 夜雨聆风
夜雨聆风
导语:这两年大模型比拼的焦点,正在从"谁更聪明",悄悄转向"谁更快"。6 月 9 日,小米放出一个 UltraSpeed 版本,让一个万亿参数的大模型每秒"吐"出 1000 多个字——这在一年前还被认为很难做到。问题来了:让 AI"打字"更快,到底难在哪?为什么一堆公司砸钱去抠这个速度?今天用大白话,把"推理速度"这件事从头拆清楚。
一、先从一个你天天遇到的体验说起
你肯定有过这种体感:问 AI 一个问题,有时候答案"唰"地一下就刷满屏幕,爽;有时候它一个字一个字往外蹦,像老式打字机,你盯着光标干着急。
同样一个模型,回答有快有慢,这个"快慢"是有专门指标的,叫每秒生成多少个 token (tokens per second,简称 TPS)。它衡量的就是 AI"嘴皮子"利索不利索。
过去大家觉得,模型的本事在"聪不聪明",速度嘛,慢点就慢点。但 2026 年的风向变了:速度本身成了硬指标,甚至成了卖点。6 月 9 日小米这次放出的 MiMo UltraSpeed,就是冲着"快"去的——一个万亿参数的庞然大物,每秒能稳定生成 1000 多个 token。
这就奇怪了:把模型做大、做聪明,大家都懂要堆显卡;可"让它说话更快",听起来不就是"算得快点"吗,怎么也成了一道要专门攻关的难题?
先把基本盘立住,咱们再开拆。
事件速览
• 事件 :2026 年 6 月 9 日,小米联合 TileRT 推出 MiMo-V2.5-Pro-UltraSpeed,首次让一个万亿(1T)参数级模型的解码速度突破 1000 token/秒(来源:小米 MiMo 官方博客,2026-06-09) • 模型底子 :MiMo-V2.5-Pro 是混合专家(MoE)架构,总参数约 1.02 万亿,但每次推理只激活约 420 亿(42B)——"万亿的知识量,约 400 亿的计算成本" • 对比 :标准版 MiMo-V2.5-Pro 约 42.9 token/秒;UltraSpeed 约为其 10 倍速度、3 倍价格;用一个标准 8 卡商用节点实现 • 关键概念 :推理分两步——读入提问的"预填充"(prefill,吃算力)和逐字生成的"解码"(decode,吃显存带宽);日常体验的快慢主要卡在解码
二、先搞懂两个词:token 和"两阶段"
要拆速度,得先认识两个最基础的概念,否则后面全是云里雾里。
第一个,token(词元)。 大模型不是一个字一个字地处理文本,而是切成一个个"token"——可以粗略理解为"词"或"半个词"。中文里,一个 token 大约对应一到两个汉字。模型生成回答的过程,本质就是一个接一个地"预测下一个 token" :根据前面所有内容,算出最可能的下一个词,吐出来,再把它接上去,继续算下一个。所以"每秒多少 token",就是它每秒能完成多少次这样的"预测—吐字"循环。
