 夜雨聆风
夜雨聆风



01 AI蛋白质设计最新前沿实站应用
02 AI+多肽设计实战应用
03 AI+抗体设计实战应用
04 AI+基因编辑实战应用
05 AI构建虚拟细胞实战应用
06 人工智能驱动的计算免疫学实战应用
07 AI智能体驱动生物医学实战应用

②报二送一(同时报名两个直播课免费赠送一个学习名额赠送课任选)
③报名学习课程可赠送往期课程回放(报多少赠双倍)
(可点击跳转详情链接):



一、蛋白质相关的深度学习简介
1. 基础概念
1.1. 机器学习简介:从手写数字识别到大语言模型
1.2. 蛋白质结构预测与设计回顾
1.3. Linux简介
1.4. 代码环境:VS code和Jupyter notebook*
1.5. Python关键概念介绍*
2. 常用的分析/可视化蛋白质及相关分子的方法
2.1. 常用数据库与同源序列搜索和MSA构建
2.2. 使用pymol和Mol*可视化蛋白质结构*
2.3. 使用biopython与biotite分析生物序列与结构数据*
2.4. 使用fpocket与point-site分析蛋白质结构口袋*

3. 深度学习蛋白质设计与传统蛋白质设计之间的差异
3.1. 深度学习的本质
3.2. 传统方法:全原子能量函数Rosetta与统计势
3.3. 深度学习:几何深度学习
3.4. 深度学习与传统的物理方法的互补性
3.5. 深度学习蛋白质设计的优越性

4. 蛋白质语言模型
4.1. 语言模型:从RNN到Transformers
4.2. 理解蛋白质语言
4.3. 生成式蛋白质语言模型
4.4. 结构模型与语言模型的比较分析
5. 基于深度学习的蛋白质功能与性质预测
5.1. 蛋白质功能分类预测*
5.2. 信号肽、跨膜区、亚细胞定位预测
5.3. 蛋白质同源结构搜索
5.4. 酶活性位点预测

二、深度学习与蛋白质结构预测
1. 前深度学习时代的蛋白质(复合物)结构预测
1.1 基于同源性的建模:Swiss-Model,MODELLER,I-TASSER
1.2 基于折叠匹配的预测:Phyre2,RaptorX,HHpred
1.3 基于分子动力学的从头折叠:Rosetta ab initio,QUARK
1.4 蛋白小分子间的分子对接:AutoDock Vina

2. 深度学习方法用于蛋白质结构预测
2.1 RaptorX-Contact:将ResNet用于MSA
2.2 AlphaFold2:几乎解决了蛋白结构预测问题
2.3 AlphaFold3:引入扩散模型
2.4 ESMFold:语言模型与结构预测的融合

3. AlphaFold2 原理回顾
3.1从共进化到结构
3.2注意力机制
3.3 EvoFormer
3.4 Structural Module
4. AlphaFold3 介绍
4.1 扩散模型
4.2 训练数据
4.3 AlphaFold3 的成绩与不足,与AF2的差异
4.4 AF3的竞争对手们:Chai-1&2,Boltz-1&2

5. AlphaFold2/3 实际操作与结果分析
5.1 AlphaFold2&AF-multimer实操*
5.2 AlphaFold2各指标介绍,结果分析*
5.3 AlphaFold server使用*
5.4 本地版的AlphaFold3*
5.5 AlphaFold3结果分析*
6. ESMFold
6.1 ESM2:蛋白质语言模型能力的涌现
6.2从ESM2到ESMfold
6.3 ESMFold使用*
三、固定主链蛋白质序列设计
1. 传统的蛋白质序列设计
1.1 基于全原子力场的RosettaDesign*
1.2 基于统计势的ABACUS

2 融入结构知识的语言模型设计蛋白质序列
2.1 ESM-IF原理介绍
2.2 ESM-IF的应用*
3 基于CNN的序列设计
3.1 CNN原理简介
3.2 DenseCPD设计方法
3.3 有侧链构象的设计方法

4 基于GNN设计序列
4.1 ProteinMPNN 的成功经验分析
4.2 ProteinMPNN 的广泛应用
4.3 ProteinMPNN 实际操作*
4.4 ProteinMPNN的衍生模型:LigandMPNN,SolubleMPNN,ThermoMPNN

5 其他的序列设计模型
5.1 ABACUS-R 简介与实际操作*
5.2 CarbonDesign 从结构预测来到序列设计去*
5.3 CARBonAra 环境感知的序列设计*
6 固定主链序列设计在功能蛋白设计中的应用
6.1 新骨架蛋白质表达量优化(Science文章复现)*
6.2 抗体亲和力优化(Science文章复现)*
6.3 结合进化信息的酶性质全方位优化(JACS文章复现)*

四、深度学习蛋白质结构设计
1. 传统思路回顾
1.1. 结构域拼接
1.2. SCUBA:无侧链的蛋白质力场
2. 基于蛋白质表面几何深度学习的binder设计
2.1. masif原理简介
2.2. masif用于识别蛋白表面的PPI热点
2.3. masif设计binder

