 夜雨聆风
夜雨聆风
如果 AI 只是生成更多东西,却把判断、返工和风险留给用户,那它只是包装。
AI 生成了结果,责任留给了用户
2023 年 6 月,两名叫 Schwartz 和 LoDuca 的美国律师干了一件后来被全球法律行业记了很久的事。案件叫做 Mata v. Avianca。
他们用 ChatGPT 生成了一份诉讼文件,提交给了曼哈顿联邦法院。法官 Kevin Castel 发现文件里引用了六个判例——全部不存在。格式正确、案号合理、当事人名字都没问题,但每个都是捏造的。法官罚了两人和律所五千美元,还要求他们把判决通知到六个被虚构出来的法官。那些名字对应的法官,有些早已退休或去世。
后续报道翻来覆去地讨论"AI 出错"。出错不是这个故事最深的地方。
深的地方在于:AI 没有提交任何东西,律师提交的。AI 没有核查义务,律师有。但律师没查。不是来不及查。是 AI 产出得太流畅、太像真的、太有格式感,人本能地松了手,觉得"应该没问题"。
责任没有消失,它只是从一个生成工具的手里滑到了用户手里。而用户没有意识到自己接住了什么。
这就是判断债务。
AI 让人生成得更快了,然后把判断、核查、引用真实性、合规风险和后果,全部留给了人。
生成越快,判断越贵

为什么生成能力提高了,判断负担不但没有消失,反而更重了?
这件事背后有一个简单的机制。过去产出少,一个人亲自写、亲自算、亲自查,他知道自己做了什么。现在产量翻了十倍,他查不过来。查不过来就只有两条路。要么不查,错了也不知道。要么更累,比没有 AI 的时候还多了一道"看对不对"的工序。
AI 把生成价格打了下来,但没有动过判断价格。判断还是得由人来下,而且产出越多,需要判断的总量越大。这就像一个工厂把产量提升了一百倍,但质检还是靠一个人站在产线末端用手摸——摸不过来的东西,要么漏过去,要么把人累死。
GitHub Copilot 是个能把这个机制说清楚的例子。
Microsoft Research 的研究确认了 Copilot 让开发者完成任务更快。但 2025 到 2026 年期间,陆续有多项研究开始盯着另一面:AI 生成代码越多,维护阶段需要人工审、改、排查、补安全的量就越大。有人用了一个词——"verification debt"(行业内也将这种事后核查负担称作"验证债务",本质和本文所说的判断债务指向同一问题)。生成加速之后,验证积压如果不被处理,成本只是从开发阶段移到了维护阶段。开发者从写代码的人变成了审代码的人。
不是 Copilot 不好。是 AI 再强,判断债务不会自动消失。不在流程里设计检查点,它只是从一个人手里换到了另一个人手里。
对一人公司来说,这个机制更致命。
大公司可以在流程里摊开责任:生成在 AI 层,初审在初级员工,复审在主管,终审在法务。一家小团队没有这些层级。创始人自己做客服,自己做审核,自己发版本,自己接客户电话。AI 输出的风险没有层层缓冲,直接砸在一个人身上。
2026 年初有一篇被广泛引用的研究报告抛出一个数字:91% 的 AI 用户不核查 AI 的输出。这个数字背后不是用户懒。是生成量太大了,大到人已经没法一一核查。判断债务堆积的速度,超过了任何一个人的判断产能。
好的 AI 要知道什么时候不回答
这个方向上,有一批做客服 AI 的公司选了另一种做法,值得拆开看。
它们不把"能自动回复"当卖点了。卖点是:AI 处理自己能接住的问题,剩下的自动升级到人。
这不是简单的"兜底"。升级的时候,AI 要带上对话历史、已经尝试过的方案、用户的情绪标记和当前置信度。人接到的时候不用重新了解上下文,一键就能接手。
这个设计里藏着一个关键的取舍:故意不做全能。
传统 AI 产品的思路是提升正确率,尽量少让人介入。这批产品反过来。它们把"什么时候不回答"当成一级功能来设计。低置信度不硬答。涉及退款不硬答。用户情绪激动不硬答。没有足够来源支撑不硬答。每一个"不回答"背后,是一个被明确标注的判断边界。
结果是什么?人的工作量真正降低了。
不是因为他收到的对话变少了。是因为他不需要在一堆 AI 回复里挑哪些没处理好。AI 已经把"我能接的"和"需要你看的"分开了。判断职责是清晰的。
这才是 AI 杠杆。
不是 AI 做了更多事。是 AI 做了它能做的事,然后把需要人判断的地方清楚地交还给人,附带所有上下文和边界信息。用户的工作量没有增加,他的判断负担没有变重。
回到一人公司的产品语境里,这个杠杆长什么样?
