夜雨聆风
夜雨聆风一、DADA2介绍
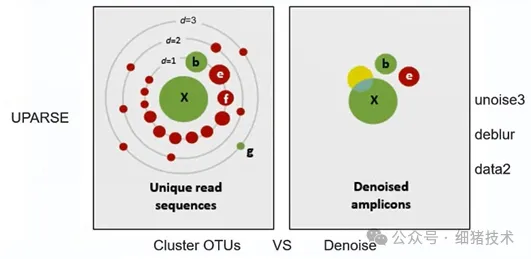
DADA2(Divisive Amplicon Denoising Algorithm 2)是一个用以自身数据构建的错误模型来推测和修正扩增子序列错误的R包,且不依赖其他参数分布模型。DADA2算法可以准确地推断序列单核苷酸差异,往往比其他方法识别更多真实扩增子变体和筛除更多虚假序列。DADA2充分利用了更多数据,例如错误模型包含质量信息和定量丰度,用以质量过滤后的推断和计算各种转置概率。DADA2去噪算法不同于OTU聚类算法,二者优劣详情请参考Callahan BJ, McMurdie PJ, Holmes SP. Exact sequence variants should replace operational taxonomic units in marker-gene data analysis. ISME J. 2017 Dec;11(12):2639-2643. doi: 10.1038/ismej.2017.119. Epub 2017 Jul 21. PMID: 28731476; PMCID: PMC5702726. https://doi.org/10.1038/ismej.2017.119.简单来说,聚类算法往往以97%相似水平聚类形成聚类群(OTU)且选择每个OTU中绝对丰度最高的序列作为代表性序列。如下图左小图所示,聚类算法将获取的绿色真实序列群(X/b/g)和众多红色虚假序列群统一纳入X真实序列群中,形成了一个以X为代表性序列的OTU,导致纳入了大量虚假序列和丢失了真实序列b和g。去噪算法基于定量丰度与测序原理评估识别“真实序列”来作为ASV,如下图右小图所示,降噪算法获取了真实序列群X、b和虚假序列群e,然后通过丰度过滤或模型参数识别筛除e。
