夜雨聆风
夜雨聆风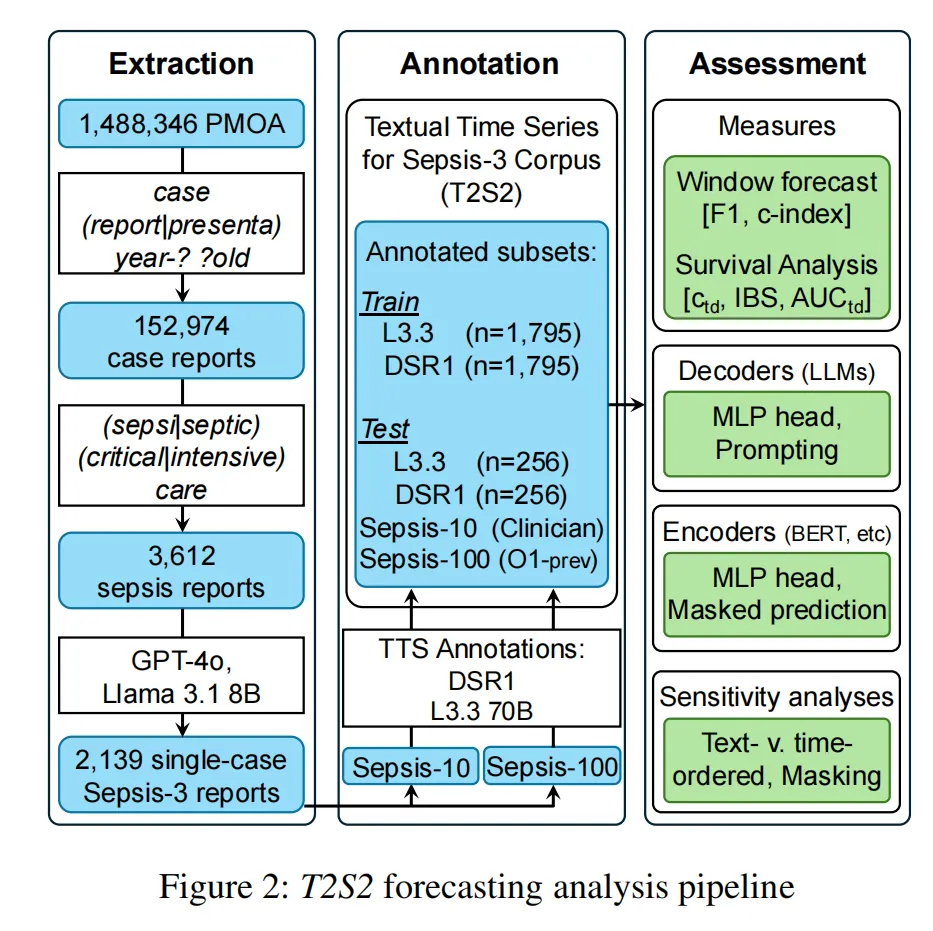 先给大家看核心的方法总结构图(图2),整个研究的脉络都在这了:从PubMed的病例报告里提取脓毒症相关数据,先做文本时间序列标注,把杂乱的临床叙事变成带时间戳的(事件,时间)元组;接着定义事件预测、时间排序、生存分析三大核心任务;然后用编码器、解码器等不同模型做训练和测试;最后通过时间排序策略、时间步丢弃等敏感性分析,验证模型的鲁棒性。一步一步,把非结构化文本变成能支撑精准预测的结构化时序数据,思路超清晰!
先给大家看核心的方法总结构图(图2),整个研究的脉络都在这了:从PubMed的病例报告里提取脓毒症相关数据,先做文本时间序列标注,把杂乱的临床叙事变成带时间戳的(事件,时间)元组;接着定义事件预测、时间排序、生存分析三大核心任务;然后用编码器、解码器等不同模型做训练和测试;最后通过时间排序策略、时间步丢弃等敏感性分析,验证模型的鲁棒性。一步一步,把非结构化文本变成能支撑精准预测的结构化时序数据,思路超清晰!
我整理了“时间序列合集”方向50篇相关论文合集,帮助大家了解学习“时间序列合集”方向,选题,挖创新点。


论文信息
题目: Forecasting Clinical Risk from Textual Time Series: Structuring Narratives for Temporal AI in Healthcare
基于文本时间序列的临床风险预测:为医疗保健中的时序人工智能构建叙事结构
作者:Shahriar Noroozizadeh, Sayantan Kumar, Jeremy C. Weiss
为啥这个研究这么重要?
