 夜雨聆风
夜雨聆风1. 一个让CUDA老兵沉默的事实
2023年,OpenAI发布了一组让整个GPU编程圈震动的数据:用Triton写的融合Softmax内核,比PyTorch原生实现快了3倍;用不到25行代码实现的矩阵乘法,性能追平了NVIDIA工程师调了十年的cuBLAS。
一个不会写CUDA的研究员,用Python写了几十行代码,跑出来的性能竟然和NVIDIA最顶尖的优化库打平——这在三年前简直不可想象。
更让NVIDIA紧张的是,PyTorch 2.0的默认编译器TorchInductor,直接把Triton当成了GPU代码生成的后端。这意味着全球几百万PyTorch用户,在调用torch.compile()的那一刻,已经在不知不觉中用上了Triton。
CUDA的护城河,正在被一种Python风格的GPU编程语言从内部瓦解。Triton不是在CUDA之外另起炉灶,而是在CUDA之上构建了一层让普通人也能驾驭高性能GPU编程的抽象。
2. 写CUDA到底有多痛苦?
要理解Triton为什么能颠覆CUDA编程,得先知道写CUDA到底有多难。
假设你要实现一个简单的Softmax操作。在PyTorch里,一行代码就搞定了:
output = torch.softmax(x, dim=-1)但如果你要用CUDA C++手写这个kernel,你面对的是这样的世界:
- 线程管理
:你要决定每个block多少个线程,每个线程处理哪些数据 - 内存层次
:你要手动管理全局内存(HBM)、共享内存(SRAM)、寄存器之间的数据搬运 - 访存合并
:你要确保连续线程访问连续内存地址,否则性能断崖式下降 - 同步机制
:block内的线程同步用 __syncthreads(),跨block?对不起,得结束kernel重来 - bank conflict
:共享内存的bank冲突会让性能直接腰斩
一个有经验的CUDA工程师,写一个高性能的融合Softmax大约需要150-200行C++代码。其中真正描述算法逻辑的只有20行,剩下的全是性能优化细节。
CUDA编程的核心矛盾:性能的瓶颈从来不是算法,而是对硬件细节的管理。现代GPU真正的瓶颈是"数据搬不动"而不是"算得不够快"。
现代GPU的性能天花板被两个东西锁死:
- 内存带宽
:HBM到SM的数据搬运速度,远低于SM的计算速度 - kernel启动开销
:每次调用kernel,CPU要向GPU发送指令,这个延迟在微秒级
对于大模型训练来说,一个Transformer层里,LayerNorm、GELU、Dropout这些逐元素操作,每个都要单独启动kernel,每个都要把中间结果写回HBM再读出来。
GPU在等内存,而不是在等计算。
3. Triton的魔法:从线程到分块
Triton的核心理念可以用一句话概括:别管线程,只管分块。
在CUDA里,你编程的最小单位是线程(thread)。你要思考"第37个线程应该读哪个地址的数据"这种问题。
在Triton里,你编程的最小单位是块(block/tile)。你只需要思考"这个程序实例应该处理哪一块数据"。
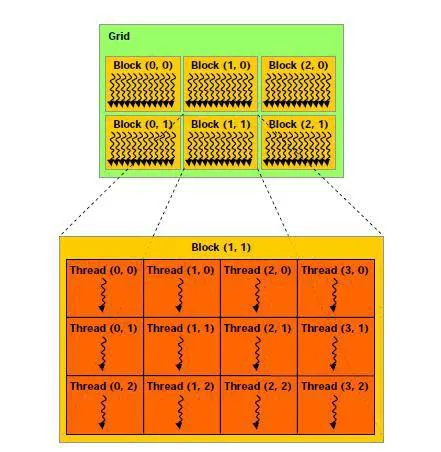
GPU线程层级结构:CUDA要求你在Thread级别编程,Triton让你在Block级别编程
来看一个最直观的例子——向量加法:
