 夜雨聆风
夜雨聆风我是老九,一个一直在一线折腾技术和AI的人。我习惯留意一些看着很先进,但放到工作和生活里付出不小代价的事。欢迎关注我!
当前章节:第一章|Token与分词机制
当前小节:第四节|Token 为什么会影响模型行为(Prompt 与上下文层)
本篇知识点:lost in the middle
我以前用大模型的时候遇到一个奇怪的现象:发了一大段内容,开头模型记住了,结尾模型也记住了,偏偏最重要的信息放在中间,它忘了。
比如:
要求A
......
要求B(最重要)
......
要求C
结果回答里:
A 执行了。
C 执行了。
B 没了。
我还怀疑模型是不是偷懒?其实不是。
理论上Transformer可以看到整个上下文。
开头,
中间,
结尾,
全部都在窗口里。但能看到不等于会重点关注,这就是特别有名的研究现象,名字就叫:Lost in the Middle中间遗失。
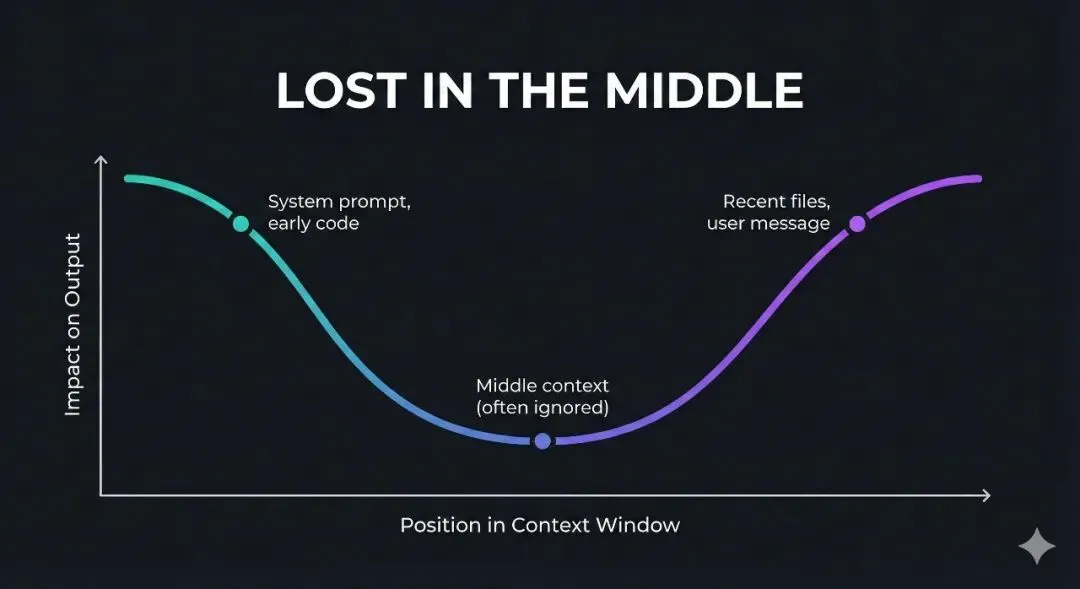
我看过一篇文章,研究人员做过实验。把同一个答案分别放在:开头,中间,结尾。
测试模型能不能找到,结果发现开头命中率高,结尾命中率高,中间最低,形成一个很明显的U型曲线。换句话说模型最容易忽略的就是中间那部分。
为什么会这样?我说一个场景可能会容易解释这个现象。
你在看一本书,第一页写着:考试重点
你会记住。
最后一页写着:考试重点
你也容易记住。
但如果放在:第127页中间某一段。
很多人看完就忘。
模型也类似,因为注意力资源不是无限的,虽然Transformer理论上能看全部token,但Attention分配是有倾向的,很多头会天然关注:当前位置附近。
或者:序列两端。
于是中间区域经常成为竞争最激烈的地方。
还有一个问题:上下文越长,问题越明显。
例如:100个token可能影响不大。
但:10万token,20万token,甚至百万token。
中间内容被稀释得越来越厉害,因为每个token都在争夺注意力。注意力预算有限,很多信息还没来得及建立强连接就被后面的内容覆盖了。
这里有个特别有意思的现象,以前我做RAG时会发现知识库命中了,但模型没用,排查发现检索结果被塞进了上下文正中间。模型看到了但没重点关注,于是回答时直接跳过。后来很多RAG框架开始优化:信息摆放位置。
例如:重要内容放前面或者放最后面,不是放中间。因为位置本身就在影响引用概率。
还有一个特别明显的例子,长Prompt。
例如:
角色设定
......
背景资料
......
重要要求
......
输出格式
很多人把最重要要求塞在中间,结果模型老忘。后来改成开头说一次,结尾再说一次,效果明显提升,原因就在这里。
再多说一句,这篇和以前说的Recency Bias不一样。Recency Bias讲的是最后内容影响更大,Lost in the Middle讲的是中间内容影响更小。
一个是加强。
一个是削弱。
共同构成了长上下文里的注意力分布。
很多时候不是模型没看见,也不是模型故意忽略。而是在一条很长很长的token河流里,中间那部分最容易被淹没。
如果你读着还行,欢迎点赞收藏关注;如果有不同的观点,也欢迎大家留言讨论。
