 夜雨聆风
夜雨聆风PPX 开源之后,我们解决了复杂 PDF / 图片文档解析的第一层问题:把文档变成结构化 Markdown、JSON、表格、坐标和版面对象。
但真实业务里,文档解析只是开始。年报、法律文书、审计报告、合同、理财说明书进入系统之后,下一步往往是:从里面稳定抽出字段。
比如年报里的审计意见、签字注册会计师、会计师事务所;法律文书里的案号、案由、裁判结果、审判人员;理财说明书里的费用、期限、风险提示和提前赎回规则。
这些字段不能只靠一次大模型回答。企业真正需要的是:字段定义清楚、抽取过程可复现、结果能评测、错误能回归,下一批文档还能继续复用。
Phoenix 要解决的,就是复杂文档字段抽取的工程闭环。
一、PDF 解析之后,字段抽取才是真正的业务入口
很多文档自动化项目,一开始都会把注意力放在“能不能读出 PDF 内容”。这一步当然重要。没有稳定解析,后面的 RAG、知识库、Agent、字段抽取都会失真。
但当 PDF 已经被解析成结构化内容之后,新的问题马上出现:业务到底要哪些字段?这些字段从哪里取?遇到不同模板、不同年份、不同公司、不同文书类型时,口径怎么保持一致?
这里要区分两种 JSON:一种是文档解析 JSON,解决的是“PDF 内容如何被机器稳定读取”;另一种是业务字段 JSON,比如从年报里抽审计意见、从法律文书里抽案号和裁判结果。
通常的文档抽取流程是,先把 PDF 解析成文档 JSON、Markdown、表格和版面结构,再在这个稳定中间层上做业务字段抽取。也就是说,先解决“文档内容在哪里、结构是什么”,再解决“我要的字段是什么、应该怎么抽、抽得对不对”。
如果跳过这层结构化文档结果,直接让大模型读一份 PDF,然后一次性生成业务字段 JSON,这种方式适合演示,不适合长期运行。它很难留下可复用资产,也很难在结果错了之后系统性修正。
Phoenix 的定位,就是把复杂文档字段抽取做成一个可迭代的工程流程:先定义字段,再生成标准答案和业务说明,再写可运行的抽取程序,最后用评测工具验证结果。
PPX 解决“复杂 PDF 怎么被机器读懂”。Phoenix 继续往下走一步:让字段抽取从一次性回答,变成可以持续迭代的工程资产。
二、直接问大模型,为什么不够
直接把 PDF、Markdown 或解析后的文档内容丢给大模型抽业务字段,通常会遇到几个问题。
字段口径不稳定。同一个字段,在不同文档里可能叫法不同、位置不同、格式不同。
结果无法评测。没有标准答案,就不知道到底抽对了多少。
错误无法回归。今天修了一个字段,明天换一批文档可能又坏掉。
能力难以复用。一次业务字段 JSON 结果很难迁移到下一批同类文档。
Phoenix 则会围绕一类文档类型建立对应的 workspace,把字段结构、业务规则、标注答案、抽取程序和评估记录都沉淀下来。
这一点很关键。复杂文档抽取不能停在“问一次,答一次”,它必须是一个“定义、开发、评估、修正、复用”的长期过程。
三、从问题出发:Phoenix 的三次关键迭代
Phoenix 的迭代不是简单地“多加几个 Agent”,而是围绕复杂文档抽取里不断暴露出的关键问题,逐步把系统能力拆清楚、做稳定。
问题一:抽取程序能不能被评估反馈驱动?
最早要验证的是一个基础判断:字段抽取不能只靠一次回答,必须能被评估结果反向驱动。于是第一阶段建立了“评估当前程序 → 定位错误样本 → 修改抽取逻辑 → 再评估”的闭环,用来证明抽取程序可以在评价反馈下持续改进。
问题二:错误来源能不能让 Agent 自己查清楚?
进入真实文档后,错误不一定只来自代码,也可能来自原文定位、表格结构、字段口径或标注答案。Phoenix的第二阶段把评估文档、代码的测试能力工具化,让 Agent 可以自己查看评估结果、打开错误样本、读取原文、运行局部测试,再做小步修正。
问题三:业务口径、程序开发和完成判断能不能分开?
