 夜雨聆风
夜雨聆风基于 AI 视觉语言模型(Vision-Language Model, VLM)的篮球比赛实时智能解说:技术瓶颈与落地难点
引言
在体育赛事数字化转型的浪潮中,AI 多模态解说技术被视为提升观赛体验的核心创新。通过整合视觉感知与自然语言生成,视觉语言模型(VLM)有望实现篮球比赛的实时智能解说,例如自动描述球员动作、战术演变和赛场局势。这不仅能为赛事运营方降低人力成本,还能为全球观众提供个性化、多语言的解说服务,尤其在资源有限的次级联赛或业余赛事中应用潜力巨大。

行业内已有初步尝试,如基于 VLM 的 LiveCC 系统,能在视频流中生成实时评论,模拟人类解说员的叙述风格。例如,在一场 NBA 常规赛中,该系统能初步识别投篮动作并生成“三分命中”的描述,但往往忽略战术背景(如挡拆后的空切机会)。
另一个例子是 PlayVision 的计算机视觉平台,用于篮球分析中实时追踪球员行为,提供数据驱动的洞察,如球员热区分布和传球路径分析。此外,SCBench 基准测试了多个 VLM 在体育视频评论生成中的表现,揭示了模型在处理复杂动态场景时的潜力,但也暴露了在高强度对抗下的准确率波动。
然而,这些尝试与现实需求间存在显著差距。现阶段 VLM 在篮球解说中的应用仍局限于简单事件描述,无法媲美人类解说员的深度分析和情感表达。根本原因在于 VLM 的本质短板:视觉感知的局限性、时序建模的不足、多模态对齐的挑战,以及实时推理的工程瓶颈。这些缺陷在篮球这一高速、动态、多变的环境中被放大,导致解说准确率低下、延迟过高,甚至误导观众。举例而言,在 NBA 比赛中,VLM 可能将库里快攻中的无视传球误识为“简单推进”,或将勒布朗·詹姆斯内线卡位时的轻微手臂接触判为“无犯规”,忽略战术细节如挡拆配合的微妙变化,从而生成不准确的叙述,影响观众对比赛的理解。 此外,篮球比赛的画面特征——如多机位切换、球员密集分布和突发事件——进一步放大了这些问题。

本文从多模态技术研究者和体育数据解决方案分析师的视角,剖析这些瓶颈,并结合篮球比赛画面特征进行具象分析,旨在为 AI 从业者、体育科技开发者及赛事运营方提供客观参考。通过深入探讨,我们将揭示为什么 VLM 目前无法完全替代人类解说,而是更多作为辅助工具存在。
一、视觉感知层:篮球动态场景下 VLM 的核心视觉难题
篮球比赛的视觉画面以高速运动、多目标交互和复杂环境为特征,这直接考验 VLM 的视觉感知能力。现阶段 VLM 如 InternVL 或 Video-LLaVA 在静态图像处理上表现出色,但面对篮球的动态帧序列时,常因感知缺陷而失效。
