 夜雨聆风
夜雨聆风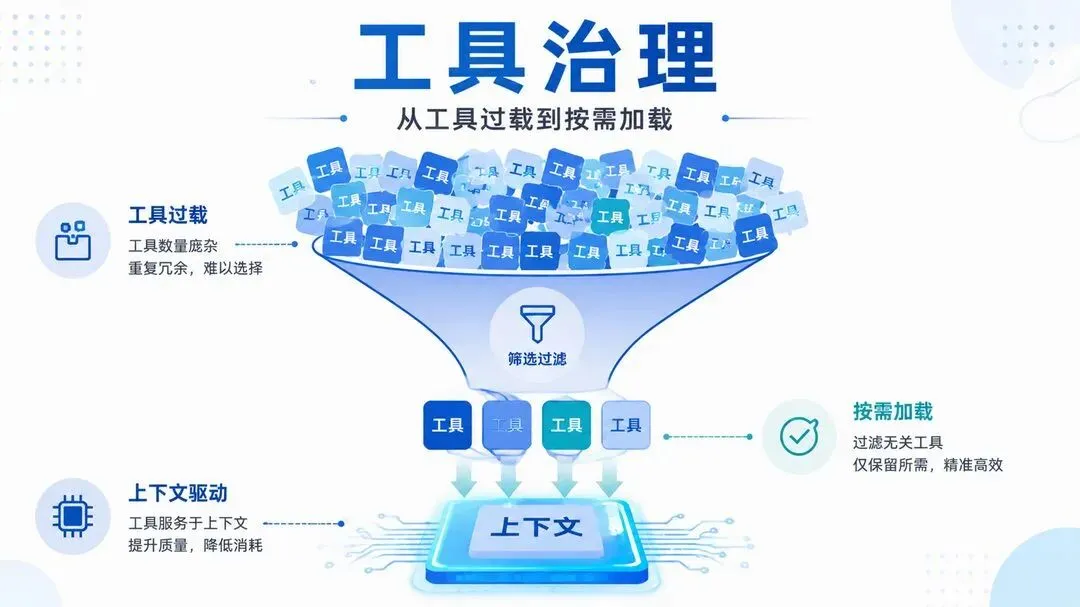
AI 工程实践
把 50 个工具一次性塞给模型,就像把整本 API 文档拍在它脸上说"自己挑"——它当然挑得又慢又错。
1. 问题:工具不是越多越好,是越多越贵
先说一个很多人都踩过的场景。
你给 Agent 接了 GitHub、Slack、Sentry 三个 MCP server,想让它"什么都能干"。结果它还没读到你的第一句话,光这三个 server 的工具定义,就已经在上下文里占掉 约 5.5 万 token(Apideck 2026 年 3 月实测)。再接几个,一套十几个 server 的栈,工具 schema 能干到 14.3 万 token——当时相当于 Claude 上下文窗口的 72%。

这不是个别现象。公开 MCP 目录现在列出超过 2 万个 server,光 4 月本地下载量就有 6700 万次(Pulse MCP);Bloomberry 跟踪的 1400 个 server 半年增长 232%。大家都在疯狂往 Agent 上接工具。
但工具接得越多,有两件事在悄悄变坏。
一是上下文被工具定义吃掉。 每个工具的名字、描述、参数 schema,每一轮请求都要重新注入。有开发者实测,在 Claude Code 里 MCP 工具定义占满了 16.3% 的上下文,而他一句正经话还没说。窗口从 200K 涨到 1M 也没救——Roadie 的测算说得很直白:更大的窗口给你更多余量,但不改变"每次调用都要为 schema 付费"的成本结构。
二是注意力被相似工具稀释。 这个更隐蔽。arXiv 一篇《How Many Tools Should an LLM Agent See?》实测:当候选工具从精选扩到塞满,Claude 选对工具的准确率从 93.1% 掉到 87.1%。dev.to 上一篇 AWS Hero 的拆解更狠:8B 小模型的甜蜜点大约在 19 个工具,到 46 个就开始崩;再大的模型,过了 100 个也吃力。机制叫"工具幻觉"——名字相似的工具一多,模型开始编不存在的工具名、把 A 工具的参数塞给 B 工具。
更麻烦的是,这种退化往往不是平滑下滑,而是过了某个阈值后断崖式塌掉:上下文膨胀(50 个工具以上,光 schema 就能吃掉 5–7% 窗口)和工具幻觉两股力量一旦叠加,准确率会突然崩盘,而不是慢慢变差。
一句话:工具规模化之后,瓶颈不在模型会不会推理,而在它有没有上下文预算去看清这些工具。
2. 一个洞见:把工具当"要检索的知识",而不是"要常驻的菜单"
想清楚一件事,后面全通:工具和知识,本质是同一类东西——都不该一次性全塞进 prompt。