// CUDA C++ 版本:线程级编程__global__ voidadd(float* x, float* y, float* out, int N){int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) { out[idx] = x[idx] + y[idx]; }}# Triton 版本:块级编程@triton.jitdefadd_kernel(x_ptr, y_ptr, out_ptr, N, BLOCK_SIZE: tl.constexpr): pid = tl.program_id(0) offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE) mask = offsets < N x = tl.load(x_ptr + offsets, mask=mask) y = tl.load(y_ptr + offsets, mask=mask) out = x + y tl.store(out_ptr + offsets, out, mask=mask)看起来代码量差不多?但注意一个关键区别:在CUDA里,你是在单个线程的视角下写代码;在Triton里,你是在一个block的视角下写代码。
这意味着Triton编译器可以在后台帮你做很多事:
- 自动内存合并
:你写 tl.load(x_ptr + offsets),编译器自动确保这些访问是合并的 - 自动共享内存管理
:中间结果自动缓存在SRAM,不需要你手动声明 __shared__ - 自动指令调度
:SM内部的warp调度、指令流水线,编译器全包了
你唯一需要决定的,是数据怎么分块——也就是SM之间的工作分配。这正是算法层面最重要的决策,也是Triton唯一留给程序员的控制权。
4. 算子融合:Triton的杀手锏
如果说"块级编程"是Triton的骨架,那算子融合就是它的灵魂。
在大模型训练中,一个典型的操作序列可能是:
LayerNorm → Linear → GELU → Linear → Dropout在PyTorch的eager模式下,这5个操作会启动5个独立的GPU kernel。每个kernel都要从HBM读取输入、计算、把结果写回HBM。5次HBM读写。而在很多情况下,中间结果完全可以留在寄存器或L2 cache里,直接传给下一个操作。
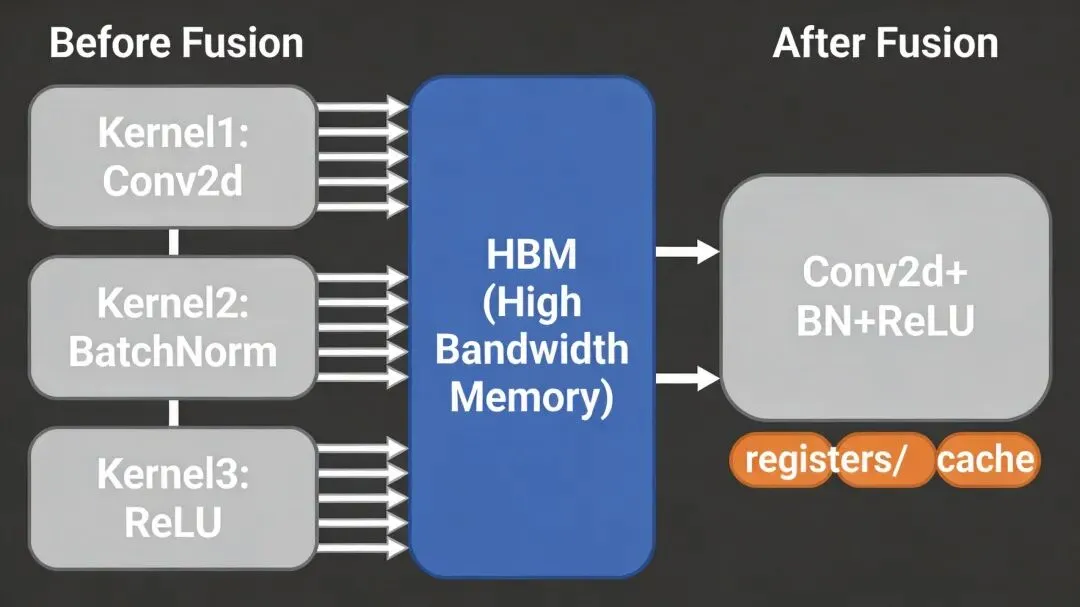
算子融合的核心价值:中间结果留在片上存储,省掉昂贵的HBM访问
这在CUDA里实现起来极其痛苦。你要手动把BatchNorm和ReLU的逻辑揉进Conv2d的kernel里,重新规划共享内存的使用,处理数据布局的转换。每融合一个新操作,代码复杂度就翻倍。
而在Triton里,融合就是自然而然的事情:
@triton.jitdeffused_layer_norm_gelu_kernel( x_ptr, out_ptr, weight_ptr, bias_ptr, N, eps: tl.constexpr, BLOCK_SIZE: tl.constexpr): row_idx = tl.program_id(0) offsets = row_idx * N + tl.arange(0, BLOCK_SIZE)# 加载一行数据 x = tl.load(x_ptr + offsets) w = tl.load(weight_ptr + tl.arange(0, BLOCK_SIZE)) b = tl.load(bias_ptr + tl.arange(0, BLOCK_SIZE))# LayerNorm —— 中间结果留在寄存器 mean = tl.sum(x, axis=0) / BLOCK_SIZE var = tl.sum((x - mean) ** 2, axis=0) / BLOCK_SIZE x_norm = (x - mean) / tl.sqrt(var + eps) x_norm = x_norm * w + b# GELU —— 直接使用寄存器中的x_norm,无需HBM读写 out = x_norm * 0.5 * (1.0 + tl.erf(x_norm / 1.41421)) tl.store(out_ptr + offsets, out)看,LayerNorm和GELU之间的数据传递完全是隐式的——x_norm就待在寄存器里,没有额外的HBM访问。