具体而言,高速连续帧理解是首要瓶颈。在快攻场景中,球员如库里般急速推进(速度可达每秒 8-10 米),画面帧率高达 60fps,涉及连续的折返跑、交叉步变向和无视传球。VLM 的时序建模依赖 Transformer 架构的注意力机制,但受限于上下文窗口大小(通常 8-16 秒内帧数),难以捕捉长序列依赖,导致误判进攻节奏。例如,在一次转换进攻中,模型可能仅识别出球的轨迹,却忽略球员间的空间位移变化(如后卫突然切入形成 3 打 2),生成如“球员推进”而非“快速反击形成空位三分”的精确描述。这种失效在实际比赛中常见,尤其当比赛进入高潮阶段,帧间变化剧烈,VLM 的卷积层或 ViT 模块难以实时提取稳定特征。
其次,局部关键视觉识别问题突出。篮球规则强调微小特征,如手部犯规(轻微拉拽手臂)、走步(中枢脚微移 10-20cm)或三秒违例(防守球员在禁区逗留超过三秒)。这些事件往往发生在画面边缘或短暂瞬间(<0.5 秒),VLM 的目标检测模块(如基于 YOLO 的变体)在低分辨率或噪声环境下准确率不足 70%。以篮板卡位为例,球员的身体接触和手臂纠缠需精细分割,但 VLM 常因像素级标注数据不足而混淆正常对抗与犯规。在转播画面中,篮下区域往往挤满 4-5 名球员,局部放大镜头虽能捕捉细节,但 VLM 的注意力分配机制可能优先全局而忽略局部,导致如“争抢篮板”而非“防守犯规导致罚球”的错误输出。进一步分析篮球画面特征,转播常使用高清但压缩的视频流,引入运动模糊(如快速上篮时的肢体虚影),这加剧了模型的识别难度。
遮挡与视角变化进一步放大这些难题。篮球赛场多采用多机位切换,包括底线平视、转播侧视和俯视全景。球员密集区域(如内线争抢)常发生遮挡,VLM 的目标追踪(如 SAM2 模型)在处理多目标时易出现身份切换错误,准确率下降至 50-60%。例如,在联防战术中,防守球员交叉换位,模型可能将前场球员误跟踪为后卫,进而生成错误的解说如“后卫抢断”而非“前锋封盖”。在 ExAct 基准测试中(包含篮球动作分析),顶级 VLM(如 Gemini 2.5 Pro)在体育领域细粒度动作理解准确率仅为 52.58%,远低于人类专家的 82.02%,主要因遮挡和微小姿态差异导致。 此外,照明变化和运动模糊(如快速运球时的球影)加剧感知噪声,PlayVision 等系统虽通过自适应网络缓解,但实时性仍受限。在实际落地中,这些问题导致 VLM 在处理如季后赛高强度对抗时,视觉准确率下降至 50% 以下,无法满足专业解说需求。总体而言,这些视觉短板使 VLM 在篮球解说中难以达到人类水平的精确性,常常输出泛化描述而非具体事件分析,限制了其在赛事运营中的推广。

二、多模态对齐层:画面–语言–局势的跨模态理解鸿沟