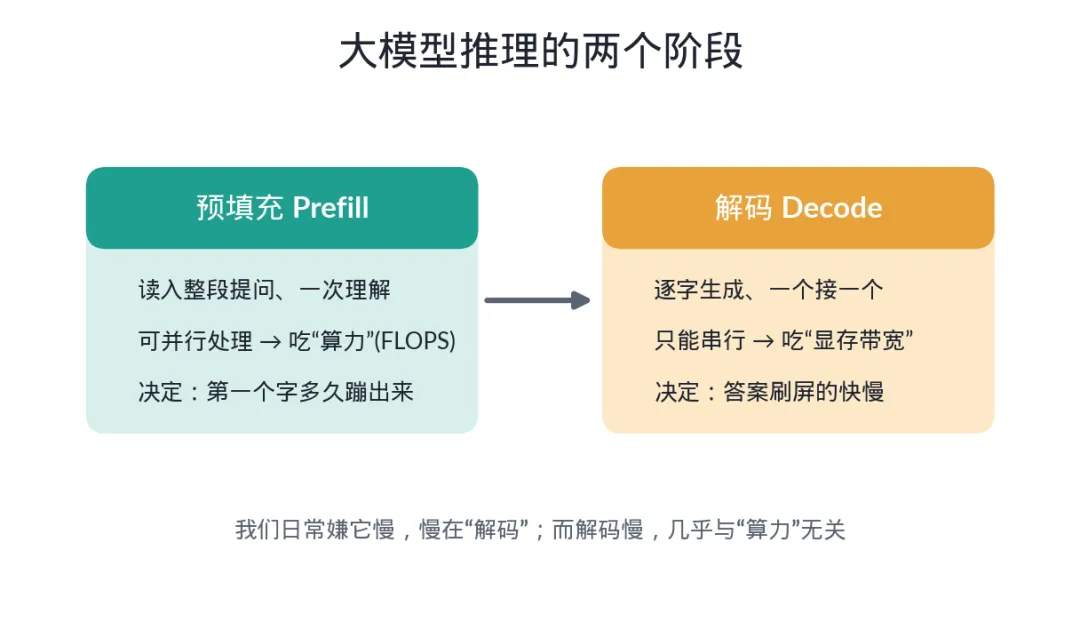
第二个,推理分两个阶段,脾气完全不同。
• 预填充(prefill) :模型先把你的整段提问"读"进去、理解一遍。这一步可以把所有输入 token 一起并行处理,特别吃算力 (也就是芯片的计算能力 FLOPS)。它决定了你按下回车后"第一个字多久蹦出来"。 • 解码(decode) :理解完了,开始一个一个往外生成答案。这一步是串行 的——必须先有上一个字,才能算下一个字,没法并行。它决定了答案"刷屏"的速度。
记住这个分工,因为整篇文章的关键就在这儿:我们日常嫌它慢,慢在解码;而解码慢的真正原因,跟"算力"几乎没关系。
三、第一层:慢,不是因为"算得慢",是因为"搬得慢"
这是整件事最反直觉的一点,也是理解一切加速手段的钥匙。
直觉上,我们以为"生成快"靠的是"算力强"——芯片每秒能做的乘法越多就越快。这话在预填充 和"一次处理一大批用户请求"时是对的。但对单个请求的逐字生成(解码) 来说,几乎是错的。
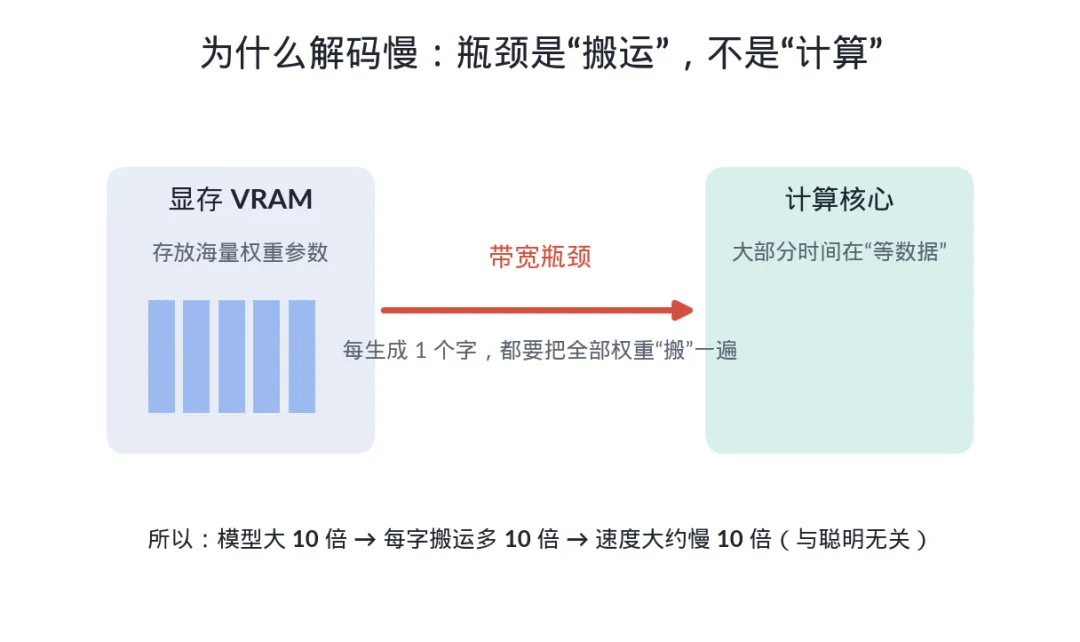
为什么?咱们看一遍解码时芯片到底在干嘛。每生成一个 token,芯片都要把模型相关的权重参数 从显存(VRAM)里搬到计算核心上,过一遍,吐出一个字;下一个字,再搬一遍。一个几百亿、上千亿参数的模型,每吐一个字,都意味着要把巨量的数据从显存里"读"出来一趟。
瓶颈就在这"读"上。决定解码速度的,不是芯片算得多快,而是显存往外"喂"数据有多快 ——这个指标叫显存带宽(memory bandwidth) 。打个比方:解码不像是考你心算多快,而像是让你抄一本厚厚的字典,你抄写的速度再快也没用,瓶颈是你翻书、找到那一页的速度 。计算核心大部分时间在"等数据上来",而不是在"埋头算"。

这就解释了一个老规律:模型越大,生成越慢,而且几乎是成比例地慢。 一个 700 亿参数的模型,比 70 亿参数的大十倍,每吐一个字要搬运的数据也大约多十倍,于是在同样的硬件上,速度大致慢十倍。这跟"聪明不聪明"无关,纯粹是"每个字要搬多少砖"的物理问题。
一个经验区间能帮你建立体感:解码速度 50 token/秒以上,人感觉"瞬间出答案";20—30 还能接受;低于 10,就明显卡顿、像挤牙膏了。
理解了"慢在搬运、卡在带宽"这一层,下面所有的加速魔法,本质都在干同一件事:想方设法少搬点、或者搬得更聪明。
四、第二层:三板斧,是怎么把速度抠出来的
既然慢的根子是"每个字要搬运太多权重",那提速的思路就清晰了。业界主要靠三板斧,咱们一个个看,每个都给原理和例子。
第一斧:MoE(混合专家)——别每次都动用全部脑细胞。
传统大模型是"密集"的:每生成一个字,整个模型的全部参数都要参与、都要被搬运一遍。MoE 换了个思路:把模型拆成很多个"专家"小网络,每次只激活其中一小部分 ,让最相关的几个专家来干活,其余的睡大觉。