Triton最核心的竞争优势:它让算子融合从一项需要顶级工程师数周才能完成的工作,变成了一个普通研究员用Python就能搞定的事情。开发效率提升3-10倍,性能却能达到手工优化CUDA的80-100%。
5. torch.compile:Triton的生态奇袭
如果说Triton是一门好语言,那torch.compile就是让这门语言占领世界的特洛伊木马。
当你写下这行代码时:
model = torch.compile(model)你的模型经历了一段奇妙的旅程:
5.1 TorchDynamo——捕获计算图
Dynamo在Python字节码层面拦截你的代码。它不关心Python的控制流、print语句、debug代码——它只盯着PyTorch的张量运算,把连续的运算序列提取成一个FX Graph。
# 你的代码defforward(self, x): x = self.linear1(x) # Dynamo看到了一个matmul+add x = torch.relu(x) # Dynamo看到了一个relu x = self.linear2(x) # 又一个matmul+addreturn x# Dynamo捕获的FX Graph# placeholder(x) → matmul → add → relu → matmul → add → output5.2 AOTAutograd——反向传播也编译
AOTAutograd把前向图和反向图都捕获下来,这样训练和推理都能受益于编译优化。传统框架只在推理时编译,而PyTorch 2.0让反向传播也享受融合加速。
5.3 TorchInductor——生成Triton代码
这是最精彩的部分。Inductor分析FX Graph,把可以融合的操作打包在一起,然后直接生成Triton kernel代码。
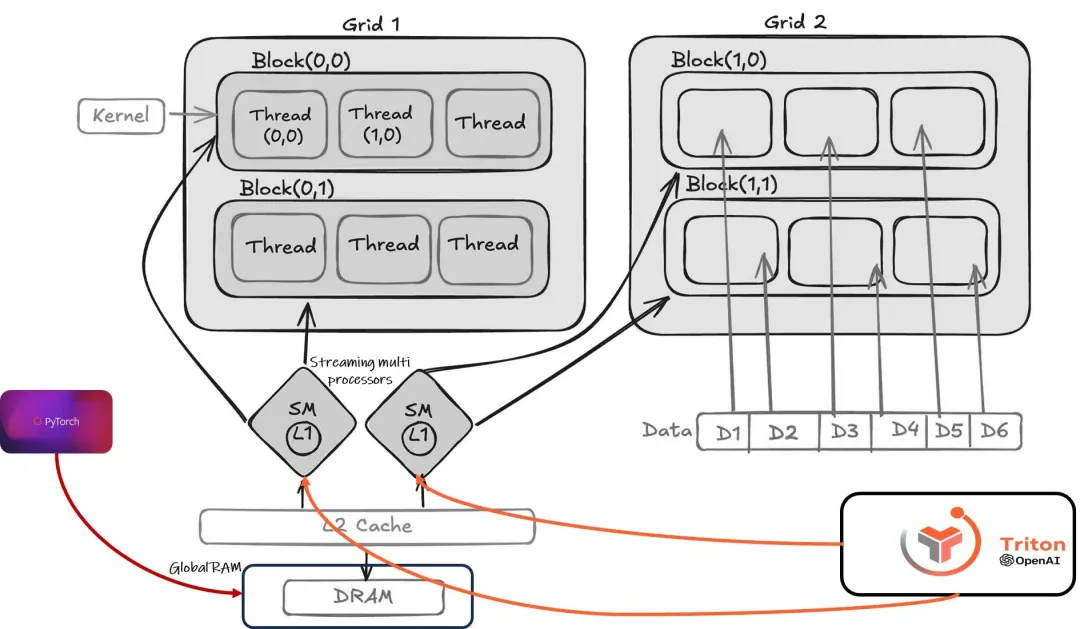
Triton在PyTorch编译栈中的位置:Dynamo捕获图 → Inductor生成Triton代码 → GPU执行
设置TORCH_COMPILE_DEBUG=1,你会看到Inductor生成的Triton代码:
@triton.jitdeftriton_fused_kernel(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK: tl.constexpr): xoffset = tl.program_id(0) * XBLOCK xindex = xoffset + tl.arange(0, XBLOCK)[:] xmask = xindex < xnumel# 融合了 cos + sin 两个操作的单一kernel tmp0 = tl.load(in_ptr0 + xindex, xmask) tmp1 = tl.cos(tmp0) # cos结果留在寄存器 tmp2 = tl.sin(tmp1) # 直接使用寄存器中的cos结果 tl.store(out_ptr0 + xindex, tmp2, xmask)两个操作被融合进了一个kernel,cos的结果直接传递给sin,省掉了一次HBM读写。这个过程完全自动,用户不需要写任何Triton代码。
关键数据:对于180+个真实模型,torch.compile实现了2.27倍推理加速和1.41倍训练加速。这背后最大的功臣就是Triton后端的自动算子融合。
6. 性能真相:Triton真的比CUDA快吗?
