 夜雨聆风
夜雨聆风


小东
学历背景:南京大学建筑学研究生
写在前面

产品图
这段时间在找工作,于是我的产品【一间属于自己的房间】差不多跑起来了。
很难讲这两件事之间有什么必然联系。按常理说,一个人找工作的时候应该认真投简历、改简历、背八股、练面试,而不是突然打开电脑开始做一个文学阅读器。但人类的行为本来也不太服从常理,尤其是我。越是有正事要做,越容易把别的事情做得飞快。
准确说,代码项目名还叫 woolf-room。这个名字听起来像一个后端仓库,对外我还是想叫它《一间属于自己的房间》。名字有点长,不像一个互联网产品,互联网产品最好两个字,三个字也行,四个字就显得产品经理没有受过 KPI 的毒打。
但我很喜欢这个名字。
它不是一个“帮你三分钟读完名著”的工具,也不是一个“帮你把文学总结成思维导图”的 AI 阅读器。事实上我非常害怕三分钟读完名著这种说法。一个人如果真的三分钟读完了伍尔夫,那他读完的很可能不是伍尔夫,是短视频知识博主的选题文案。
我想做的东西更小一点。
你可以把它理解成一个文学阅读房间:把书放进去,慢慢读。读到不懂的地方,可以问。读到有感触的段落,可以留下。AI 不会跳出来说“亲爱的读者,让我们一起探索意识流的奥秘”,也不会把一整章总结成三个知识点。它最好只是坐在旁边,在你需要的时候说两句,不需要的时候闭嘴。
听起来好像也不复杂。
但这段时间做下来,我最大的感受是:一个 AI 产品从“能回答问题”到“像是真的进入了某个场景”,中间隔着很多细小、琐碎、看起来不值一提,但一旦做不好就会让人立刻想关掉页面的东西。

为什么要做这个项目?
我喜欢读书。
这句话写出来很像简历里的“兴趣爱好”栏,下一句就该写“热爱运动,性格开朗,有团队协作精神”。但事实确实如此——我喜欢读书,尤其喜欢那些有点厚、有点不肯立刻交代自己到底在说什么的书。

喜欢归喜欢,读不下去也是常有的事。
有些书不是不好,而是太远。远在时代,远在某种早已消失的生活秩序。你知道它重要,也知道自己应该读,但读到第三页就开始走神。查一个词,顺手点进百科;看一个背景,顺手点进知乎;再回来的时候,原文已经在屏幕上变成一片静止的黑字,像一个被你辜负的人。

图源网络,但当你打开《疯癫与文明》时,
会真切感受到阅读的痛苦
传统阅读器很安静,安静到近乎冷酷。
它会帮你翻页、做笔记、调字号、切夜间模式,但它不会理会你在某个句子前卡住。它只是一个容器,容器没有安慰你的义务。
AI 工具又太热情。你把一段话丢进去,它很快告诉你这段话体现了作者对于女性处境、社会结构、主体意识和现代性困境的深刻思考。每个词都对,但每句话都像论文摘要。
我不想要一个替我读书的东西。
我想要一个帮我继续读下去的东西。
Woolfroom 一开始想解决的就是这件事:当一个人真的在读一本书的时候,AI 能不能不要站在书外总结它,而是稍微坐近一点,在原文旁边帮他把那条路照亮一点。
只要亮一点,够他继续往前走。

谁该用 Woolfroom?
做了一阵之后,我意识到 Woolfroom 不是给所有读者的。
它不是给那种一年读两百本书、看完还会自动生成读书方法论的人用的。这种人已经不需要产品了,他们本人就是产品,甚至可能还会开知识星球。
它也不是给只想快速获取信息的人用的。快速获取信息有很多工具:搜索引擎、AI 总结、短视频、公众号,都可以。Woolfroom 在这件事上没有优势,也不想有优势。
它更适合三类人:
1.想读经典文本,但总是被卡住的人。
2.不想被 AI 总结毁掉阅读体验的人。
3.想要一个文学搭子,但不想要一个话痨的人。
我希望它像一个比较克制的朋友。你问,它回答。你不问,它别在旁边刷存在感。
它可以提醒你这里有一个时代背景,那里有一个修辞转折,这句话和前面某段有关系。但它不能每隔三行就跳出来说“我发现了一个深刻主题”。
没有必要时时刻刻互动。
我一开始也想做得很大
这是所有个人产品的通病。
一开始只是想做个阅读器,后来很快想到 AI 对话、作者人格、段落社区、个人书架、长期记忆、文学地图、学术推荐、阅读报告、章节测试、知识图谱、会员系统、后台管理、书签功能……
写需求的时候非常快乐。人类在 Notion 里规划未来时,总是显得格外有出息。