当任务变复杂后,一个 Agent 同时理解业务、写代码、判断完成,容易把职责混在一起。Phoenix的第三阶段把系统拆成 Supervisor、BusinessAgent、DevAgent 和 xdev:Supervisor 判断下一步,BusinessAgent 负责字段口径、schema、labels,DevAgent 负责编写和修正 program.py,xdev 负责数据管理和正式评估。
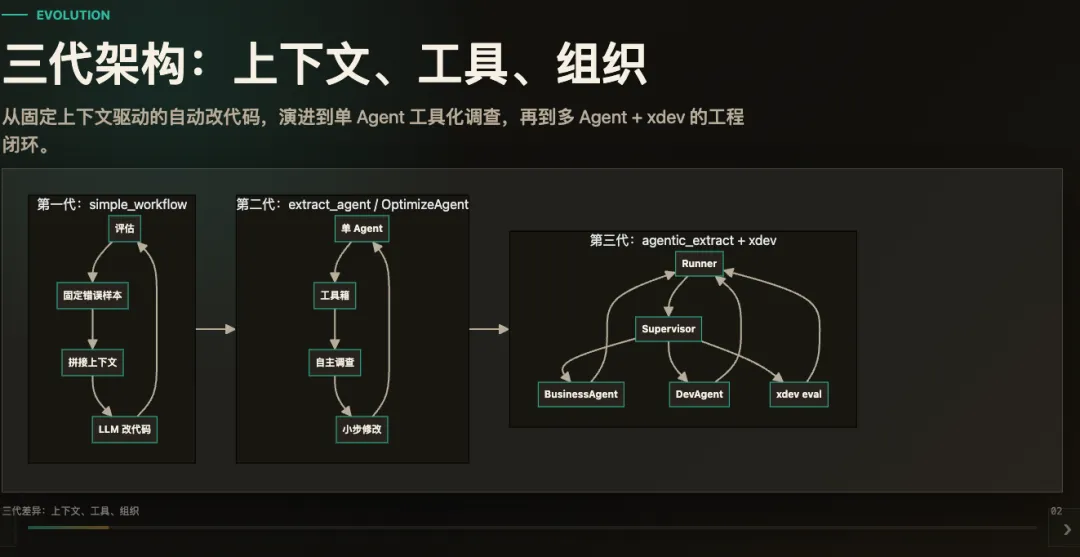
Phoenix 的三次关键迭代
这次迭代的关键变化,是把“完成判断”从单个 Agent 手里拿出来,交给正式评估和 Supervisor 决策。DevAgent 说“我改好了”只是过程信息,只有 xdev eval 跑过,系统才知道结果是否真的达标。
所以 Phoenix 当前的重点,是把文档抽取任务组织成一个有数据、有规则、有代码、有评估、有运行记录的工程系统,而不是追求某一次回答看起来漂亮。
四、跑完以后,留下的是一组工程资产
一次 Phoenix 任务跑完,留下来的不只是抽取结果,还包括一组可检查、可复用的文件。
这也是 Phoenix 选择生成 program.py 的原因。一次大模型输出很难复用,但一份程序可以审阅、可以测试、可以继续改,也可以迁移到相似任务。
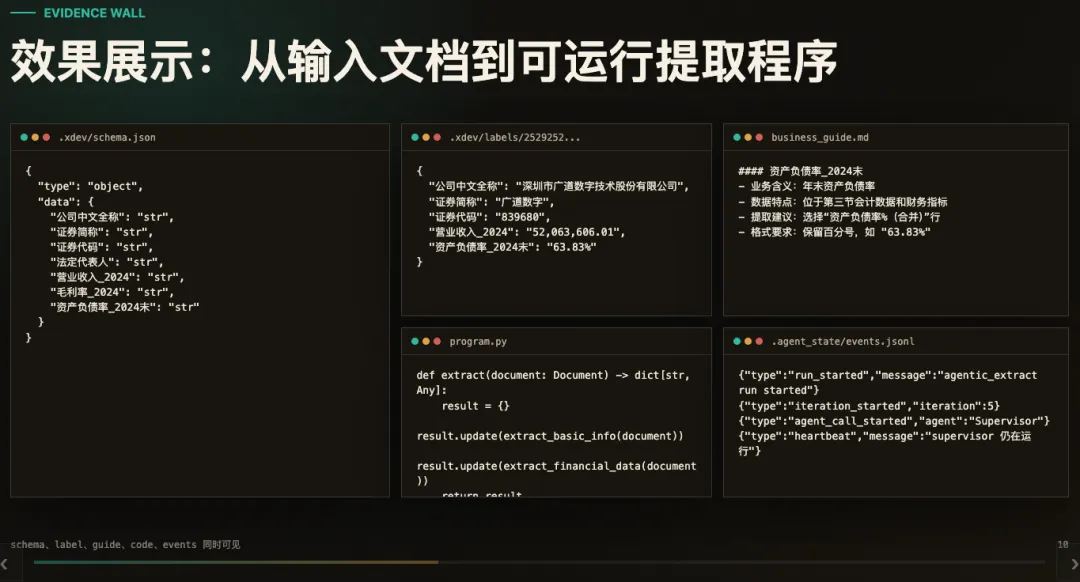
一次抽取任务跑完后,schema、labels、business_guide、program.py、events 会一起留下来,形成可检查、可复用的工程资产。
对企业文档自动化来说,这一点比“一次回答看起来像样”更重要。
五、实测案例:10 份 A 股年报审计意见,全量 eval 100%
