 夜雨聆风
夜雨聆风摘要:给 AI 助手接上越来越多的外部工具,它有时反而变笨、变慢、变贵。Hermes Agent 新上线的 Tool Search 没换更大的模型,只是把工具的"说明书"从桌面收进书架、要用再查,同一个模型的准确率就从 49% 涨到了 74%。这篇聊聊这个很小但很顶用的机制,以及它背后那个值得每个人记一记的判断。

最近在折腾 Hermes Agent的同学们,很多人给它接了一堆外部工具:连 GitHub,连数据库,连浏览器,本来想让它更能干、能多帮我跑点活。结果它不光没变灵光,反倒慢了,每次响应还贵了不少。我当时就琢磨,这咋回事呢?说好的工具越多能力越强,怎么成了拖累?
你想啊,这就像一个新员工上班第一天,本该意气风发开始干活,结果桌上先被人堆了几百本设备说明书。纸质文档满桌乱叠,活还一个字没动,桌子先占满了,人也看懵了。我那段时间就是这种感觉——东西越加越多,它却越来越迟钝,反应慢、还容易出错,价格也跟着往上飙。明明给它配了更多"装备",怎么反而变笨了呢?
这事儿其实挺普遍的。现在大家都在拼命给 AI 接新东西,可很多人没意识到:你每接一个工具,说白了就是往它的办公桌上又拍了一摞说明书。桌子就那么大,堆到最后,它能好使才怪。
工具多了,AI 的脑子先被说明书塞满
咱别光说抽象的,我觉得讲个真实数字最直观。Hermes 如果一套配置接了 5 个工具服务器、34 个工具,平均每一轮对话,AI 要先把大约 45000 个"字"吃进它的工作台——工作台你就理解成它当下眼前能看到的那块有限空间。这 45000 字里,大约有一半,22000 字,纯粹是工具的参数说明,跟你要问的事一点关系都没有。
更夸张的我也见过。有人实测接了 7 个工具服务器,光说明书就占了 67300 个字,硬生生把一个 20 万字容量的工作台先挤掉了三分之一多。你说你刚开口,一个字还没问呢,它就得先把这堆说明书从头背一遍。再说个细节,单单一个 GitHub 工具集,27 个工具的说明书就占了大约 18000 字——哪怕你这轮对话压根没想用 GitHub,它也得乖乖背着。
这就好比你每天早上一到公司,不管今天用不用,得先把整个文件柜从头翻一遍,确认每一本说明书都摊在桌上,万一临时要用呢。每天上班的头一件事不是干活,是搬文件。这个过程又荒诞又费劲,效率直线往下掉。