第一版只做三件事
第一,读书。
这听起来像废话。一个阅读产品当然要能读书,就像饭店当然要能吃饭。
但真实做起来才知道,越基础的事越不能糊弄。阅读器要能打开正文,章节要能切出来,段落要能稳定显示,阅读进度要能保存——用户下次回来要知道自己读到哪。这些东西没有任何炫技成分,发朋友圈也不会显得很酷,但它们一旦没有,产品就像一个装修很漂亮但没有门的房间。

第二,边读边问。
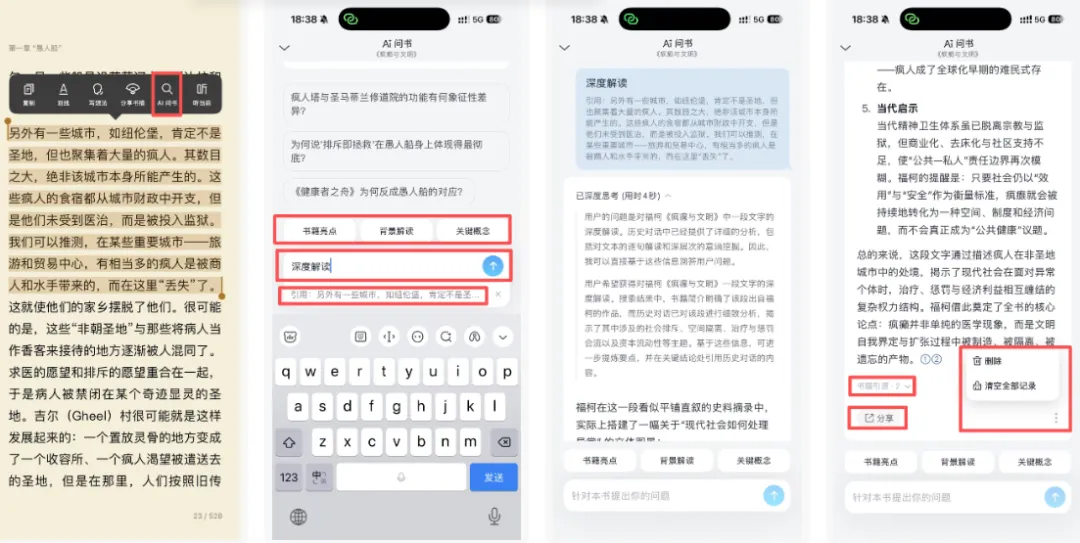
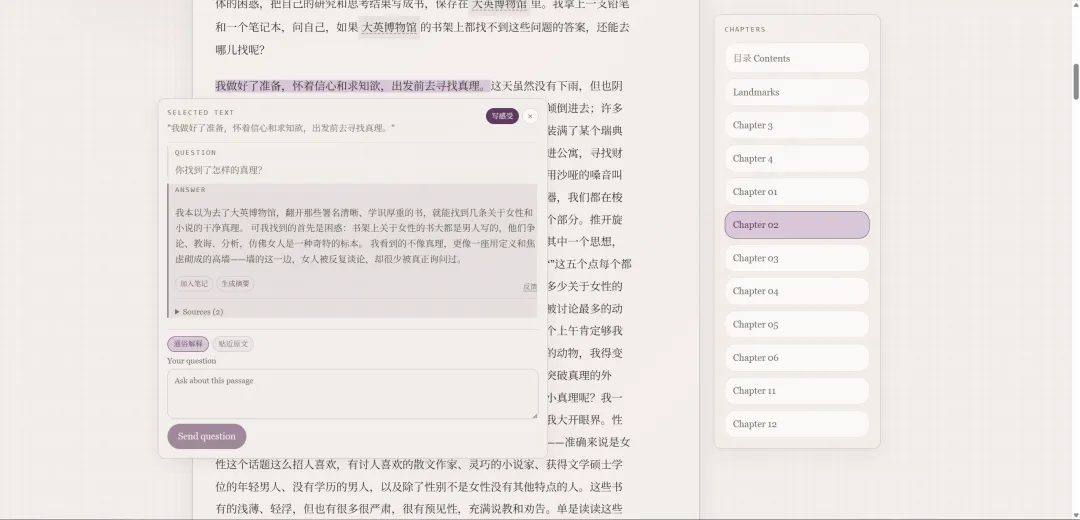
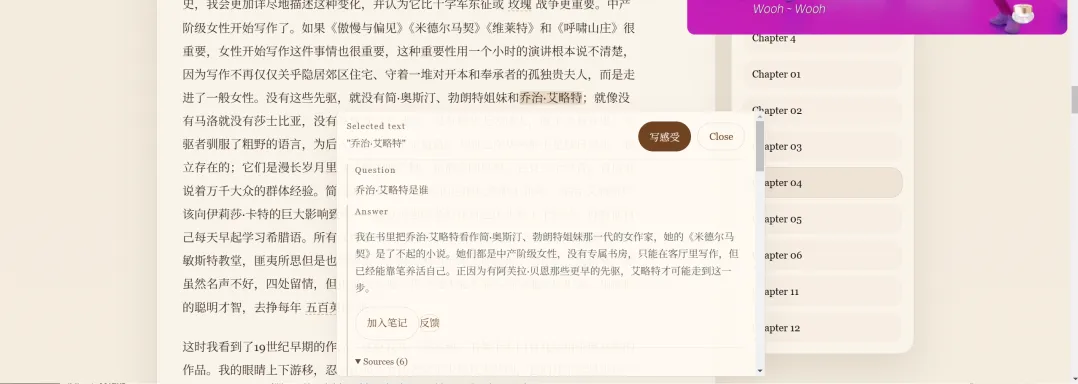
用户选中一段文字(或者长按),可以唤起 AI 问询面板。
这里不需要 AI 多聪明,重要的是它不能把用户从阅读里拽走。很多 AI 产品一提问就进入另一个巨大的聊天界面,好像用户刚才不是在读书,而是在给客服发工单。我不想这样。我想让提问像是在书页旁边写了一个小问号。问完,答案出来。看完,继续读。不要仪式感太重。
第三,留下痕迹。
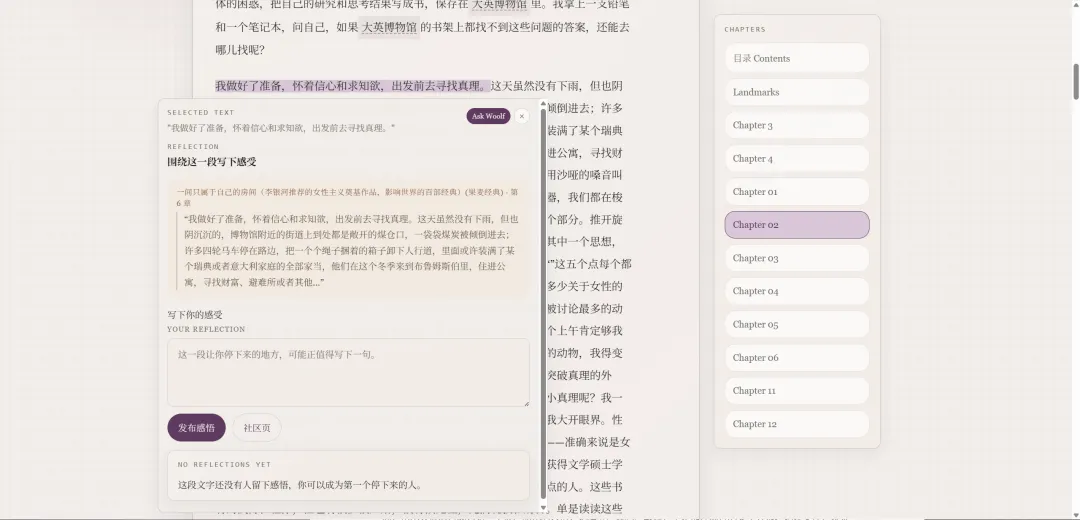
