 夜雨聆风
夜雨聆风
摘要
在AI大语言模型与自动化编译反馈闭环的加持下,软件反编译正从少数专家的“孤立个案”演变为低成本的“工业化能力”。当攻击方的边际成本趋近于零时,传统软件依赖保密和授权机制的护城河正面临失效风险,甚至导致传统资产评估体系中“技术壁垒相对稳定”的底层假设发生动摇。
—— 吴国平律师 北京市隆安律师事务所
最近看到一个技术案例:一家企业因为无法接受海外软件公司每年近百万元人民币的访问授权费,于是技术团队开始研究软件的授权机制。他们通过wireshark抓包、IDA反编译、AI辅助分析以及二进制修改,最终绕过了软件公司的License验证。
在抓包过程中,因为数据包校验机制问题,直接抓包全是 TLS 加密乱码,因此需要配置 Chrome 输出 DEBUG 日志,配置环境变量 SSLKEYLOGFILE,在 Wireshark 中配置解析 DEBUG 日志,编辑->首选项->Protocols->TLS/SSL,然后新建用户变量 SSLKEYLOGFILE,编辑->首选项->Protocols->TLS->(Pre)-Master-Secret log filename 浏览选择上述生成的文件,在soft\Chrome\mytestssl.txt 文件中就会显示 Chrome 产生的密钥。而后通过IDA Pro搜索字符串定位核心函数,而后通过Xref 找到调用者,配合 DeepSeek 理清加密逻辑,最后跳过软件版权人设置的证书校验步骤。
从技术人员的角度看,这是一场精彩的逆向工程实战。但从律师的角度看,这却释放出一个危险信号:AI正在让软件破解变得越来越容易。过去,一个商业软件想被破解,需要经验丰富的逆向工程师投入大量时间。今天呢?IDA+调试器+查壳工具+系统运行监控+抓包(解密)构成了复合工具,其中AI大语言模型负责理解代码逻辑和解释加密算法。甚至连复杂的汇编代码,都可以轻松翻译成自然语言。
以前需要数年经验的逆向工程师完成的工作,现在可能只需要一个实习生加一个AI工具。传统的反编译工作,是以帮助程序员更快速、准确地分析闭源软件,应用场景是为缺少源代码的老旧系统提供更好的理解和维护方案。传统反编译方法依赖于静态分析技术,例如控制流图提取、函数调用图重构和 API 使用情况分析。虽然这些方法在受控环境中有效,但在混淆、打包和加密技术面前往往不堪一击,而且需要专家级分析师投入大量人工。AI工具的出现,大大打破了这种界限。
以下为一段截取的汇编代码:
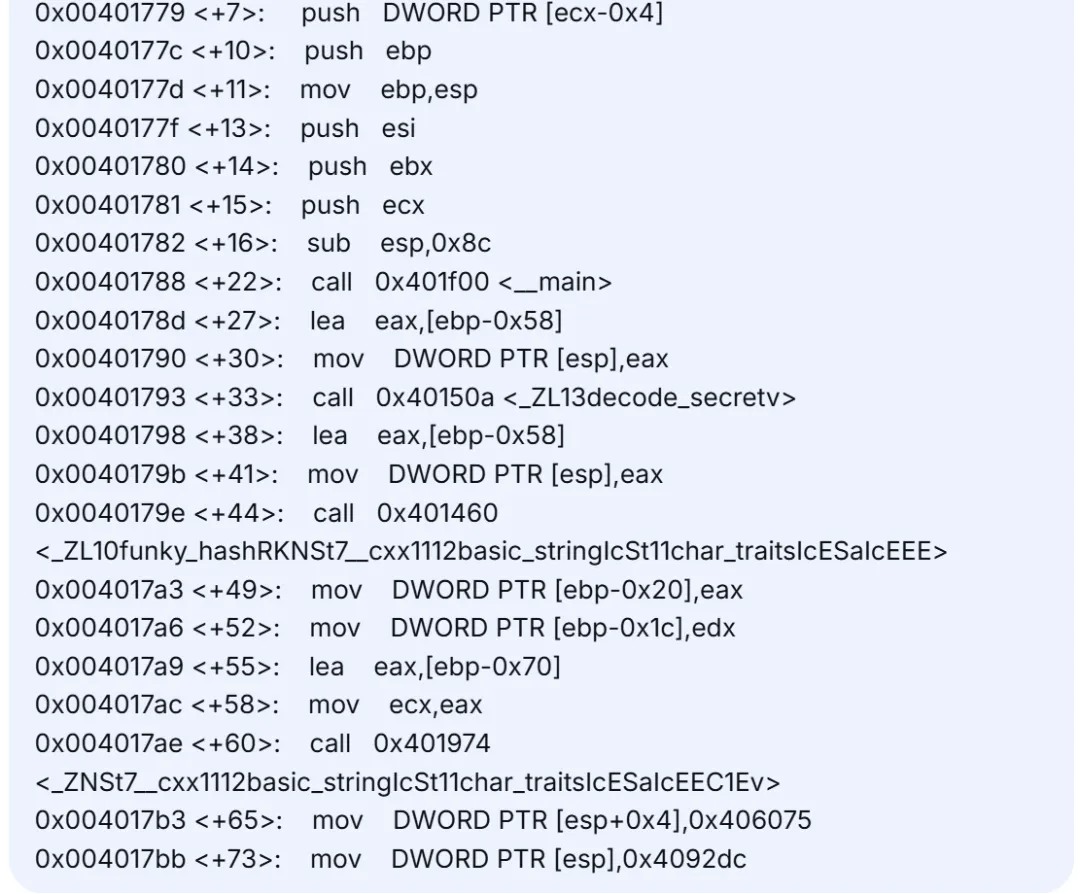
将上述代码发送给AI工具进行分析,可以很快了解汇编代码的函数调用关系,并且可以直接推测内存地址与字符串之间的关系,AI的部分分析截图如下:
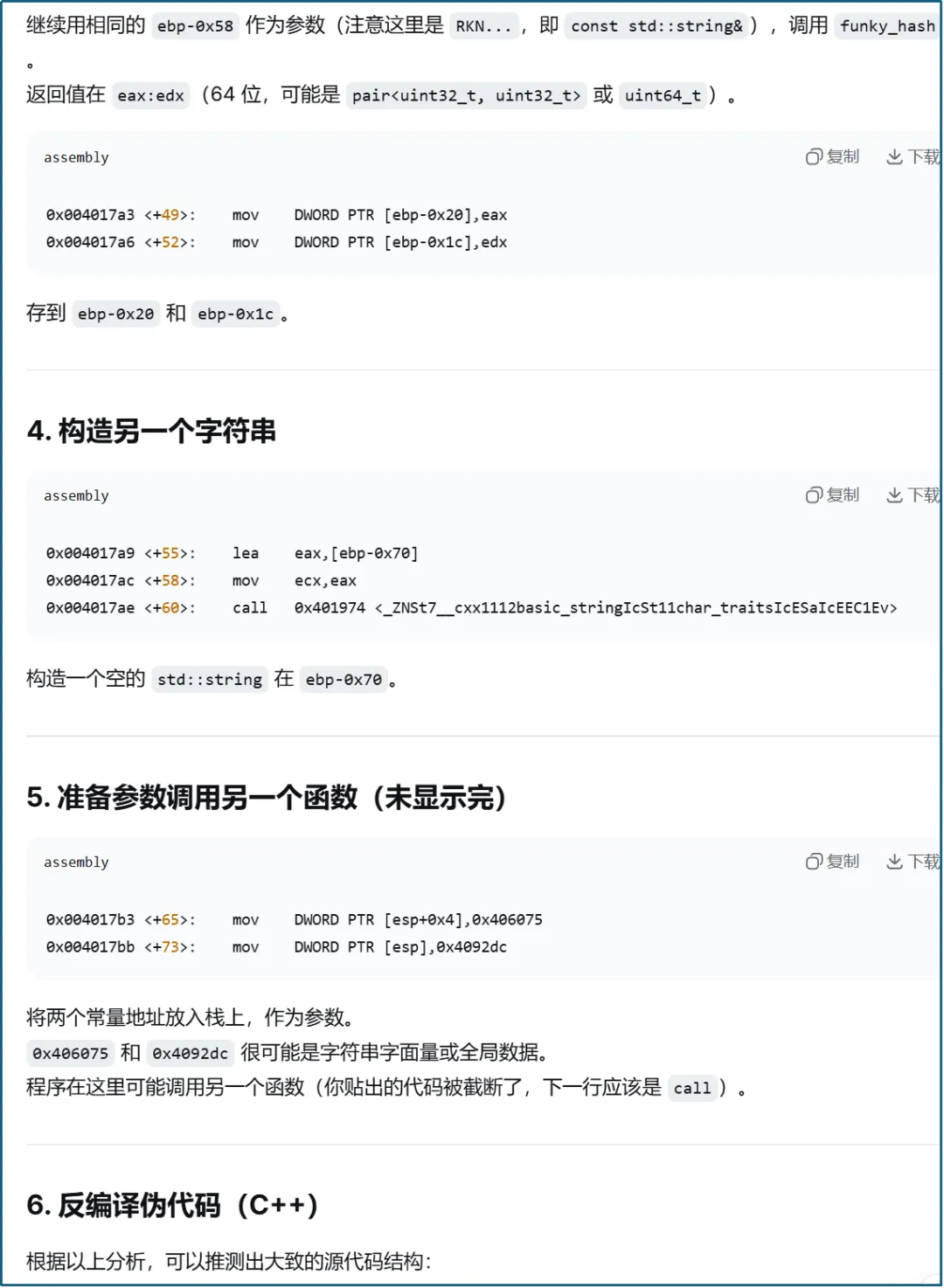
上述示例意味着软件公司的传统保护体系正在面临巨大挑战。很多软件公司一直认为:“我的源代码没有泄露,所以我是安全的。”事实上并非如此,对于很多商业软件来说,真正值钱的并不是源代码本身,而是License授权机制、加密算法、核心业务逻辑,而这些内容,正在成为AI辅助逆向工程的重点攻击目标。
更为严重的是,原来的软件反编译,注定了是极少数的个别专家才能完成的孤立案例,但是随着以大语言模型和海量数据进行训练的LLM4Decompile工具的出现,反编译技术已经由孤立的个案向工业化能力进行转变。
唯一制约反编译技术向工业化转变的瓶颈取决于数据规模和算力,一旦突破以上瓶颈,则反编译技术可能成为“普遍适用性”的工业化产品。
宾夕法尼亚大学借助大语言模型研究反编译新方案让LLM反编译正确率暴涨,他们的核心思路不是只相信模型的一次输出,而是让模型生成多个候选输出,再用编译器反馈选出最可能正确的版本,从而同时提升可读性与功能正确性。在这个过程中,反编译源码与真实源码的对应关系不再是一对一,而是N对一, 通过编译器自动反馈把候选代码重新编译,与原始二进制做字节级或汇编级比较,用真实编译结果筛掉低质量输出。宾夕法尼亚大学路线本质上是生成多个候选源码→重新编译→与原二进制比较→自动修正,已经开始形成闭环。这意味着反编译不再依赖程序员经验,而开始依赖算力和数据规模。
大型语言模型反编译要做的,不是从二进制编码中得到与版权人相同的源代码,他们充当的是翻译者或解释者的角色,它们能够生成有意义的变量和函数名称、生成清晰的自然语言摘要、标注程序逻辑并阐明复杂的调用结构。截止2026年6月可公开查询的数据显示LLM4CodeRE (S2S) 的可重新执行性最高可到86%,这无疑也显示了这种进步。
从经济角度,如果逆向成本低于重新开发成本,那传统软件产品的护城河就失效了,而且随着算力的不断提升,攻击方的成本会断崖式降低,当攻击方的边际成本趋近于零时,防御方的边际成本将趋向于无穷大。即,为了维持原版权价值,软件版权人维权支出比例必须随AI反编译能力同步增加,且最终必然导致版权保护体系颠覆。