AI Agent 工具调用稳定性深度解析AI Agent 工具调用稳定性深度解析:从并行调度到异常自愈
文 | AI编程
2025 年 11 月,4 个 LangChain Agent 因无限工具调用循环,连续运行了 11 天,消耗 $47,000 才被发现。这不是模型不够聪明,而是工具调用系统缺少可靠性设计。当 Agent 从"单次问答"走向"自主执行",工具调用的稳定性不再是锦上添花——它是 Agent 能否投入生产的分水岭。
一、一次 Agent 调用到底支持多少个工具?
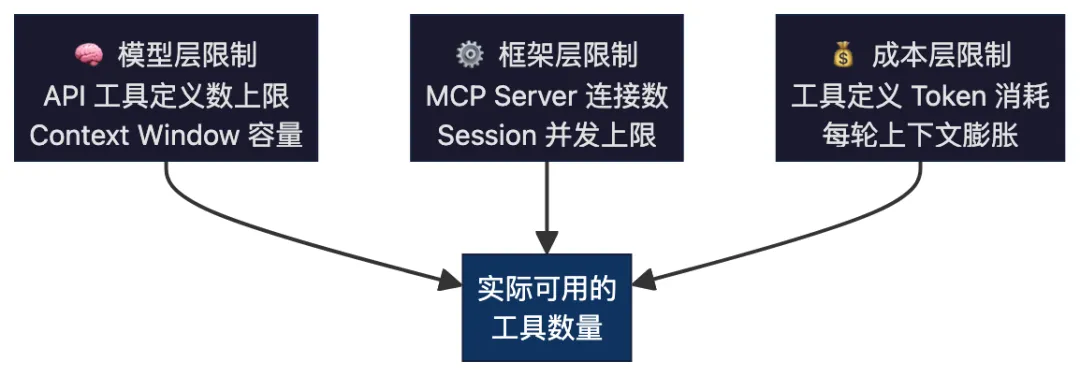
1.1 工具数量的三层上限
Agent 的工具能力不是"越多越好",而是受三重约束:
| 约束层 | 具体限制 | 影响 |
|---|
| 模型层 | Claude API 单次请求可定义数百个工具,但 Context Window(200K)会先爆 | |
| 框架层 | MCP Server 每个会话连接数有限;Claude Code Pro 全局并行会话 ≤ 5 | |
| 成本层 | 100 个工具定义 ≈ 10K-50K tokens,每次请求都消耗 | |
1.2 实际工程中的"有效工具数"
理论极限:Claude API 可定义 256+ 个工具(tool_use blocks)
工程现实:
轻量 Agent(单次任务): 5-15 个工具 → 最佳性价比区间
中等 Agent(多步推理): 15-30 个工具 → 需要工具搜索/延迟加载
重型 Agent(自主运营): 50+ 个工具 → 必须使用 Tool Search Tool
关键瓶颈不在模型能力,在上下文管理:
- 每个工具定义 ≈ 200-500 tokens
- 30 个工具定义 ≈ 6K-15K tokens → 已经占 Context Window 的 7.5%
- 加上 System Prompt + 对话历史 → 留给实际推理的空间被严重挤压
|
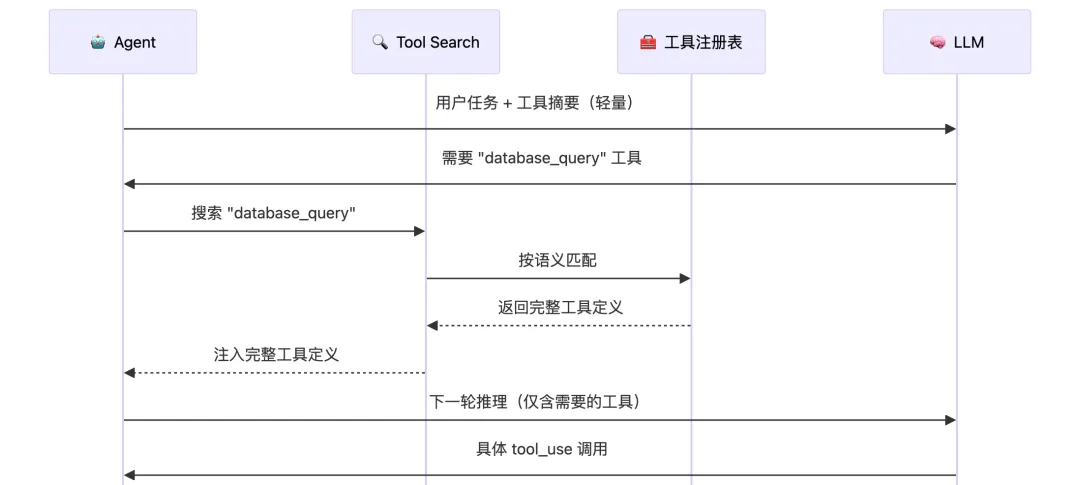
1.3 工具搜索:突破数量的关键
Anthropic 在 2026 年推出的 Tool Search Tool 是解决"工具太多"问题的核心方案:
传统模式:
所有工具定义 → 全部进入 Context Window → 每次推理都消耗
Tool Search 模式:
工具定义存储在外部 → 只将"工具摘要"放入 Context
→ Agent 推理时先搜索 → 只加载当前步骤需要的工具定义
→ Token 节省:77K → 8.7K(减少 ~85%)
|
二、多个工具并行返回时,如何保证上下文不乱?