真正的阅读经验往往不是“我读完了某本书”,而是“我在某一句话那里停了一下”。
很多年后,你可能不记得整本书讲了什么,但记得某一句话给过你一种非常具体的感觉。就像:“雷亚里奥诺,马孔多在下雨。”它可能没有改变人生,也没有提供方法论,只是让你在某个下午突然沉默了两秒。
我希望 Woolfroom 能保存这两秒。所以笔记、感悟流这些东西,对我来说不是社区功能的装饰,而是这个产品里很重要的一部分。阅读不是只有理解,还有留下。
AI 解释不能太像 AI 解释,伍尔夫人格也不能太像伍尔夫人格
在你读书的时候,作者本人像幽灵一样坐在旁边,听你提问,偶尔回答,偶尔反问——听起来是一件很酷的事情。但古今中外文学大家浩如烟海,真要挨个做成 AI 角色,成本和风险都很高。每个作者的语言、立场、时代背景、思想边界都不一样。如果只是粗暴套一层“某某风格”,很快就会变成文学 cosplay。
所以我决定先从伍尔夫入手。一方面是因为《一间属于自己的房间》本来就是这个产品最初的精神来源;另一方面,伍尔夫很适合成为第一个被产品化的人格:她清醒、锋利、敏感,不是那种温吞的文学导师。她谈女性,谈金钱,谈房间,谈写作,也谈一个人如何从既有秩序里挣脱出来——多么朋克!

