 夜雨聆风
夜雨聆风一句话结论:
AI 写代码已经从"尝鲜"进入"主力生产"阶段——Google 自称 75% 的新代码由 AI 生成;但"机器写得更快"并不自动等于"项目交付得更好",这条鸿沟才是 2026 年最值得讲的故事。 更要紧的是分清场景:小型项目的 0-1 开发,AI Coding 已经完全没问题;但很多人误以为这种能力可以原样平移到大型企业系统——这是个危险的误解。面对大型企业的存量系统,AI Coding 目前还做不到自助(自治)完成,即便有 harness engineering(工程化脚手架)加持,依然困难重重。
一、大厂的"AI 代码采纳率":数字很猛,口径要小心
过去 18 个月,几家头部公司的 CEO 接连在财报或开发者大会上抛出 AI 代码占比数字,构成了一条陡峭的上升曲线。
Google:25% → 50% → 75%,18 个月翻三倍
- 2024 年 10 月(Q3 2024 财报电话会):Sundar Pichai 首次公开口径——"今天 Google 超过四分之一(>25%)的新代码由 AI 生成,再由工程师审查并接受",并强调"这帮助工程师做得更多、跑得更快"。(TechRadar、Futurism)
- 2025 年秋:该比例升至约 50%。
- 2026 年 4 月 22 日(Google Cloud Next 2026,博客公告):Pichai 宣布"今天 Google 75% 的新代码由 AI 生成并经工程师批准,高于去年秋天的 50%",同时表示团队"正转向真正的智能体(agentic)工作流,工程师在编排完全自治的数字任务队列",并举例一次复杂代码迁移"比一年前快了 6 倍"。(Fast Company、DevOps.com)
📈图 1 Google 新代码 AI 生成占比的陡峭曲线(2024–2026)

Microsoft:20–30%,但 CEO 用词很谨慎
- 2025 年 4 月(LlamaCon):Satya Nadella 在被 Zuckerberg 追问时回答——"我会说,可能 20%、30% 的代码……在我们的仓库里、某些项目里,大概都是软件写的"。他特别补充:Python 进展更好、C++ 更难;AI 更擅长写新代码而非改旧代码;这个比例可能升向 40%。(TechCrunch、CNBC)
- Microsoft CTO Kevin Scott 更激进地预测:到 2030 年 95% 的代码将由 AI 生成。
- 工具侧,GitHub Copilot 累计用户已超 2000 万(2025 年 7 月,较 4 月的 1500 万三个月增长 500 万),并被 90% 的财富 100 强采用,企业客户环比增长约 75%。(TechCrunch、Dataconomy)
Amazon:不谈"占比",谈"省了多少人年"
Andy Jassy 的口径很务实——不报代码百分比,而报工程成果:用 GenAI 助手 Amazon Q 做 Java 17 升级,平均耗时从约 50 个开发者-日降到几小时,累计相当于节省 4500 个开发者-年的工作量、约 2.6 亿美元的年化效率收益;其中 79% 的 AI 代码评审无需额外改动即可上线。(Slashdot、About Amazon)
Meta:还在"打赌"阶段
- 2025 年 4 月(LlamaCon):Zuckerberg 坦言不知道确切数字,但"我们的赌注是,明年大概……也许一半的开发会由 AI 而非人来完成,然后从那里继续往上走"。(TechCrunch)
行业大盘
- Gartner 预测:到 2028 年,75% 的企业软件工程师将使用 AI 代码助手,而 2023 年初这一比例不足 10%;2023 年第三季度已有 63% 的组织在试点或部署。(注意这是分析师预测,非已观测事实)(Gartner)
