夜雨聆风
夜雨聆风
Andrej Karpathy说过一句话:"LLM不会无聊,不会忘记更新交叉引用,而且一次能修改15个文件。"——这就是为什么AI Agent需要一种专属的知识格式。
你有没有遇到过这个场景:
你搭了一个AI Agent,让它回答公司内部的业务问题。
数据表的Schema在BigQuery里,业务规则在Confluence wiki里,指标定义在仪表盘配置里,操作手册在共享网盘里。
Agent要回答一个问题,得从四个不同的地方拉信息,每个地方的格式都不一样。
这不是Agent能力不够,是知识本身就是碎片化的。
2026年6月12日,谷歌开源了OKF(Open Knowledge Format)——一个厂商中立的Markdown规范,专门解决这个问题。
今天这篇文章,把OKF从设计理念到文件格式到实际场景掰清楚——帮你判断这东西值不值得关注、值不值得用。
一、OKF是什么?一句话说清楚

OKF = 一个目录的Markdown文件 + YAML frontmatter,用来给AI Agent喂结构化的组织知识。
就这么简单。不需要专有SDK,不需要特殊平台,不需要数据库。
你能 cat 一个文件,就能读 OKF;你能 git clone 一个仓库,就能分发 OKF。
1.1 规范有多简洁?
OKF v0.1的完整规范放在GitHub上,一页纸就写完了。
核心规则只有三条:
每个文件必须有可解析的YAML frontmatter frontmatter中只有一个必填字段: type保留文件名 index.md和log.md有特殊含义
1.2 一个完整的OKF文档长什么样
---type: BigQuery Tabletitle: Ordersdescription: 每个已完成的客户订单一行记录resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orderstags: [sales, revenue]timestamp: 2026-05-28T14:30:00Z---# Schema| Column | Type | Description ||-------------|--------|---------------------------------|| order_id | STRING | 全局唯一订单标识符 || customer_id | STRING | 外键 → customers|# Joins与 customers 通过 customer_id 关联。
注意那个customers——这不只是一个链接,这是知识图谱的一条边。 Markdown链接就是概念之间的关系,不需要额外的关系定义语言。
二、Knowledge Bundle:知识打包成文件夹

OKF的核心概念是Knowledge Bundle——一个知识包,本质上就是一个文件夹。
sales/├── index.md # 入口:整个sales领域的概览├── datasets/│ ├── index.md # 数据集目录│ └── orders_db.md # orders数据库文档├── tables/│ ├── index.md # 表目录│ ├── orders.md # orders表详细文档│ └── customers.md # customers表详细文档├── metrics/│ ├── index.md # 指标目录│ └── weekly_active_users.md # WAU指标定义└── log.md # 变更历史
2.1 路径即身份
文件路径就是知识的唯一ID——tables/orders.md就代表"orders表"这个概念。不需要额外的ID系统。
2.2 index.md是渐进式入口
每个目录的index.md列出该目录下有什么——Agent先读index.md了解全貌,再按需深入具体文件。
这就是渐进式披露(Progressive Disclosure)——不一次性灌入所有知识,而是让Agent按需探索。对Context Window极度友好。
2.3 可以用Git分发
Bundle本质是文件夹,可以:
打成tarball传输 放在Git仓库里版本控制 在GitHub上直接人类可读 被任何Agent无需适配地消费
三、OKF解决什么问题?