3. 基于扩散模型的蛋白质骨架设计模型
3.1. FrameDiff:基于IPA的主链生成*
3.2. Chroma:等变图神经网络结构设计
3.3. RFDiffusion:基于RosettaFold的多任务设计(以及RFantibody)
3.4. RFDiffusion2&3:从骨架设计到全原子设计
3.5. 其他全原子蛋白设计模型简介(BindCraft/Boltzgen/HalluDesign)

4. 基于RFdiffusion的蛋白设计案例
4.1. 抗蛇毒中和蛋白的从头设计顶刊讲解(Nature-2025.1.15)

4.2. 构象依赖的细胞因子结合蛋白设计顶刊讲解(Nature-2025.8.13)

4.3. 钙离子通道蛋白的计算设计顶刊讲解(Nature-2025.10.22)

4.4. DNA结合蛋白设计顶刊讲解--2026最新

4.5. 靶向GPCR结合蛋白的生成式设计顶刊讲解-2026最新

5. 基于RFdiffusion3的功能蛋白设计
5.1. 基本流程介绍(表位选取,可设计性评估,结构生成)
5.2. 指定位点的结合蛋白设计
5.3. 核酸结合蛋白设计
5.4. 小分子结合蛋白设计
6. 基于RFdiffusion和RFDiffusion3的酶设计
6.1. Theozyme理论解释
6.2. 骨架生成策略
6.3. 活性位点设计与活性进化

五、酶设计与 AI 辅助酶改造
1酶设计基础
酶的结构与催化原理 活性中心、底物结合口袋、催化残基、过渡态稳定、构象变化;
区分“结合设计”和“催化设计”。
2传统与半理性酶改造
从理性设计到定向进化
理性设计、半理性设计、饱和/组合突变、library 设计、筛选/选择实验;活性、稳定性、选择性的 trade-off。
案例:一个野生型酶如何制定改造目标?
突变库设计草案
3结构生成模型
RFDiffusionAA 与小分子驱动设计
Diffusion 生成思想;
RFDiffusion 与 RFDiffusionAA 的差异;
围绕小分子、金属离子或辅因子生成结合蛋白/酶 scaffold。
4酶活性位点设计 Catalytic motif / active-site scaffolding
theozyme、催化几何约束、motif 固定、scaffold 生成;
结合 ProteinMPNN/LigandMPNN 做序列设计与侧链优化。
练习:定义催化残基和几何约束。 活性位点约束表
5.AI 辅助酶改造
EvolvePro 与 MultiEvolve PLM embedding、few-shot regression、主动学习;
单点突变预测、多点组合、epistasis 建模;减少实验轮次。
讨论:何时需要 DMS,何时只用小规模数据?
突变体排序与下一轮建议
6酶设计实操 从设计到筛选的完整示例
以 heme binder / ligand-centered design 为例:输入准备、约束设置、backbone 生成、序列设计、结构筛选、候选排序。
上机:运行或演示 RFDiffusionAA 类流程。 候选结构与筛选报告
实操 1 酶设计 从小分子/辅因子出发生成候选 protein scaffold,并做初筛。 ligand/辅因子结构、motif/约束、参考脚本 准备输入 → 生成 backbone → 序列设计 → 结构预测/筛选 → 候选排序 候选结构、筛选表、简短解释
实操 2 酶改造 用少量突变体数据模拟 EvolvePro/MultiEvolve 风格的主动学习。 WT 序列、突变列表、fitness/活性数据、PLM embedding 提取 embedding → 训练回归模型 → 预测突变体 → 选择下一轮候选 ranking 与下一轮实验建议
六、蛋白语言模型与基于语言模型的蛋白质设计
1. 语言模型基础 Transformer、BERT 与 GPT Self-attention、position encoding、encoder/decoder;MLM 与 autoregressive generation
2.自然语言模型到蛋白序列模型的迁移。
比较 MLM 与 next-token prediction。
2. 蛋白语言模型概览
3. 蛋白序列作为“生物语言”
氨基酸 token、序列 embedding、residue/sequence-level 表征;
PLM 如何学习进化、结构和功能约束。
讨论:PLM 学到的是语法还是适应度景观?
PLM 应用场景地图
4. ESM 系列模型
5. ESM-1/2、MSA Transformer、ESMFold、ESM-3、ESMFold2、
ESM-2 的 masked LM 表征;
MSA Transformer 的共进化信息;
ESMFold 的单序列结构预测;
ESM-3 的序列-结构-功能多模态生成;ESMFold2用ESMC表征
世界模型ESMFold2 操作上机-2026最新

比较:AF2、ESMFold、ESM3 的输入与输出。
ESM 模型对照表

6. 生成式蛋白语言模型 ProGen、ZymCTRL 与条件生成 Conditional tag、功能/家族条件控制、预训练+微调;ProGen 案例分析;