2.1 tool_use_id:并行调用的"身份证"
当 Agent 一次性发起多个工具调用,每个调用都有唯一的 tool_use_id。所有结果的正确配对,全靠这个 ID。
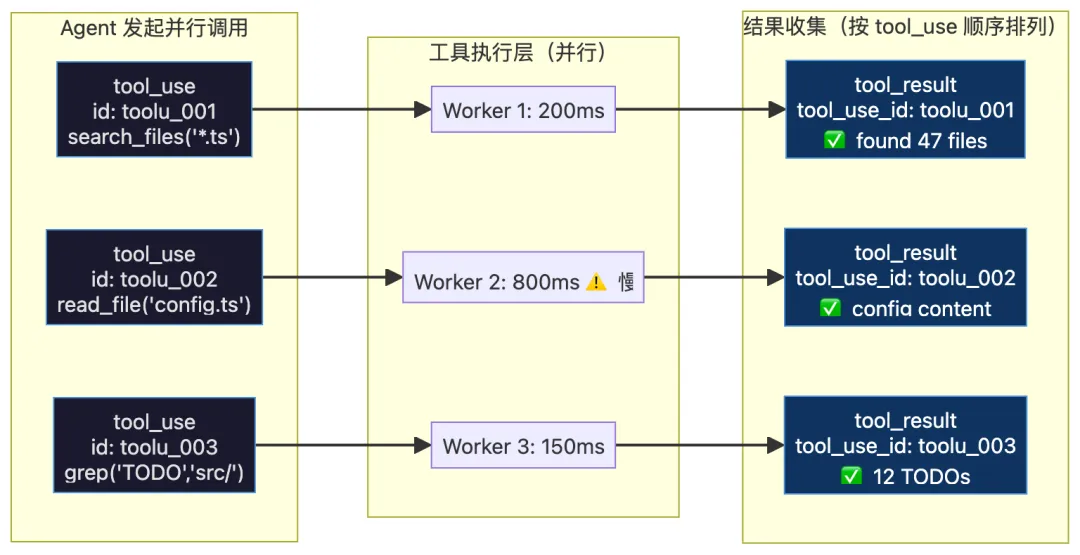
2.2 结果排序的核心原则:按请求顺序,不按完成顺序
这是最容易被忽视但最关键的设计:
错误做法(按完成顺序排列):
tool_use 顺序: [搜索文件, 读取配置, 代码检查]
完成顺序: [代码检查 150ms, 搜索文件 200ms, 读取配置 800ms]
结果排列: [代码检查结果, 搜索文件结果, 读取配置结果]
❌ toolResults[i] ≠ toolCalls[i] → Prompt 不稳定 → Cache Miss → 成本上涨
正确做法(按工具调用顺序排列):
tool_use 顺序: [搜索文件, 读取配置, 代码检查]
结果排列: [搜索文件结果, 读取配置结果, 代码检查结果]
✅ toolResults[i] = toolCalls[i] → Prompt 稳定 → Cache 命中
|
💡 关键洞察:结果的排列顺序直接影响Prompt Cache 稳定性。同样的输入产生不同的结果顺序,会导致缓存失效。因此所有主流 Agent 框架(Harness SDK、AtomicBot、LangChain)都强制规定:toolResults[i] 必须对应 toolCalls[i],无论实际完成顺序如何。
2.3 一条用户消息的"铁律"
Anthropic API 有一条严格但容易忽略的规则:同一轮并行调用的所有结果,必须放在一条 user message 中。
// ❌ 错误:分开发送——"教会"模型不要并行调用
[
{"role": "assistant", "content": [tool_use_1, tool_use_2]},
{"role": "user", "content": [tool_result_1]}, // 第一条
{"role": "user", "content": [tool_result_2]} // 第二条 ← 错误!