不是在大产品里加一个升级系统。是更小的事。AI 生成了一段方案,旁边有一颗灰色小字写着"这一段基于过往偏好生成,如果要改方案方向,建议先跟客户确认"。另一个地方写着"以下数据来源是上次导入的表格,如果有更新需要重新上传"。一段分析旁边有个标识说"这条判断没有足够历史数据支撑,仅作参考"。
这都是不贵的东西。它们是产品里的责任设计。
AI 放在产品里的位置,决定它是不是杠杆
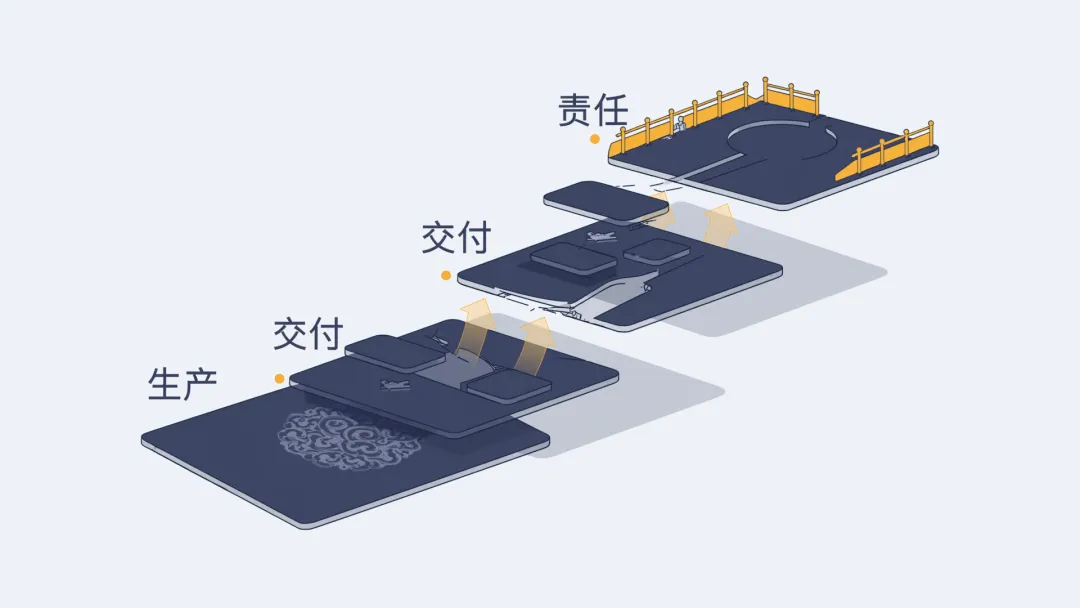
拆开看,AI 在一个产品里可能落在五个不同的位置。不是所有位置都能形成杠杆。从低到高。
第一层,生产层。AI 只做一件事:让创始人做得更快。它帮你写、帮你想、帮你查、帮你搭。用户看不见。用户也不为它付费。它只是把一个人的产能撑得像个团队。
很多独立开发者在这一层卡了很久。自己写文章快了一倍,以为产品价值也涨了一倍。自己搭落地页快了五倍,以为转化率也该涨。自己回复邮件像流水线,以为用户问题已被解决。解决的是创始人的问题,不是用户的问题。
第二层,交付层。AI 开始进入用户可见的交付链条,降低每多服务一个用户的边际成本。自动生成初版、自动整理方案、自动处理常见咨询。创始人能接更多单而不崩溃。
但交付层有一个陷阱:量大不等于质稳。交付成本降了,用户仍然要自己判断哪一版能用、哪一段需要人工改。他拿到的东西多了,判断任务也多了。交付杠杆如果不带着判断杠杆,就是在用更快速度堆积判断债务。
第三层,结算层。这一层已经在变用户为什么付钱。从卖工具变成卖结果。从卖时间变成卖省心。用户不再为一个 AI 功能按钮付费,而是为"这件事已被做完,我能直接用"付费。
第四层,责任层。产品不承诺零错误,不包揽一切风险。但它清楚告诉用户:哪里可靠、哪里需要你自己看、哪里出过类似问题、哪段有来源、哪个建议是低置信度、哪种情况可以转人工。不是夸口说"我都帮你做了",而是坦率说"这几段我确认过,那几段你看一眼,最后这个判断需要你决定"。
第五层,装饰层。聊天框、生成按钮、智能标签、流式输出,看上去很强,但用户真正要做的事没有变轻。判断还在他手里。确认还是得他自己做。他只是多了一个看起来很厉害的入口,里面没有接住任何东西。AI 在这里是包装,不是杠杆。
一个很容易对号入座的例子:AI 文案工具一键生成推广文案,但不标注适用场景、风险话术或合规边界。用户拿到文案之后要自己判断能不能投、会不会踩雷、哪一句太满哪一句不够。生成很快,判断全留给了用户——这就是典型的交付层陷阱加判断债务转嫁。
从一个减轻负担的小改动开始
不需要重做产品,不需要加一套合规系统。
把产品最近一次 AI 的输出拿出来。一段文案、一份报告、一串代码,还是一个自动生成的方案。把它摊开在面前。写五句话。不是技术分析,是你作为这个产品的用户,拿到输出之后要做的事:
我还要查什么? 我还要改哪里? 我敢不敢直接发给客户? 如果错了,我找谁? 哪一句话最让我不放心?
把这些答案按现实写下来。
然后在里面只选一个点。一个就够了。
如果用户不放心数据来源,补一行小字注明数据从哪里来的、什么时候导入的。如果用户不敢直接发给客户,补一段说明:"这几段可以直接用,这一段语气偏保守,如果你的客户偏好更直接,建议改一下开头那两句话。"如果用户不知道 AI 有没有把握,补一个置信度标识,哪怕只是"高把握 / 中等 / 不确定"三级。如果用户怕错,补一个一键转审的入口。
只做这一个点。然后观察一次用户在使用中是否少了一步确认动作。
反过来看。如果你加完所有 AI 功能之后,回到产品主路径上走一遍,发现每一点都是生成一堆东西,然后把判断义务原封不动抛给用户——那就不是杠杆。是加速把用户推到不敢用的位置。
出现这个情况,不要继续加功能。先退回去。在用户判断压力最大的地方,放一个接应。
最后看用户少没少操心
判断一个产品的 AI 杠杆,不用看它用了什么模型,也不用看它的功能列表。
就看一件事:用户付了钱之后,他还要为多少东西操心。
把这个数字压下来,才是杠杆。
好的 AI 产品,是帮人减少操心,而非制造新的审查负担。