7. ymCTRL 用于酶序列生成。
8. 练习:设计条件生成 prompt/tag。
9. 条件生成实验设计
10. PLM 驱动的功能蛋白设计
11. 突变评分、微调与非自回归生成 零样本突变效应预测、embedding regression、有监督微调;ProteinGAN、DeepEvo、Prot-VAE、P450Diffusion;生成后评估。
12. 讨论:生成模型如何与实验筛选闭环?
13. 候选序列评估指标表
14.蛋白语言模型实操 ESM2/ESM3 上机与小项目整合 ESM2 embedding 提取、突变打分;ESM3 序列补全与结构生成;将 PLM embedding 接入酶改造预测模型。
上机:完成 WT vs mutant 的 PLM 评估或 ESM3 生成。


培训目标:
让学员系统掌握深度学习在蛋白质设计领域的技术体系、前沿模型与工程落地思路
吃透传统蛋白设计与 AI 方法的差异及互补逻辑。可独立完成蛋白质序列、结构、结合口袋的可视化与数据分析,学会AlphaFold2/3、ESMFold等结构预测模型,能运用 Rosetta、ABACUS 完成传统设计,熟练操作 ProteinMPNN、ESM-IF、DenseCPD 等深度学习模型开展序列设计、侧链优化与蛋白稳定性改造,并复现顶刊相关应用案例。熟练掌握扩散模型、图神经网络在蛋白骨架 / 全原子设计中的应用,可基于 RFDiffusion 系列、FrameDiff、Chroma 等模型实现结合蛋白、酶、核酸结合蛋白、靶向配体蛋白的从头设计,完成表位筛选、结构生成、可设计性评估与候选分子排序。理解酶设计与改造核心原理,能结合 Theoyzme 催化基序、几何约束完成酶骨架与活性位点设计,使用 EvolvePro 等工具结合主动学习、突变效应预测开展 AI 辅助酶改造,搭建突变库并完成方案设计。掌握ESM 系列、ProGen、ZymCTRL等蛋白质语言模型,理解模型架构与表征逻辑,可完成序列 Embedding 提取、零样本突变打分、条件序列生成、模型微调,并实现语言模型与结构模型、改造模型的联动使用。能够基于 GNN、CNN、几何深度学习搭建蛋白预测与设计模型,完成模型训练、效果调优,规避数据泄露、过拟合等常见问题。
上下滑动查看更多







培训目标:
让学员更好的知道当下蛋白质设计的核心热点以及优势能独立完成蛋白结构可视化:用 PyMOL 加载复合物、识别结合界面、测量相互作用、渲染高清结构图。能使用 ESM2 完成序列评分,用 PepMLM 实现靶标定向短肽生成,并通过 Python 完成数据清洗、筛选与可视化。能用 AF2/Multimer 预测肽 - 蛋白复合物结构,解读 pLDDT/ipTM/PAE 指标,完成界面分析与质量评估。能用 LigandMPNN 基于固定骨架优化短肽序列,结合多指标完成候选肽筛选与成药优化方案设计。建立AI 短肽设计完整思维闭环:靶点选择→候选生成→性质筛选→结构评估→优化验证。具备独立解决实操问题的能力,能合理解读 AI 预测结果、规避模型局限,输出可实验验证的短肽候选。掌握跨工具联用能力,实现 ESM2、PepMLM、AF2、LigandMPNN、PyMOL 的流程化配合使用。
上下滑动查看更多