小米这次的 MiMo-V2.5-Pro 就是典型:总参数约 1.02 万亿,但每次推理只激活约 420 亿。这意味着什么?你享受到的是"万亿模型"的知识储备,但每个字的搬运成本,只相当于一个 400 多亿参数的模型。 用我们上一层的话说——它把"每个字要搬的砖"砍掉了一大半,速度自然上去。这也是为什么近两年的前沿大模型几乎清一色转向了 MoE 架构。
第二斧:投机解码(speculative decoding)——让小模型"打草稿",大模型"批改"。
前面说过,解码是串行的、一个字一个字来的,这是天然的慢。投机解码用了个巧劲:先让一个又小又快的"草稿模型",一口气往前猜好几个字(比如猜 4 个),然后让又大又准的"主模型"一次性并行验证 这几个字对不对。猜对的部分直接采纳,等于"一步顶好几步";猜错了再回退重算。
这招的妙处在于:验证 4 个字和生成 1 个字,对主模型来说耗时差不多(因为验证可以并行),但前者一次就推进了好几个 token。据 Cerebras 公开的数据,用一个 30 亿参数的草稿模型去配 700 亿参数的主模型做投机解码,速度能冲到每秒约 4000 token。相当于雇了个手快的实习生先把答案草拟出来,教授只负责快速打勾,整体出活快了好几倍。
第三斧:专用硬件——干脆换一种芯片。
既然瓶颈是"显存带宽",那能不能从硬件上根治?两家公司给了两种极端答案。
• Cerebras 用"晶圆级"芯片,把整个模型直接装进芯片内部的高速 SRAM 里,带宽据称高达约 21 PB/秒,省掉了"从外部显存反复搬运"这个最慢的环节。其公开数据显示,跑 Llama3.1-8B 能到约 1800 token/秒,70B 约 450 token/秒,号称比主流 GPU 云快约 20 倍。 • Groq 走的是另一条路:用大量轻量核心组成"数据流"流水线,把模型像传送带一样流过去,控制开销极低。它在小模型上也做到了每秒上千 token、首字延迟低于 100 毫秒的水平。
当然,专用硬件各有取舍,第三方基准(如 Artificial Analysis)上各家排名常有变动,具体数字随模型、批量、配置浮动,别把单一数字当圣经。但方向是一致的:为"快"专门设计的芯片,确实能把通用 GPU 甩开一大截。

回头看小米这次的成绩就更有味道了:它用的是一个标准的 8 卡商用节点 ,没上什么神秘专用芯片,靠软件层(TileRT)和 MoE 架构的配合,硬是把万亿模型怼到了 1000+ token/秒。代价是 UltraSpeed 版本大约 3 倍于标准版的价格、换来约 10 倍的速度——这恰恰说明:速度,是可以用钱和工程直接买到的一种产品规格。
五、第三层:为什么"现在"突然都来拼速度
最后一个问题:速度一直都重要,为什么是 2026 年这个节点,大家集体上头?
