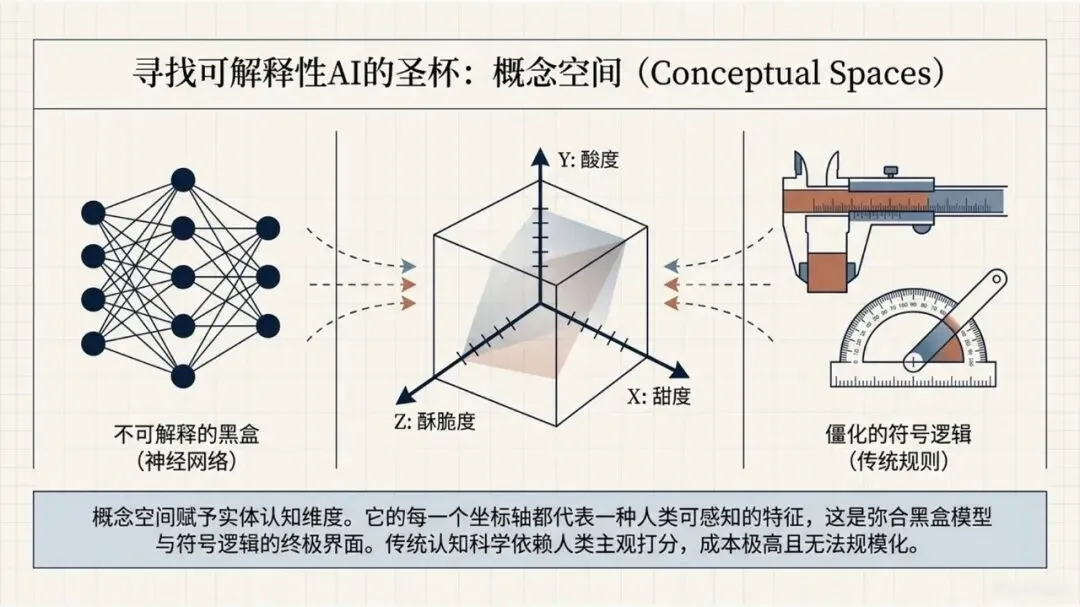
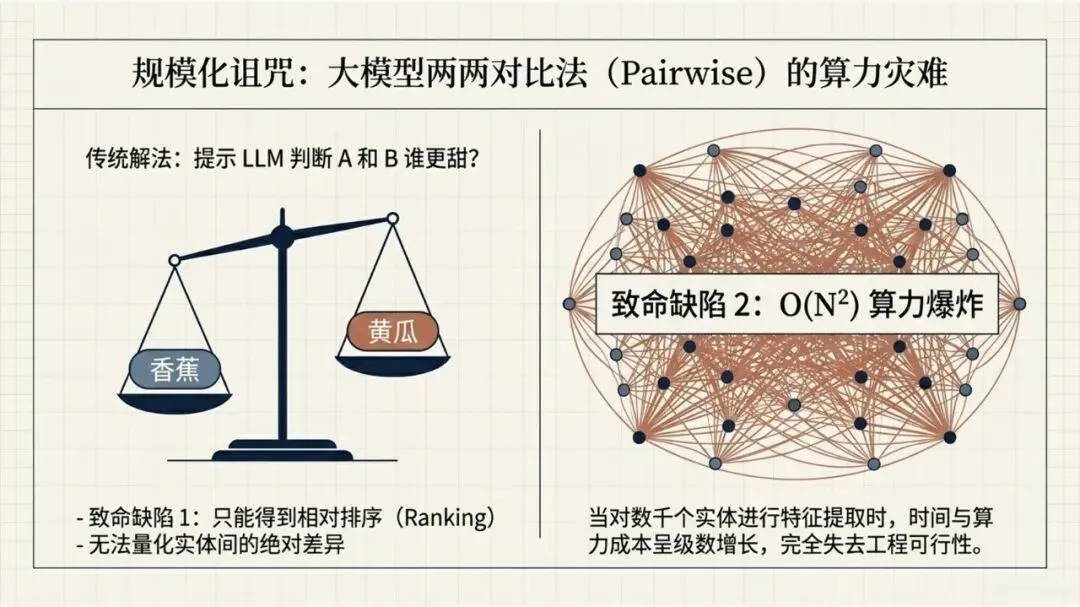
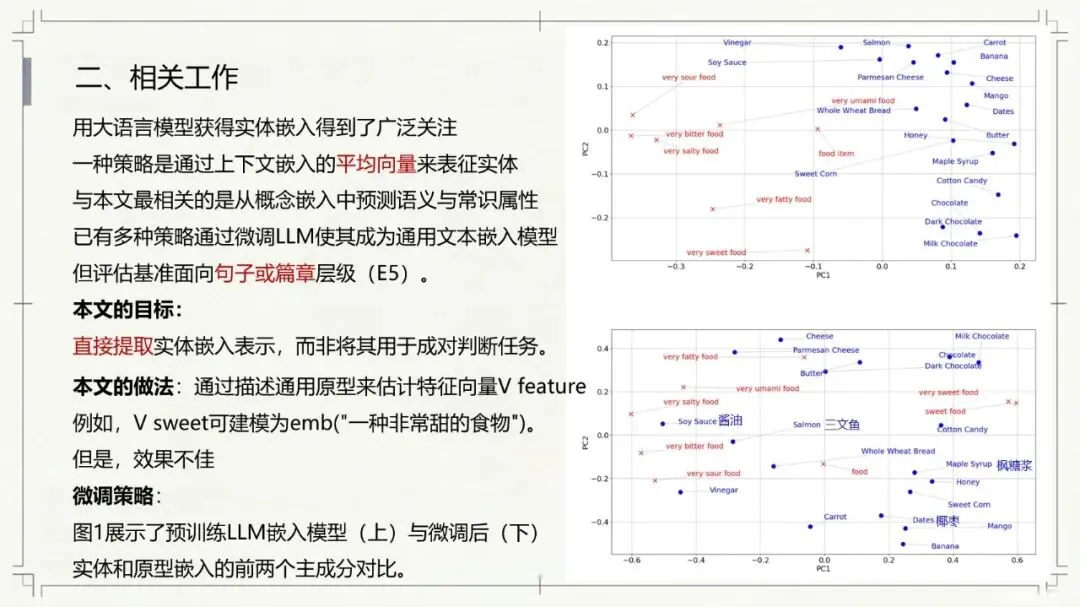
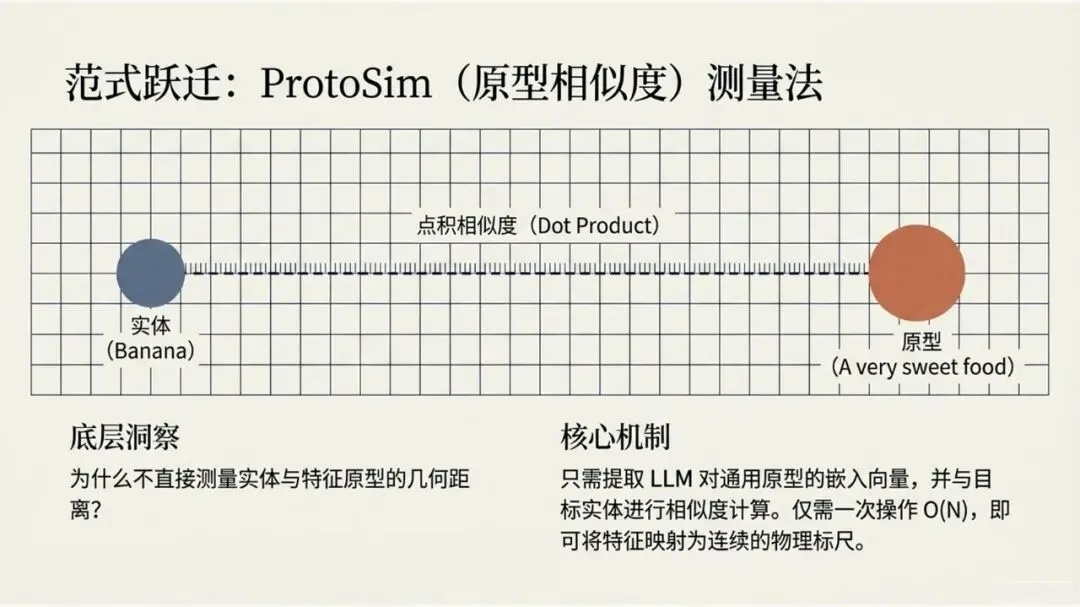
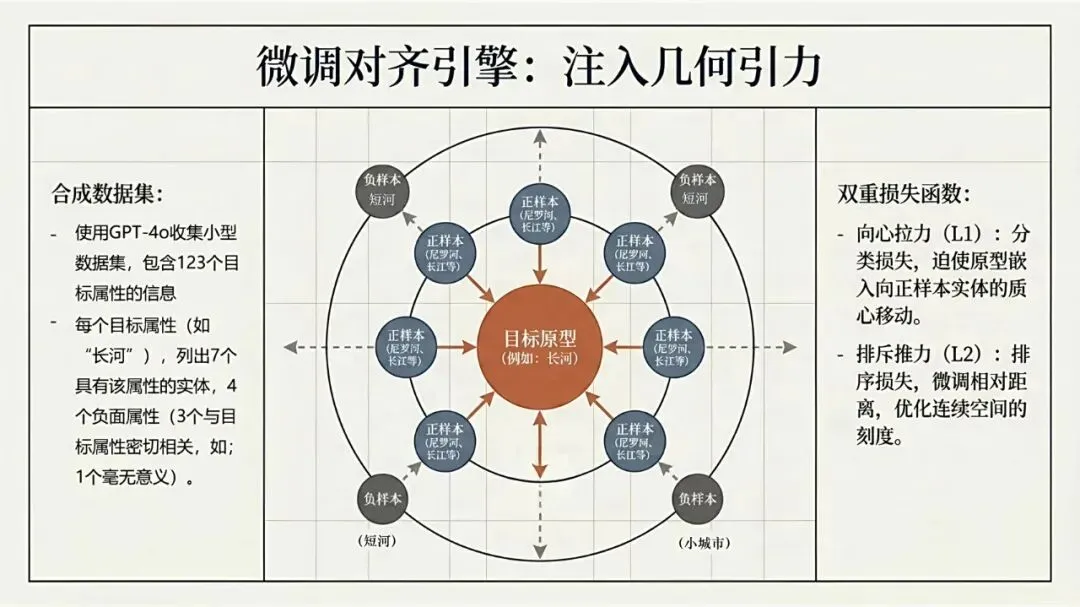
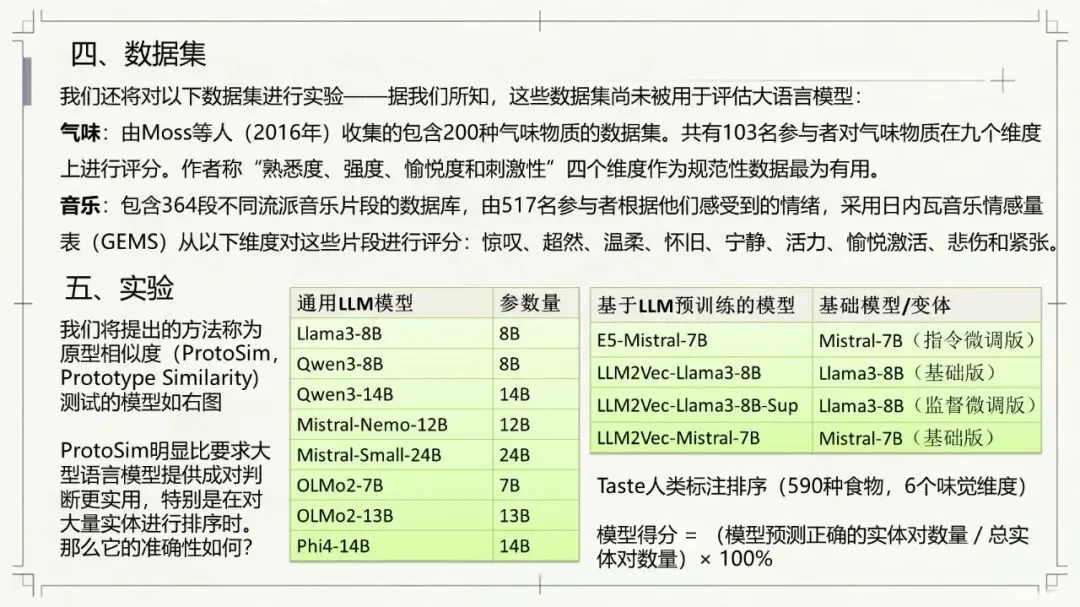
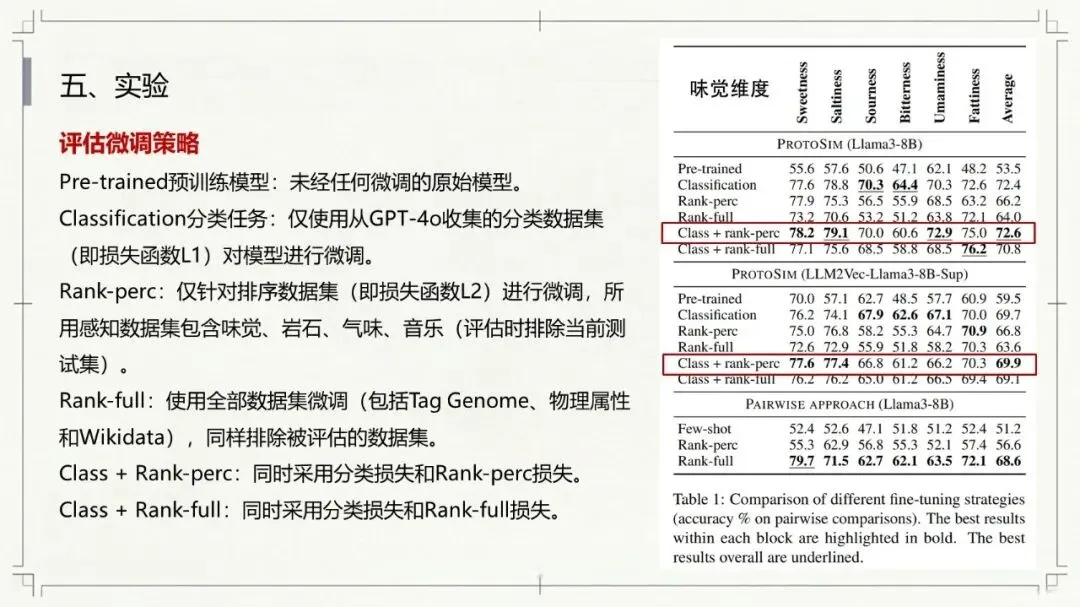
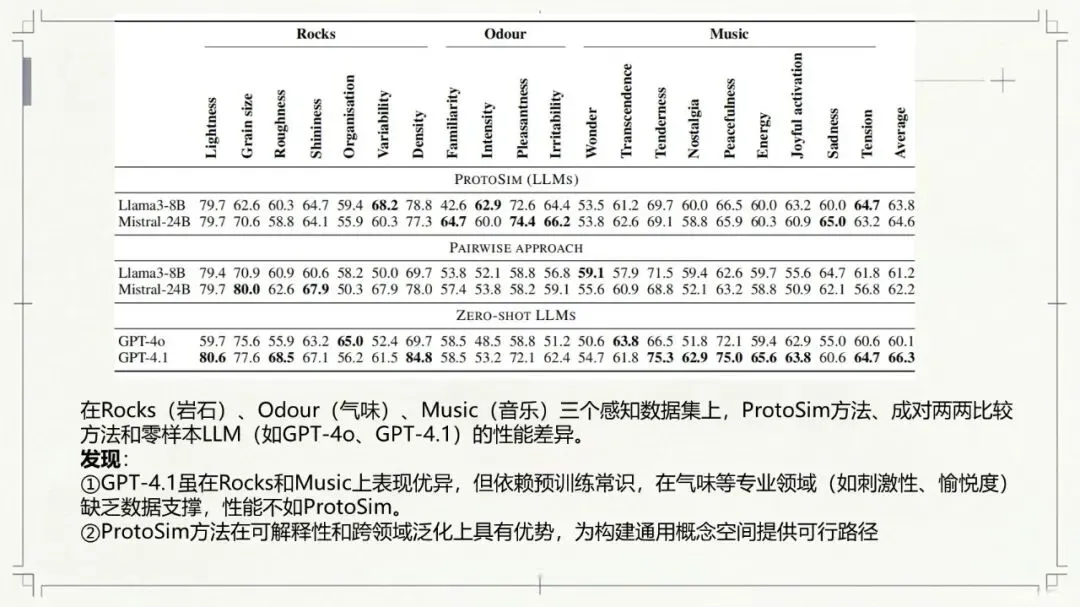
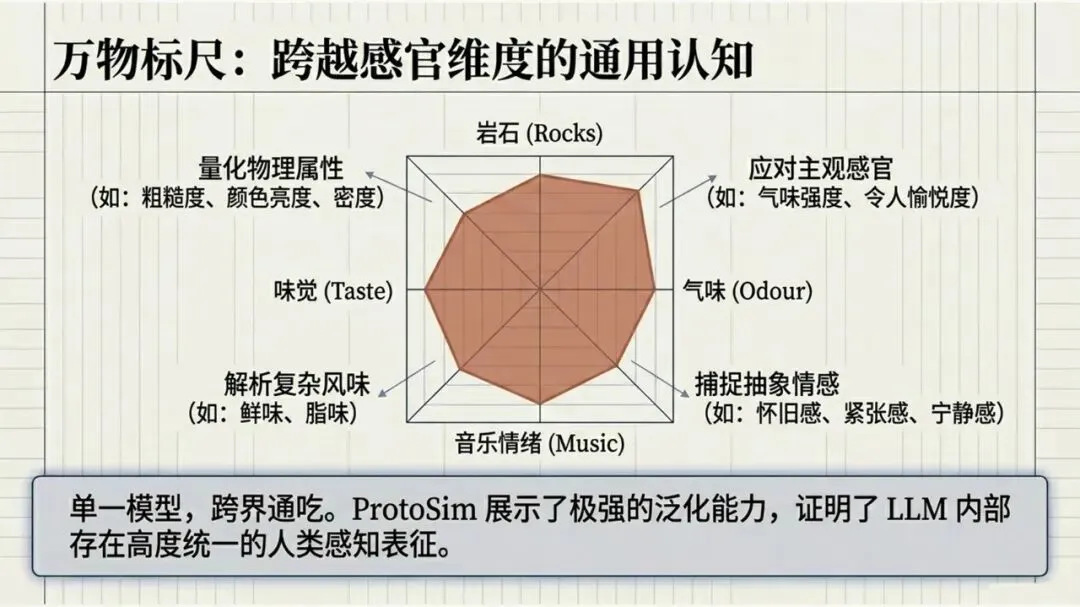
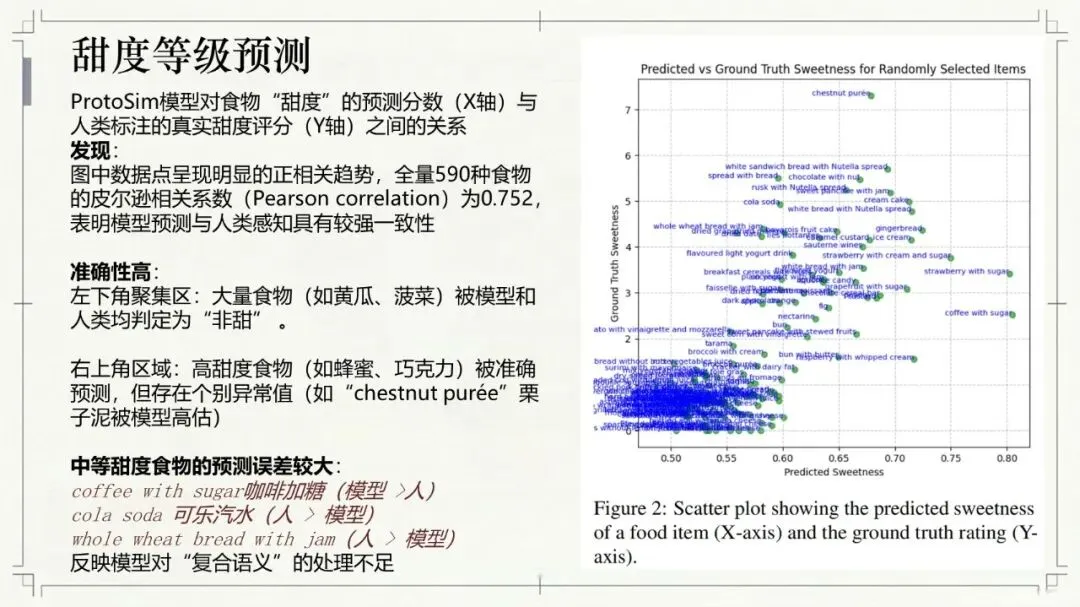
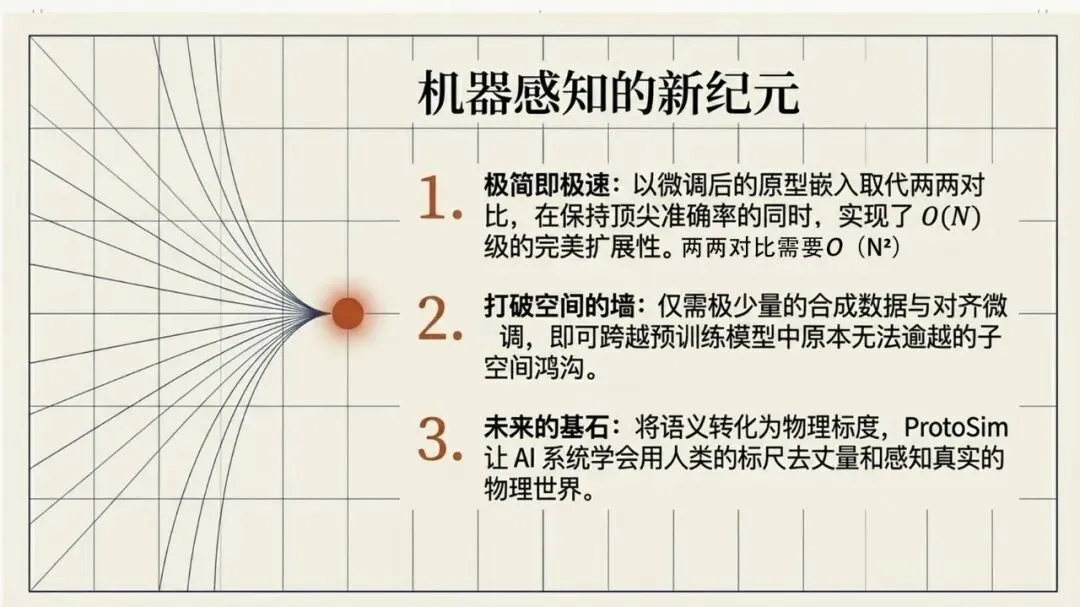