第一天:代码基础,抗体基础,介绍各大药企在AI辅助抗体药物开发上的布局,复现GSK在抗体亲和力成熟上的工作
 1.代码基础知识讲解,环境搭建:Linux,VS code*
1.代码基础知识讲解,环境搭建:Linux,VS code*
a)超算的登录
b)Linux系统的常用shell命令:vim, ls, cd, less, rm等;
c)一些package安装的常用命令:pip, conda, source等。
d)VS code的基本配置:连接服务器;选择不同python版本的Interpreter;debug模式的使用等。
2.抗体基础知识讲解:
a)VDJ重排,germline,CDR区域,表位(epitope/paratope),抗体亲和力成熟,抗体的可开发性等概念介绍
b)不同抗体编号方案(Kabat,Chothia,IMGT)讲解,使用python自动化对抗体序列编号,并识别CDR区域*
c)抗体药物开发的基本流程
3.各大药企在AI辅助抗体药物开发上的布局:讲解各大药企公司发表的文献及报告:
a)Genetech的lab-in-the-loop,结合了实验和计算方法的迭代优化策略的工作b)Genmab手动建立了多样性的抗体可开发性数据集,以进行可开发性数据的训练和预测.
c)GSK、阿斯利康、诺和诺德等在抗体亲和力成熟上做的工作等。
4.抗体结构预测
1)通用蛋白结构预测模型:AlphaFold3。
u运行网页server上的AlphaFold3预测结构,https://alphafoldserver.com*
uAlphaFold3输出结果分析,各项置信度指标的含义,以及如何判断预测的准确度,如pLDDT,ipTM,PTM,PAE。
uAlphaFold3的安装过程讲解。
a)抗体专用结构预测模型:ImmuneBuilder,IgFold。实操如何在服务器安装和使用。
5.复现GSK在抗体亲和力成熟上的工作*
第二天:基于大语言模型的抗体亲和力成熟。
1.基础知识讲解
1)介绍蛋白质的语言模型(26字母语言模型->20氨基酸字母表,上下文依赖->氨基酸的共进化)
2)为什么要开发蛋白质大语言模型?
1. 相比于结构或功能信息,序列信息更加海量;
2. 蛋白质序列通过进化而来,可以学习蛋白质基本规律,折叠,共进化等
3)模型架构和基础理论:transformer,多头注意力机制,Bert,GPT,T5等
2.基于Bert架构的蛋白质语言模型
1)ESM系列(ESM-1b、ESM-1v、ESM2、ESM C)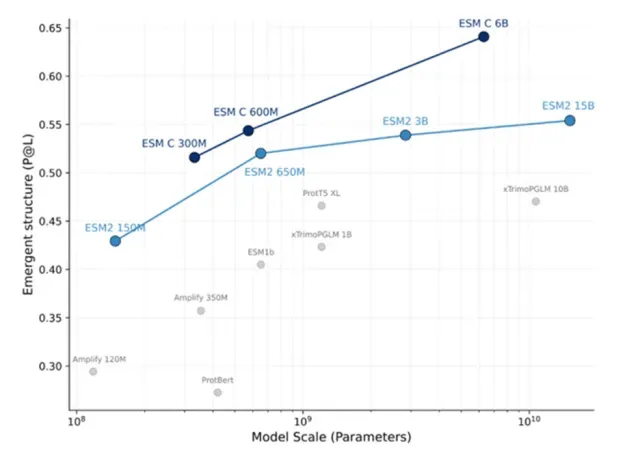 2)ESMFold:无需MSA信息的结构预测
2)ESMFold:无需MSA信息的结构预测
3)多模态的蛋白质语言模型ESM3
4)使用抗体序列库训练的语言模型:Ablang,AntiBERTy
3.Adaptyv EGFR Binder比赛——设计靶向EGFR的更高亲和力binder。1) 比赛结果展示
2)比赛排名靠前的抗体/蛋白是如何设计的
a)第一轮比赛,排名第一的方法:BindCraft
b)第二轮比赛,排名第一的方法:Cradle,在Cetuximab的基础上,用的LLM,突变了10个FR的氨基酸
c)第二轮比赛,排名第二的方法:对一个纳米抗体进行人源化改造
d)第二轮比赛,排名第三的方法:保留与结合重要的氨基酸,生成其它氨基酸RFdiffusion+inverse folding
4.零样本的抗体亲和力成熟*
1) Efficient evolution,基于序列的语言模型推荐突变点(Nat. Biotechnol.文章)
i.了解语言模型推荐突变点的原理;
ii.安装package和模型参数。https://github.com/brianhie/efficient-evolution
iii.运行以推荐突变点:python bin/recommend.py [sequence]
2)Structure evolution,基于结构的语言模型推荐突变点(Science文章)
i.了解inverse folding推荐突变点原理
ii.安装package和模型参数
1.git clonehttps://github.com/varun-shanker/structural-evolution.git
2.conda env create -f environment.yml
3.conda activate struct-evo
4.wget -P ~/.cache/torch/hub/checkpoints https://zenodo.org/records/12631662/files/esm_if1_20220410.zip
5.unzip ~/.cache/torch/hub/checkpoints/esm_if1_20220410.zip
iii.运行以推荐突变点:python bin/recommend.py examples/7mmo_abc_fvar.pdb \
--chain A --seqpath examples/7mmo_chainA_lib.fasta \
--outpath examples/7mmo_chainA_scores.csv \
--upperbound 109 --offset 1
5. 小样本的抗体亲和力成熟*,在已有少量样本的亲和力数据下训练模型。使用MULTI-evolve的方法预测多点的组合突变。