]
// ✅ 正确:合并为一条消息——保持并行调用能力
[
{"role": "assistant", "content": [tool_use_1, tool_use_2]},
{"role": "user", "content": [tool_result_1, tool_result_2]} // 一条消息
]
|
原理:分开发送让模型"学会"逐个等待结果,后续调用会退化为串行。合并发送让模型"知道"多个结果可以同时到达。
2.4 独立失败,互不连累
并行调用中一个工具失败,不应该中止其他工具:
场景:3 个并行工具调用,其中读取文件失败
tool_use_1: search_files('*.ts') → ✅ 47 个文件
tool_use_2: read_file('不存在.md') → ❌ 文件不存在
tool_use_3: grep('TODO') → ✅ 12 个匹配
结果数组:
toolResults[0] = { status: 'success', data: 47 files }
toolResults[1] = { status: 'error', is_error: true, content: 'No such file' }
toolResults[2] = { status: 'success', data: 12 matches }
处理原则:
✅ tool_use_2 的失败不影响 tool_use_1 和 tool_use_3
✅ 模型看到个别错误后,可以决定重新调用或跳过
❌ 不因为一个失败就中止整个并行批次
|
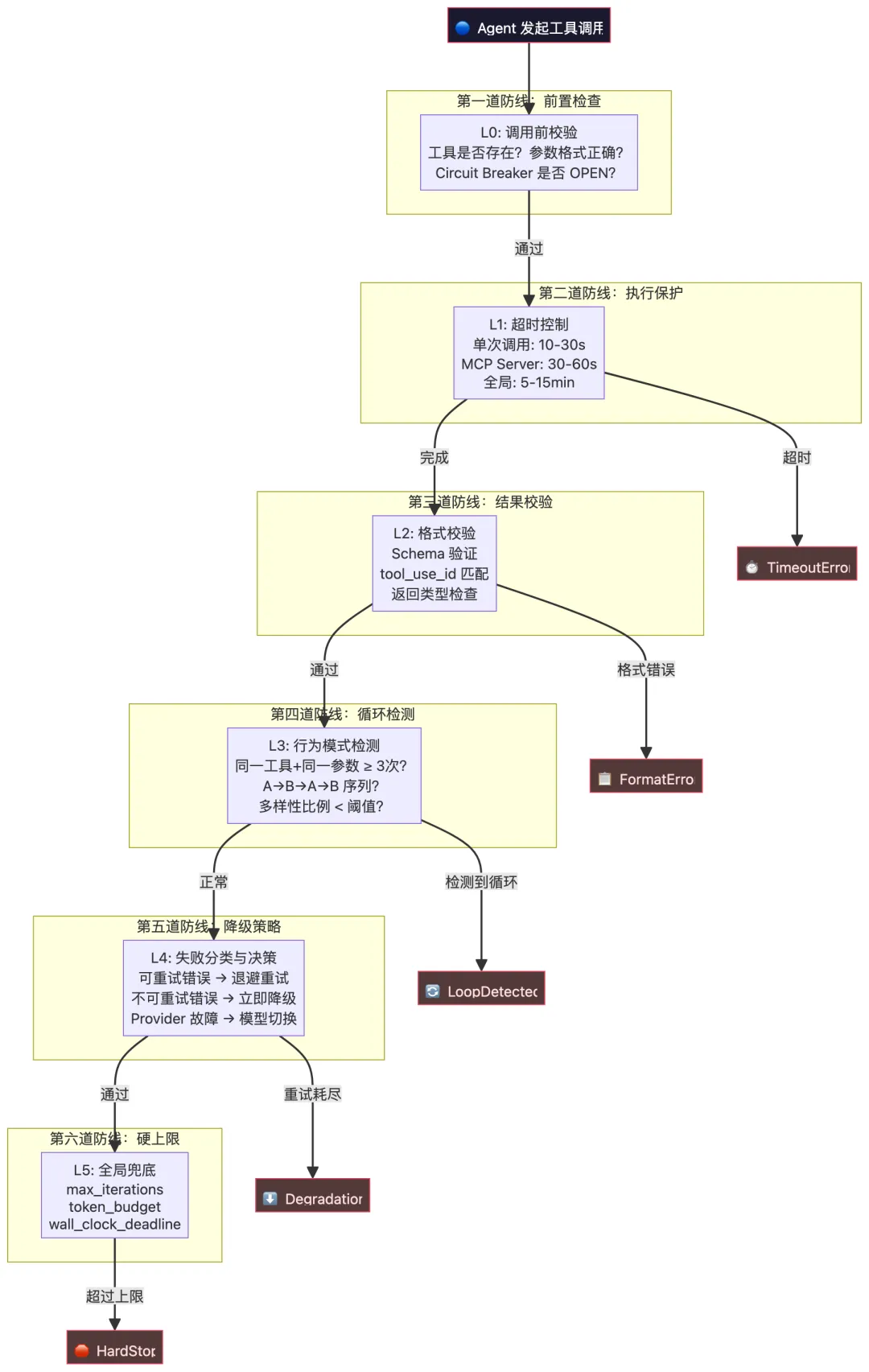
三、工具调用的异常处理:六道防线
Agent 的工具调用面对的不是"会不会出错",而是"出错了以后怎么办"。生产环境的异常处理需要分层防御,每一层解决一类问题。
3.1 全景架构
3.2 第一道防线:超时处理
超时不是简单的"等太久就放弃",而是分层超时:
超时层级设计:
L1 工具调用超时(10-30秒):
适用: 单次工具执行
原理: 大部分 API 调用应在 10s 内完成;30s 覆盖慢查询
超时后: 标记为 TIMEOUT,进入重试队列
L2 MCP Server 超时(30-60秒):
适用: MCP 传输层
原理: MCP Server 可能承载多个工具调用,需要更长窗口
超时后: 断开连接,标记该 Server 的所有待处理调用为失败
L3 全局工作流超时(5-15分钟):
适用: 整个 Agent 会话
原理: 防止 Agent 无休止运行
超时后: 强制终止,保存当前状态到 Memory
超时处理的正确姿势:
1. 不是所有超时都该重试——区分"对方慢"和"对方死了"
2. 超时后检查心跳——MCP Server 是否还在响应 ping?
