 夜雨聆风
夜雨聆风手机识别人脸、相册搜索“猫”、自动驾驶系统标出车道和行人,很多人会把这叫作AI“看见”了世界。
但机器并不是像人一样睁开眼睛就理解画面。对计算机来说,一张图最初只是数字矩阵。视觉神经网络的发展史,实际上是在回答一个问题:怎样让机器从像素中逐层学出边缘、纹理、部件,最后识别物体?
第一站不是电脑,而是视觉皮层
1959年,David Hubel(戴维·休伯尔,1926–2013,加拿大裔美国神经生理学家)和Torsten Wiesel(托斯滕·维泽尔,1924–,瑞典神经生理学家)在猫的初级视觉皮层记录单个神经元反应。他们发现,有些细胞对特定方向的线条、边缘更敏感。后来,“简单细胞”“复杂细胞”和“感受野”成为理解视觉处理的重要概念。
感受野可以粗略理解为:一个神经元只“关注”视野中的一小块区域。真实大脑并不是简单流水线,但这个概念给工程研究一个启发:图像不必一上来全局连接,局部结构可以先被提取,再逐层组合。
新认知机:把“层级视觉”做成模型
1980年,日本研究者Kunihiko Fukushima(福岛邦彦,1936–,日本计算机科学家)发表Neocognitron,也就是“新认知机”。它采用层级结构,用S-cells提取局部特征,用C-cells增强对位置变化的容忍,目标是让识别结果不受图形位置移动影响。
它还不是今天这种用反向传播训练的大规模CNN。它更多依赖无监督的自组织学习。但它已经把两个思想摆上桌面:视觉可以逐层抽象;同一个特征出现在不同位置时,系统应该尽量认出它是同一种东西。
LeNet:从论文走向真实业务
1980年代末到1990年代,Yann LeCun(扬·勒丘恩,1960–,法裔美国计算机科学家)和同事在贝尔实验室推动卷积网络用于手写数字、邮政编码和支票识别。1998年,LeCun团队发表《Gradient-Based Learning Applied to Document Recognition》,系统介绍了LeNet-5等模型。
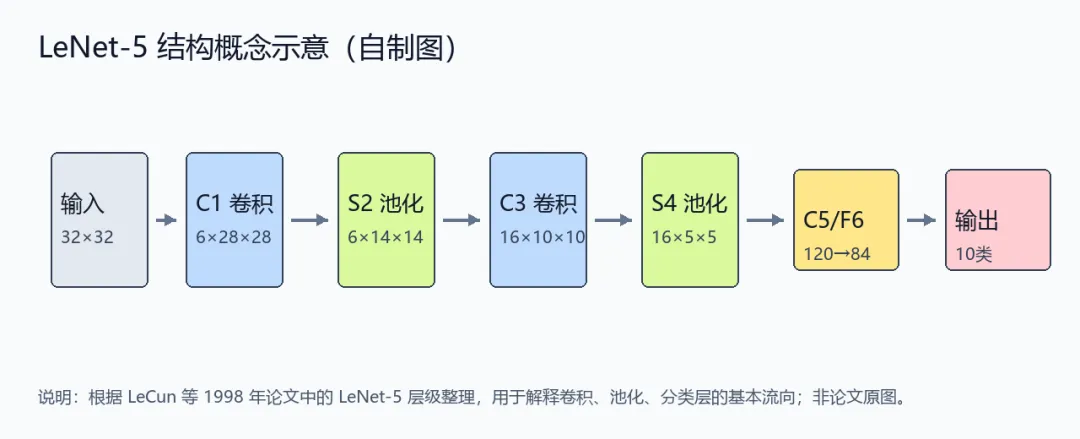
自制图:LeNet-5结构概念示意,根据LeCun等人1998年论文中的层级描述整理,用于说明卷积、池化和分类层的基本流向;非论文原图。
LeNet证明了一个工程方向:与其手工写规则告诉机器什么是数字,不如设计合适的网络结构,让模型从样本中学习局部特征。卷积负责找局部模式,池化让位置轻微变化不至于毁掉判断,全连接层负责最后分类。
ImageNet:先改变的其实是数据
2009年,普林斯顿与斯坦福等机构的研究团队发表ImageNet数据库论文,核心推动者包括Fei-Fei Li(李飞飞,1976–,华裔美国计算机科学家)。论文介绍,ImageNet基于WordNet组织图像,当时报告了5247个synset、320万张图像。
2010年开始的ImageNet Large Scale Visual Recognition Challenge,把大规模图像分类和检测变成公开竞赛。它的重要性在于提供统一数据、统一指标和公开比较方式,让研究者在同一个赛场上交成绩。
AlexNet:GPU把旧想法推过临界点
2012年,Alex Krizhevsky(亚历克斯·克里泽夫斯基,乌克兰裔加拿大计算机科学家)、Ilya Sutskever(伊利亚·苏茨克维,1986–,以色列裔加拿大计算机科学家)和Geoffrey Hinton(杰弗里·辛顿,1947–,英国裔加拿大计算机科学家)的深度卷积网络在ImageNet上取得显著领先。NeurIPS论文写明,这个模型约有6000万参数和50万个神经元。
