 夜雨聆风
夜雨聆风
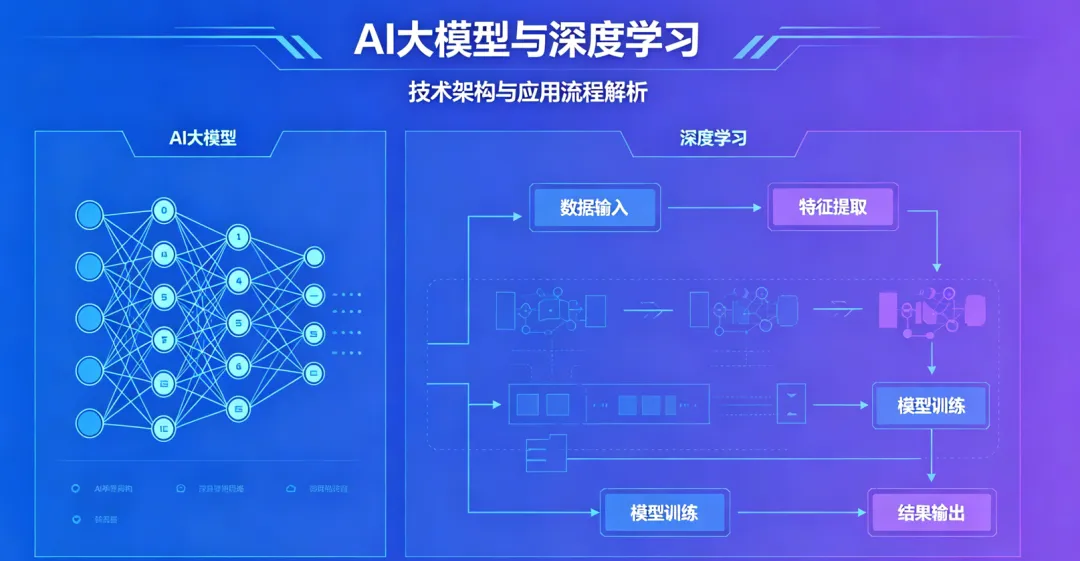
深度学习:一种机器学习方法。核心是使用多层神经网络,自动从图像、声音、文本等数据中学习从底层到高层的特征。它是一种技术范式,像CNN(卷积神经网络)、RNN(循环神经网络)、Transformer等都属于深度学习的模型架构。
大模型:通常指参数量巨大(千亿甚至万亿级)、训练数据海量(TB甚至PB级)的深度学习模型。它不是一个新技术,而是深度学习在规模上达到一个临界点后,涌现出小模型不具备的复杂能力(如逻辑推理、上下文学习)的新阶段。大模型几乎都是基于深度学习的,尤其是Transformer架构。
深度学习:参数量可大可小。一个经典的LeNet(用于手写数字识别)参数量只有6万。一个用于工业检测的小型CNN模型,参量可能是几百万。
大模型:参数量的门槛在不断被刷新,通常认为至少在10亿以上。典型如GPT-3有1750亿参数,GPT-4、PaLM等模型则有万亿级别。
深度学习:通常使用特定领域、标注精细的“小数据”。比如用几千张标注好的猫狗图片训练一个分类器。数据量级常以MB或GB计。
大模型:使用广泛、海量、未经过细标注的互联网数据。几乎“阅读”了公开的大部分网页、书籍、论文、代码库。数据量级常以TB甚至PB计。
大模型作为“老师”,通过知识蒸馏训练出轻量级小模型
大模型虽然能力强,但推理慢、耗电高,无法在手机、摄像头等边缘和人穿戴/可移动设备上运行。知识蒸馏是一种经典技术:用大模型(教师)的软输出作为监督信号,训练一个精简的小模型(学生)。
例子:医疗影像辅助诊断。
教师模型:一个百亿参数的多模态大模型(看过海量病历、影像、文献),能精准诊断罕见病。
学生模型:一个只有几MB的轻量级CNN,专门用于X光片的肺炎筛查。
做法:让大模型对10万张X光片生成诊断概率分布(不仅仅是“是/否”,还有“60%肺炎,30%正常…”),然后用这些“软标签”去训练小模型。
价值:小模型最终能达到接近大模型的精度,但可以在手机、CT机上实时运行,且不依赖网络。
许多传统深度学习模型(如目标检测、语音识别)的前几层本质上是通用特征提取器。现在的大模型(如CLIP、BERT、ViT)经过海量预训练,提取的特征更通用、更鲁棒。可以直接用大模型作为“固定特征提取器”,后面再接一个简单的专用小头。
例子:零样本分类或小样本学习。
使用CLIP模型(多模态大模型),输入一张从未见过的动物图片。
不需要任何训练,CLIP就能输出该图片与“猫”、“狗”、“熊猫”等文本描述的相似度。
如果还想适配特殊类别(如“狐獴”),只需在CLIP提取的特征上训练一个极简单的线性分类器,样本量要求极低。
价值:极大降低专用模型对新类别的适配成本
此外,现代的大模型内部本身就嵌套了传统深度学习的经典结构。例如:
Vision Transformer (ViT) 内部使用了自注意力机制(Transformer),但其早期层仍然会做类似CNN的局部特征聚合。
多模态大模型(如Flamingo、BLIP-2) 内部既有负责图像的特征抽取器(通常是ViT或CLIP的视觉编码器,本身就是深度CNN或Transformer),也有负责文本的大语言模型。
扩散模型(如Stable Diffusion) 内部大量使用U-Net结构(一种经典的深度学习架构)来逐步去噪。
所以,在实际代码层面,你很难划清“传统深度学习模块”和“大模型模块”的边界——它们本就是同一套工具库(PyTorch/TensorFlow)构建的。