过去,反编译者需要雇佣高薪的逆向工程师,花费数周时间分析汇编代码。此时,软件版权人只需要投入相对较少的资源(比如5%的收入用于法务和技术防护),就能维持一种动态平衡。未来随着AI反编译工具(如LLM4Decompile)的不断进化,攻击者的门槛从“专家级”降到了“实习生”。以前需要数周的分析工作,现在AI几秒钟就能给出带注释的伪代码。最终版权人原本那5%的预算,为了堵住这些漏洞,防御方被迫将预算提升到20%、50%,甚至更多。但是,更复杂的混淆加密技术会严重影响软件的运行性能,例如卡顿、启动慢等,因此传统交付型软件产品面临空前压力。
从律师的角度,意味着未来的软件侵权案件,也将出现新的变化。过去的诉讼重点是:你是否复制了我的代码?”未来的诉讼重点可能变成“你是否通过逆向工程获取了我的技术秘密”、“你是否规避了我的技术保护措施”、“你是否非法重建了我的业务逻辑”。
未来,传统软件行业最大挑战,不是AI会不会写代码,而是AI会不会帮助别人更快地理解和重构你的代码。传统软件公司的竞争,正在从“开发能力竞争”逐渐演变为“保护能力竞争”。很多传统软件会发现破解版满天飞,那个时候,版权的价值损失往往已经很难挽回。
传统软件资产评估体系存在一个隐含假设,目前无论采用成本法、市场法还是收益法,对软件资产进行评估时,都存在一个几乎从未被明示的前提:软件产品的技术壁垒将在可预见的时间内保持相对稳定,换句话说,传统评估体系默认软件被破解的难度是相对稳定的、软件被复制的成本是相对困难的、软件核心逻辑被竞争对手理解和重构的难度是相对稳定的、软件授权体系的有效性是相对稳定的。 因此,在估算未来现金流时,通常不会单独考虑反编译技术进步所带来的价值侵蚀。
过去几十年中,这个假设一直成立。因为反编译始终属于少数逆向工程专家掌握的专业能力,其发展速度虽然持续推进,但总体呈现平缓渐进式演化。但是,AI反编译打破了传统评估模型的上述基础假设,大语言模型出现以后,情况发生了根本变化。以LLM4Decompile为代表的新一代AI反编译技术,其核心价值并不在于恢复与原作者完全一致的源代码,而在于快速理解软件逻辑、恢复业务流程、识别授权机制、重建算法结构。对于资产评估而言,这意味着原有假设的软件资产未来价值衰减曲线发生了断崖式的变化。原本需要数十年才能被突破的技术壁垒,未来可能一年甚至数月内就被显著削弱。
软件资产评估领域需要引进新的风险因子,如果借鉴金融行业的风险模型,可以将其理解为一种新的软件估值变量,简称ADR(AI Decompilation Risk)。