Kumar, N., Chatterjee, U., & Schockaert, S. (2025). Extracting conceptual spaces from LLMs using prototype embeddings. In C. Christodoulopoulos, T. Chakraborty, C. Rose, & V. Peng (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2025 (pp. 9275-9298). Association for Computational Linguistics. Kumar等(2026)这篇论文探讨了如何让大语言模型(LLM)“理解”并量化一些抽象、主观的感知特征,比如食物的甜度、气味的强烈程度、音乐的忧伤感等。下面是对该文的介绍。让AI学会“品甜”、“闻香”、“听曲”:如何从大语言模型中提取概念空间 AI能不能像人一样,判断出“香蕉比黄瓜甜”,或者“钢琴曲比电钻声更悦耳”?这不仅仅是让AI认识这些词汇,而是让它理解背后的感知维度——比如甜度、明亮度、愉悦感。在认知科学里,这种用几何空间来表示概念和实体之间关系的方法,被称为“概念空间”。简单说,就是把香蕉、苹果、蛋糕这些实体,放进一个多维度的坐标系里,每个维度代表一个感知特征(比如甜度、脆度)。 这个概念听起来很有意思,而且在“可解释AI”里很有用——如果AI能告诉你它判断“香蕉很甜”的依据是“甜度坐标”有多高,那它的决策过程就透明多了。但问题来了:怎么给AI建立这样的概念空间? 传统的做法是让真人做海量的两两比较(比如“香蕉和苹果哪个更甜?”),但这种方式太慢、太贵、根本没法大规模应用。一个大胆的念头:让LLM自己来 近几年,大语言模型(比如GPT-4、Llama)展现出了惊人的“常识”和“感知模拟能力”。比如你问它“香蕉和黄瓜哪个更甜?”,它能给出合理的答案。但如果你要它为成千上万的食物排一个“甜度排行榜”,你总不能一个个问吧?那会累死API接口的。 于是,论文的作者们提出了一个更聪明的思路:能不能直接从LLM生成的“实体嵌入”(也就是实体在LLM内心世界里的“数字画像”)中,读出它的感知属性? 换句话说,能不能找到一个方向向量,用它和“香蕉”的嵌入做点积运算,结果就直接等于香蕉的“甜度值”?这样,我们就不用再问LLM“哪个更甜”,而是直接“算”出来。原型嵌入:用“极致代表”定义特征 那么,怎么找到这个神奇的方向向量呢?