因为 AI 的用法变了,对 token 的"消耗量"暴涨了。
早期你用大模型,就是一问一答,生成几百个字也就够了,慢一点忍忍也行。但现在两类新用法,把 token 消耗拉高了一两个数量级:
一是会"思考"的推理模型。 这类模型在给出最终答案前,会先在内部生成一大段"思维链"——自言自语地推演、试错、检查。这意味着它要先吐出成千上万个"草稿 token",你才能看到那几句结论。生成量一上去,速度就成了生死线:同样的思考深度,慢的模型让你等一分钟,快的模型几秒钟就好。
二是 AI 智能体(agent)。 让 AI 自动完成多步任务——查资料、写代码、调工具、再修正——背后是一轮接一轮的生成,token 像流水一样消耗。在这种场景里,速度直接决定了"一个任务要跑多久",慢一倍,可能就意味着体验从"能用"掉到"没法用"。
而且速度还直接挂钩成本 。生成同样多的 token,速度越快,单位时间内服务的用户越多,摊到每个 token 的硬件成本就越低。所以对厂商来说,"快"不只是体验好,更是省钱 ——这也是为什么连"算力荒"喊得震天响的当下,大家还要拼命抠推理效率:省下来的每一分带宽,都是真金白银。
一句话总结这一层:当 AI 从"聊天"走向"思考"和"干活",token 从奢侈品变成了消耗品,谁能把每个 token 的生成又快又便宜,谁就握住了规模化的命门。
六、这事跟你我有什么关系
不写代码的普通人,从这篇能带走三个判断力。
第一,看 AI 产品别只看"参数多大、多聪明",要看"用起来跟不跟手"。 一个稍微笨一点但反应飞快的助手,日常体验往往胜过一个绝顶聪明但每次都让你等半分钟的。速度是体验的一部分,而且是最容易被忽略、又最影响你愿不愿意天天用的那部分。
第二,理解了"大模型越大越慢",你就不会被参数数字唬住。 厂商爱秀"万亿参数",但 MoE 告诉你,真正影响速度和成本的是"激活了多少",而不是"总共有多少"。下次看到天文数字的参数,可以多问一句:它每次到底动用了多少?
第三,"快"是能用钱买的规格,所以会分层。 就像小米的标准版和 UltraSpeed 版,未来你大概率会看到 AI 服务按速度分档定价——急用、要快,多付钱;不急,用便宜的慢档。心里有这个框架,你就能按需选择,而不是为用不上的速度白掏钱。
七、说到底
说到底,大模型这场竞赛,正在从"比谁脑子大",进入"比谁手脚快"的新阶段。
这背后是一条特别朴素的工程规律:任何技术,一旦从"能不能做到"跨过门槛,竞争就会转向"能不能又快又便宜地做到"。 汽车比完马力比油耗,芯片比完性能比能效,大模型也一样——聪明是入场券,高效才是护城河。
1000 token/秒今天还是个值得发博客庆祝的纪录,但你我都知道,要不了多久它就会变成"标配",然后被下一个数字刷新。技术的进步,往往就是这么一回事:把昨天的"奇迹",熬成今天的"日常"。
下次 AI 再"唰"地一下给你刷满一屏答案时,你可以想一想——这背后,是一整个行业在跟"显存带宽"这堵墙较劲的结果。
参考来源
• MiMo-V2.5-Pro-UltraSpeed 突破 1000 token/秒、MoE 总参约 1.02 万亿/激活约 420 亿、标准版约 42.9 token/秒、UltraSpeed 约 10 倍速 3 倍价、单 8 卡节点、试用期 2026-06-09 至 06-23:小米 MiMo 官方博客《Pushing 1T-Parameter Model Generation Speed to 1000 TPS》及 MiMo 模型页(2026-06-09 查询) • 推理分预填充(compute-bound)与解码(memory-bandwidth-bound)、解码速度由显存带宽决定、模型大十倍约慢十倍、TPS 体感分级:多篇 LLM 推理速度科普(inferencerig、hardware-corner 等,2026 查询) • 投机解码原理(草稿模型提议、主模型并行验证)、MoE 与投机解码结合:arXiv 相关论文综述(2508.21706、2506.20675 等,2026 查询) • Groq LPU、Cerebras 速度数据(Cerebras Llama3.1-8B 约 1800 token/秒、70B 约 450、投机解码达约 4000;晶圆级 SRAM 约 21 PB/秒带宽;Groq 上千 token/秒、首字延迟<100ms):Cerebras 官方博客与第三方基准(Artificial Analysis 等,2026 查询;具体数字随模型与配置变化) • 注:本文为推理加速原理科普,速度数字来自厂商与第三方基准,不同测法口径有出入,仅供建立量级概念。
配图来源
• 内文"NVIDIA H100 加速卡":Wikimedia Commons,File:NVIDIA H100 (极客湾Geekerwan) 016.png,CC BY 3.0,授权以 Commons 文件页为准。文件页 https://commons.wikimedia.org/wiki/File:NVIDIA_H100_(%E6%9E%81%E5%AE%A2%E6%B9%BEGeekerwan)_016.png • 封面、"推理两阶段""解码带宽瓶颈""三种提速思路"对照图为本文自制图(数据来源见参考来源)。
