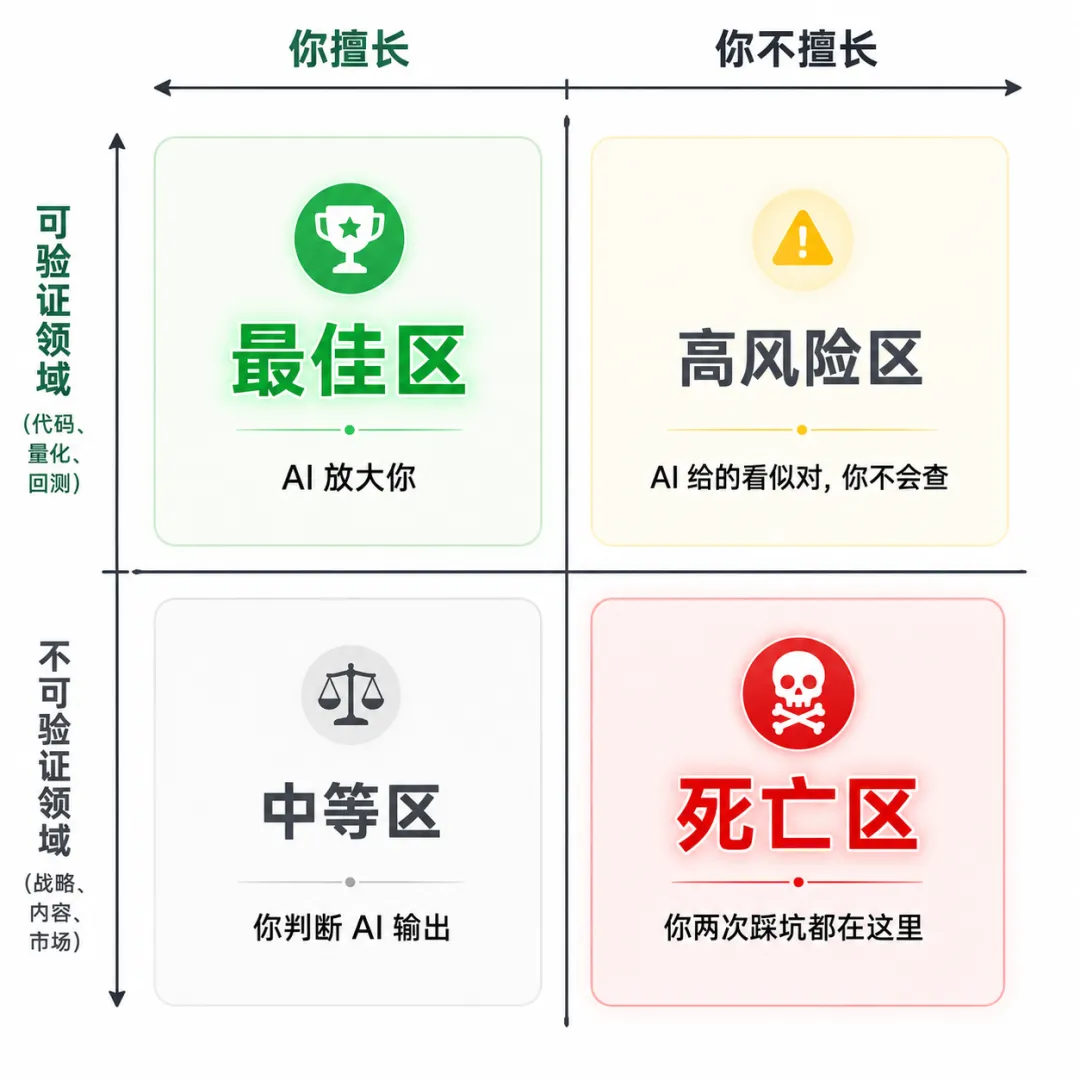
四象限还少了一个维度,补上才完整:反馈周期。短反馈周期(代码当天就能跑、回测当天出结果)= AI 杠杆最大、撞墙也修得快。长反馈周期(自媒体要 3 个月看流量、贸易要半年看复购)= AI 杠杆最危险、撞墙就是大损失。我两次坑都是长反馈周期,不是巧合。短反馈× 可验证 × 你熟悉 = 绿区,放手让 AI 干。长反馈× 不可验证 × 你不熟悉 = 死区,任何 AI 给的方案先打 70% 折扣。我现在的工作准则就建立在这条上。
六、关于"AI 没有洞察力"这件事
群里讨论时我说:人有一个能力 AI 没有,叫洞察力——没有依据和条件,能直接指向答案的能力。不一定有逻辑,但有时候直觉很准。有人反驳说:那叫经验。这个反驳对了一半。人类的"无依据直觉"实际上是三种东西的混合:第一是隐性经验**(tacit knowledge)。大量案例压缩成模式识别,你说不出依据,但模式其实在你脑子里。这部分,AI 通过足够多的训练数据确实在追平,甚至在某些垂直领域已经超过普通从业者。第二是跨域类比迁移。从领域A 的结构迁移到领域 B 的能力。这块当前 AI 架构是真的弱,尤其跨度大的时候。它能在领域内组合,但很难做"从生物学想到经济学"这种远距离的结构性迁移。第三是具身世界模型。物理直觉、社会直觉、对人的判断。人类有几十年真实世界交互训练数据,LLM 只有文本。让 AI 判断"这个人靠不靠谱""这事在中国市场行不行",它给的答案大部分时候是统计上的中位数,不是基于真实社会观察的判断。所以,"经验"这个反驳对的部分是:很多看起来神秘的洞察,本质就是压缩后的经验,可以被模式学习。错的部分是:跨域迁移和世界模型这两块,确实是当前 AI 架构的结构性短板,不只是数据量问题。
七、"两年内解决不了就泡沫化"这个判断,我自己拆一下
群里我说过一句:如果两年内 AI 不能解决"人只提问题、审核 AI 自己搞定"这件事,第一代 AI 就要泡沫化了,还不能完全替代智力人工。复盘一下,这句话里至少混淆了三件事:
技术问题:AI 能否自动审核自己
商业问题:AI 能否产生足够商业价值
替代问题:AI 能否完全替代智力劳动
这三件事不在同一条判断链上。历史类比:Excel 没有"完全替代会计",但创造了万亿级价值并重塑了整个会计行业。生产力工具不需要完全替代,augmentation 本身就是价值。更重要的是经济学硬定理——比较优势定律。即使 AI 在所有任务上都比人强,只要算力是有限稀缺资源,把 AI 用在它相对优势最大的任务上、把人用在 AI 相对优势最小的任务上,总产出更高。这意味着即使技术上 AGI 实现了,经济结构上"AI 干 95%、人干 5%"仍然是稳定均衡,而那 5% 在总产出里的价值分配比例可能反而上升。所以"完全替代"作为泡沫判断标准是错的。更准的泡沫锚点是:AI 资本开支(数据中心 + 芯片)的回收周期 vs 实际产生的生产力提升**。当前全球 AI capex 在 3000-4000 亿美元量级,这才是泡沫风险的真正度量。
八、对内容创作者和一人公司,真正的风险是什么
