 夜雨聆风
夜雨聆风
当AI面试官"偏心"
视频面试评估的公平性困局与破局之道

AI面试官来了,但它公正吗?
后疫情时代,异步视频面试(Asynchronous Video Interview, AVI)已成为企业招聘的主流方式。候选人录制视频回答预设问题,面试官事后评分。为了提高效率,越来越多企业引入AI自动评估系统——让机器"看"表情、"听"语调、"读"内容,自动预测候选人的面试得分。
然而,一个关键问题浮出水面:AI面试官会"偏心"吗?
2018年,亚马逊的AI招聘工具因对女性的系统性歧视被迫下架,这一事件敲响了警钟。当AI从历史数据中学习"什么样的人得高分"时,它很可能一并继承了数据中潜藏的性别、种族等偏见——把"过去的不公平"变成"未来的标准"。
近期,韩国东国大学Kim等人发表于IEEE Access的研究,正是针对这一痛点,提出了一个在多模态视频面试评估中兼顾公平性与准确性的解决方案。

01
公平性研究的三个空白
本文指出,现有公平性研究存在三个关键空白:
01
从"分数"到"录用"
此前研究几乎都盯着最终的二分类结果,却忽略了分数预测阶段就可能存在偏差——而这是所有后续决策的起点。
02
多模态场景下的公平性
视频面试涉及视觉(面部表情、肢体动作)、语音(语调、语速、韵律)、文本(语言内容)三种模态的融合,但已有公平性算法大多基于表格数据设计,计算成本高,难以直接迁移到大规模多模态视频数据。
03
公平性-准确性权衡
提升公平性往往以牺牲预测准确性为代价,但现有方法很难让使用者灵活调节二者之间的平衡。
02
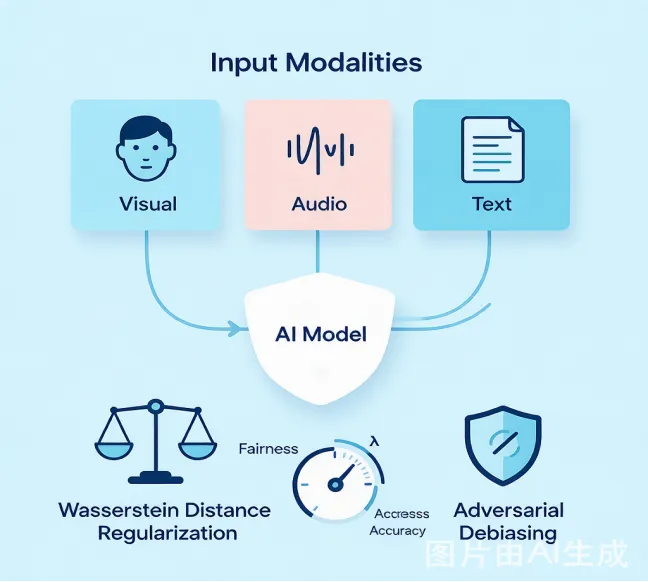
实现"公平的多模态评估"
01
拉平群体间的"起跑线"
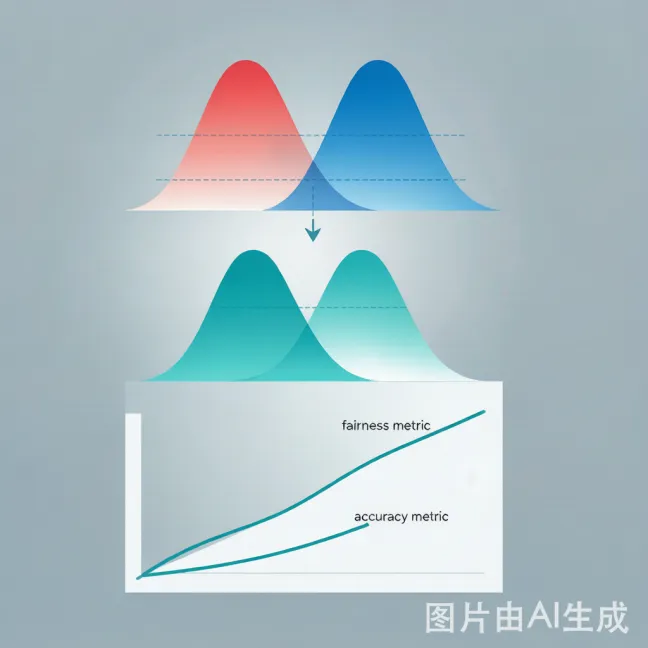
核心思路简洁而优雅:在损失函数中加入一个正则化项,最小化不同敏感群体(如男性vs.女性)预测分数分布之间的Wasserstein距离。通俗的理解就是,如果模型给男性打分的分布和给女性打分的分布"长得不一样"(比如男性系统性偏高),Wasserstein距离就会变大,正则化项就会对模型施加"拉平"的力量,迫使模型学到与敏感属性无关的特征表示。
02
让模型"看不见"敏感属性
除了正则化,研究还引入了梯度反转层(Gradient Reversal Layer)进行对抗训练。简单说,就是加一个"反间谍"的装置——判别器试图从模型学到的特征中猜测候选人的性别等敏感属性,而编码器的目标则是让判别器猜不准。两者博弈的结果,是编码器被迫学到与敏感属性无关的"干净"表示。
03
公平性与准确性的"旋钮"
方法引入超参数λ_W控制正则化强度:λ越大,公平性越强但准确性可能下降;λ越小则反之。这使得HR团队可以根据法律法规要求和业务场景灵活调节,而非被动接受一个"非此即彼"的结果。