二、DADA2安装
(1) 请参考Windows系统安装R+RStudio+Rtools安装R、RStudio和Rtools
(2) 使用R创建一个R脚本DADA2.R,放入新建R工作文件夹D:\R
(3) 关闭R,重新打开DADA2.R,此时R工作路径为D:\R
(4) 参考https://benjjneb.github.io/dada2/dada-installation.html安装DADA2
# 设置国内清华源镜像加速下载site="https://mirrors.tuna.tsinghua.edu.cn/CRAN"# 检查是否存在Biocondoctor安装工具,没有则安装if (!requireNamespace("BiocManager", quietly = TRUE))install.packages("BiocManager")
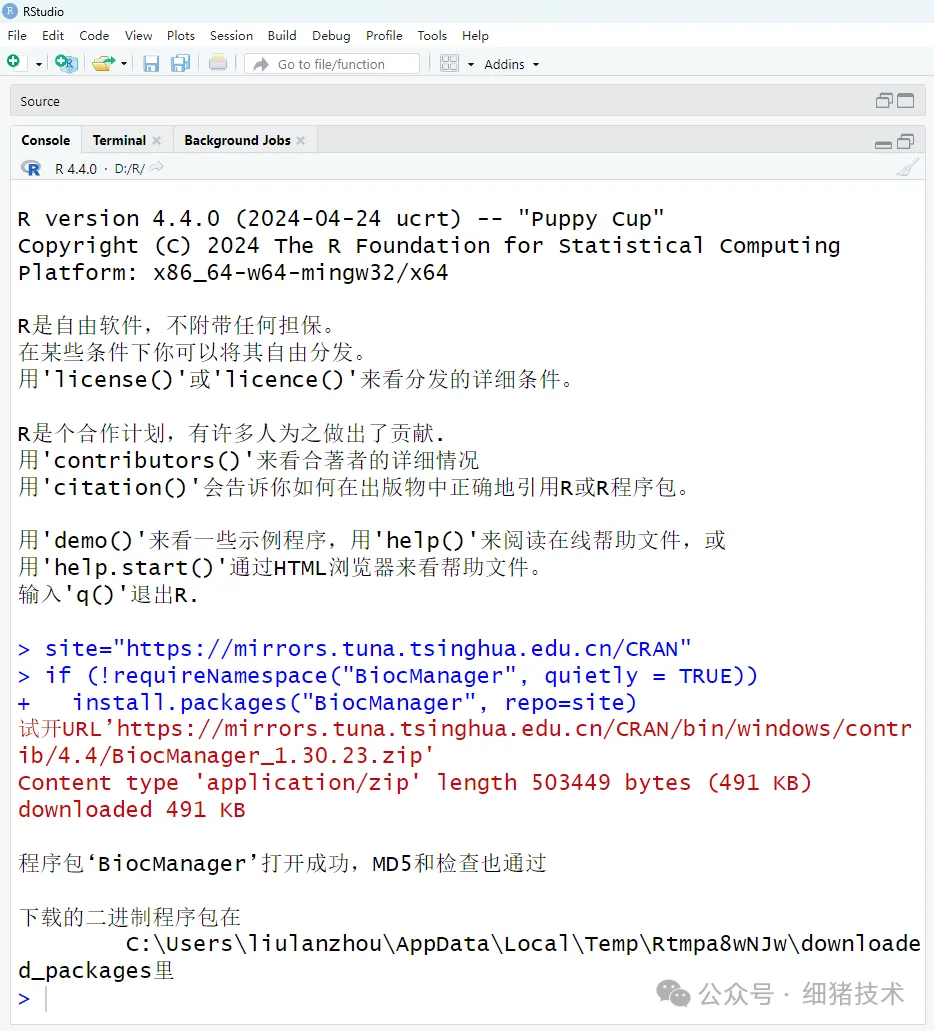
# 加载安装工具与安装DADA2,根据提示信息选择安装合适的DADA2版本library(BiocManager)BiocManager::install("dada2", version = "3.19")
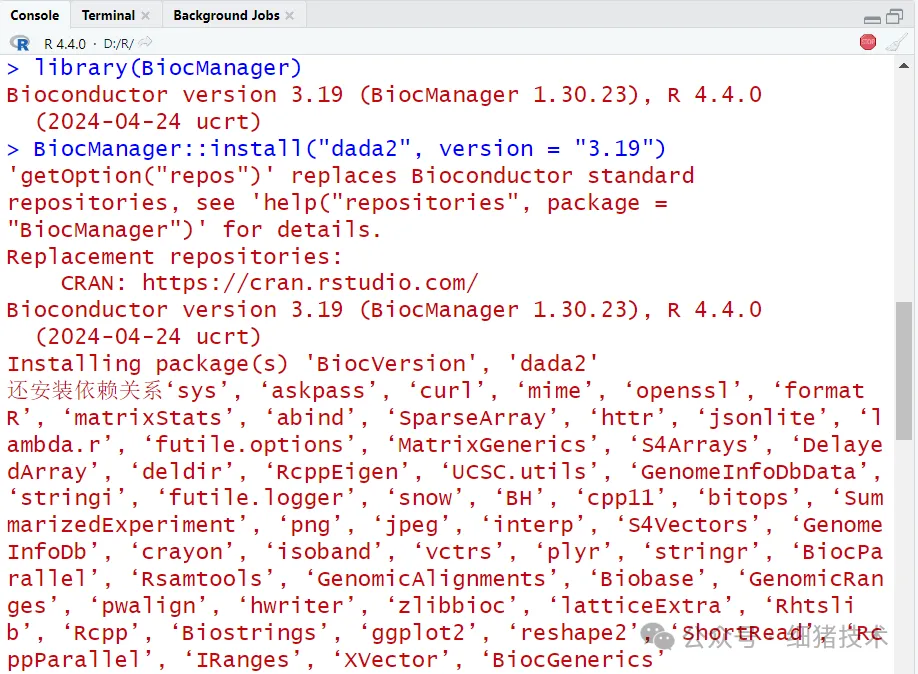
# 加载DADA2包library(dada2)# 显示R包版本信息packageVersion("dada2")# 使用命令“?`dada2-package`” 或”help("dada2-package")”获取DADA2包的帮助文档。针对任何内置或加载获取的R包均可以使用“?R包名称”获取相应函数的帮助文档,包括内置命令、参数选择与使用方法等。?`dada2-package`help("dada2-package")