 夜雨聆风
夜雨聆风过去几年,AI最吸引眼球的是神经网络、transformers和large language models。但如果把视角放到工程落地层面,会发现一个经常被低估的事实:现代AI能够跑起来,本质上依赖硬件能力持续提升。训练模型需要海量数学运算,生成图像需要在数秒内完成大量计算,而手机端AI又要求低功耗和低延迟,这些都不是传统计算架构最初设计时重点考虑的问题。
- AI训练和推理本质上依赖海量重复数学运算。
- 矩阵乘法和tensor计算需要极高并行度。
- 传统硬件难以满足不断增长的计算需求。
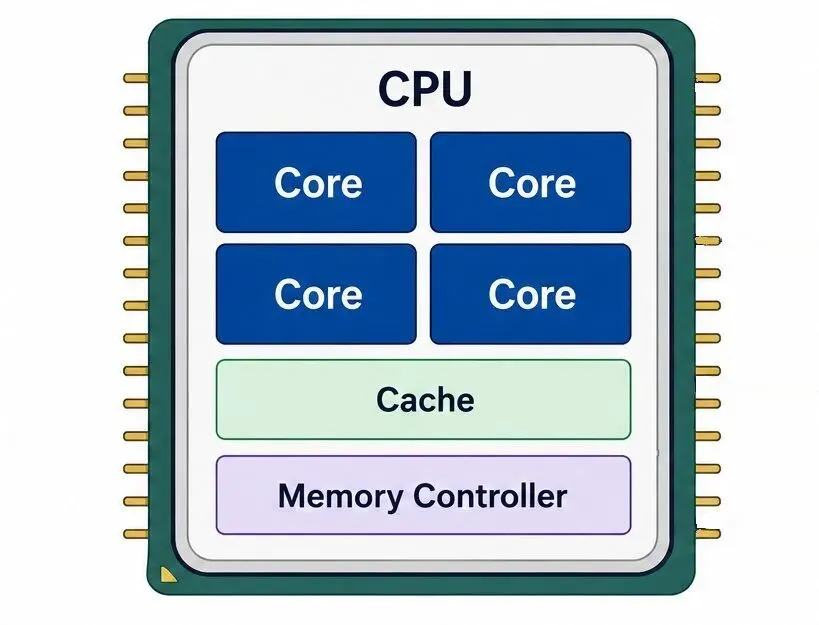
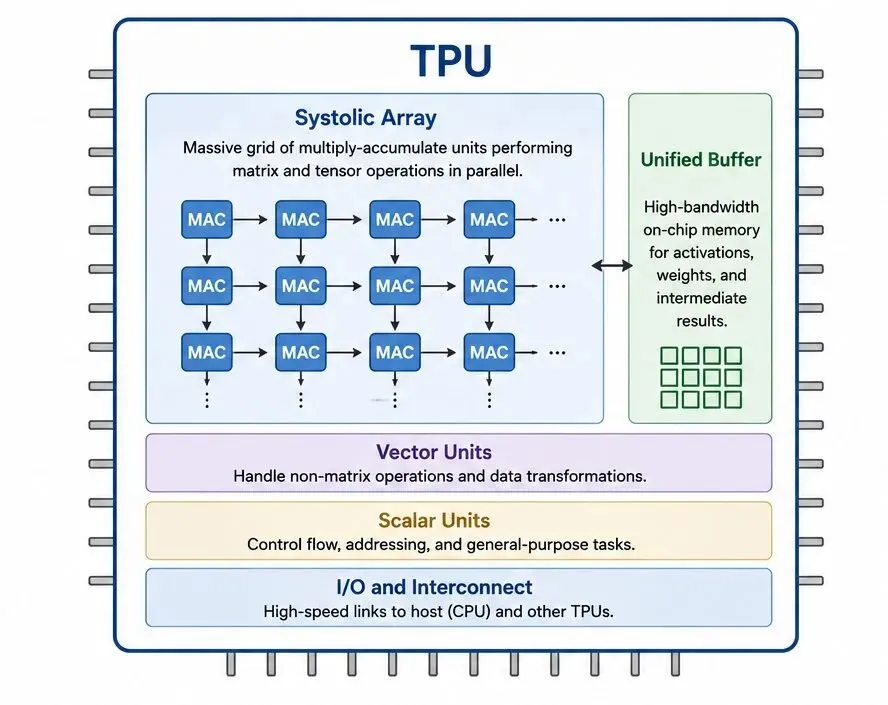
- CPU、GPU、TPU、NPU分别承担不同任务。
- 现代AI的发展速度,与硬件演进高度相关。
对于AI从业者来说,这个话题值得花90秒看完。很多团队讨论模型效果时投入大量精力,却忽略了硬件架构决定训练成本、推理吞吐和部署边界。理解硬件分工,往往比单纯追逐新模型更接近真实生产环境。
为什么AI需要专用硬件
机器学习训练过程中,大量时间都花在数字运算上。神经网络训练需要不断执行矩阵乘法和tensor运算,而且这些操作会被重复执行数百万次甚至数十亿次。
这与传统软件的工作方式差异很大。浏览器更多是在响应用户输入、加载资源,而AI系统则倾向于对海量数据执行同一种计算。计算模式不同,自然会推动硬件设计方向发生变化。
工程上最直接的需求就是并行计算能力。因为大量运算彼此独立,所以同时处理的数据越多,整体效率越高。这也是专门面向AI场景的处理器不断出现的重要原因。