ADR评估变量主要用于评估软件核心逻辑被AI反编译理解的难度、License机制被AI反编译绕过的可能性、软件商业秘密被重构的可能性、现有技术保护措施的有效性。ARR与传统的软件质量评估、技术尽职调查、律师尽职调查并不相同,它关注的不是软件过去和现在的法律或经营状态,而是软件在AI反编译技术的冲击下还能否长期保持其独占价值。
目前资产评估机构、会计师事务所和审计机构已经能够完成软件开发成本测算、软件收益测算、软件市场价值分析。 但是他们通常缺乏以AI反编译能力评估、License体系攻击模拟、AI技术发展趋势研判,上述这些工作本质上超出了传统财务人员的专业边界。
我们的律师团队多年关注软件版权相关业务,联合反编译技术专家组成专项评估小组,为会计师、资产评估机构回答一个过去从未被认真讨论的问题:当AI反编译正在快速降低软件被理解、被重构、被复制的成本时,ADR变量将如何影响软件资产未来的价值?
律师团队以AI反编译工具为基础,通过软件样本逆向测试、软件授权系统评估、商业秘密暴露评估和盗版生态调查综合衡量分析短期内AI反编译技术发展对软件资产价值衰减的速度和趋势,目前已经初步形成标准化的ADR模型和综合性的评估指标,以ADR风险因子的形式成为软件资产评估过程中新增的重要参考指标。同时,ADR影响报告也有助于软件企业在新的时代重构软件资产的保护体系。窗体顶端
律师简介

吴国平 律师
隆安律师事务所 合伙人
吴国平律师的执业领域集中在科技与创新领域,拥有超过十余年的丰富实践经验。在软件行业的法律服务中,他深耕多年,特别是在软件版权保护、芯片行业法律事务、大数据和人工智能项目的法律合规审查等方面有着深入的研究与实践。
吴律师凭借其对科技发展的深刻理解,帮助众多科技企业解决复杂的法律问题,从软件著作权的保护到芯片产业的法律支持,再到AI项目的数据合规性审查,他都能提供专业而精准的法律服务。吴律师曾服务的客户包括IBM、Microsoft、三星等知名公司,还曾因代理阿里巴巴旗下公司案件而获得阿里巴巴法学院“创新奖章”,代理的三星公司的著作权侵权案件更是国内首例手机操作系统侵权案件。作为技术与法律交汇领域的专家,吴国平律师致力于为客户提供具有前瞻性的法律建议,助力企业在迅速变化的科技环境中稳步前行。
特别声明:本公众号所载的文章仅代表作者本人观点,不得视为北京市隆安律师事务所出具的法律意见。如需转载或引用以上文章内容,须征得作者本人同意。
关于隆安