我们早就接受了 RAG:知识库再大,也不会把整个语料灌进上下文,而是按问题检索 top-K。可轮到工具,大多数人还在用"把菜单全摆出来"的老办法——把所有工具定义常驻在上下文里,赌模型能从一百道菜里挑对。
Tool RAG 就是把 RAG 那套搬到工具上:先按用户意图召回最相关的几个工具,再把它们交给模型。Red Hat 2025 年 11 月的数据是——智能工具检索能把工具调用准确率做到三倍,同时砍掉一半 prompt 长度。
所以这篇文章讲的"工具治理",核心就一句:把工具当成需要检索的知识,而不是需要常驻的菜单。 常驻的越少,模型越清醒。
3. 工具治理的四层架构
把上面这句话落到工程上,是一条从"工具事实"到"按需注入"的流水线。我把它拆成四层:
用户意图 / 当前任务
│
▼
┌────────────────┐ 只留一行摘要,不灌全量 schema
│ 1 工具注册层 │ tool summary 常驻
└───────┬────────┘
▼
┌────────────────┐ 按意图召回 top-K(向量 / BM25 / 规则)
│ 2 工具检索层 │ Tool RAG / Tool Search
└───────┬────────┘
▼
┌────────────────┐ 只把选中的 schema 注入上下文
│ 3 渐进加载层 │ deferred tools / lazy schema
└───────┬────────┘
▼
┌────────────────┐ 调用 + 裁剪返回值,别灌满窗口
│ 4 执行裁剪层 │ result truncation / code mode
└────────────────┘
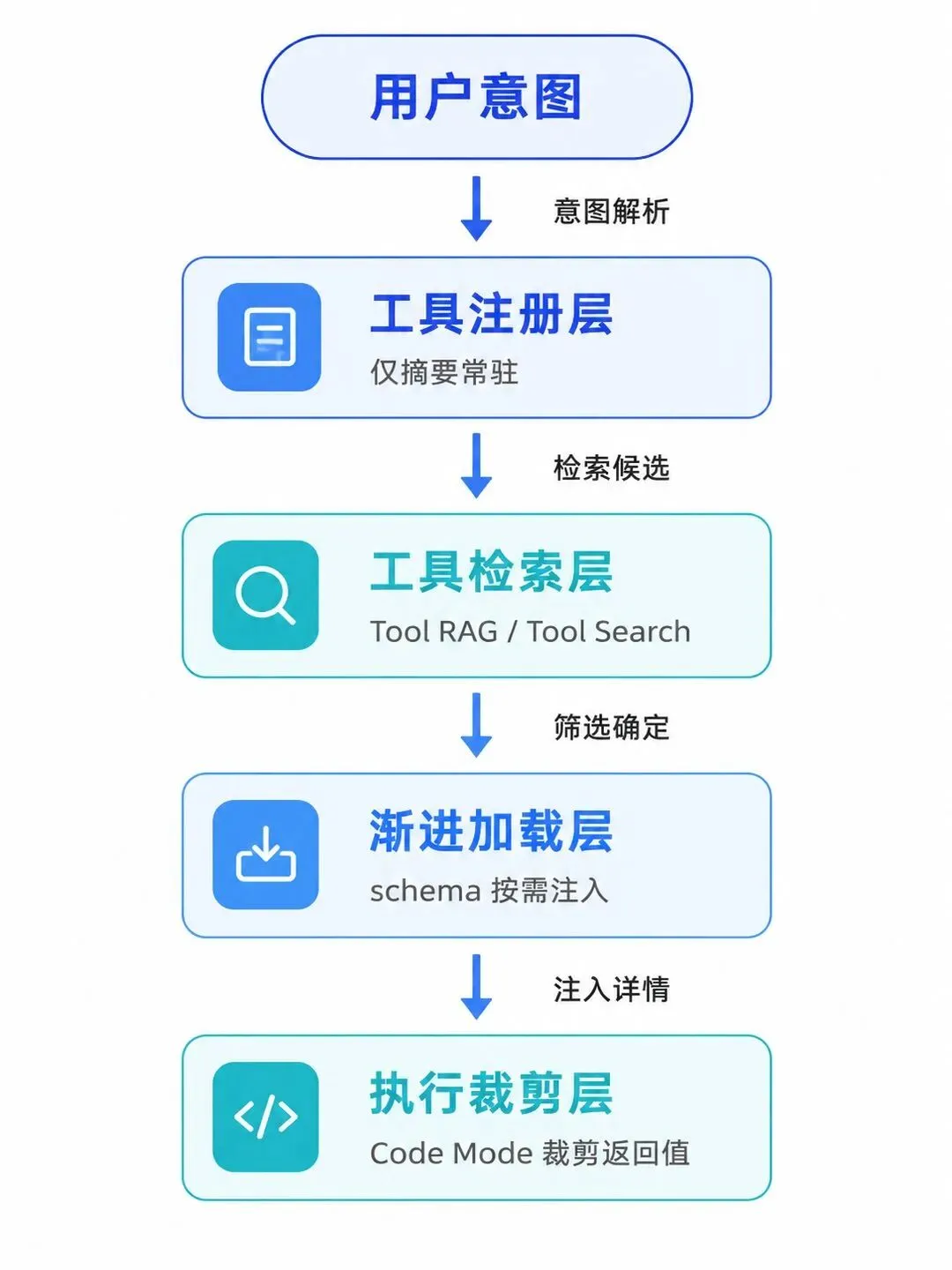
3.1 工具注册层:摘要常驻,schema 按需。 第一刀切在"常驻什么"。常驻的不该是完整 schema,而是一行摘要——工具名 + 一句话能力描述。几十个工具的摘要加起来不过几百 token,模型用它来"知道有什么",但还不需要"知道怎么调"。完整的参数 schema 留到选中之后再加载。
3.2 工具检索层:把选择前置。 模型不该在一百个工具里现场挑,而该先有一步检索把候选压到个位数。实现可以很轻:向量召回、BM25、甚至基于任务类型的规则路由都行。关键是让模型每次只面对 3-5 个真正相关的工具,而不是全量清单。arXiv 那篇的结论反过来用就是:候选越聚焦,选择准确率越高。
3.3 渐进加载层:选中才注入。 这是省 token 的主力。工具的完整定义默认"延迟加载"(deferred),只有被检索层选中、或被模型显式请求时,schema 才进上下文。Anthropic 的 Tool Search Tool 走的就是这条路:工具定义 token 砍掉 85%,而且准确率不降反升——Opus 4 在大工具库上从 49% 升到 74%,Opus 4.5 从 79.5% 升到 88.1%(Anthropic 官方工程数据)。