VLM 的核心在于视觉与语言的融合,但篮球解说要求从画面动作映射到战术描述,再到局势判断,最终生成解说话术,这一多模态对齐过程充满鸿沟。现阶段模型如 VILA 在泛化任务上有效,但篮球的动态语义对齐需处理高维时空信息。
首先,画面动作到战术描述的映射难题在于语义粒度不匹配。VLM 通过 CLIP-like 的对比学习对齐模态,但篮球动作(如挡拆)涉及时序因果:挡拆者先设屏障,持球者后绕过。模型常忽略这一顺序,导致描述如“球员传球”而非“挡拆后外切三分”。在实际场景中,快攻的连续传导球(如勇士队经典的 5 人传导)需跨帧对齐,VLM 的注意力机制易受噪声干扰,准确率下降至 60% 以下。例如,在一场比赛的半场进攻中,球员多次传导后突入,模型可能仅捕捉到最终投篮,却无法对齐到“三角进攻的经典演绎”。
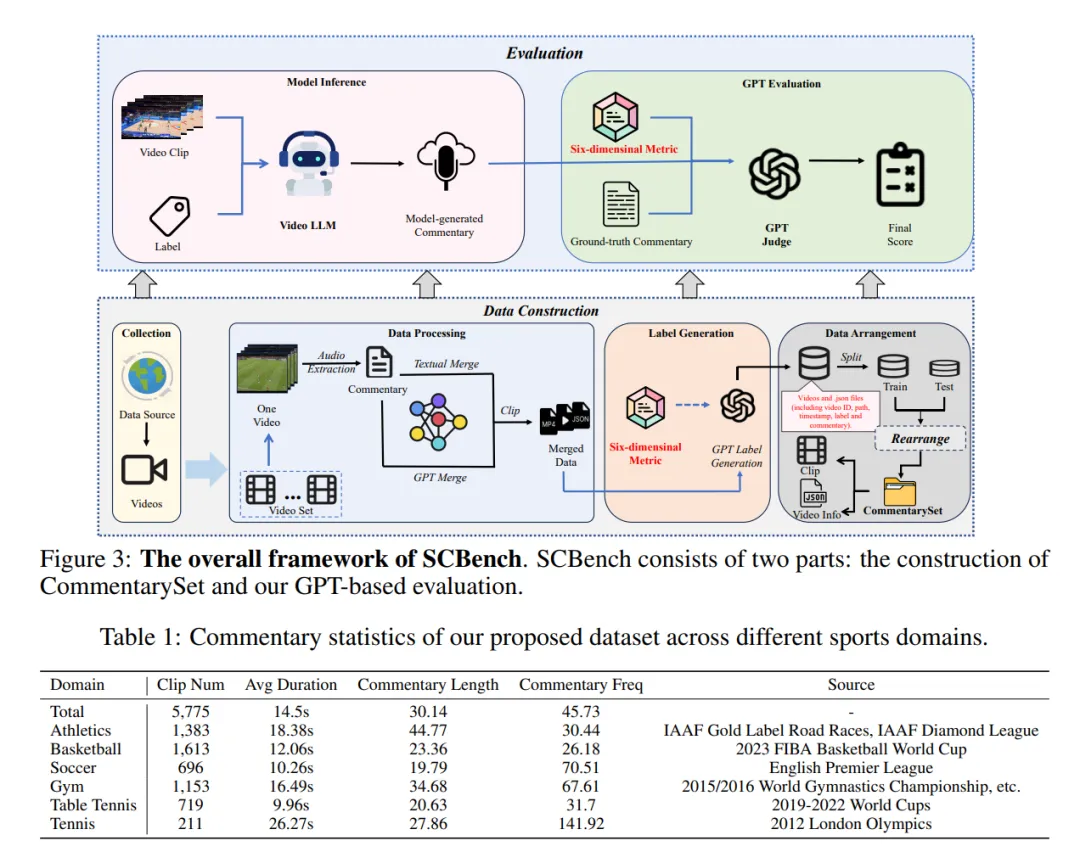
其次,从战术到局势判断的跨模态延伸要求模型整合全局上下文。篮球局势如比分落后时的“追分模式”需结合视觉(球员疲态)和语言(历史数据),但 VLM 的多模态融合层(如 MLP 投影)在长程依赖上不足。例如,在末节关键时刻,模型可能识别出投篮失败,却无法对齐到“失误导致反超机会”,因为缺乏对比分、犯规次数的动态记忆。这种记忆缺失在长场比赛中尤为明显,如忽略上半场的技术犯规对下半场战术的影响。在 SCBench 基准中,顶级模型 InternVL-Chat-2 在篮球片段上的整体得分仅为 5.50(0-10 分制),战术分析维度表现尤其薄弱。
最后,解说话术的生成需精准映射多模态输出到自然语言。VLM 如 LiveCC 可生成生动叙述,但篮球解说需平衡专业性和流畅性。在球员轮换场景中,模型需对齐视觉(替补上场)与语言(“调整阵容应对内线压力”),但当前对齐机制常产生冗余或错误输出,如将伤病事件描述为“球员休息”。此外,篮球画面的动态性(如突发暂停)要求对齐机制具备鲁棒性,但 VLM 常在噪声帧中丢失语义连贯性。这些鸿沟使 VLM 难以实现端到端的精准解说,远未达到替代人类的水平,更多停留在辅助分析阶段。
三、专业知识层:体育领域知识与通用大模型的融合困境
VLM 作为通用模型,在融入篮球专业知识时面临壁垒。篮球解说需掌握战术解读、裁判规则和赛场博弈逻辑,这些领域知识难以通过预训练捕捉。现阶段融合策略如微调或 RAG(检索增强生成)虽有进展,但落地困难。