- DORA 研究:2024 年 75.9% 的开发者已将 AI 用于至少一项日常任务、约 75% 报告生产力提升;2025 年使用率升至约 90%、超过 80% 报告生产力提升。(DORA 2024、RedMonk 对 DORA 2025 的解读)
- Bain 2025:三分之二的软件企业已上线 GenAI 工具,但开发者实际使用率偏低——"部署了"不等于"用起来了"。(Bain)
⚠️关键提醒:这些百分比不能照单全收。 业界没有统一的"AI 生成代码占比"测量口径——是按字符、行数、commit,还是按"由 AI 起草后人工修改"算?连 Nadella 本人都用了"可能""大概"这样的措辞。更关键的是,所有这些数字都回避了一个指标:拒绝率/返工率——AI 生成的代码在上线前被重写了多少?这比"75%"这个头条数字更能反映 AI 编码的真实成熟度。把"采纳率"当作"价值"的代理指标,是当下最常见的误读。
二、效率实践:任务变快了,交付却未必变好
这是整篇调研里最重要、也最反直觉的发现。把不同研究横向摆在一起,会看到一个清晰的张力——单个编码任务的提速是真的,但它没有线性地传导到项目交付层面。
🔻图 2 提速为何在传导中层层衰减

受控实验:任务级提速显著,但极不均衡
- McKinsey 实验室研究(2023,40+ 名美/亚开发者,对照实验设计):在隔离的编码任务上,AI 最高可让任务提速近一倍。但:高复杂度任务的时间节省不足 10%;对越复杂的任务、越缺乏经验的开发者,增益越低。(McKinsey)
- 口径提醒:这是 McKinsey 研究自家员工、自报数据、且是隔离实验任务而非真实代码库。流传甚广的"文档提速 45–50%、生成 35–45%、重构 20–30%"以及"整体快一倍"这类拆分,在本次核查中未通过验证,不建议引用。
- 田野研究给出相反信号:在真实生产环境(Cui et al. 2024,微软/埃森哲)中,开发者任务量增加约 26%,且 AI 对低活跃度/初级开发者帮助更大——与 McKinsey 实验室"对初级帮助小"的结论恰好相反。这个矛盾本身就是重要洞察(见第三部分)。
警示性反例:资深开发者反而变慢了
METR 2025 随机对照实验(RCT)是迄今设计最严谨的反例:16 名资深开源开发者、246 个真实任务、在他们熟悉的成熟代码库上,使用 2025 年初的 AI 工具(Cursor Pro + Claude 3.5/3.7),结果任务完成时间增加了 19%(即变慢)。更扎心的是巨大的感知偏差:他们事前预估能提速 24%、事后仍以为提速了 20%,而实测是慢了 19%。(METR)
范围限定:此结论仅适用于"资深开发者 + 熟悉的成熟代码库 + 早期 2025 工具",不可外推到所有人群和场景。但它戳破了一个幻觉:开发者对 AI 提效的主观感受可能系统性地高于客观事实。
交付指标:DORA 连续两年发现"AI 与交付变差相关"
如果说任务级数据还算乐观,交付级数据则泼了冷水:
- DORA 2024:连续第二年发现,AI 采纳与软件交付性能恶化相关(前置时间、吞吐量、变更稳定性下降)。量化估计:每增加 25% 的 AI 采纳,约对应吞吐量 -1.5%、交付稳定性 -7.2%,但个人生产力 +2.1%、工作满意度 +2.6%。其机制被归因为 AI 增大了变更批量(batch size)。(DORA 2024)
- DORA 2025(部分反转):AI 采纳与交付吞吐量、产品性能转为正相关(逆转上一年),但与交付稳定性仍为负相关。结论凝练为一句话——决定交付成败的是"稳定性而非速度",而不稳定性是横跨 2024–2025 的持续短板。(RedMonk 解读,底层为 Google/DORA 官方报告)
ROI:50% 的提速,为什么只换来 ~10% 的周期改善?