桌面被堆满,后果有两个:
• 贵、浪费钱:一次没命中缓存的请求,可能要多花 7 到 10 美分。单看不多,可你一天几十上百轮地用,加起来挺吓人。 • 挑错工具:这个更要命。AI 表面看着懂很多,可一旦面前摆着几百个用不上的选项,它反而会犯迷糊,挑错那一个。
第二点你换个场景就懂了。你让一个新同事去一个堆满几百种工具的仓库里找一把螺丝刀,他大概率要么拿错,要么愣在那儿干等。工具越多越挑花眼,挑错了还得返工。这套折腾放到 AI 身上,就是答非所问、效率滑坡。

Hermes 的解法:说明书搬进书架,要用再拿出来
先说个背景。给 AI 插工具靠的是一个叫 MCP 的接口,你可以把它想象成工具的配送员——每来一个新工具,它就往 AI 桌上又塞一叠说明书。配送员勤快是勤快,可这叠放就没完没了,桌子迟早被埋。
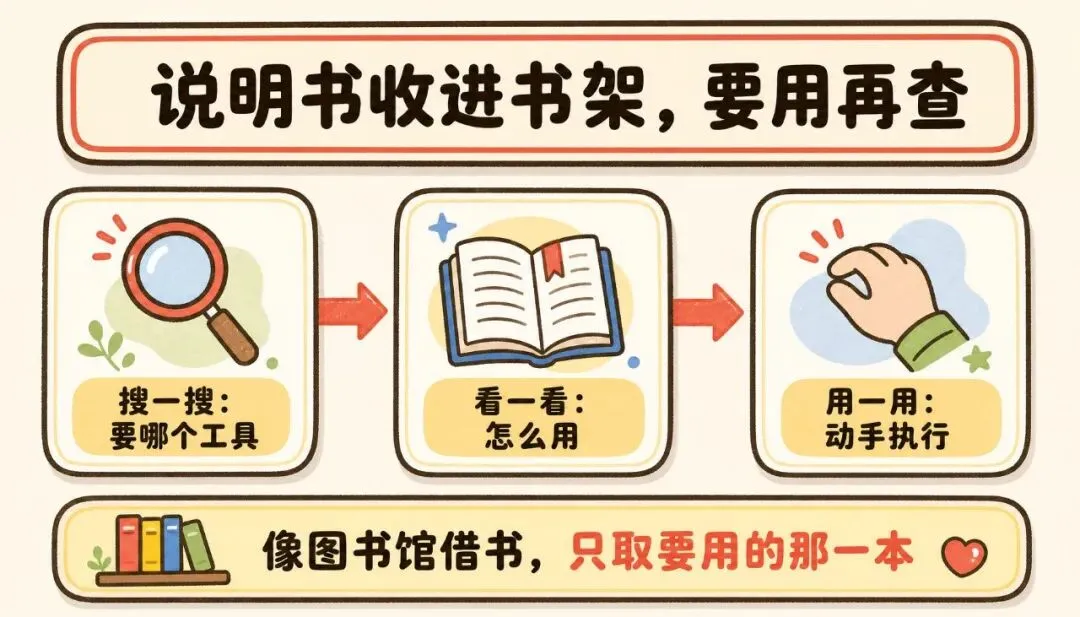
Hermes 想了个小招,叫 Tool Search。它没去换更大的模型,也没重新练什么更复杂的能力,就做了一件特别朴素的事:把这堆说明书都收进「书架」,桌上只留三个常用的"桥梁工具"——
• 搜书架的图书管理员(tool_search):你喊一声"我要办入职登记",它去书架里找最对口的那几本说明书。 • 翻目录看细节的(tool_describe):你要看某个工具具体怎么用,它帮你把那一本调出来翻给你看。 • 真正动手用的(tool_call):确认就是这个了,才去把工具取出来执行。
这套流程,其实就是图书馆借书:你先到搜索台查一查哪几本书跟你的事相关,再翻翻简介和目录确认这本到底讲啥,确定有用了,才去书架上把它取下来。每次只借你要的那几本,桌上再也不用堆着几百本随时落灰的书。
我觉得这套设计最难得的是那股克制劲儿。它没想着立刻给你换个更厉害的员工、或者塞个脑容量更大的模型进来,就是让眼下这个模型,先把自己的桌面理一理,干净利落地开工。你想,换个更能干的人当然好,可招人难、风险大、还得多花钱;给现有的人配一个分类清楚的书架,让他几秒钟就能定位到要用的那本,成本低得多,见效还快。
它怎么知道我要哪个工具
你可能会问,说明书一股脑全收进书架,AI 不就抓瞎了吗?怎么反而更聪明了?
