 夜雨聆风
夜雨聆风先贴GPT5.5 做的魂斗罗。
玩了一下手感还不错。
昨天我让三款编程工具去复刻《魂斗罗》第一关。
当时我对 Codex 这一路的评价比较差。
后来评论区有人贴了一个结果:他直接用 Codex,选择 GPT-5.5 模型,也能做出一个可用版本。
所以我今天重新跑了一遍。
这次确认下来,昨天那版最大的问题不是Codex不是 GPT-5.5 ,而是我的 Codex 环境里开了 SuperPower 插件。里面的 Brainstorm skill 会在我输入需求后自动启动,先做一轮比较重的规划和发散。开了 superpower 这个插件的兄弟要小心一点了。
这会影响这类“一句话需求,一遍做出来”的测试结果。
这里也把昨天对比里的工具和模型关系说清楚。
我对比的不是单纯的模型裸跑,而是三套“编程工具 + 模型”的组合:
• Claude Code,使用模型 Claude Opus 4.8• ZCode,使用模型 GLM-5.2• Codex,使用模型 GPT-5.5
claude code ,和 Zcode 是我朋友充值的 pro 会员,Codex 是我的 pro 会员,都用最强能力。
它们接到的初始需求都很短,基本就是一句话:
复刻《魂斗罗》,完成第一关。
昨天那轮里,Claude Code 和 ZCode 都是一句话一遍过。
Codex 那边因为 SuperPower / Brainstorm 自动介入,过程就不是一个干净的 Codex + GPT-5.5 直接实现过程了。
所以这篇主要是补充这个事实:昨天的 Codex 结果,不能直接等同于 GPT-5.5 在干净环境下的表现。
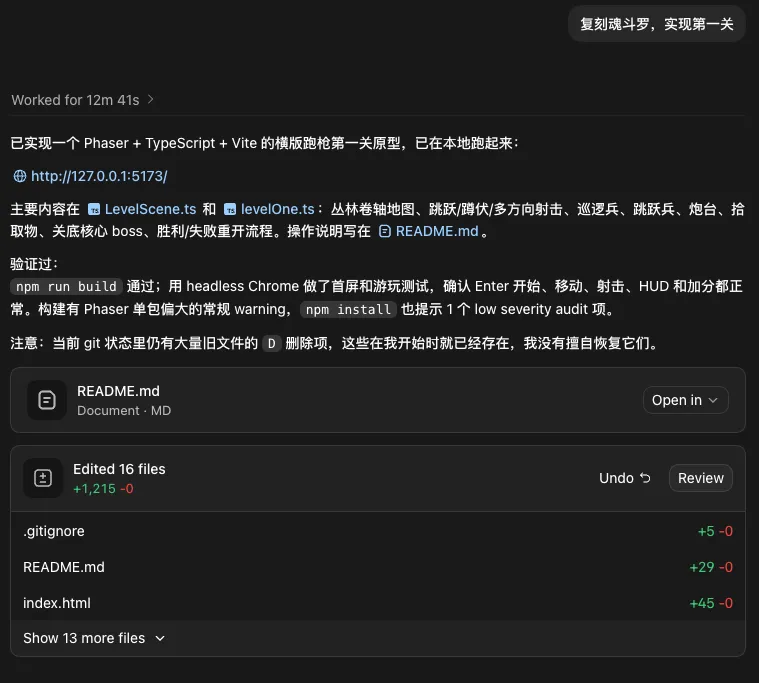
第一遍做出来,有点问题到不了关底。
让他自己玩,做 5 轮优化,就是视频的版本,效果还不错。
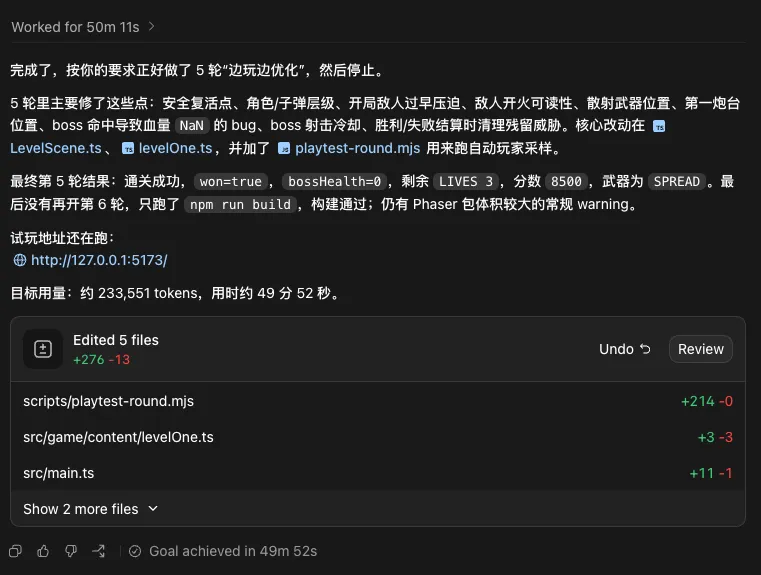
只能算是一个能力测试,真要用这种一句话做游戏,还差得远。