Gartner 一针见血地点出任务级与交付级的换算关系:供应商常宣称"编码提速最高 50%",但编码只占软件全生命周期约 20% 的时间——50% × 20% ≈ 整体周期仅改善约 10%。这也解释了为何只有 34% 的 CIO/技术领导认为 AI 编码工具是"游戏规则改变者"。Gartner 同时警告:AI 代码助手的价值难以量化,传统的"降本"ROI 框架无法捕捉其全部价值。(Gartner)
三、洞察与趋势:从"发工具"到"重构流程"
把上述数据连起来看,2026 年 AI Coding 的真实图景可以提炼为五条洞察。
洞察一:单纯"发工具"不见效,价值来自重构研发流程
McKinsey 与 Bain 两家独立得出一致结论:给开发者发个 AI 助手并不会自动产生效益。 真正的回报来自把 AI 嵌入完整软件生命周期(需求—规划—设计—编码—测试—部署—运维—维护),并重新设计流程、把省下的时间再投入到高价值工作。Bain 补充了一个常被忽视的事实:代码生成只占"从想法到上线"全过程约 25–35% 的时间——只优化这一段,天花板有限。(McKinsey、Bain)
这也印证了为什么 Amazon 的故事(Q 做大规模代码迁移、Google 的"6 倍速代码迁移")比"代码占比"更有说服力——它们优化的是端到端的工作流,而不只是"打字速度"。
洞察二:差距在拉大——头部玩家吃到了真正的红利
McKinsey 调研约 300 家上市公司高管发现,处于前 20% 分位的"顶级表现者"在生产力、上市时间、客户体验上获得 16–30% 的提升、在软件质量上获得 31–45% 的提升。AI 不是平均地抬升所有人,而是放大了组织能力的差距:会用的人和会用的公司,正在把不会用的甩开。(McKinsey)
洞察三:瓶颈正在"转移",而非"消失"
DORA 的稳定性下降给出了机制性解释:当 AI 让"写代码"这一环节大幅加速,更多、更大的变更涌入下游,瓶颈就从编码转移到了代码评审、测试、部署和运维。如果评审和质量门禁跟不上,速度的提升会以稳定性的下降为代价。这意味着 2026 年的提效重点,正从"让 AI 写得更快"转向"让评审、测试、CI/CD 跟得上 AI 的产能"。
洞察四:初级 vs 资深的悖论,决定了推广与培训策略
实验室研究说"AI 对初级帮助小",田野研究和 METR 却显示"AI 对低活跃/初级开发者接受率更高,对资深开发者在熟悉代码库上甚至拖慢"。这个看似矛盾的现象其实指向同一件事:AI 最擅长填补"知识/样板"的空白,最不擅长替代"深度上下文与判断"。 对企业的含义是——AI 工具的推广和培训不能"一刀切",要按人群(初级/资深)和场景(新项目/成熟代码库)差异化设计,并警惕开发者的"提速错觉"。
洞察五:下一站是 Agentic(智能体)工作流