03
研究过程与实验结果
研究使用了两个数据集:HR数据集(真实求职面试视频)和FI数据集(公开的人格印象基准数据集)。
特别值得一提的是,作者设计了一种可控不公平度预处理方法——通过参数α手动调整训练数据中敏感属性与评分的相关程度(α=1为原始数据,α越大偏见越重)。这相当于构建了一个"偏见实验室",可以在不同程度的不公平条件下测试方法的稳健性。
实验结果显示,公平与准确可以兼得:
01 公平性指标达到标准水平
无论训练数据的偏见程度如何(α从1到4),本文方法的SPDD(统计均等差异)和SPEO(强成对机会均等)均显著优于三种基线方法(无去偏、仅对抗去偏、仅重加权去偏),且预测准确性(PCC、SRCC)也更高。
02 可以兼顾公平与准确性
传统认为公平性和准确性是"鱼与熊掌",但本文方法在提升公平性的同时反而获得了更好的预测性能。可能的解释是:消除偏见相当于去除了数据中的"噪声"信号,让模型专注于真正与胜任力相关的特征。
03 小数据集也适用
当HR数据集仅剩约1000条样本时,方法依然表现稳健,这对企业实际应用是件好事。
04 隐空间可视化验证公平
PCA降维可视化显示,本文方法学到的特征表示中,不同敏感属性群体的分布几乎重叠,而基线方法则呈现明显的群体分离。
01
局限、展望与启示
敏感属性的标注困境。方法依赖训练数据中标注敏感属性(性别、种族等),但随着欧盟GDPR等隐私法规的强化,收集这类信息变得越来越困难。如何在无敏感属性标签的条件下实现公平,是一个亟待解决的难题。
面试场景的单一性。研究仅考虑了最常用的异步视频面试形式,尚未覆盖实时互动面试、群面等更复杂的场景。
跨文化公平性未检验。数据来自特定文化背景,模型在其他文化情境中是否同样公平,还需要更多验证。
01
AI面试评估必须考虑公平性
仅报告预测准确性是不够的——如果系统对特定群体系统性低估,那么其效标效度本身就是有偏的。
02
公平性不是“0或1”的选择题
λ参数的设计表明,公平性是一个可以量化调节的连续谱,HR团队应当根据组织公平理论和法律合规要求主动设定合理阈值。
03
“公平+准确”并非不可实现
本文结果表明,去除偏见信号可以帮助模型聚焦于真正的胜任力特征,这为"公平的AI更有用"提供了实证支持。

参考文献
Kim, C., Choi, J., Yoon, J., Yoo, D., & Lee, W. (2023). Fairness-Aware Multimodal Learning in Automatic Video Interview Assessment. IEEE Access, 11, 122677–122693. https://doi.org/10.1109/ACCESS.2023.3325891
作者:梁雪晶
编辑:梁丹
排版:张晨