第三天:抗体可开发性预测和优化1
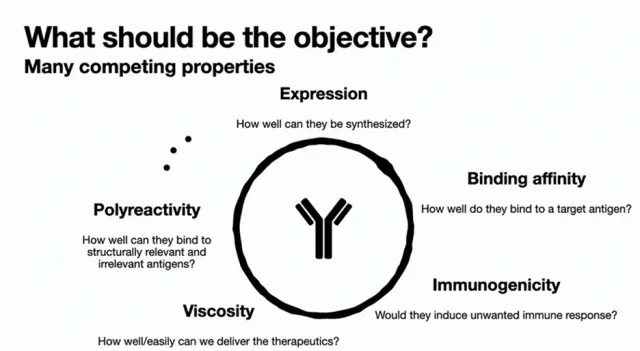
1.抗体可开发性优化在药物开发过程中的意义,
2.衡量抗体可开发性要考虑的因素,如免疫原性、自聚集性、结合特异性、稳定性等等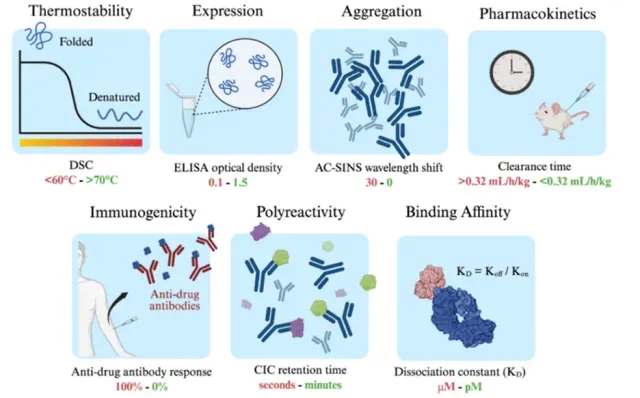 3.以一篇专利文件为例讲解AI辅助抗体改造的案例。Patent No.: US12110324B2。Generate:Biomedicines公司通过AI方法在tezepelumab上改成的一种靶向(TSLP)的长效单克隆抗体GB-0895。
3.以一篇专利文件为例讲解AI辅助抗体改造的案例。Patent No.: US12110324B2。Generate:Biomedicines公司通过AI方法在tezepelumab上改成的一种靶向(TSLP)的长效单克隆抗体GB-0895。
4.抗体结构简单物理性质的计算:溶剂可及表面积(SASA)的讲解及计算;等电点的计算;蛋白质表面电荷分布的计算。*
5.讲解Ginkgo举办的抗体可开发性预测比赛的结果。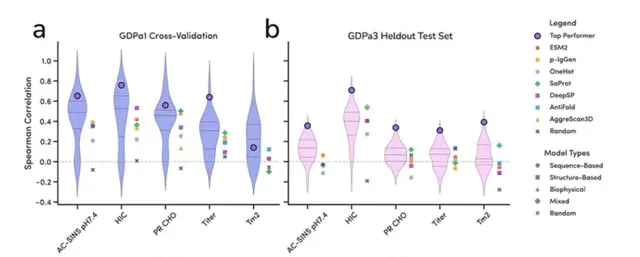 6.公开的抗体可开发性数据的收集。
6.公开的抗体可开发性数据的收集。
7.抗体性质预测的模型实践,展示在小样本的情景下训练机器学习模型*1)数据处理,划分数据集
2)模型构建,基于特征工程的机器学习模型(随机森林,XGboost,ElasticNet等);学习根据蛋白质序列和结构信息构建常见特征。seq_features = feature_utils.get_all_seq_features(heavy_seq, light_seq, is_fv=True, isotype='igg1', lc_type='lambda')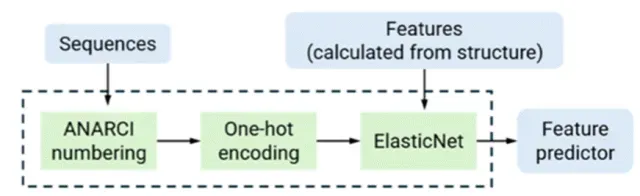 3)模型训练和评价,GridSearchCV交叉验证调参等
3)模型训练和评价,GridSearchCV交叉验证调参等 4)模型的可解释性,特征重要性分析
4)模型的可解释性,特征重要性分析
第四天:抗体可开发性预测和优化2和抗体人源化
1. 基于蛋白质语言模型的可开发性预测*
1)零样本的可开发性预测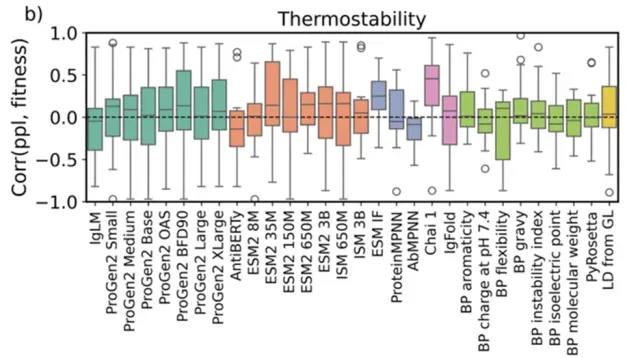 2)少样本的可开发性预测。给定抗体序列和相应的性质,构建下游模型预测。
2)少样本的可开发性预测。给定抗体序列和相应的性质,构建下游模型预测。
a)数据处理,划分数据集
b)获得序列embedding以构建下游模型,实现蛋白质序列的不同方式encoding,包括"onehot", "georgiev", “esm”系列模型。
c)深度学习模型的构建。上游的大语言模型+下游简单线性层。
d)模型训练和评价:绘制训练曲线,训练集和测试集的评价指标随epoch的变化, 2.免疫原性预测
2.免疫原性预测
1)免疫系统介绍,MHC-I和MHC-II,Anti-drug Antibody等基础概念
2)免疫原性预测是MHC结合肽段的预测
3)预测免疫原性。netMHCpan的原理讲解,安装和使用
3.抗体人源化
1)人源化的基础知识和流程。目标:保留亲和力+减小免疫原性+好的稳定性和可开发性。CDR移植到人源框架,回复突变,Vernier Zone,
2)Germline的搜索,IMGT/V-QUEST数据库搜索得到V 基因和J基因相似的人类germline序列。
3)人源化的经典方法biophi的原理讲解、安装和使用。
4)基于AI和基于物理能量(Rosetta)的方法是如何辅助抗体人源化的。
5)排除抗体序列的PTM。