无论是 Google 宣称的"编排自治数字任务队列",还是 McKinsey 提出的四级成熟度框架,方向高度一致:
级别 | 形态 | 说明 |
L1 | 无 GenAI | 传统人工编码 |
L2 | 加速单个任务 | 当下大多数团队所处阶段(Copilot 式补全/问答) |
L3 | 自动化整个工作流步骤 | AI 接管某个完整环节 |
L4 | 智能体团队端到端交付 | AI 智能体团队端到端交付整个应用,仅在真正需要人类判断处上报 |
(来源:McKinsey)
🪜图 4 AI 软件开发成熟度阶梯(多数组织仍在 L2)

绝大多数组织今天仍停留在 L2。从 L2 跨到 L3/L4,要解决的恰恰是第三条洞察里的"下游瓶颈"——评审、测试、可观测性和质量保障的自动化,将成为智能体规模化落地的前提。Robinhood 等公司已宣称"多数新代码由 AI 编写、工程师接近 100% 采用",是 L3 早期信号;但 McKinsey State of AI 2025 也显示,真正"规模化 AI 智能体"的企业仍不足 10%——理想与现实之间,路还很长。
四、仍未解决的挑战:为什么"存量大系统"最难提效
前面的乐观数字大多来自新代码、新项目、隔离任务。一旦把镜头转向真实世界里占绝大多数的大型存量工程系统,AI Coding 立刻撞上几堵尚未推倒的墙。
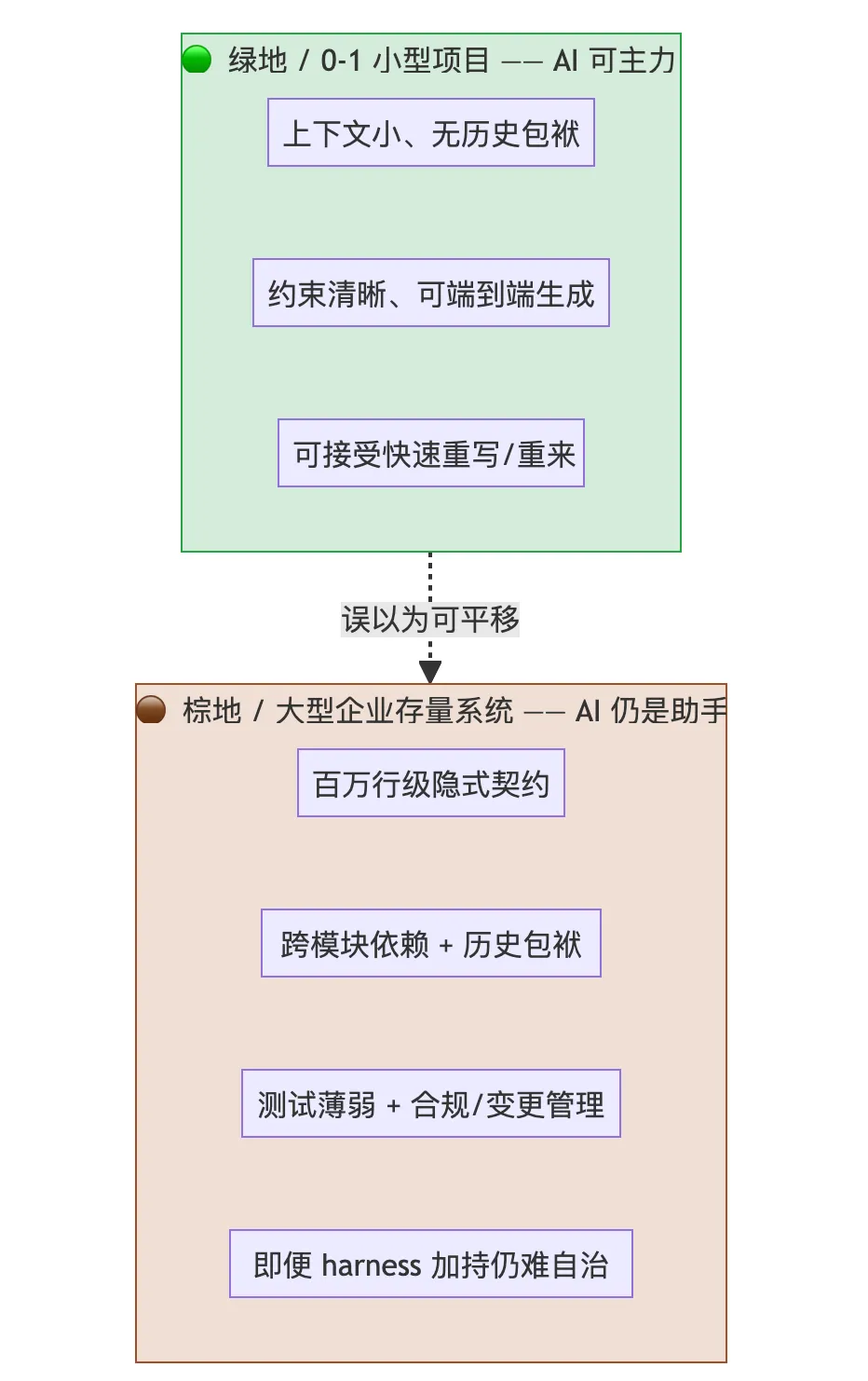
💡必须先分清的场景边界——这是全文最想纠正的一个误解:
- 小型项目 / 0-1 绿地开发:AI Coding 已经完全没问题。 上下文小、无历史包袱、约束清晰,模型甚至能端到端起一个能跑的应用——大厂"75% 新代码""明年一半开发由 AI 完成"的乐观,大多成立在这个语境里。
- 大型企业存量系统:AI Coding 目前还做不到自助(自治)完成。 很多人把前者的成功直接外推到后者,这是危险的误解。存量大系统的难点不在"写",而在理解百万行级的隐式契约、跨模块依赖、历史包袱和合规约束——即便有 harness engineering(为 AI 搭建的工程化脚手架:上下文检索、工具链、测试沙箱、多智能体编排、人在环审查)加持,依然困难重重。 Harness 能放大 AI 的有效性、推高上限,但还不足以让它在棕地系统里"无人值守"地交付。
换句话说:AI Coding 在绿地是"主力",在棕地仍是"高级助手"。 下面五项挑战,正是这道边界背后的结构性原因。
🟢🟤图 3 绿地 vs 棕地:AI Coding 能力的分水岭
挑战一:准确率与"长上下文"——大型代码库是 AI 的弱区