3. 级联超时——L1 超时触发 L1 重试,3 次 L1 超时触发 L2 降级
|
3.3 第二道防线:格式错误与"幻觉工具"
Agent 可能调用不存在的工具,或传入格式错误的参数。这不是模型能力问题,而是概率系统的必然行为:
常见格式错误类型:
1. 工具不存在(Hallucinated Tool Call):
表现: Agent 调用了 "send_email" 但工具列表里只有 "send_notification"
检测: 工具名不在注册表中 → 立即拒绝,不重试
原因: 模型"创造性"地组合了训练数据中的工具概念
2. 参数 Schema 不匹配:
表现: 必填字段缺失、类型错误(string 传了 number)
检测: JSON Schema 验证 → 返回具体错误信息给模型
处理: 将验证错误作为 tool_result(is_error=true) 返回,让模型修正
3. tool_use_id 错配:
表现: tool_result 的 id 与 tool_use 不匹配
检测: API 层直接拒绝 → 框架层修复 ID 映射
预防: 使用中间件统一 ID 格式(如 LangChain AnthropicToolIdSanitizationMiddleware)
核心原则:格式错误 → 快速失败,不自动重试
重试不会让不存在的工具变得存在
重试不会让错误的 Schema 变得正确
唯一例外:网络传输导致的格式损坏 → 可以重试
|
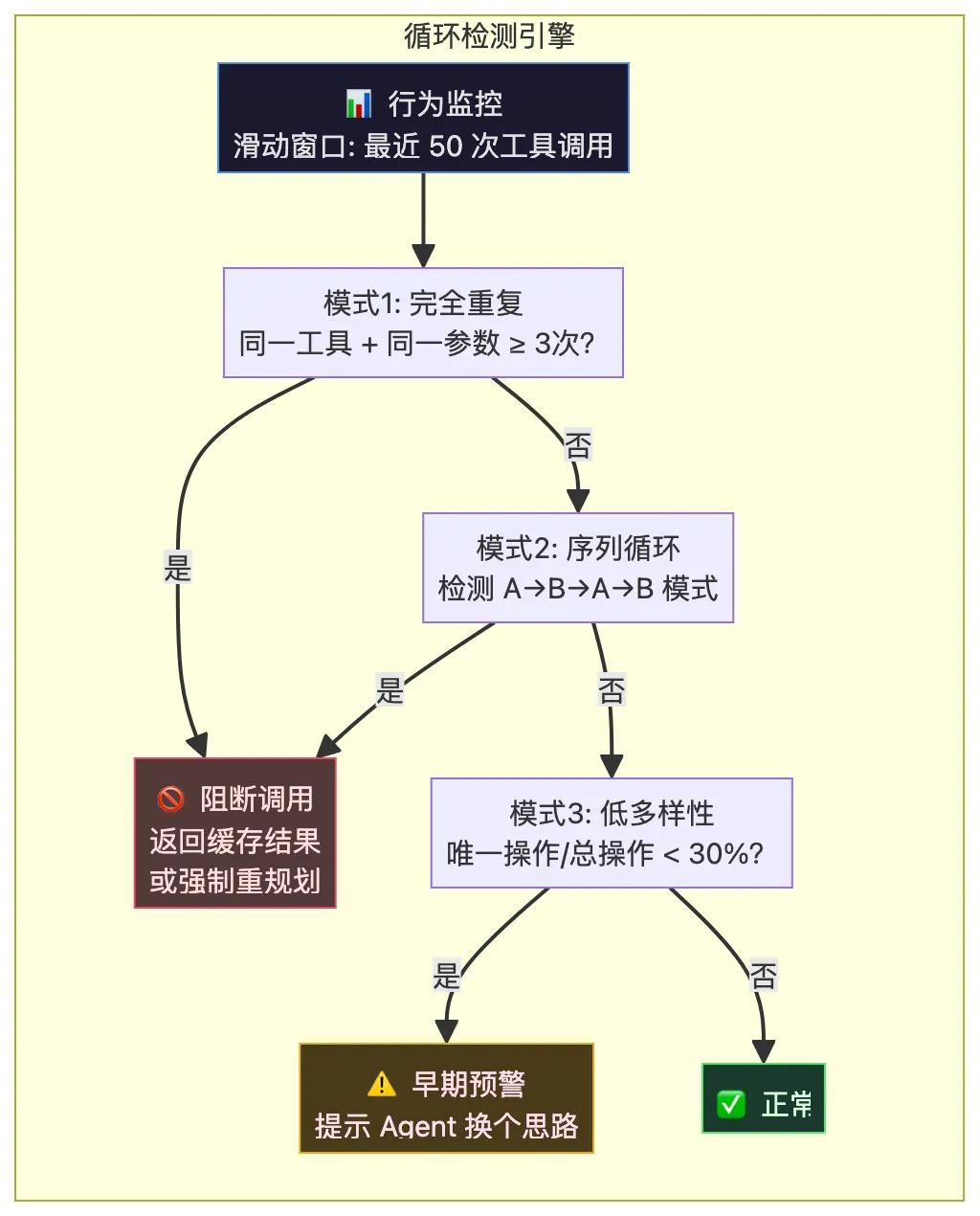
3.4 第三道防线:循环检测
循环是 Agent 工具调用中最昂贵、最难检测的异常模式。2025 年 11 月 $47,000 的惨案就是循环检测缺失的后果。
三类循环检测算法:
类型1: 完全重复检测(O(1),基于哈希):
算法: SHA-256(tool_name + args_json)