在 A 股年报审计意见字段抽取测试中,Phoenix 从 1 份年报建场,再扩展到 10 份年报做泛化验证。
这 10 份文档覆盖深市主板、创业板、北交所,跨 2020、2023、2024 三个报告期,涉及 10 家公司、9 家会计师事务所、4 种审计意见类型。
本次抽取字段共 4 个:
is_audited:是否经过独立审计机构审计
domestic_audit_opinion_type:境内审计报告意见类型
domestic_signing_cpas:签字注册会计师姓名列表
domestic_audit_firm_name:境内审计机构名称
第一轮,Phoenix 接收第1 份最新年报,从零建立 workspace,自动生成 schema、business_guide、labels 和 program.py,并跑通单文档评估。

年报审计报告表格原文
第二轮,在同一个 workspace 中新增 9 份不同公司的年报。Phoenix 继续补标注、迭代 program.py,并在准确率回退时判断问题来源,区分代码逻辑问题和标注口径问题。
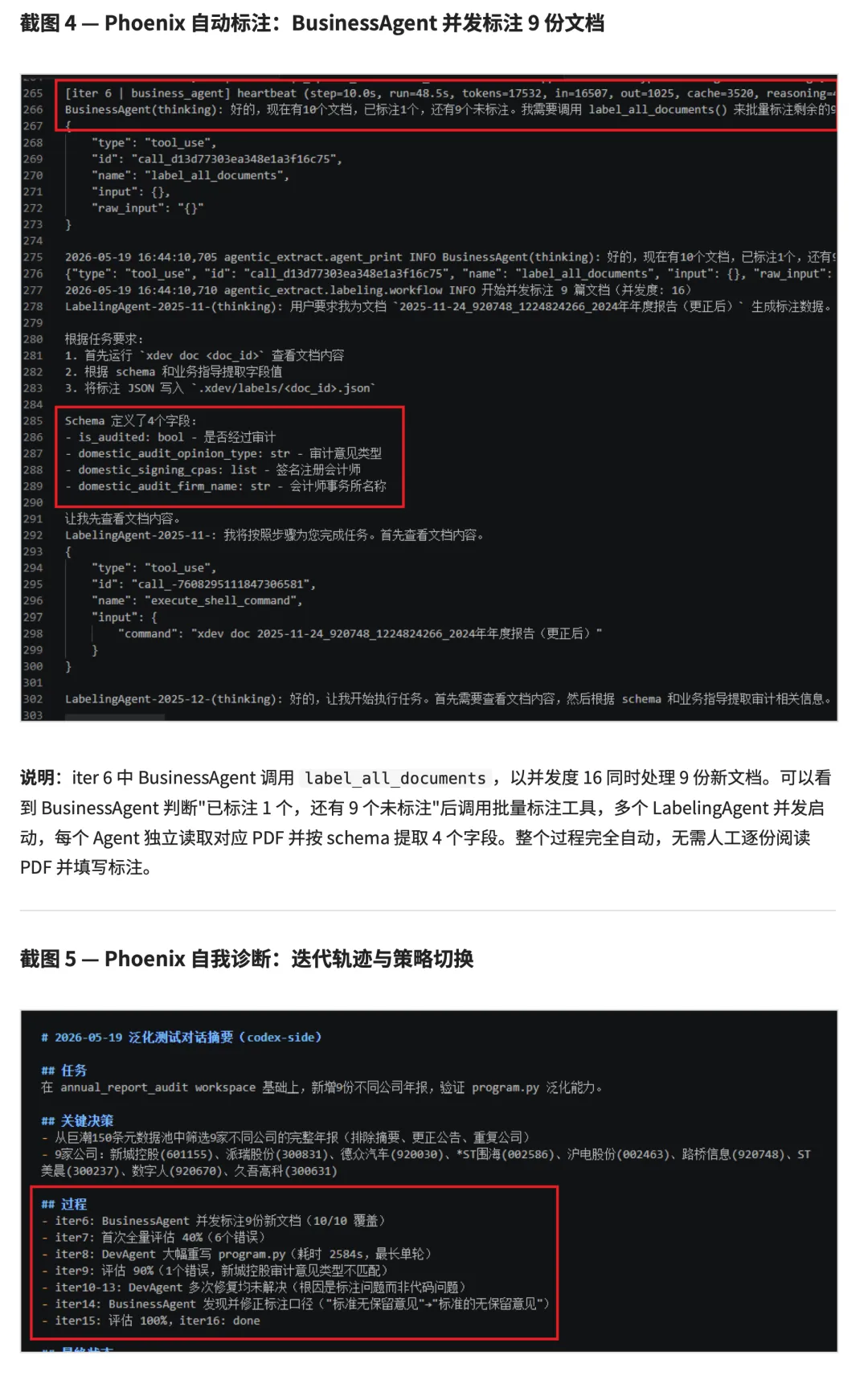
Phoenix 自动标注和自我诊断
最终结果
总体准确率:100.00%
字段平均准确率:100.00%
正确文档数:10
错误文档数:0
这个案例的价值不只在于结果达到 100%,更在于它验证了 Phoenix 的另一层能力:当结果不稳定时,系统可以根据运行记录和评估反馈选择修复路径。
六、再看一个法律文书案例
在最高人民法院法律文书测试中,输入是 5 份样例 PDF,全部为最高人民法院出具的民事裁定书或民事判决书。