大厂高管的口径里藏着诚实的限定词。Nadella 明确指出 AI "更擅长写新代码,而非修改旧代码",且不同语言差异明显——Python 进展好、C++ 更难(TechCrunch)。METR 的 RCT 更是直接量化了这堵墙:在开发者熟悉的成熟代码库上,早期 2025 工具让资深开发者慢了 19%(METR)。
机制不难理解:大型系统的复杂度不在"写一段函数",而在跨模块的隐式约定、历史包袱、长链路依赖——这些上下文往往超出模型有效窗口、且大量存在于文档之外(在老工程师的脑子里)。AI 在缺乏全局上下文时会"自信地写错",而越大的系统,验证这种错误的成本越高。
挑战二:边界条件与"看似正确"——最危险的不是报错,是悄悄错
AI 生成代码的典型失效模式不是语法错误(这类容易被编译器/lint 抓住),而是边界条件、并发、错误处理、安全校验上的"静默缺陷"——主流程跑得通,偏偏在 null、空集合、超时、竞态、越权这些角落出问题。配合 METR 揭示的感知偏差(开发者以为提速 20%、实际慢 19%),风险被进一步放大:人会倾向于信任"读起来很顺"的 AI 代码,从而降低审查强度。这正是 DORA 交付稳定性持续为负的微观来源(DORA 2024)。
挑战三:自动化测试覆盖——产能上去了,"安全网"没跟上
AI 把"写代码"加速后,瓶颈转移到下游的评审与测试(见洞察三)。但存量系统恰恰是测试覆盖最薄弱的地方:缺乏单元/集成测试、依赖难以 mock、回归套件老旧。结果是——AI 用更大的批量(DORA 归因的 batch size 增大)往一张本就有破洞的安全网上扔进更多变更,稳定性自然下滑。讽刺的是,AI 最该先帮忙补的恰恰是测试本身(补齐测试覆盖、生成回归用例),但"为遗留系统补测试"又依赖对系统的深度理解——回到了挑战一。
挑战四:存量系统难以"全面"提效——天花板是结构性的
Bain 提醒,代码生成只占"从想法到上线"全过程约 25–35% 的时间(Bain);Gartner 的换算更直白——编码提速 50%,整体周期也只改善约 10%(Gartner)。在存量系统里,真正吃时间的是理解旧代码、协调依赖、回归验证、合规与变更管理,而这些正是 AI 目前最不擅长的环节。所以会出现一种割裂:绿地新项目(greenfield)提效明显,棕地存量系统(brownfield)提效有限——而企业的核心资产恰恰是后者。
挑战五:技术债与"提效幻觉"的长期账
短期"写得快"可能以长期技术债为代价:风格不一致、重复实现、缺乏抽象、文档缺失的 AI 代码,会在未来的维护中反噬。如果省下的时间没有被重新投入到重构、测试、文档等高价值工作(McKinsey/Bain 反复强调的前提),提效就只是把成本从"现在"挪到了"以后"。
还需要 AI 进一步解决的问题(2026 的开放议题)
- 超大上下文的可靠推理:如何让模型真正"读懂"百万行级代码库的全局约束,而非局部补全?