窗口: 最近 50 次调用
阈值: 同一哈希出现 ≥ 3 次 → 阻断
案例: Agent 反复调用 search_kb("退款政策") → 第 3 次时阻断
类型2: 序列循环检测(基于滑动窗口模式匹配):
算法: ZDD(Zero-suppressed Decision Diagram)模式匹配
检测: A→B→A→B 或 A→B→C→A→B→C 等重复序列
案例: Edit → Bash → Edit → Bash → ... → 检测到 3 轮后阻断
类型3: 低多样性检测(基于信息熵):
算法: 唯一操作数 / 总操作数
阈值: 低于 30% → 预警;低于 10% → 阻断
案例: 50 次调用只用了 5 种不同操作 → 可能陷入局部循环
|
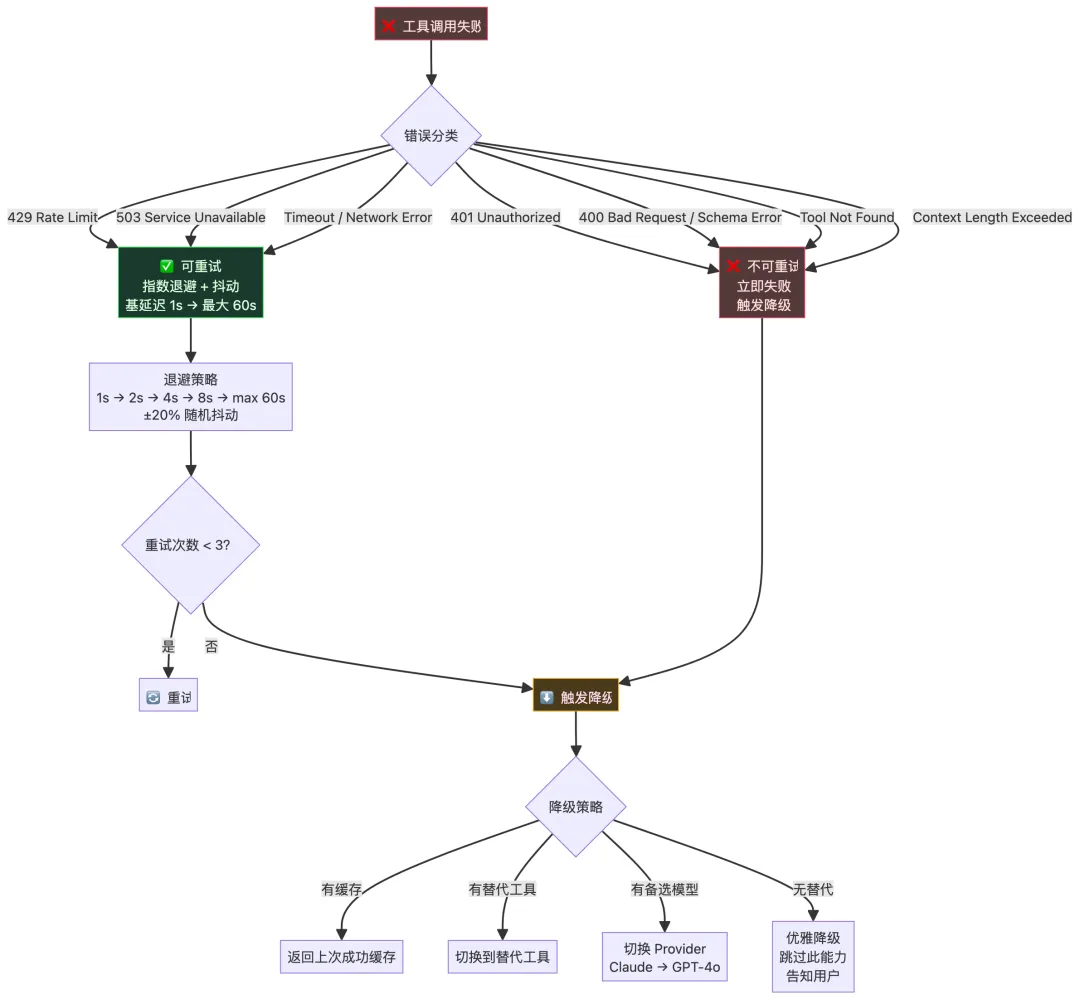
3.5 第四道防线:自动重试与降级
不是所有错误都该重试。关键在于错误分类:
智能重试的四个核心机制:
1. 错误分类器(决定"要不要重试"):
┌─────────────────────────────────────────┐
│ 可重试: │
│ 429 Rate Limit → 等一等就好 │
│ 503 Overloaded → 对方暂时忙 │
│ Timeout → 网络波动 │
│ Network Error → 传输层问题 │
│ │
│ 不可重试: │
│ 401 Unauthorized → 重试没用,权限不够 │
│ 400 Bad Request → 参数错了,重试也错 │
│ Tool Not Found → 工具不存在 │
│ Context Too Long → 上下文爆了,只会更爆│
└─────────────────────────────────────────┘
2. 指数退避 + 去相关抖动(决定"等多久"):