3.4 执行裁剪层:返回值也要治。 工具治理不止治"输入",还要治"输出"。一个工具返回 2 小时会议纪要、几百行日志,照样能灌满窗口。解法是把执行搬到模型上下文之外——code execution / Code Mode:模型写代码去调工具、在沙箱里处理中间结果,只把最终需要的那一点点回传。Anthropic 那个 Google Drive→Salesforce 的例子,就是靠这个把一次工作流从 15 万 token 压到 2000 token(降 98.7%)。
每一层都在回答同一个问题:这个 token 值不值得占上下文。不值得,就别让它常驻。
4. 三种主流实现的对比
工具治理不是单一方案,2026 年已经收敛出三条主流路线。它们解决的是同一个问题的不同切面:
search()+execute(),模型写代码调 |
还有一条更"土"但有效的路线:干脆别用 MCP,改用 CLI。同一个任务,Microsoft Graph MCP 要约 14.5 万 token,换成命令行工具只要约 4150——便宜 35 倍,而且复杂任务下 MCP 的可靠性会从 100% 掉到 72%。CLI 天然就是"按需加载":--help 才告诉你有什么,不调用就不占上下文。
选型没有银弹,一句话经验:单次只用少量工具就上 Tool Search;工具多到要靠语义区分就上 Tool RAG;要串长链路、还要处理大块返回值就上 Code Mode。
5. 改造前后:一份真实参照
把"全量常驻"换成"按需加载",差别大概是这样:
这不是纸上谈兵。我现在跑的这套环境,本身就是按需加载的:几十个工具默认不在上下文里,要用的时候,我先 search 出工具名、再 fetch 出它的完整 schema,它才变得可调用。换句话说,"工具治理"对我不是一个要不要做的选项,而是这套系统能跑起来的前提——没有它,光工具定义就能把上下文榨干。
顺带提醒一个最容易被忽略的放大器:多环境、多实例。你想查 dev / staging / prod 三套库的节点数,用 MCP 就要起三个 server,同样的四个 schema 进上下文三遍。工具数不只随功能涨,还随环境涨。解法是把环境做成参数,而不是做成新 server。
当然,治理本身也有成本。如果你的 Agent 统共就接了十来个工具,强行套一层检索只会徒增复杂度——这时候老老实实全量常驻反而更简单。工具治理是规模化之后的必修课,不是起步阶段的银弹。 一个经验阈值:工具数过了 20–30 个、或单个 server 的 schema 开始以万 token 计,再上这套也不迟。
6. 落地 Checklist
把上面这套收成一份能逐条照做的清单:
- 先量再治。
用 /context之类的手段,先看清工具定义到底占了多少上下文。多数人没量过,一量吓一跳。 - 工具分层。
常驻的只留一行摘要,完整 schema 改成按需加载。 - 上工具检索。
工具超过 20 个,就该有一步 Tool RAG / Tool Search 把候选压到个位数,别让模型面对全量清单。 - 裁剪返回值。
大返回(日志、纪要、长 JSON)走 code execution,在上下文外处理,只回传结论。 - 环境参数化。
多环境用参数,不要为每个环境复制一套 server。 - 设预算红线。
给工具定义占用定个上限(比如不超过上下文的 5%),越线就触发治理。
一条贯穿始终的判断标准:每一个进上下文的 token,都要问它值不值得占模型的注意力。 工具也不例外。
工具不是接得越多 Agent 越强。把工具当知识来检索、按需加载——少即是多,这是 2026 年 Agent 工程绕不开的一课。
参考资料
[1] How Many Tools Should an LLM Agent See? A Chance-Corrected Answer, arXiv:2605.24660, 2026 [2] MCP Tool Design: Why Your AI Agent Is Failing (And How to Fix It), dev.to / AWS Heroes, 2026 [3] Tool RAG: The Next Breakthrough in Scalable AI Agents, Red Hat, 2025-11-26 [4] Why Your MCP Server Might Be Eating Your Context Window, Roadie, 2026 [5] Anthropic Engineering — Advanced tool use(Tool Search Tool / Programmatic Tool Calling), 2025-2026 [6] Anthropic Engineering — Code execution with MCP, 2025 [7] MCP vs CLI for AI Agents / Cloudflare Code Mode, Firecrawl, 2026 [8] 10 Interesting MCP Statistics, NordicAPIs, 2026
一句话锐评
工具不是接得越多 Agent 越强,而是常驻得越少它越清醒。 把工具当菜单全摆出来,是在用模型有限的注意力预算,买一份它根本看不完的菜单。
关注「人工智能AI技术圈」
获取更多 AI 与机器人前沿动态
大模型 · 智能体 · 机器人 · 前沿拆解

长按识别二维码 · 一键关注