3.1 知识碎片化
每个组织的知识分散在N个地方:
数据仓库Schema在BigQuery/Snowflake 业务规则在Confluence/Notion 操作手册在Google Docs 指标定义在Looker/Grafana配置里 架构图在draw.io 代码规范在README里
每个Agent开发者都在独立解决同一个问题:怎么把这些碎片拼成Agent能用的上下文。
OKF说:别拼了,把所有知识统一成Markdown+YAML,Agent直接读。
3.2 知识锁定
现有的知识要么锁在Confluence的API里,要么锁在某个SaaS平台的专有格式里。换一个工具,知识就带不走。
OKF是纯文本。你换Agent框架、换LLM、换平台,知识格式不需要变。
3.3 上下文工程的基础设施
2026年的热词是Context Engineering——给Agent组装高质量的上下文。
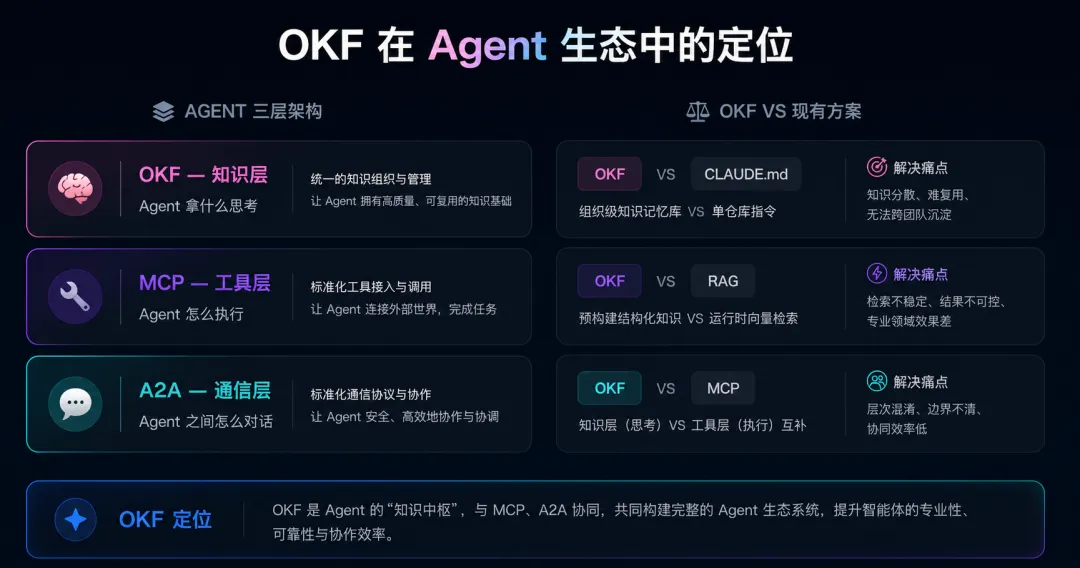
MCP解决了Agent怎么执行(调API、查数据库)。
OKF解决了Agent拿什么思考(组织知识、业务规则、架构约束)。
MCP是手,OKF是脑子里的知识。 两者互补,不是竞争。
四、OKF vs 你已经知道的那些东西
4.1 OKF vs CLAUDE.md / AGENTS.md
CLAUDE.md是单文件或少量文件,给一个仓库的Agent写指令。
OKF是目录级的知识图谱,给整个组织的Agent提供知识。
不冲突。 CLAUDE.md可以引用OKF文件:
执行分析任务前,先读 /okf/sales/metrics/weekly_active_users.md4.2 OKF vs RAG
RAG是运行时检索——Agent遇到问题,去向量数据库里搜相关文档。
OKF是预编纂的知识库——人类(或Agent)事先把知识整理好,Agent直接读。
区别在于:RAG检索回来的可能是"大概相关"的片段,OKF提供的是"经过整理的、有结构的、有交叉引用的"知识。
RAG解决"不知道有什么",OKF解决"知道但很乱"。
4.3 OKF vs MCP
- MCP
:Agent的工具层——怎么执行(调API、查数据库、发消息) - OKF
:Agent的知识层——拿什么思考(业务规则、数据结构、操作流程)
这两层是正交的。一个好的Agent既需要MCP连接工具,也需要OKF提供知识。
五、谷歌自己怎么用OKF?