公式: delay = min(base * 2^attempt + random_jitter, max_delay)
示例: 1s → 2.3s → 4.7s → 8.1s (max 60s)
抖动: ±20% 随机偏移,防止"惊群效应"
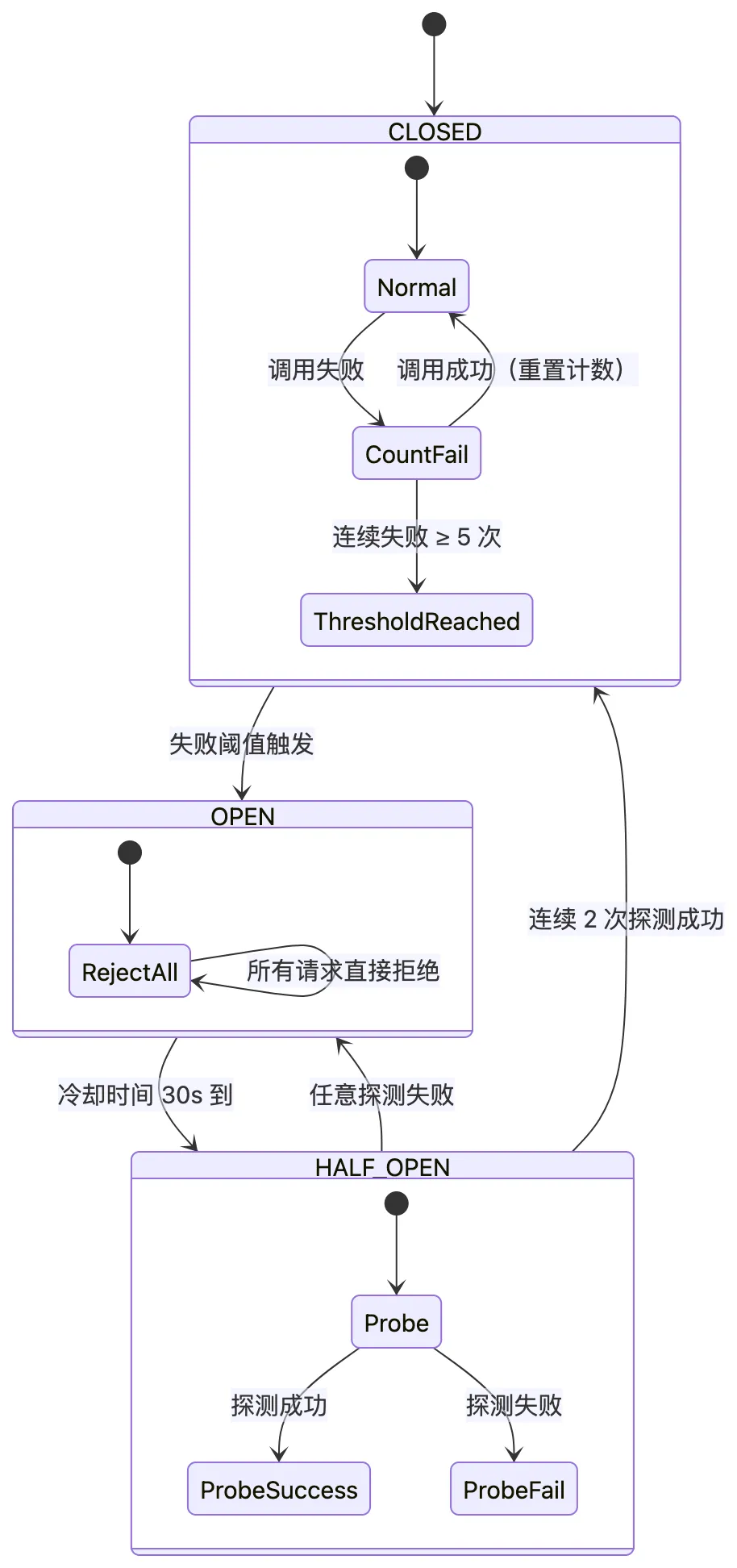
3. 熔断器(决定"什么时候放弃"):
三态机: CLOSED → OPEN → HALF_OPEN → CLOSED
条件: 连续 5 次失败 → OPEN(直接拒绝 30s)
30s 后 → HALF_OPEN(放行 1-3 个探测请求)
探测成功 → CLOSED(恢复正常)
4. 优雅降级链(决定"失败了怎么办"):
优先: 使用缓存的上次成功结果
其次: 切换到功能相似的替代工具
再次: 切换到备选模型 Provider
最终: 跳过此能力,告知用户当前限制
|
3.6 第五道防线:迭代限制(硬上限)
软性检测(循环检测、重试计数)可能失效。最后一道防线是硬性上限——无条件的终止条件:
三重硬上限(必须全部配置):
1. max_iterations(最大迭代次数):
作用: Agent 循环的绝对步数上限
典型值: 简单任务 10 | 中等任务 32 | 复杂任务 100
触发后: 强制终止,输出当前状态
注意: 设太大 → $47,000 悲剧;设太小 → 正常任务被截断
2. token_budget(Token 预算):
作用: 总 Token 消耗上限
典型值: 简单任务 50K | 中等任务 200K | 复杂任务 1M
触发后: 在 80% 时预警,95% 时准备终止,100% 时强制停止
优势: 比 max_iterations 更精确地控制成本
3. wall_clock_deadline(时钟截止):
作用: 真实时间的绝对截止