第五天:抗体(scFv, VHH)的从头设计
1.从头设计的意义
1) 跨膜蛋白例如GPCR,难以稳定表达为可溶性蛋白
2)VHH动物免疫羊驼成本高。
3)更高效快速获得候选分子
2.基础模型方法概念介绍:Diffusion模型、 flow-matching、全原子(all-atom)建模等
3.不同公司和方法模型、实验结果讲解
1)Rfdiffusion3+ProteinMPNN生成序列,AphaFold2筛选序列。将学会各个包的安装,不同参数的选择,结合的hotspot位点选择。
a)Rfdiffusion3结构设计,生成~10000个蛋白质主链结构;根据hotspot位点,生成新的结构:
./scripts/run_inference.py 'contigmap.contigs=[B1-100/0 100-100]' 'ppi.hotspot_res=[A30,A33,A34]' inference.output_prefix=test_outputs/binder_test inference.num_designs=10000
b)ProteinMPNN-FastRelax进行序列设计,每一个主链结构两个对应的序列,共设计~20000个序列;
c)筛选:使用AlphaFold2预测设计结构,预测的置信度pAE<10,预测结构与设计结构的RMSD<1A,从中挑选95个进行实验验证。
2)Nabla Bio开发的JAM(Joint Atomic Modeling)系统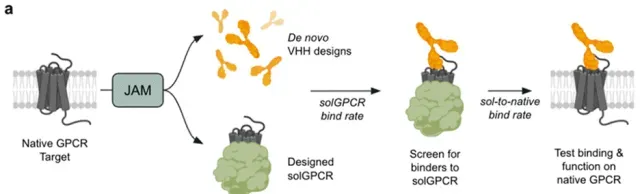 3)Chai2 Discovery开发的Chai-2方法,用以实现抗体的从头生成
3)Chai2 Discovery开发的Chai-2方法,用以实现抗体的从头生成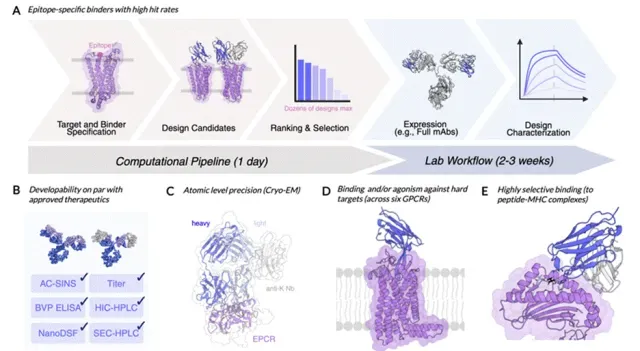 4)MIT开发的Bolzgen方法原理、安装使用讲解。
4)MIT开发的Bolzgen方法原理、安装使用讲解。
安装和使用boltzgen讲解,将详细讲解yaml配置文件的写法,以一个靶点为例,从头生成VHH与该靶点结合。

 5)PPIFlow:基于flow-matching的生成方法,原理,安装和使用方法。
5)PPIFlow:基于flow-matching的生成方法,原理,安装和使用方法。
4.VHH的生成实践
1)确定纳米抗体序列框架(Framework区域)序列,生成CDR区域序列。分析整理纳米抗体序列,绘制序列保守性的Logo图,以此确定在生成VHH时,哪些位置的氨基酸需要固定。 2)对生成的序列进行筛选。在亲和力、序列稳定性、可开发性等各个方面进行筛选。
2)对生成的序列进行筛选。在亲和力、序列稳定性、可开发性等各个方面进行筛选。
a)预测结构与设计结构的RMSD,AlphaFold预测设计结构的置信度pAE等
b)筛选Cys,Met等氨基酸含量
c)减少电荷patch
d)根据等电点等性质筛选。
培训目标:
培训聚焦深度学习驱动的抗体设计为核心方向,以David Baker实验室核心设计方法、主流抗体大语言模型、AI抗体结构预测模型为教学核心,秉持理论夯实、实操落地、科研进阶、工程应用的培训原则。依托高性能服务器实操环境,循序渐进讲解行业主流软件、开源模型、代码实操、数据处理与模型调优,搭配十篇顶刊经典文献深度解析,全方位覆盖当下抗体设计领域前沿技术、研究热点与工业落地方案。助力零基础及进阶学员快速打通理论原理、代码实操、模型应用、科研创新全流程,熟练掌握AI抗体设计全套技术栈,可独立完成抗体结构预测、抗体亲和力优化、可开发性改造、抗体从头设计等科研实操任务,适配药物研发、生物工程、合成生物学等科研与工业应用场景。
上下滑动查看更多