谷歌同时发布了两个参考实现和三个示例Bundle:
5.1 BigQuery Enrichment Agent
这个Agent会自动遍历你的BigQuery数据集,为每个表和视图自动生成OKF文档——包括Schema描述、Join路径、引用来源。
你不需要手写OKF。 让Agent帮你写,你审核就行。
5.2 静态HTML可视化器
一个单文件的HTML页面(无后端),把OKF Bundle转换成可交互的知识图谱。
你可以在浏览器里看到所有概念之间的关系——哪些表和哪些指标相关、哪些字段是外键引用。数据不离开你的浏览器。
5.3 三个示例Bundle
- GA4电商数据
:Google Analytics 4的电商事件Schema - Stack Overflow公开数据集
:问答数据的知识结构 - Bitcoin公开数据集
:区块链数据的知识结构
想试手?直接clone下来看。
六、Karpathy的LLM Wiki哲学
OKF的设计哲学和Andrej Karpathy提出的"LLM Wiki"理念高度一致。
Karpathy的观察是:人类维护知识库(wiki)最终都会烂尾——更新太累、交叉引用容易忘、格式逐渐混乱。
但LLM不会:
- 不会无聊
——让它更新100个文件的交叉引用,它不会抱怨 - 不会遗忘
——修改了一个表名,它会自动更新所有引用这个表的文档 - 一次能改15个文件
——人类做不到的批量一致性修改,LLM轻松搞定
OKF就是把这个理念标准化了:让Agent来写、维护和消费组织知识,用一种Agent友好的格式。
七、OKF的局限和开放问题
别光说好的,说说问题。
7.1 知识冲突怎么办?
两个OKF文件对同一个指标的定义不一致——规范没说怎么处理。v0.2承诺会加入矛盾语义和信任层级。
7.2 静态知识会过期
OKF是静态的Markdown文件。数据库加了一列、业务规则改了——如果没人(或Agent)更新OKF文件,知识就过期了。
这就是为什么BigQuery Enrichment Agent很重要——它能自动化知识更新,而不是靠人记得去改。
7.3 谁来治理?
目前OKF发布在Google的GitHub组织下,12个Issue、2个PR。还没有独立的社区治理结构。
对比MCP已经被Linux Foundation接管——OKF在治理成熟度上差了一大截。这会影响其他厂商的采纳意愿。
7.4 会不会"又一个标准"?
Agent生态已经有MCP、A2A、AAMP、ACP……OKF会不会变成"又一个没人用的标准"?
谷歌的回答是:OKF运作在比这些标准更底层的位置——它不关心Agent怎么通信、怎么执行,只关心Agent读的知识长什么样。
八、对开发者意味着什么?
8.1 如果你在做Agent项目
现在就可以试。把你的业务知识整理成OKF格式的Markdown文件,放在Agent能读到的地方。即使OKF最终没成为标准,这种结构化的知识整理方式本身就有价值。
8.2 如果你在做企业AI平台
关注OKF和MCP的配合。MCP给Agent工具,OKF给Agent知识——工具+知识=有用的Agent。缺一不可。
8.3 如果你只是围观
记住一个趋势:AI Agent的竞争正在从"谁的模型更强"转向"谁的上下文更好"。
Context Engineering是2026年的主旋律。OKF就是这个趋势的产物——不是造更强的Agent,而是给现有Agent喂更好的知识。
写在最后
OKF v0.1简单到有些"无聊"——不就是Markdown文件加个YAML头吗?
但这恰恰是它的精妙之处。
伟大的标准都很无聊。 HTTP无聊吗?JSON无聊吗?Markdown本身无聊吗?正是因为足够简单、足够通用,它们才成为了基础设施。
OKF赌的是同一件事:最终胜出的知识格式,一定是最简单的那个。 不需要专有SDK、不需要数据库、不需要培训——cat一个文件就能读,git clone就能分发。
当然,v0.1还很早期,治理、冲突处理、社区建设都是未知数。但方向是对的——Agent需要的不是更多工具,而是更好的知识。
如果你做Agent项目,不妨试试把你的业务知识OKF化。最差的结果也不过是你多了一份整理好的Markdown文档。
我是老周,一个在架构领域摸爬滚打多年的技术人。如果这篇文章对你有帮助,欢迎点赞、在看、转发三连。关注「老周聊架构」,每周深度解读AI和架构的最新趋势。