典型值: 单步 2min | 任务 10min | 工作流 30min
触发后: 保存当前状态,优雅退出(不是 kill -9)
场景: 防止 Agent 在半夜把服务器跑崩
配置建议:
- 三者同时配置,取最先触发的
- 80% 时发出早期预警,给人工介入留时间
- 触发后必须保存状态(Memory),支持从断点恢复
|
3.7 第六道防线:上下文压缩时的协议保护
当 Agent 长时间运行,Context Window 满了需要压缩(Compaction)时,一个隐蔽的 Bug 出现了:压缩可能破坏 tool_use / tool_result 的配对关系。
问题场景:
1. Agent 执行了 50 轮工具调用
2. Context Window 接近 200K 上限
3. 系统触发压缩:删除"旧"消息以腾出空间
4. 压缩算法删除了 tool_result,但保留了 tool_use
5. API 调用时:tool_use 存在但 tool_result 缺失 → 400 错误
6. 或者 tool_use 被删但 tool_result 还在 → 孤立的 tool_result
解决方案:原子配对压缩
原则1: tool_use + tool_result 作为原子单元 —— 要么都保留,要么都删除
原则2: 压缩前验证 —— 检查是否有"孤儿"tool_use 或 tool_result
原则3: 孤儿恢复 —— 对缺失的 tool_result 注入合成错误:
{ is_error: true, content: "Tool result lost during context compaction" }
原则4: 压缩循环熔断 —— 如果连续 3 次压缩都失败,停止重试
|
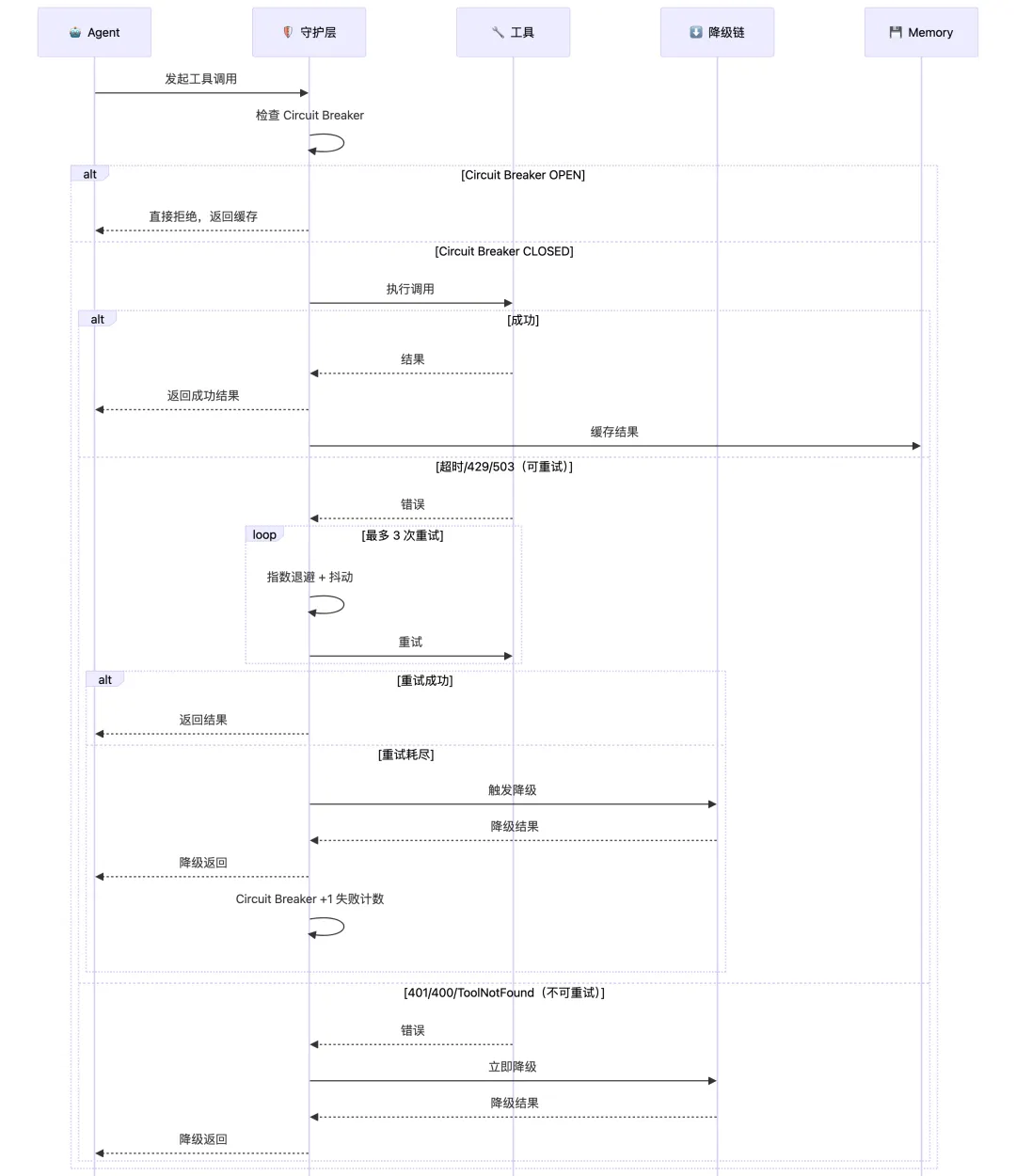
四、AI Agent 如何保证自动重试和降级?