关键在那个"图书管理员"用的检索法,叫 BM25。这是搜索引擎里特别经典的一套打分匹配,你就理解成按关键词的相关程度排序推荐。比如我说"帮我查一下员工入职登记",它会先去所有工具说明的名字、描述、参数里找匹配,按相关度排个序,把最对口的几个递给你。要是实在没找到特别匹配的,它还会退一步,做最朴素的"名字里带没带这个词"的兜底,起码不让你空手而归。换成图书馆,就是你在检索台输"人事合同",它先按书名、简介、标签给你排结果,万一没命中,再帮你扫一眼书名里带"合同"两个字的,总能给你点线索。
它的启动也很有分寸,默认是自动模式。门槛说得很清楚:只有当那些可以延后加载的工具说明书会占掉工作台 10% 以上的空间时,它才出手接管;你工具要是没几个,它压根不掺和,零额外开销。而且它每一轮都重新判断一次——工具少就一直不出场,工具一多(一般 15 个以上)才开始接手;你中途把某个工具拔了,下一轮它又自动恢复成直接显示。这种"看人下菜碟"的劲儿,我挺欣赏。
我自己试过一次。当时桌上挂着十几个工具,我让它去某个仓库里建一条任务记录。开了 Tool Search 之后,我能在界面上清楚看到它先搜了一下"创建记录"这类关键词,调出对应工具的用法看了看,确认参数对得上,才真正去执行。整个过程它没有在一堆无关工具里东张西望,干脆利落。这种"先查再用"的节奏,比它过去抱着一摞说明书边翻边猜,靠谱多了。
还有两个细节让人放心。一是那几个最核心的工具,相当于你桌上常备的笔和本子,永远不会被收进书架,随手就能拿到。二是所有的安全检查、需要你点头批准的操作,认的都是真实的工具名字,不是那个当中介的"桥梁工具"——你在界面上看到的、批准的,就是实打实那个真工具,绝不会被这层中介蒙混过去。

清空桌面后,同一个模型聪明了一大截
我觉得最有说服力的,是 Anthropic(做 Claude 那家公司)自己给模型测的一组结果。同一个模型,没换、没重练,就因为开了 Tool Search 把无关说明书清走了,准确率:Opus 4 从 49% 涨到了 74%,一口气涨了 25 个百分点;Opus 4.5 也从 79.5% 涨到了 88.1%。与此同时,工具说明书占的空间降了大约 85%。
模型一点没动,就是把桌面收拾干净了,它就又快又准又省。这事儿反过来给我提了个醒:AI 答不好,很多时候真不怪它笨,是被一堆用不上的选项给埋住了、带跑偏了。你要让它好好答,第一步往往不在于买个更贵的"大脑",先给它腾出一张干净的桌子可能更管用。
当然,我也得实话实说,这套机制是有代价的:
• 那三个"桥梁工具"本身要占一点固定开销,这是省不掉的成本。 • 每次让图书管理员去搜工具,AI 都得多跑一轮思考,反应会慢那么一点点。
所以这招到底划不划算,得看场景。它最适合的是"工具一大堆、但每次只用其中几样"的情况——这时候省下来的远比多付的多。要是你本来就没接几个工具,再套这么一层搜索,反倒是白搭。我建议你开之前先掂量一下自己手头工具的量,别盲目跟风。

你看,插越多工具,不一定越聪明
回到开头那个困惑:为什么工具越加越多,AI 反而越慢、越笨、越贵?
我现在的体会是,这事儿真不能全赖模型不够大、算法不够牛。更多时候,是我们自己变着法子把它的桌面堆成了杂货铺。它每开工一次,都得先把那一摞用不上的说明书从头搬一遍、看一遍,一轮一轮地耗,能不卡吗?
与其没完没了地惦记着换个更大更贵的模型,不如先低头看看:是不是给它塞了太多它根本用不上的东西。我让 Hermes 开了 Tool Search 之后,实际体验就是——工具照样一大堆,但桌上清清爽爽,它反而更省钱、答得也更准。这套东西当然不是完美无缺,可这个思路我觉得比一味追更大的模型踏实多了。一个几十行的检索小机制,效果有时候比换模型还猛。
怎么样,你要不要也回头看看,自己那张办公桌上堆着的一摞摞"用不上的资料",是不是早就拖慢了你呢?
参考信息来源
• Hermes Agent 官方文档 · Tool Search 功能页(hermes-agent.nousresearch.com/docs) • MarkTechPost:《Hermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4》(2026-05-29) • Anthropic 工程团队关于 MCP 工具上下文开销与 Tool Search 的公开数据 • 社区实测:claude-code issue #11364(7 个 MCP 服务器占用 67,300 tokens) 
