 夜雨聆风
夜雨聆风
大家好,我是小米,前几天,一个朋友跑来找我吐槽:“公司搞了个 AI 知识库,刚上线时聪明得像个博士,现在回答问题越来越像实习生。”,我一听就乐了,这不就是典型的“记忆管理混乱症”吗?
如果把大模型比作一个学霸,那么向量数据库就是它的大脑记忆库,学霸再聪明,如果图书馆管理得乱七八糟,找资料也得翻半天。
而今天要介绍的 Couchbase Vector Search,就像一个拥有超大仓库、智能导航、全文检索和实时更新能力的超级图书馆管理员,SpringAI 已经为我们集成好了 Couchbase 向量数据库,让开发 AI 应用变得异常简单。
今天我们就通过一个有趣的故事,把它彻底讲明白。
假设有一家全国连锁图书馆,每天都有海量新书入库,用户既可能通过书名查找,也可能描述内容查找:那本讲微服务架构的书在哪?或者有没有讲 SpringAI 与向量数据库结合的资料?
传统数据库更擅长“书名匹配”,而 AI 场景需要的是“内容理解”,这时候就需要向量数据库,Couchbase 在原有 NoSQL 能力基础上增加了 Vector Search 能力,可以同时存储业务数据和向量数据,因此:
不需要额外部署独立向量库
不需要维护数据同步
可以统一查询接口
对于企业级 AI 系统来说非常方便。
Couchbase 向量数据库支持以下核心能力:

可以把它理解成:一家既能按书名找书,又能按内容找书,还能全国联网同步的超级图书馆。
1. 分布式向量存储
传统向量库可能是一台服务器,而 Couchbase 是分布式架构,例如:
北京节点
上海节点
深圳节点
共同维护一个知识库,即使某个节点故障,服务依然可用。
优点:
高可用
水平扩容
海量数据存储
2. 全文搜索
很多企业知识库都有一个痛点。用户输入:SpringAI 向量存储,既希望匹配关键词,又希望理解语义。
Couchbase 支持:
Full Text Search
Vector Search
两种能力结合,相当于,既查书名目录,又查书籍内容,精准度大幅提升。
3. 多维扩展
现代 Embedding 模型维度越来越高,例如:
768维
1024维
1536维
3072维
Couchbase 可以轻松支持高维向量存储,因此非常适合:
OpenAI
Gemini
Claude
SpringAI Embedding
生成的向量数据。
4. 实时操作
很多系统要求文档上传后立即可查,例如:
客服知识库。
运维文档中心。
企业内部 Wiki。
Couchbase 支持实时写入和快速检索,新数据可以迅速参与搜索。
接下来看看 SpringAI 如何集成 Couchbase。
1. Maven 基本设置
2. Couchbase 向量数据库配置
application.yml


3. 用法代码

SpringAI 自动完成实例化,开发者直接使用即可。
图书馆建好了,接下来开始存书和找书。
1. 向量存储代码

执行后,SpringAI 自动:
调用 Embedding 模型
生成向量
写入 Couchbase
整个过程开发者几乎无感知。
2. 相似性搜索代码
用户提问:什么是语义搜索?

返回最相似的文档,实现原理:

非常适合:
RAG
企业知识库
智能客服
AI问答
3. 全文搜索集成代码

结合 Couchbase Full Text Search 后,既能匹配关键词,又能匹配语义,搜索效果更好。
大型生产环境通常还需要高级配置。
1. 自定义索引配置代码

该配置用于创建向量搜索索引。
2. Bucket 配置代码

关键参数:
RAM 配额
副本数
Flush 开关
这些直接影响性能与可靠性。
3. 监控配置
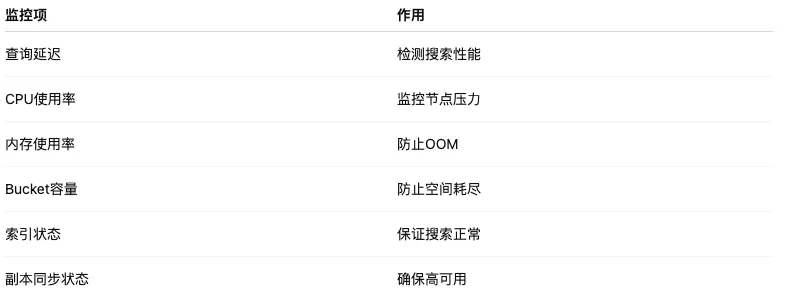
生产环境建议接入:
Prometheus
Grafana
Spring Boot Actuator
形成完整监控体系。
我曾经见过一个项目,上线第一天搜索速度飞快,三个月后搜索速度慢得像蜗牛,最后发现什么都往一个节点塞,索引也从不优化,所以使用 Couchbase 时建议遵循以下原则。
1、集群设计
合理规划节点角色,建议:
Data Node
Query Node
Search Node
职责分离,避免互相影响。
2、索引管理
定期检查:
索引数量
查询命中率
向量维度
避免无效索引占用资源。
3、内存管理
向量数据非常吃内存,建议:
设置合理 RAM 配额
控制缓存大小
监控内存增长趋势
4、复制
生产环境至少 Replica = 2,这样节点故障时依然能够服务。
5、监控
重点关注:
查询耗时
Bucket容量
Search延迟
节点健康状态
提前发现问题。
下面是项目里最常见的问题。
1、连接问题
验证连接字符串
couchbase://localhost
检查:
IP
端口
DNS
是否正确。
2、检查集群状态
登录 Couchbase Dashboard。
确认:
节点在线
Bucket正常
3、查看身份验证
确认:
用户名
密码
权限
配置正确。
4、性能问题
优化索引配置:过多索引会拖慢写入,过少索引会拖慢查询,需要平衡。
调整内存配额:向量搜索对内存要求较高,适当增加 RAM。
查看查询模式:排查、是否全表扫描、是否返回过多结果、是否频繁重建索引。
5、存储问题
监控 Bucket 使用情况:容量接近上限时及时扩容。
配置清理策略:历史向量数据定期归档,避免无限增长。
查看保留策略:明确保存多久、删除规则、数据生命周期,降低存储成本。
如果说 Redis 像一个超快的记事本,那么 Couchbase 更像一座全国联网的超级智慧图书馆,它不仅能存储海量向量数据,还天然具备分布式、高可用、全文搜索以及实时更新能力。
在 SpringAI 体系下,我们几乎只需要几行配置,就能把:
Embedding
向量存储
语义检索
全文搜索
RAG知识库
完整串联起来。
对于企业级 AI 应用来说,Couchbase 最大的价值并不是“能存向量”,而是把业务数据和 AI 数据放在同一个平台统一管理。
当你的知识库规模从几千条增长到几亿条时,你会发现,一个既懂数据库、又懂搜索、还懂向量检索的“超级图书馆管理员”,究竟有多重要。
好朋友们,我们下篇见~