这是最容易引起误解的问题。让我把话说清楚:
Triton不会让你写的每一段代码都比CUDA快。
Triton的性能优势来自三个场景:
| 算子融合 | 1.5-3x | |
| 自定义操作 | 最高35.7x | |
| 跨平台可移植 |
一位医学AI研究者用Triton把状态空间模型的推理延迟从805ms压到23ms——35.7倍加速。关键操作是"时间感知插值+推理"的融合,这个组合没有任何现成库支持。
但Triton也有短板:
- 标准矩阵乘法
:cuBLAS已经把GEMM优化到极致,Triton很难超越,最多追平 - 极小规模运算
:Triton的JIT编译有启动开销,对小tensor反而不划算 - 极致底层控制
:如果你需要warp-level的精确指令编排,CUDA仍然是唯一选择
NVIDIA显然也意识到了Triton的威胁。他们开发了CUDA Tile IR后端,让Triton可以编译到Tile IR而不是PTX。这保留了Triton的高层抽象,同时利用了NVIDIA底层的Tensor Core优化。某种意义上,这是NVIDIA在"打不过就加入"。
7. Neptune:算子融合的新前沿
Triton解决了"简单融合"的问题——逐元素操作、简单的reduction,融合起来很自然。但对于复杂的reduction操作,比如注意力机制中的Softmax,现有编译器还是会卡壳。
2025年发表的系统Neptune提出了一个激进的思路:故意打断数据依赖,再用代数修正项补偿。
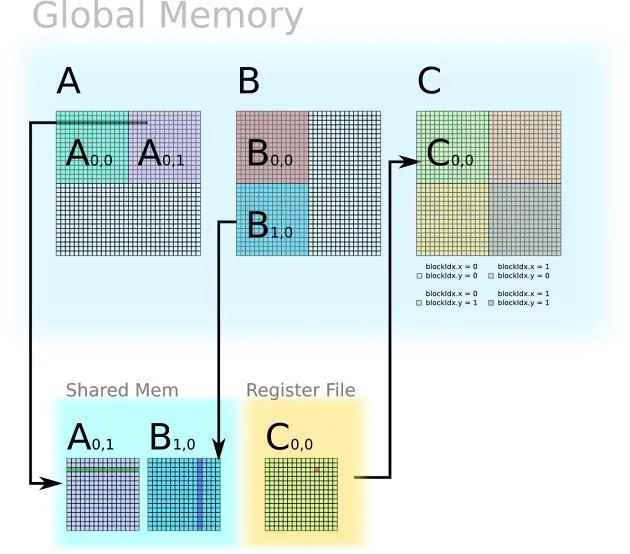
GPU内存层次结构:优化的本质是让数据尽量留在更快的存储层
听上去很疯狂,但效果惊人。把Neptune的高级融合应用到普通的注意力操作上,它自动生成了等价于FlashAttention和FlashDecoding的优化内核。在10个注意力变体的测试中,Neptune比Triton、TVM、FlexAttention都快——平均1.35倍,在AMD GPU上最高3.32倍。
AI编译器的竞争正在从"能不能融合"进化到"能融合多复杂的东西"。FlashAttention级别的优化不再是天才程序员的专属,编译器正在自动推导出同样高效的融合策略。
8. 行业判断:编程范式的权力转移
回到文章开头的问题:Triton为什么能让普通人写出比CUDA还快的kernel?
答案不是Triton比CUDA更强——Triton编译出来的底层代码,本质上还是跑在CUDA硬件上的。答案在于Triton改变了性能优化的抽象层级。
在CUDA时代,高性能 = 对硬件的深度理解 + 大量的手工优化。这是一项只有极少数专家才能掌握的技能,也构成了NVIDIA生态的护城河。
在Triton时代,高性能 = 正确的分块策略 + 编译器的自动优化。分块策略是算法层面的决策,编译器负责把它映射到硬件。这意味着性能优化的核心能力,从"理解GPU架构"转移到了"理解算法结构"。
判断一:AI编译器会重塑GPU编程的权力格局。当Triton/TVM/XLA这类编译器足够成熟,芯片厂商只需要提供Tile IR级别的接口,而不是让每个开发者都学一套专有的编程语言。这对AMD、Intel等NVIDIA的挑战者是巨大利好——它们不需要再追赶CUDA的生态壁垒,只需要在编译器后端支持上做到位。判断二:算子融合是AI系统性能优化的终局。随着模型越来越大、内存带宽越来越成为瓶颈,把更多操作融合到更少的kernel里会变成最重要的优化手段。未来的AI编译器不会只做"简单的逐元素融合",而会像Neptune那样,自动推导出等价于FlashAttention的复杂融合策略。
GPU编程的未来不是写更快的CUDA代码,而是让编译器替你写最快的代码。而你,只需要告诉它算法逻辑。当编译器足够聪明,编程语言的门槛就不再是瓶颈,算法思维才是。