培训目标:
本次培训聚焦基因组编辑技术体系与人工智能辅助基因编辑设计前沿方向,系统讲解CRISPR基因编辑全套技术原理、编辑工具、脱靶检测、实验流程、主流设计分析软件;深入剖析深度学习在gRNA优化、编辑活性预测、编辑酶改造、新型编辑系统挖掘中的核心应用。培训秉持理论扎实、通俗易懂、实操落地、案例复刻、科研进阶的教学理念,依托高性能GPU服务器,手把手完成Linux环境配置、深度学习模型搭建、AI蛋白进化、从头设计、结构比对、新型CRISPR挖掘等高阶实操。结合当下主流AI生成模型、大语言模型、结构比对工具,复刻多篇顶刊经典研究案例,使学员能够完整掌握传统基因编辑+人工智能基因编辑全流程技术栈,具备独立开展基因编辑载体构建、gRNA智能优化、编辑酶定向进化、新型编辑元件挖掘、人工设计结合蛋白等科研能力,适配植物育种、基因治疗、生物医药、分子诊断等科研及工业研发场景。
上下滑动查看更多







培训目标:
• 技术栈回顾:从数据→状态→调控→动态→药物→疾病→孪生→临床• 前沿趋势:大模型、多模态、空间组学、虚拟敲除• 职业发展:计算生物学人才需求与能力路径配套资源
• 课程PPT(理论讲解)• 实操代码包(Jupyter Notebook)• GPU服务器账号(云端实操)• 数据集(公开单细胞/空间数据)• 参考文献(最新顶刊论文,基本是2026、2025新文章+少量经典文章)
上下滑动查看更多
















培训目标:
让学员系统掌握人工智能在计算免疫学中的核心热点与优势,能独立完成免疫分子结构可视化:用 PyMOL/Mol* 加载 pMHC、TCR-pMHC、抗体-抗原复合物,识别结合界面、测量相互作用、渲染高清结构图。能使用蛋白质语言模型(ESM、ProtT5)提取序列表征,用 DeepTCR 完成受体组聚类与抗原特异性分类,用 PanPep 实现少样本 TCR-抗原结合预测,并通过 Python(NumPy/Pandas/PyTorch)完成免疫数据清洗、划分、负样本构造与模型训练。能用 AlphaFold‑Multimer / tfold 预测 TCR-pMHC 或抗体-抗原复合物结构,解读 pLDDT / PAE / DockQ 等质量指标,完成界面残基分析与结合模式评估。能用图神经网络(GCN / GAT / EGNN)构建原子级 TCR-pMHC 图,优化抗原识别与亲和力排序。建立 AI 驱动免疫设计的完整思维闭环:抗原筛选 → 表位/MHC结合预测 → TCR/BCR特异性识别 → 结构验证 → 候选排序 → 疫苗/抗体优化方案。具备独立解决实操问题的能力,能合理解读 AI 预测结果、规避数据泄漏与过拟合风险,输出可实验验证的免疫候选分子(新抗原、特异性 TCR、优化抗体)。掌握跨工具联用能力,实现 IEDB/VDJdb 数据库 → ESM/ProtT5 → DeepTCR/PanPep → AlphaFold-Multimer → PyMOL 的流程化配合使用。
上下滑动查看更多





培训目标:
本培训面向生物领域科研人员,旨在通过5天系统化学习,使学员系统掌握 AI 智能体的核心技术与实战能力。在知识层面,帮助学员理解大语言模型的工作原理与能力边界,建立 Prompt 工程、结构化输出、Function Calling、RAG 四大应用范式的系统认知,理解智能体架构及多智能体协作模式。在技术层面,使学员熟练使用 Claude Code、Codex 等 AI 编程智能体工具,掌握 MCP 服务器搭建与 Skills 技能系统配置,能够基于 LangChain/LangGraph 框架构建具有状态管理、条件路由、人机协同等高级控制流的生物数据分析智能体,能够搭建生物文献 RAG 知识库实现精准问答与引用溯源,掌握 AutoGen 多智能体框架以设计多角色协作系统。在实战层面,使学员能够独立完成 RNA-seq 差异分析、蛋白质结构分析、单细胞数据注释等生物数据分析智能体的开发,能够将 GenBank、UniProt、临床报告等多源非结构化数据转化为结构化数据并构建 ETL 流水线,能够集成物数据库 API 构建多工具协同分析平台。在综合素养层面,帮助学员了解AI 生物科研前沿趋势,掌握智能体系统的可靠性设计方法,最终具备独立设计并实现个人定制化生物科研智能体项目的完整能力。
讲师介绍