先聊聊背景——全球医疗资源分布不均,很多地方的关键临床信息只存在于手写的病例报告、病程记录里,没有结构化的数据系统。传统AI模型要么只认结构化数据,要么用大语言模型直接分析文本时,会栽在"时序推理"这个坑里。
就像这张图(图1)展示的,大语言模型天生对时间顺序不敏感,哪怕接触过海量生物医学文本,想让它从临床叙事里恢复正确的时间线,概率低到0.002%都不到!用这样的模型做临床风险预测,很容易"因果泄漏"——把还没发生的事当成已知信息来用,预测结果自然不靠谱。
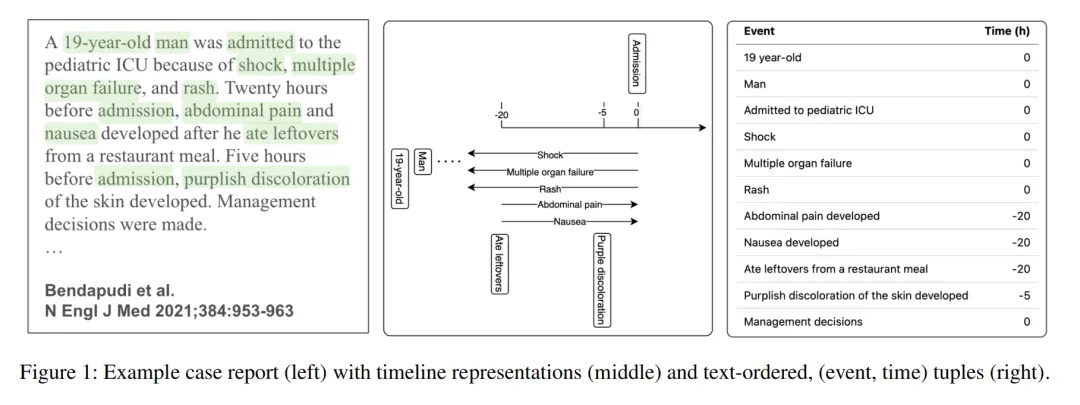
而这篇论文最核心的价值,就是解决了"临床文本时序化"这个痛点,让AI能真正读懂患者病程的时间逻辑,不管是短期事件预测,还是长期生存分析,都有了更靠谱的依据。
核心玩法:给临床文本"装"上时间戳
研究团队第一步就做了件关键事——把自由文本的临床叙述,转化成"文本时间序列"。简单说,就是给每个临床事件(比如"胸痛并向胸骨后放射""肝脏转移")都贴上时间戳,变成(事件,时间)的元组。
这里有两个超实用的细节:一是提取临床发现时,不把完整的症状拆成碎片(比如保留"胸痛并向胸骨后放射"完整意思),二是把复合短语拆成单独事件(比如"肝脏和胰腺转移"拆成两个),既保上下文,又让标注更精准。
为了生成高质量的文本时间序列,团队还设计了"规则+LLM"的混合流程:先用正则表达式过滤脓毒症相关病例,再用DeepSeek-R1、Llama-3.3等模型提取事件和时间,最后经过专家验证,既避免了因果泄漏,又保证了标注的时序一致性。
模型大比拼:没有全能选手,只有精准匹配
接下来就是重头戏——模型对比测试。团队一口气测了五类模型:微调解码器LLM、提示式LLM、微调编码器、编码器掩码模型(微调/零样本),在三大任务里挨个"打分":
1. 事件预测:编码器更胜一筹
预测未来1小时、24小时、1周内会不会发生某个临床事件,编码器模型(尤其是BioClinical-ModernBERT-base)直接碾压解码器LLM!比如24小时事件预测,BioClinical-ModernBERT-base的F1分数能到0.635以上,而最好的解码器模型才0.482。
这里要夸夸生物医学预训练的优势:通用ModernBERT内部测试分数稍高,但BioClinical版在外部数据集上泛化能力更强,零样本预测也能打出0.246的F1(普通BERT几乎是0),这对真实临床场景太重要了——毕竟不同医院的病历格式、表述都不一样,泛化性差的模型根本没法用。
2. 时间排序:编码器依然稳
让模型给未来的临床事件排顺序,编码器模型的一致性指数(c-index)还是更高!BioClinical-ModernBERT-base能达到0.677,哪怕是没接触过PubMed的RedPajama模型,也能打到0.618,说明这个任务里,通用模型也能打,但生物医学预训练还是更顶。
3. 生存分析:解码器反超
有意思的是,预测患者死亡时间的生存分析任务里,指令微调的解码器LLM(比如Llama-3.3-70B、RedPajama)反而更厉害!比如168小时的生存预测,RedPajama在外部数据集上的一致性指数能到0.76,把编码器远远甩在后面。
这也印证了研究的核心结论:没有全能模型,要根据任务选——事件预测、时间排序用编码器,生存分析用解码器,精准匹配才是王道。
敏感分析:这些细节影响预测效果!
最后团队还做了两个超有价值的敏感性分析,给实际部署划了重点:
1. 时间顺序vs文本顺序
按时间排序训练,模型的排序一致性更高;按文本叙述顺序训练,在外部数据集上的F1分数更好。简单说,想让模型排对事件顺序,就按时间来;想让模型适应不同数据集,就保留文本原始顺序。
2. 历史信息缺失:排序比分类抗造
随机删掉部分历史事件(模拟临床文档缺失),事件分类的F1分数在删掉60%后暴跌,但事件排序的一致性指数几乎没变化!这意味着,哪怕病历记录不完整,模型依然能较准确地给事件排顺序,这对医疗资源匮乏、文档记录不规范的地区太友好了。
总结:不止是研究,更是落地指南
这篇论文不只是提出了一个新框架,更给医疗AI落地指了明路:
临床文本不是"无用的杂乱文字",只要做好时序结构化,就能支撑精准预测; 生物医学预训练模型的泛化性、鲁棒性,是真实临床场景的"刚需"; 不同任务要选不同模型,别指望一个模型搞定所有事; 哪怕病历不完整,时序排序任务依然靠谱,这是资源有限地区的"救命稻草"。
当然,研究也有小局限——目前数据来自PubMed病例报告(偏罕见/不典型病例),后续还需要在MIMIC等真实住院病历上验证。但不可否认,这个"文本时间序列"框架,已经为医疗时序AI打开了新大门,未来在脓毒症之外的疾病、实时临床决策支持上,都有超大的应用空间!
看完是不是觉得,给临床文本"捋顺时间线"这件事,真的能改变医疗AI的落地节奏?毕竟在很多地方,一份完整的病例报告,可能就是拯救患者的关键——而这篇研究,让AI终于能读懂这份关键。