CPU、GPU、TPU、NPU为何同时存在
文章指出,今天的AI生态中,CPU、GPU、TPU和NPU都承担着重要角色。原因并不复杂:不同任务对计算方式、能耗和并行度的要求并不相同。
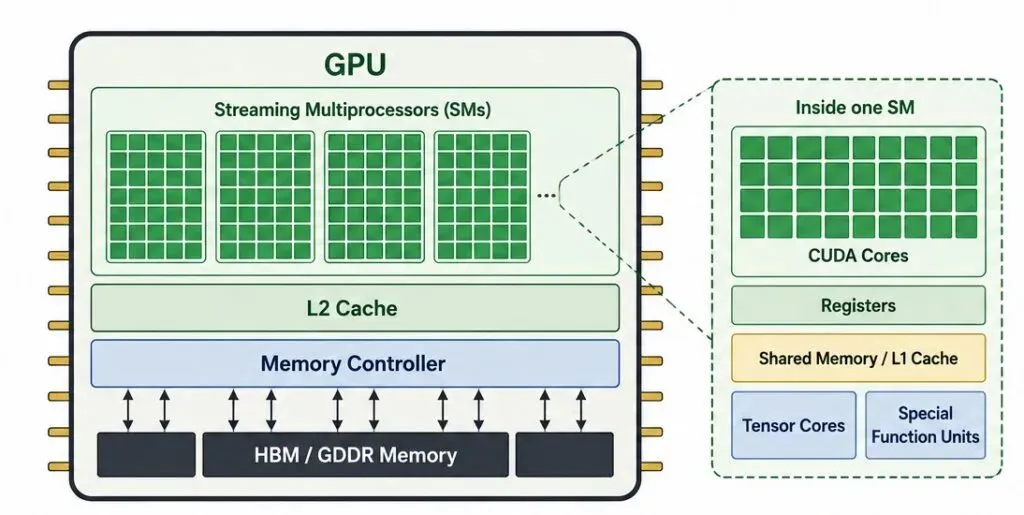
从工程视角看,没有一种处理器能够覆盖所有场景。训练大型模型、生成内容、处理海量数据以及移动端运行AI,面对的是完全不同的约束条件。因此行业并没有走向单一架构,而是逐步形成多种专用硬件协同工作的局面。
这种分工背后反映的是一个现实:AI规模越大,对硬件设计的要求越高。随着模型参数量和计算需求持续增长,硬件架构也必须同步演进。
工程视角的一个提醒
很多团队讨论AI时容易把焦点集中在算法突破上,但从部署和成本控制角度看,硬件往往决定项目最终能否落地。模型训练时间、推理响应速度、设备功耗以及整体资源利用率,都与底层计算架构直接相关。
对于技术决策者而言,一个值得关注的趋势是:未来AI竞争不仅发生在模型层,也发生在硬件层。随着计算需求持续增长,单纯优化算法很难覆盖全部瓶颈。理解CPU、GPU、TPU、NPU各自适合解决什么问题,比盲目追逐参数规模更有现实价值。很多时候,系统性能提升并不是换一个模型,而是把任务放到更适合的处理器上执行。
留言聊聊
你所在团队目前最影响AI效率的瓶颈,是模型本身、算力资源,还是硬件架构选择?
往期推荐
- ·2022年Sureel创立,Warner Music选择收编
- ·24%性能落差暴露知识编辑短板
- ·LLaMA-3.1-8B顺序微调让作文评分F1最高达87%
点击公众号头像 → 历史消息,可翻阅以上文章