AI蛋白质设计(最新前沿)
主讲老师在学术界和工业界都有丰富算法开发和应用经验,来自国内超顶尖课题组,主要从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在PNAS、Angew. Chem. Int. Ed.、Nature、Science等国际知名期刊发表,课题组已发表文献300余篇。

AI多肽设计
主讲老师在学术界和工业界都有丰富算法开发和应用经验,毕业于南开大学院士课题组,从事AI多肽设计、抗菌肽设计以及蛋白质设计的研究工作,相关工作成果已在New England、Plos one等国际知名期刊发

AI辅助抗体设计
主讲老师在学术界和工业界都有丰富算法开发和应用经验,博士毕业于国内顶尖课题组,从事蛋白质结构预测和蛋白质设计的研究工作,相关工作成果已在Cell Systems、Angew. Chem. Int. Ed.、JCIM等国际知名期刊发表论文。目前在知名药企担任高级研究员,主导AI驱动的大分子药物设计平台开发与团队管理。

AI基因编辑
主讲老师在学术界具有多年的研究经历和应用经验,来自于国内顶尖课题组,从事基因组编辑技术与人工智能交叉融合的研究工作,相关工作成果已在Nature Biotechnology、Nature Plants、Trends in Biotechnology等国际知名期刊发表

AI构建虚拟细胞
主讲老师来自浙江大学,主要研发方向为组学算法开发与虚拟细胞建模,以第一作者(含共同)发表高水平期刊会议论文数篇,包括Nature Communications,ISBI等,承担各层次研发课题3项,领导共创开源社区搭建,github star数百,具有丰富的科技成果转化落地经验,讲课一致受到学员高度评价。

人工智能驱动计算免疫学
主讲老师毕业于清华大学,致力于AI for Science(AI4S)领域的前沿研究,深耕生物信息学与计算免疫学。在腾讯AI Lab等头部大厂拥有丰富的算法落地经验。研究成果丰硕,多篇论文发表于ICLR、KDD、AAAI、BIBM等人工智能国际顶级会议,以及《Nature Communications》、《Analytical Chemistry》、《Expert Systems with Applications》等领域内顶级学术期刊。

AI智能体全流程自动化实战
讲师介绍:AI应用算法工程师,长期专注于大模型应用部署、Agent系统搭建、企业知识库接入、多平台协同与自动化流程设计,拥有丰富的一线项目实施与交付经验。曾参与多类智能助手、业务自动化平台与科研辅助系统的方案设计与落地,擅长将大模型能力与真实业务流程结合,快速构建可运行、可扩展、可维护的Agent应用。



01

AI蛋白质设计设计授课时间
共计6天的课 通过腾讯会议直播 线上实操 提供全部录播
02
AI+多肽设计授课时间

2026.7.04-2026.7.05(09:00-11:30--13:30-17:00)
2026.7.7-2026.7.8(19:00-22:00)
2026.7.11-2026.7.12(09:00-11:30--13:30-17:00)
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
03

AI抗体设计授课时间
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
04
AI+基因编辑授课时间

共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
05

AI构建虚拟细胞授课时间
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
06

人工智能驱动的计算免疫学授课时间
共计6天的课 通过腾讯会议直播 线上实操 提供全部录播
07

AI智能体驱动生物医学授课时间
共计5天的课 通过腾讯会议直播 线上实操 提供全部录播
课程报名费用:
公费价:每人每班¥6880元 (含报名费、培训费、资料费、提供课后全程回放资料)
自费价:每人每班¥6580元 (含报名费、培训费、资料费、提供课后全程回放资料)
重磅优惠:
报二送一(同时报名两个班免费赠送一个学习名额赠送班任选)
特惠1:
两班同报:10880元 (可学习三个直播课)
三班同报:14880元 (可学习四个直播课)
四班同报:18880元 (可学习四个直播课)
特惠二:24880元(可免费学习两整年本单位举办的任意课程)
特惠三:提前报名缴费可以优惠300元(仅限前15名)
报名学习课程可赠送往期课程回放(报多少赠双倍)
(可点击跳转详情链接):

1、课程特色--全面的课程技术应用、原理流程、实例联系全贯穿
2、学习模式--理论知识与上机操作相结合,让零基础学员快速熟练掌握
3、课程服务答疑--主讲老师将为您实际工作中遇到的问题提供专业解答
授课方式:通过腾讯会议线上直播,理论+实操的授课模式,老师手把手带着操作,从零基础开始讲解,电子PPT和教程开课前一周提前发送给学员,所有培训使用软件都会发送给学员,有什么疑问采取开麦共享屏幕和微信群解疑,学员和老师交流、学员与学员交流,培训完毕后老师长期解疑,培训群不解散,往期培训学员对于培训质量和授课方式一致评价极高!

学员对于培训给予高度评价


腾讯会议实时直播解答|手把手带着操作


微信:Z13283822597
报名电话:13283822597( 微信同号)
邮箱:13283822597@163.com