- 可验证性与自纠错:AI 能否对自己生成的代码主动生成测试、做形式化/属性化验证,把"静默缺陷"变成"显式失败"?
- 存量系统的自动化理解:能否自动重建遗留系统的领域模型、依赖图与隐式契约,降低 brownfield 的改造门槛?
- 稳定性导向的 Agentic 流程:智能体不仅要会写,还要会评审、会回归、会灰度——把 DORA 的稳定性短板补上,才谈得上 L3/L4 规模化。
- 统一的度量口径:在"代码占比"之外,建立包含返工率、缺陷逃逸率、交付稳定性的可信评估体系。
未来仍有不确定性。 AI Coding 的曲线很陡,但它究竟是会突破"存量大系统"这道墙、走向真正的端到端自治,还是会在某个能力平台期长期停留于"高级辅助",目前没有定论。可以确定的是:谁先解决了准确率、边界条件和测试覆盖这三件事,谁才真正握住了把"采纳率"兑换成"交付力"的钥匙。
五、给读者的实践建议
- 别把"采纳率/代码占比"当 KPI。 它衡量的是投入而非产出。要盯交付级指标(DORA 四项:前置时间、部署频率、变更失败率、恢复时间),尤其是稳定性。
- 把 AI 嵌进流程,而不是发给个人。 ROI 来自端到端重构(评审、测试、CI/CD、文档),而非单点的"打字加速"。
- 差异化推广。 对初级开发者侧重"补能力短板",对资深开发者侧重"减重复劳动",并在成熟代码库场景下谨慎评估真实收益。
- 建立质量门禁,迎接下游洪峰。 AI 提高了上游产能,必须同步加固评审与测试,否则稳定性会先崩。
- 关注 Agentic 工作流。 从 L2(辅助补全)向 L3(自动化环节)演进,提前布局可观测性与自动化质检。
六、落地时间建议:分阶段推进,别想一步到位
提效不是开关,而是分阶段爬坡。结合前文的能力边界与瓶颈规律,给出一个务实的时间节奏(具体周期按团队规模和系统复杂度可伸缩)。
🗓️图 5 AI Coding 落地路线图(建议节奏)
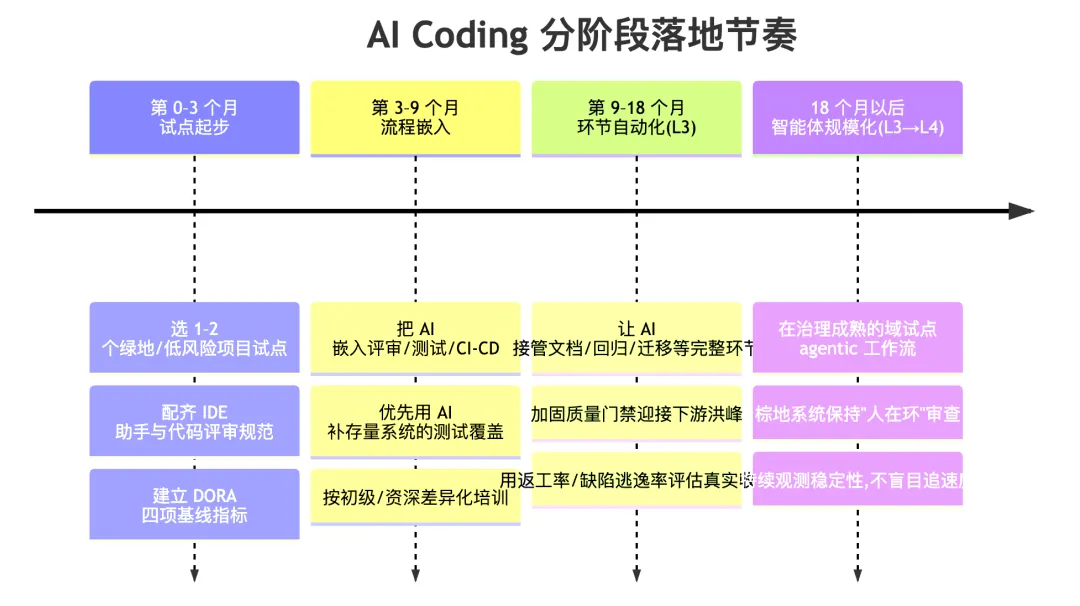
配套的时间原则:
- 先绿地、后棕地(0–3 个月)。 用低风险的 0-1 项目快速建立信心与规范,不要一上来就拿核心存量系统练手。
- 先补安全网、再加产能(3–9 个月)。 在放大 AI 产能之前,先用 AI 把存量系统的测试覆盖补起来——否则速度越快、稳定性塌得越快。
- 给"重新投入"留时间(全程)。 McKinsey/Bain 反复强调:省下的时间必须有意识地导向重构、测试、文档,否则提效只是把成本挪到未来。这一步不会自动发生,要写进流程。
- 用 3–6 个月观察窗口校验感知偏差。 鉴于 METR 揭示的"提速错觉",任何阶段的收益都应以客观交付指标(而非开发者主观感受)滚动验证后,再决定是否扩大范围。