照片:GeForce GTX 580显卡。TheStriker,CC BY-SA 4.0,来源Wikimedia Commons。AlexNet训练依赖GPU计算,GPU是这次突破的重要条件之一。
AlexNet并不是凭空发明卷积网络。它把多层卷积、ReLU、数据增强、dropout和高效GPU实现组合在一起,让“老方向”突然具备了规模化能力。ImageNet 2012的差距足够大,研究界很难再把深度神经网络当作边缘路线。
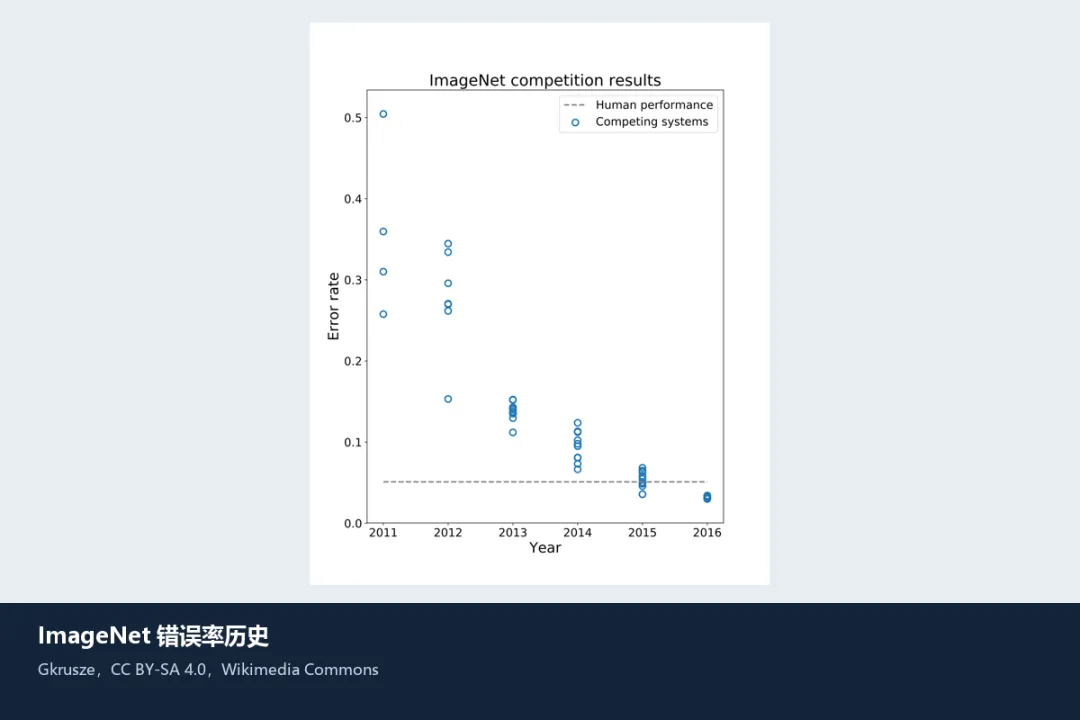
图:ImageNet错误率历史。Gkrusze,CC BY-SA 4.0,来源Wikimedia Commons。图表展示了ImageNet竞赛中视觉系统性能快速提升的阶段。
更深之后,为什么还要“残差”?
AlexNet之后,研究者很自然地想:网络能不能更深?VGG、GoogLeNet等模型推动了这条路。但深度增加后,训练会变难,模型不一定因为层数更多就更好。
2015年,何恺明等人提出ResNet。论文开头就指出,更深的神经网络更难训练。残差连接让100多层网络变得可训练,并在ILSVRC 2015分类任务中获得第一。
ViT:视觉也可以拆成token
2020年,Google Research团队提出Vision Transformer,也就是ViT。论文标题很有名:《An Image is Worth 16x16 Words》。核心做法是把图像切成固定大小的小块,每个小块像语言模型里的token一样进入Transformer。
ViT说明,卷积并不是视觉模型唯一的路线。在足够大规模预训练数据上,纯Transformer也能在图像分类任务中表现很好。它把视觉研究进一步拉向“大数据、大模型、预训练”的方向,也和今天多模态大模型的发展接上了。
它为什么重要,又有什么边界?
视觉神经网络改变了许多日常功能:相册搜索、医学影像辅助、工厂质检、自动驾驶感知、短视频审核、图像生成和多模态问答,都与这条技术线有关。
但“看见”不等于“理解”。模型可能依赖数据偏差,可能被对抗样本误导,也可能在陌生场景中失效。ImageNet的成功证明了大规模评测的价值,也提醒我们:一个榜单不是现实世界的全部。
回看这段历史,推动视觉神经网络前进的不是某位天才突然发明了一切,而是神经科学启发、网络结构、反向传播、标注数据、GPU算力和公开基准长期汇合。
如果说过去十年机器学会了识别图片,那么接下来的问题是:它能否真正理解图片背后的因果、常识和人类语境?
参考资料:
1. Hubel & Wiesel, Receptive Fields of Single Neurones in the Cat's Striate Cortex, 1959
2. Fukushima, Neocognitron, Biological Cybernetics, 1980
3. LeCun et al., Gradient-Based Learning Applied to Document Recognition, 1998
4. Deng et al., ImageNet: A Large-Scale Hierarchical Image Database, CVPR 2009
5. Krizhevsky, Sutskever & Hinton, ImageNet Classification with Deep CNNs, NIPS 2012
6. He et al., Deep Residual Learning for Image Recognition, 2015
7. Dosovitskiy et al., An Image is Worth 16x16 Words, 2020