4.1 完整的自愈流程
4.2 降级策略的四级火箭
Level 1: 缓存降级(最快,无额外成本):
条件: 该工具在最近 5 分钟内有成功调用,且参数相同
行为: 直接返回缓存结果,标记为 from_cache
适用: 查询类工具(搜索、读取、列表)
不适用: 写入类工具(创建、更新、删除)——副作用不可缓存
Level 2: 工具降级(功能略减,但可用):
条件: 首选工具不可用,但存在功能相似的替代工具
示例:
首选: database_query_prod() → 超时
降级: database_query_replica() → 数据可能延迟 5s,但可用
行为: 自动切换,告知 Agent "当前使用备用数据源"
Level 3: 模型降级(跨 Provider 故障转移):
条件: 当前模型 Provider 完全不可用(非单次 429)
示例:
首选: Claude Opus(Anthropic)→ Provider 故障
降级: GPT-4o(OpenAI)→ 自动切换
行为: Circuit Breaker 触发 → Provider 级切换 → 后续请求走备用 Provider
Level 4: 能力降级(部分功能不可用):
条件: 所有替代方案都不可用
示例:
Agent 无法访问知识库 → 基于训练数据回答,标注"知识库暂时不可用"
Agent 无法创建 PR → 生成 patch 文件,告知用户手动操作
行为: 不崩溃,继续执行可用部分的逻辑
|
4.3 熔断器的三态机设计
熔断器的配置参数:
| 参数 | 典型值 | 说明 |
|---|
| | |
| | |
| | |
| | |
| RateLimitError, APIError, TimeoutError | |
五、生产环境最佳实践全景图
工具调用稳定性的最终配置清单:
┌─ 工具数量管理 ─────────────────────────────┐
│ ✅ 轻量 Agent: 5-15 个工具,全部加载 │
│ ✅ 中等 Agent: 15-30 个,启用 Tool Search │
│ ✅ 重型 Agent: 50+ 个,Tool Search + 延迟加载 │
│ ✅ 工具定义定期审查,移除 30 天未使用的工具 │
└────────────────────────────────────────────┘
┌─ 并行调用可靠性 ───────────────────────────┐
│ ✅ 结果按 tool_use 顺序排列,非完成顺序 │
│ ✅ 所有结果放在一条 user message 中 │
│ ✅ 独立失败不中止兄弟调用 │
│ ✅ tool_use_id 使用标准格式并做中间件校验 │
└────────────────────────────────────────────┘
┌─ 异常处理六道防线 ─────────────────────────┐
│ ✅ L0: 调用前校验(工具存在性 + Schema) │
│ ✅ L1: 分层超时(10s/30s/5min) │
│ ✅ L2: 格式校验(Schema + ID 匹配) │
│ ✅ L3: 循环检测(重复/序列/多样性) │
│ ✅ L4: 智能重试 + 四级降级 │
│ ✅ L5: 硬上限(iterations/tokens/clock) │
│ ✅ L6: 上下文压缩协议保护(原子配对) │
└────────────────────────────────────────────┘
┌─ 重试与降级 ───────────────────────────────┐
│ ✅ 错误分类:可重试 vs 不可重试 │
│ ✅ 退避策略:指数退避 + 去相关抖动 │
│ ✅ 熔断器:三态机,保护上游 │
│ ✅ 降级链:缓存 → 替代工具 → 替代模型 → 优雅降级 │
│ ✅ 可观测:每次重试/降级都记录日志 │
└────────────────────────────────────────────┘
┌─ 监控与告警 ───────────────────────────────┐
│ ✅ 工具调用成功率(按工具分) │
│ ✅ P50/P95/P99 延迟 │
│ ✅ 重试率 / 降级率 / 熔断触发次数 │
│ ✅ 循环检测触发次数 │
│ ✅ Token 消耗速率 │
│ ✅ 80% 预算时预警,95% 时告警 │
└────────────────────────────────────────────┘
|
六、总结
Agent 工具调用的稳定性是 AI 工程从"能跑"走向"可靠"的关键分水岭。核心要点:
- 工具数量不是越多越好——Context Window 和成本共同定义了"有效工具数",Tool Search 是突破上限的关键
- 并行调用的上下文管理依赖
tool_use_id 配对、结果按请求顺序排列、以及"一条消息"的铁律 - 异常处理需要六道防线:前置校验 → 超时控制 → 格式校验 → 循环检测 → 智能重试降级 → 硬上限兜底
- 重试的前提是分类——只有 429、503、Timeout 值得重试;格式错误和权限错误重试没有意义
- 降级让系统"优雅地不完美"——缓存降级 → 工具降级 → 模型降级 → 能力降级,逐级兜底
- 可观测性是稳定性的前提——看不到的失败等于不存在,直到账单告诉你它存在了很久
💡 一句话记住 Agent 工具调用稳定性:模型的能力决定 Agent 能飞多高,工具调用的可靠性决定 Agent 能飞多远。前者是上限,后者是底线。
 夜雨聆风
夜雨聆风