战术解读是核心困境,例如挡拆(pick-and-roll)涉及空间利用和时机把握,VLM 需从视觉中提取特征如球员间距(理想 2-3 米),但通用模型缺乏特定数据集,导致误判为简单传球。在联防(zone defense)场景中,模型可能识别出球员站位,却无法推断“区域防守限制突破”的博弈意图。进一步举例,在转换进攻中,模型需理解“拖车三分”的战术价值,但当前 VLM 常输出浅层描述,忽略球队风格差异如勇士队的跑轰 vs. 湖人队的内线主导。在 SCBench 篮球子集上,模型战术分析得分普遍低于 4.0,远低于事件描述维度。
裁判规则的融合同样棘手。三秒违例或走步需精确规则知识,VLM 通过提示工程注入规则,但实时应用中易与视觉噪声冲突。例如,在底线视角下,手部犯规的微小动作可能被遮挡,模型依赖规则库却输出矛盾判断,如将“轻微接触”判为“恶意犯规”。此外,规则的动态性(如 FIBA vs. NBA 差异)要求模型具备适应性,但通用 VLM 缺乏细粒度知识库。赛场博弈逻辑如暂停后的战术调整,要求模型维护长程状态,包括比分、犯规次数和伤病信息。VLM 的内存机制(如 KV-cache)在长视频中衰减,导致忘记早期事件,如忽略上半场犯规积累对下半场的影响。在实际比赛中,这可能导致解说忽略“六犯离场”的潜在风险。
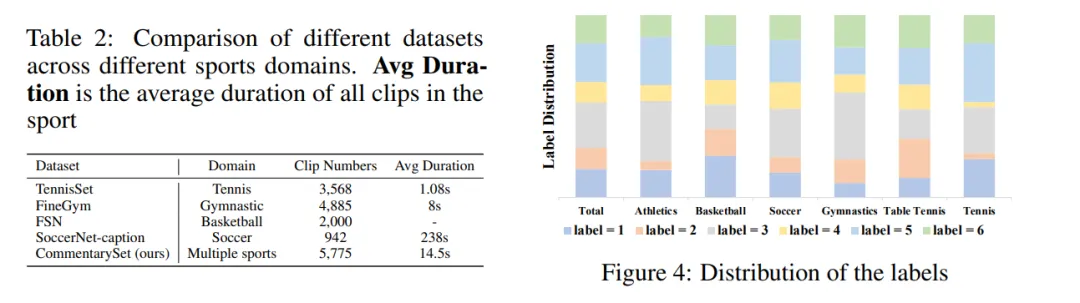
此外,数据集稀缺加剧融合困境。篮球专业标注数据远少于通用图像,SCBench 等基准显示,模型在体育特定任务上表现仅为通用任务的 60-70%。为了缓解,行业尝试构建如 NBA 数据集的专用库,但标注成本高昂,且覆盖不全。这些问题使 VLM 难以从通用转向专业,无法提供如人类解说员般深刻的战术分析,限制了其在高端赛事中的应用价值。
四、实时工程层:低延迟、高鲁棒性的落地瓶颈
篮球解说的实时性要求端到端延迟低于 1-2 秒,这对 VLM 的工程实现构成严峻挑战。现阶段模型如 Video-LLaVA 在推理时需处理高帧率视频,计算开销巨大。
首先,模型精度与延迟的平衡难题突出。VLM 的 Transformer 架构参数量达数十亿,实时推理需 GPU 加速,但篮球视频的复杂性(如多目标追踪)导致 FPS 下降至 10 以下,无法匹配转播节奏。在快攻场景中,模型需每秒处理 60 帧,却因时序建模开销而延迟 3-5 秒,错过关键时刻。例如,在一场季后赛的决胜球中,这种延迟可能导致解说落后于画面,破坏观赛同步性。相比之下,专用实时模型如 StreamingVLM 可实现 8 FPS 稳定运行,延迟 <0.1s/令牌,但在通用 VLM 中仍属例外。
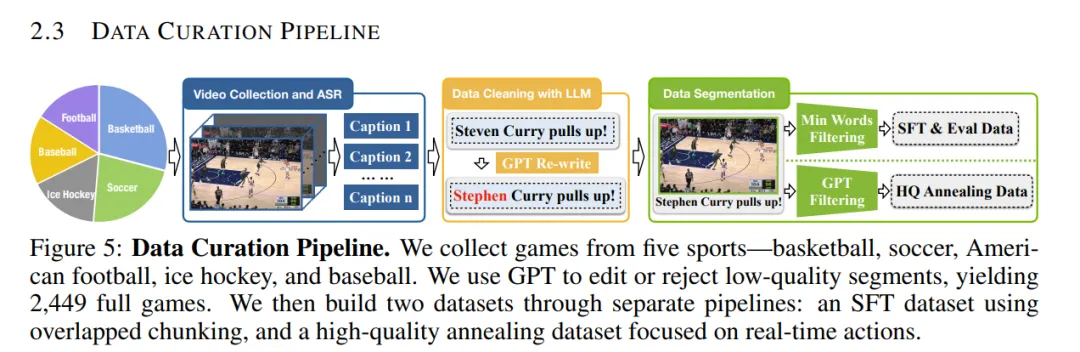