我的下行风险不是"AGI 实现导致我被替代"。这个风险离得远,而且大概率不会以"完全替代"的形式发生。我的下行风险是:AI 能力提升让大量内容创作者产能暴涨,信息噪音洪水化,高质量判断者的稀缺性溢价被淹没在信号噪音比恶化里。这个风险比AGI 风险近得多、确定性高得多。应对策略是反过来的:不绑定产能,绑定判断和身份。把每一次判断的过程、依据、修正都透明记录下来。AI 可以复制结论,但很难复制一个长期一致的判断轨迹。这也是我做"反身性"这个 IP 一开始的定位——我不是信号提供者,我是判断过程的透明记录者。AI 越强,这个定位的护城河反而越深,而不是越浅。
九、我现在的AI 协作准则,固化下来
把上面所有的认知压成可执行的三条:红线(死区)。任何"长反馈 × 不可验证 × 我不熟悉"的事情,AI 给的方案先打 70% 折扣,且必须找该领域真人验证一次再动手。重点不是找"反方"——AI 自己就能扮演反方,但 AI 反方的盲区跟 AI 正方的盲区可能高度重合。要找的是该领域真正承载 ground truth 的人。绿区(放手区)。"短反馈 × 可验证 × 我熟悉"的事情,放手让 AI 干,我只做 review。比特币量化属于这类,内容编辑也属于这类。这里追求的是极致效率。绿区里我现在用的一个具体做法:让另一个 AI 做 review**。生成成本指数级下降,验证成本没同步下降,这是 AI 协作里最棘手的矛盾(行话叫 generator-verifier asymmetry)。我的解法是把 review 本身也变成 AI 任务——一个 agent 负责生成,另一个 agent 用我预设的 review checklist 做风险分级(L1 致命问题 / L2 重大缺陷 / L3 改进建议 / L4 风格优化),我只看 review 摘要和被标红的部分。这条工作流让我能在不增加阅读负担的前提下,把 AI 产能放大 5-10 倍。黄区(协作区)。"我部分熟悉"的领域,允许 AI 协作,但保留更长的验证期,不要急着上规模。股票投资系统就在这里——代码层成功了,但策略层的真实表现要时间。
结语
回到最开始的那个问题:AI 协作的痛点能不能解决?我的判断是:靠等模型变强是解决不了的,靠工作流重构和认知重构可以。模型层面会持续进步,但"AI 给你信心十足的错误答案"这件事,不会因为模型升级而消失。它的根因不在能力,而在校准——模型对自己不确定性的诚实标注能力。这是个比"做对题"更难的问题。所以更现实的路径是:建立你自己的认知防火墙。知道哪些事可以信 AI,哪些事必须自己判断,哪些事必须找人验证。需要说清楚的是,这套认知不是对 AI 的悲观,恰恰相反。承认 AI 是放大器而不是发动机,意味着真正会用 AI 的人,杠杆比从前任何时代都大。问题只是——这个杠杆的支点在你自己身上,而不是在模型身上。模型每升级一代,杠杆倍数会上升;但如果你这一端是空的,升级再多代也撬不动东西。AI 是放大器。判断力是输入信号。输入是零,放大多少倍都还是零。这一年我最大的收获,不是学会了用 AI 做什么,而是越来越清楚——我自己作为信号源的质量,才是这套系统真正的瓶颈。
基本文件流程错误SQL调试
请求信息 : 2026-06-12 14:20:37 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/741262.html
 夜雨聆风
夜雨聆风