但这个想法听起来很好,做起来非常容易翻车。AI 一旦开始扮演文学人物,就很容易变成糟糕的舞台剧演员,每句话都像穿着长裙站在月光下朗诵:“亲爱的读者,你的灵魂正在文字中醒来。”
我写到这里都觉得很恐怖。这不是伍尔夫,这只是 AI 对“文学感”的刻板想象。
所以我后来意识到,伍尔夫人格的重点不是让她每句话都像伍尔夫,而是让她在阅读场景里有稳定的判断和边界。她可以敏锐,可以冷静,可以有一点尖锐的幽默,也可以不那么温柔。但她不是学习搭子,不是情绪客服,不是负责夸用户“你提出了一个非常深刻的问题”的捧哏。

后来我又补了一层搜索工具。
因为用户问的并不总是“这句话什么意思”,也会问作者生平、时代背景、文学流派、历史制度这些外部知识。
这类问题如果只靠模型记忆回答,很容易说得很顺,但不一定可靠。所以我把它拆成两类:文本内的问题尽量贴着原文和上下文回答;文本外的问题调用搜索工具,优先参考权威来源。如果搜不到足够可信的信息,就明确说不确定,而不是让 AI 自信地编下去。

技术栈:别让架构先把人绊住
这次技术选型很务实。
前端是 Next.js 14 + Tailwind + shadcn/ui。
数据库和认证先用 Supabase。
后面围绕着EPUB 解析、章节段落、Embedding、向量检索和 RAG 这些来做问答。
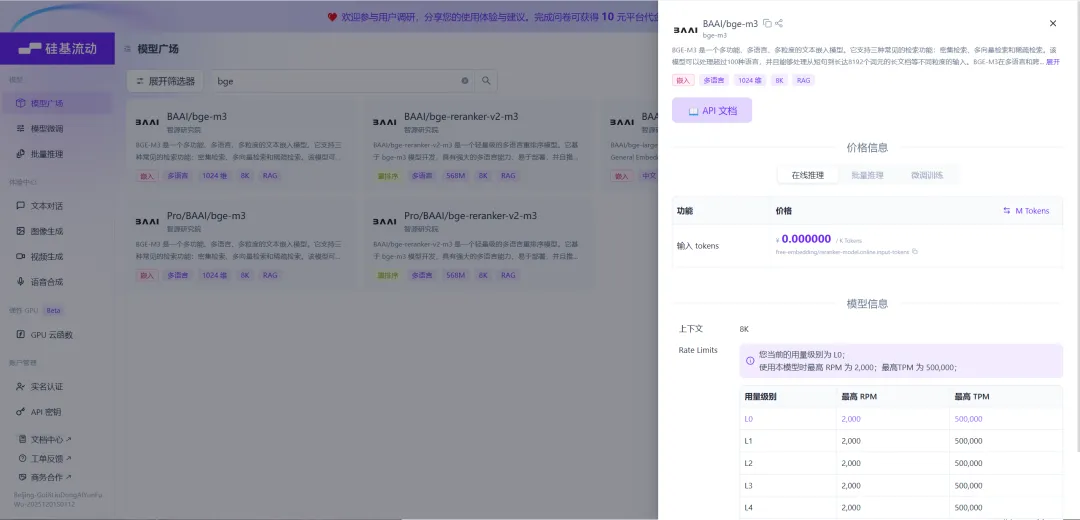
Embedding模型从硅基流动调用API
大概流程是:
·用户上传或选择一本书。
·系统解析章节和段落。
·段落切块,生成 embedding,写入库。
用户选中文本提问时,系统结合当前段落、上下文和检索结果,把证据传给 LLM,再生成回答,尽量短、尽量贴近原文。