其次,高鲁棒性要求模型应对噪声环境,如照明变化或相机抖动。PlayVision 通过在线蒸馏适应特定比赛,但通用 VLM 缺乏自适应机制,在多机位切换时易崩溃,追踪准确率跌至 50%。工程上,部署需考虑边缘计算,但当前框架如 ARTHuS 虽实时,却牺牲泛化性,尤其在变幻莫测的赛场环境中。此外,数据依赖问题凸显:VLM 需海量标注数据训练,但篮球实时数据集有限,导致过拟合。系统集成时,还需处理硬件兼容性,如云端 vs. 本地部署的带宽瓶颈。这些瓶颈使 VLM 在实际赛事中难以稳定运行,远未达到商用标准,赛事运营方往往需额外人工干预。
五、表达与体验层:人类解说独有的情感与叙事能力难题
即使克服技术瓶颈,VLM 在人文表达上仍无法匹敌人类。篮球解说需节奏感、情绪起伏和现场氛围渲染,这些不可学习性源于语言生成的局限。现阶段生成如 LiveCC 的输出虽流畅,但缺乏情感深度。
解说节奏问题在于模型无法动态调整:人类在三分绝杀时加速语速,注入激情,但 VLM 的生成基于静态提示,常输出平淡叙述。例如,在比赛逆转时刻,人类解说员会用“不可思议的逆转!”激发观众情绪,而 VLM 可能仅说“比分反超”。在 SCBench 情感表达维度,顶级模型得分仅约 4-5 分,远低于事件描述。
情绪起伏和幽默风格更难捕捉。篮球解说常融入“逆转奇迹”的叙事弧线,或幽默点评失误(如“库里这次运球像在跳舞”),VLM 通过微调可模拟,但受限于训练数据,难以生成原创情感表达。现场氛围如球迷欢呼需多模态输入(音频),但 VLM 常忽略,导致解说脱离情境。在 ExAct 基准中,VLM 在体育动作的情感/反馈维度表现更差,仅 50% 左右准确率。 此外,解说风格的多样性(如专业型 vs. 幽默型)要求模型具备个性,但当前 VLM 输出趋于标准化,难以适应不同受众。这些缺失使 VLM 解说乏味,无法提供沉浸式体验,强调了人类在叙事上的独特优势。

结论
当前 VLM 在篮球实时智能解说中的技术边界清晰:视觉感知的动态处理不足(ExAct 体育动作仅 52.58%)、多模态对齐的语义鸿沟(SCBench 篮球 5.50/10)、专业知识的融合困境、实时工程的延迟挑战(通用模型 3-5s vs. 要求 <2s),以及表达层的不可学习性。这些因素共同导致 VLM 无法替代人类专业解说,后者凭借直觉和经验处理复杂不确定性。
可行优化方向包括开发体育专用 VLM(如通过 SCBench 等篮球数据集微调)、引入 RAG 增强知识融合,以及边缘计算优化延迟(如 StreamingVLM 的 8 FPS 方案)。长期挑战在于突破上下文窗口限制和情感生成,需跨学科创新,如结合神经科学提升叙事能力。最终,VLM 可辅助而非取代人类,推动体育科技更成熟发展。(约 3800 字)