任务目标是从零建立一个可复用的 court_case workspace,抽取 10 个字段:案号、文书类型、再审申请人、被申请人、原审法院、案由、裁定结果、审判长、审判员、裁定日期。

法律文书 PDF 原文与抽取结果
DevAgent 根据评估反馈反复重写 program.py,把代码从 99 行扩展到 289 行。
第 1 轮:BusinessAgent 创建 schema、business_guide 和 labels。
第 2 轮:初始 program.py 评估 。
第 3 轮:DevAgent 重写 program.py。
第 4 轮:5 份文档 eval 达到 100%。
第 5 轮:Supervisor 标记 completed。
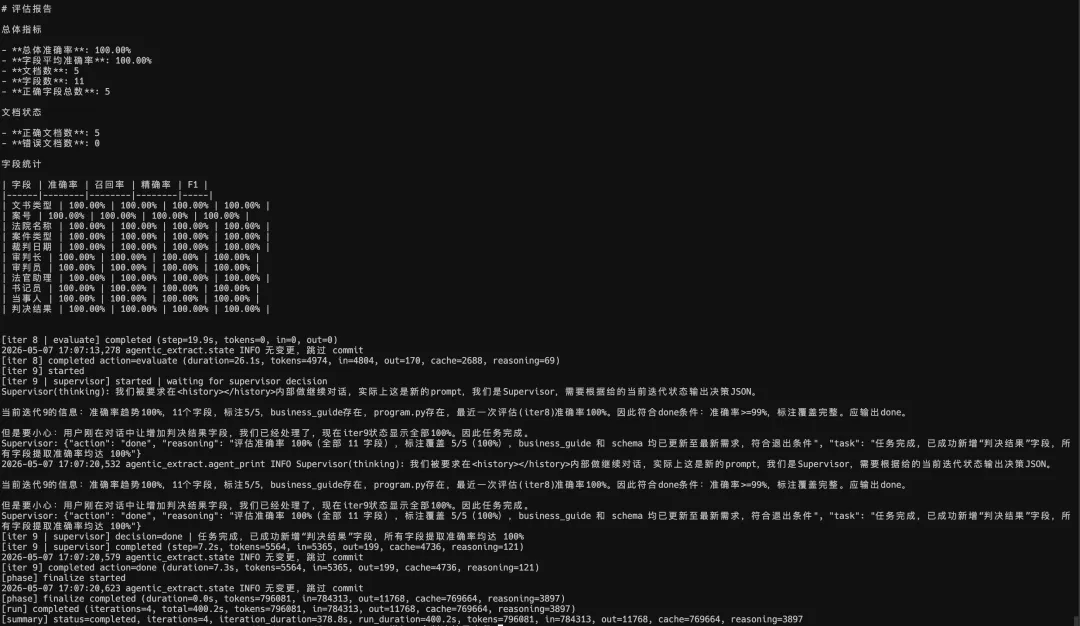
5 份文档、多个字段全量 100%,状态进入 completed。
Phoenix 的工作方式会把错误反馈带回系统,继续修正抽取程序,而不是第一次抽不对就结束。
七、开源之后,可以怎么试
Phoenix 开源地址:https://github.com/memect/phoenix
你可以用它处理自己的 PDF 样本,建立 workspace,定义字段,生成抽取程序,并用 xdev eval 检查结果。
适合先试的场景
年报字段抽取
审计意见抽取
法律文书结构化抽取
合同条款抽取
理财说明书费用、期限、风险字段抽取
从 PPX 到 Phoenix,我们想做的是同一件事的上下两层:先把复杂文档变成机器可以理解的结构化内容,再把字段抽取变成能评估、能迭代、能复用的工程资产。
如果你正在处理一批格式复杂、字段重要、结果必须可复核的 PDF,Phoenix 值得放进你的文档自动化工具链里试一轮。
欢迎使用
若无法进群,请添加小助手 wx 协助入群:black156983