一个很自然的想法是:把特征描述本身也变成一个嵌入。比如,想衡量“甜度”,我们就构建一个短语——“一种非常甜的食物”(称为“原型描述”)。然后,把这个短语也输入LLM,得到一个“原型嵌入”。最后,我们假设:某个实体(比如“香蕉”)的嵌入,与这个“甜味原型”的嵌入越相似,那它就越甜。 这个思路直觉上很美好,但实际操作时却碰了壁。预训练的LLM有个“小bug”:实体(如“香蕉”)的嵌入和原型描述(如“一种非常甜的食物”)的嵌入,不在同一个“语义子空间”里。打个比方,就像你用“米尺”量身高,却用“公斤秤”称体重——两者根本对不上。论文中Figure 1(图一律请见本文最后所附,后同)很直观地展示了这一点:在预训练模型里,实体和原型的点分布在两个不同的簇里。微调:给LLM的“嵌入空间”校准一下 为了解决这个“子空间不匹配”的问题,研究者们采取了一个巧妙的办法:对LLM进行微调。他们用GPT-4o(一个更强大的模型)自动生成了一个小型的训练数据集。这个数据集包含123个属性,每个属性对应7个正例(符合该属性的实体)和4个负例(不符合的)。例如,对于“长河流”这个属性,正例有“尼罗河、亚马逊河、长江……”;负例有“短河流、干涸河流、小城市……”(注意“小城市”和河流完全不搭,用来防止模型学偏)。 然后,他们设计了一个分类损失函数,目标就是让“原型嵌入”和它对应的7个正例实体的“平均嵌入”尽可能接近,同时远离那4个负例。这就好比是让LLM学习一个“对齐规则”:以后你说“非常甜的食物”这个原型,它的嵌入就应该和“糖、蜂蜜、蛋糕”这些真实甜食的嵌入靠近。 此外,他们还加了一个排序损失函数,目的是让模型学会正确的相对顺序(比如“香蕉”的甜度嵌入应该大于“黄瓜”的)。最终,模型的总体损失就是这两个损失的加权和。经过这样一番“定向培养”,LLM终于能把实体和原型放在同一个“概念空间”里愉快地比较了(见Figure 1的下半部分)。效果如何?不仅不差,甚至更好 为了验证这个名为ProtoSim(原型相似度)的方法到底行不行,作者们在多个数据集上进行了“盲测”。他们让模型预测不同实体的感知属性值(比如甜度、咸度、苦度、音乐的悲伤感等),然后和真人给出的评分做对比,看排序的一致性(准确率)。 结果令人满意: ProtoSim表现优异:在很多维度上,ProtoSim的准确率超过了70%,甚至80%,尤其在“甜度”、“咸度”这些比较明显的感知维度上。 