- 棕地自治不设硬性时间表。 大型存量系统的"无人值守交付"目前没有可靠时间承诺——按能力成熟度推进,而非按 deadline 倒逼,保持人在环。
数据可靠性与口径说明
- 时间标注:本文数据跨 2023–2026。McKinsey 实验室研究(2023)、Gartner(2024)、DORA 2024 相对偏旧;DORA 2025、Bain 2025、Google 2026/4 公告、Microsoft/Meta 2025/4 表态较新,已分别标注。
- 预测 vs 事实:Gartner 的"2028 年 75%"、Kevin Scott 的"2030 年 95%"、Zuckerberg 的"明年一半"均为预测/打赌,非已观测事实。
- 来源利益相关:McKinsey、Bain 售卖转型咨询服务;各大厂 CEO 的代码占比表态带有自我宣传性质,且缺乏统一测量口径与返工率披露;DORA、METR 相对中立。
- 核查中被否决、不予引用的数据:McKinsey 的 45–50% / 35–45% / 20–30% 任务拆分、"整体提速一倍"作为普适结论、Bain 的 10–15% 与 25–30% 具体百分比——均未通过对抗式验证。
- 范围限定:METR 的 -19% 仅适用于"资深开发者 + 熟悉的成熟代码库 + 早期 2025 工具",切勿外推。
主要来源
- Google / Sundar Pichai:Fast Company(75%, 2026/4)、DevOps.com、TechRadar(>25%, 2024/10)、Futurism
- Microsoft / Satya Nadella:TechCrunch(20–30%)、CNBC
- GitHub Copilot:TechCrunch(20M 用户)、Dataconomy
- Amazon / Andy Jassy:Slashdot(4500 人年)、About Amazon
- Gartner:2028 年 75% 预测新闻稿
- DORA:2024 报告、RedMonk 对 2025 报告的解读
- McKinsey:Unleashing developer productivity(2023 实验室研究)、The AI revolution in software development(四级框架 / 顶级表现者)
- Bain:From pilots to payoff(2025 技术报告)
- METR:早期 2025 AI 工具对资深开源开发者的 RCT(-19%)