我是怎么用 AI coding 把它做出来的?
这次做 Woolfroom,我最大的体感不是“AI 写代码真快”。
当然,它确实快。
但更准确地说,是 AI coding 把开发这件事拆成了两部分:一部分是我必须想清楚的,另一部分是它可以帮我快速实现的。
我一开始也很容易犯错。
比如直接跟 Codex 说:帮我做一个 AI 阅读器。
这句话听起来很明确,其实非常危险。因为“AI 阅读器”四个字里什么都有,书架、阅读器、登录、数据库、AI 问答、笔记、社区、角色人格,甚至还可以长出会员系统和个人中心。
如果我这样下指令,它真的会很努力地做。
但做出来的东西很可能是一个四处都能点、哪里都不深的半成品。
所以后来我换了一种方式。
我先把需求写进 PRD,再把功能按 P0/P1 拆开。P0 只保留第一条核心链路:用户打开书架,进入一本书,阅读,划线提问,获得回答,留下段落感悟。P1 再放引用来源、长期记忆、学术关联、管理员后台、书签体系这些后续能力。
记录每一次bug
壮观的change列表
然后我用 OpenSpec 把每个功能拆成一个更小的 change。
比如“阅读器基础阅读”是一组 change:用户能看到章节正文,段落能稳定展示,页面有基本的阅读布局。
“阅读进度同步”又是一组 change:用户离开页面后,下次回来能回到原来的阅读位置。
“划线/长按唤起 AI 问询”再单独作为一组 change:用户选中文本后能打开问询面板,问题里能带上当前段落和上下文,而不是把 AI 做成一个孤零零的聊天框。
“段落级感悟卡片”也是一组 change:用户读到某一句话时,可以把想法留在这一段附近,而不是另外打开一个和原文无关的笔记系统。
这样拆完之后,Codex 的作用就清楚了。
它不是替我决定产品怎么做。
它是在我已经想清楚边界之后,帮我把一个个 change 落成代码。
我给 Codex 的 prompt 也不是“自由发挥”。
一般会写得很具体:
·这个 change 的目标是什么。
·涉及哪些页面和组件。
·需要新增哪些数据字段。
·哪些交互必须实现。
·哪些功能这次不要做。
·完成后怎么验收。
比如做阅读器时,我不会让它顺手把社区、书签、AI 对话都做完。我会明确告诉它,这次只完成基础阅读和段落渲染,不要扩展无关功能。
这听起来有点啰嗦,但很有必要。
因为 AI coding 最大的问题不是它不会写。
是它太会写了。
你边界没说清楚,它会把“以后可能需要”的东西也写进去。看起来很勤快,实际上是在增加项目复杂度。
一个人做项目,最怕的不是功能少,而是代码库里突然长出很多你还没准备维护的东西。

现在它能做什么?
现在 Woolfroom 已经能跑出一个早期闭环:
·打开书架,进入一本书。
·在阅读器里读,系统自动保存进度。
·读到不懂的地方,划线或长按问 AI,AI 会结合上下文回答,不离开文本乱飞。
·章节结束时可以和伍尔夫聊聊。
·留下段落感悟,把某个停顿存下来。
它离“成熟产品”还差很远。有 bug,有些地方别扭,有些页面还可以再改。但它已经不是一个“我想做一个文学 AI 阅读器”的想法了。它能打开,能阅读,能提问,能回答,能记录,也能在你读不下去的时候轻轻推你一下。对一个个人项目来说,这已经很重要。
下一步我不打算急着把它做成“文学 AI 平台”。
“平台”这两个字听起来很气派,像是产品已经站在时代潮头,下一秒就要发布生态战略。但我对平台一直有点警惕——很多东西一旦自称平台,就会开始长出一些很难解释用途的东西。用户只是想读一页书,产品已经替他准备好了广场、排行榜、成长体系和年度报告。
我暂时不想这样。
下一步最优先的事,其实没那么宏大:AI 回答太慢了。
用户读到一句话,被绊了一下,顺手问一句——这不是提交咨询工单。如果 AI 转半天圈,阅读的气就断了。等待会把人从书里拽出来。
所以先做几件具体的事:
1.回答变短,一句话能说清就别写论文。
2.等待别只转圈,告诉用户“正在查背景”。
3.读到这里 → 被绊住 → 顺手问 → 很快得到有依据的短回答 → 没离开书 → 继续读。
这条链路如果顺了,Woolfroom 就不只是一个会回答问题的 AI 阅读器。它会更像一间真的能坐下来的房间。房间里不只有书,也有笔记,有回声,有对话,有某个下午忽然停住的两秒钟。

如果你愿意试试 Woolfroom,也欢迎把卡住你的地方告诉我。这些具体的小问题,就是这个房间下一次要添的东西。
最后附上产品链接,感兴趣的朋友可以试一试,需要web端科学上网。【Woolfroom】一间属于自己的房间:https://a-room-rbkp.vercel.app/
ReStart
图文来源:小东
文中作品及图片归原作者本人所有
未经授权禁止转载
编辑|约约
审核|UU
往期文章



Team Profile