比“两两比较法”更实用且性能相当:之前的方法(一个个问“哪个更甜”)虽然准确率也不错,但计算成本高得离谱。而ProtoSim只需要一次嵌入计算,就能得出所有实体的分数,效率呈指数级提升。最关键的是,在多个数据集(如食物味道、音乐情感)上,ProtoSim的平均表现超越了这种缓慢的两两比较法。 微调是关键:如果不做微调,直接拿预训练模型算相似度,准确率只有可怜的50%多(相当于瞎猜)。而加入那个小型的分类数据集后,准确率一下子飙升到72%以上。这证明“对齐空间”这一步是神来之笔。 模型大小不是唯一:有意思的是,并不是模型越大效果越好。在某些任务上,8B参数的Llama3居然比24B的Mistral表现还好。这可能说明,对于感知特征,模型的“对齐能力”比纯粹的参数规模更重要。不只能排序,还能打分:从“谁更甜”到“甜度几分” ProtoSim还有一个隐藏技能:它不仅能给出排序,还能输出一个连续的具体数值(实体嵌入和原型嵌入的点积)。这个数值可以被直接解释为“甜度分数”。论文里展示了一个散点图(Figure 2),横坐标是模型预测的甜度,纵坐标是真人评分的甜度(来自590种食物)。结果发现,两者呈现出明显的正相关(皮尔逊相关系数高达0.752)。也就是说,模型不仅仅知道“香蕉比黄瓜甜”,它甚至能给香蕉打个“7.8分甜度”(假设满分为10)。当然,对于一些“中间态”食物(比如“加糖的咖啡”),模型有时也会“走眼”,但总体上相当靠谱。存在的不足:不擅长“否定”,也会“望文生义” 任何研究都有局限性,这篇也不例外。作者们通过一个“食谱推荐”任务做了定性分析,发现ProtoSim有几个“软肋”: “抓不住重点”:有时候模型会过于关注查询中的某一个词,而忽略了整体。比如问“富含抗氧化剂的沙拉”,模型却推荐了“富含维生素的奶昔”——它只看到了“抗氧化剂”和“维生素”的关联,忘了“沙拉”和“奶昔”的区别。 “太吃文字表面意思”:如果查询和选项有大量相同的词(比如“糙米甜点”),模型会倾向于选择包含“糙米”的选项,即使那个选项根本不是甜点(比如“糙米蘑菇饭”)。它被“词袋”迷惑了,没有真正理解语义。 “不懂否定词”:当查询中出现“不含……”时,模型基本就懵了。例如,“不含蔓越莓酱的感恩节晚餐”,它还是会正儿八经地推荐“火鸡配甜蔓越莓酱”。对于“无乳糖”、“不油腻”这类否定约束,它目前还很难从嵌入相似度中捕捉到。总结:一条通往“可解释AI”的捷径 总的来说,这篇论文展示了一条非常实用的路径:我们不需要让LLM不厌其烦地回答无数个“哪个更X”的问题,而是可以通过“原型描述”和一个轻量级的微调,直接把LLM内部的知识蒸馏成一个结构清晰、维度可解释的“概念空间”。这样一来,我们不仅获得了实体的感知属性评分,效率还更高。虽然它目前还不太擅长处理否定和复杂的组合条件,但作为一项基础方法,它已经证明了自身的价值。未来,如果能结合线性映射或更好的否定处理机制,这种方法很可能成为AI理解人类主观感知世界的一把利器。原文链接:https://arxiv.org/pdf/2509.19269
关注“语言实验与计算”公众号,获取更多开放、共享资源!
更多资源请访问“语言实验与计算”交叉科学实验室官方网站!
基本文件流程错误SQL调试
请求信息 : 2026-06-17 00:14:43 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/755170.html
 夜雨聆风
夜雨聆风