 夜雨聆风
夜雨聆风写在文章开头
笔者现在大部分时间都在审查 AI 写的代码,日常的线程池调优也基本是结合生产实际情况来设参数——有时候,标准的做法不一定是最好的。
举个例子,一个长时间运行、偶尔才突发一次小高峰的并发任务场景,其实并不一定需要养一个常驻线程池。临时用 fixpool 跑完就关,反而能避免非必要的内存占用,也能避免被未充分了解上下文的同事滥用。
当然这只是个引子,真把线程池用对,还得回到原理上。本文笔者就带你把核心参数、工作流程、状态机到拒绝策略一行行啃透,再用几个真实翻车的案例,讲清楚为什么不建议直接用 Executors、参数到底该怎么调。
SharkChili · 禅与计算机程序设计的艺术
开源项目
mini-redis:笔者用 Go 从零手写的教学级 Redis,适合对着源码把缓存与网络底层一行行啃透,欢迎 Star 和交流 · https://github.com/shark-ctrl/mini-redis
如果想进一步交流,欢迎关注笔者的公众号 写代码的SharkChili ,发送关键字 【加群】 添加笔者好友、进技术交流群。
详解线程池核心知识点
为什么需要线程池
我们可以从性能、资源、安全等角度来回答这个问题:
提高响应速度:从性能角度来说,通过线程池进行池化统一管理线程,使用时直接通过线程池获取,不再需要手动创建线程,响应速度大大提高。 降低资源消耗:创建一个线程并不是免费的——需要陷入内核态向操作系统申请资源、分配默认约 1MB 的线程栈、再注册进调度器,销毁时也要回收。在高并发下频繁地创建、销毁线程,这部分开销相当可观。线程池通过复用固定的一批线程,正是把这部分反复创建销毁的成本给摊掉了。 便于管理和监控:因为我们的工作线程都来自于线程池中所以对于线程的监控和管理自然方便了许多。
线程池使用示例
接下来我们展示了一个非常简单的demo,创建一个含有3个线程的线程池,提交3个任务到线程池中,让线程池中的线程执行。 完成后通过shutdown停止线程池,线程池收到通知后会将手头的任务都执行完,再将线程池停止,笔者这里用awaitTermination阻塞当前线程,直到线程池完全终结后再退出方法。
//创建含有3个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//提交3个任务到线程池中
for (int i = 0; i < 3; i++) {
finalint taskNo = i;
threadPool.execute(() -> {
log.info("执行任务{}", taskNo);
});
}
//关闭线程池,不再接受新任务
threadPool.shutdown();
//阻塞等待线程池中已提交的任务全部执行完毕
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
对应输出结果如下:
10:38:51.993 [pool-1-thread-3] INFO com.sharkChili.Main - 执行任务2
10:38:51.993 [pool-1-thread-2] INFO com.sharkChili.Main - 执行任务1
10:38:51.993 [pool-1-thread-1] INFO com.sharkChili.Main - 执行任务0
详解线程池核心参数
我们上文通过Executors框架创建了线程池,它底层是通过ThreadPoolExecutor完成线程池的创建:
publicstatic ExecutorService newFixedThreadPool(int nThreads){
returnnew ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
可以看到ThreadPoolExecutor的构造方法包含下面几个参数,它们分别是:
corePoolSize:核心线程数,即使空闲也会保留在线程池中的线程。maximumPoolSize:线程池允许创建的最大线程数,例如配置为10,那么线程池中最大的线程数就为10。keepAliveTime:核心线程数以外的线程的生存时间,例如corePoolSize为2,maximumPoolSize为5,假如我们线程池中有5个线程,核心线程以外有3个,这3个线程如果在keepAliveTime的时间内没有被用到就会被回收。这里要补充一个容易被忽略的开关:默认情况下核心线程即使空闲也不会被回收,但如果调用了allowCoreThreadTimeOut(true),核心线程在空闲超过keepAliveTime后同样会被回收。所以对内存资源敏感、又能接受核心线程随用随建的场景,建议开启这个参数,让空闲的核心线程也被释放,省下常驻线程的内存开销。unit:keepAliveTime的时间单位。workQueue:当核心线程都在忙碌时,任务都会先放到队列中。threadFactory:线程工厂,用户可以通过这个参数指定创建线程的线程工厂。handler:当线程池无法接受新的任务时,就会根据这个参数做出拒绝策略,默认拒绝策略是直接抛异常。
对应的构造方法如下所示:
publicThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler){
//......
}
线程池的工作流程
从ThreadPoolExecutor的execute方法我们大体可以窥探到其内部核心逻辑:
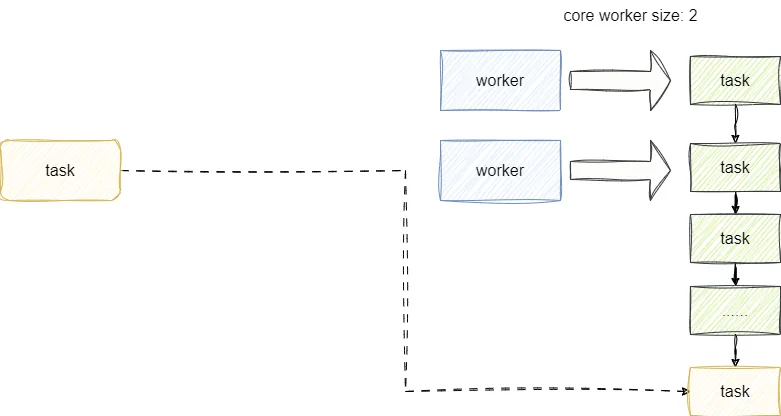
如果工作的线程小于核心线程数,则调用 addWorker创建线程并执行我们传入的任务。如果核心线程都在工作,则调用 workQueue.offer(command)将我们提交的任务放到队列中。如果队列也放不下了,则调用 addWorker新建非核心线程,直接执行当前这个入队失败的任务(线程总数不超过maximumPoolSize)。如果还有新的任务接入且当线程数达到 maximumPoolSize时,说明已经无法容纳任务了,则调用reject(command)按照拒绝策略处理任务。
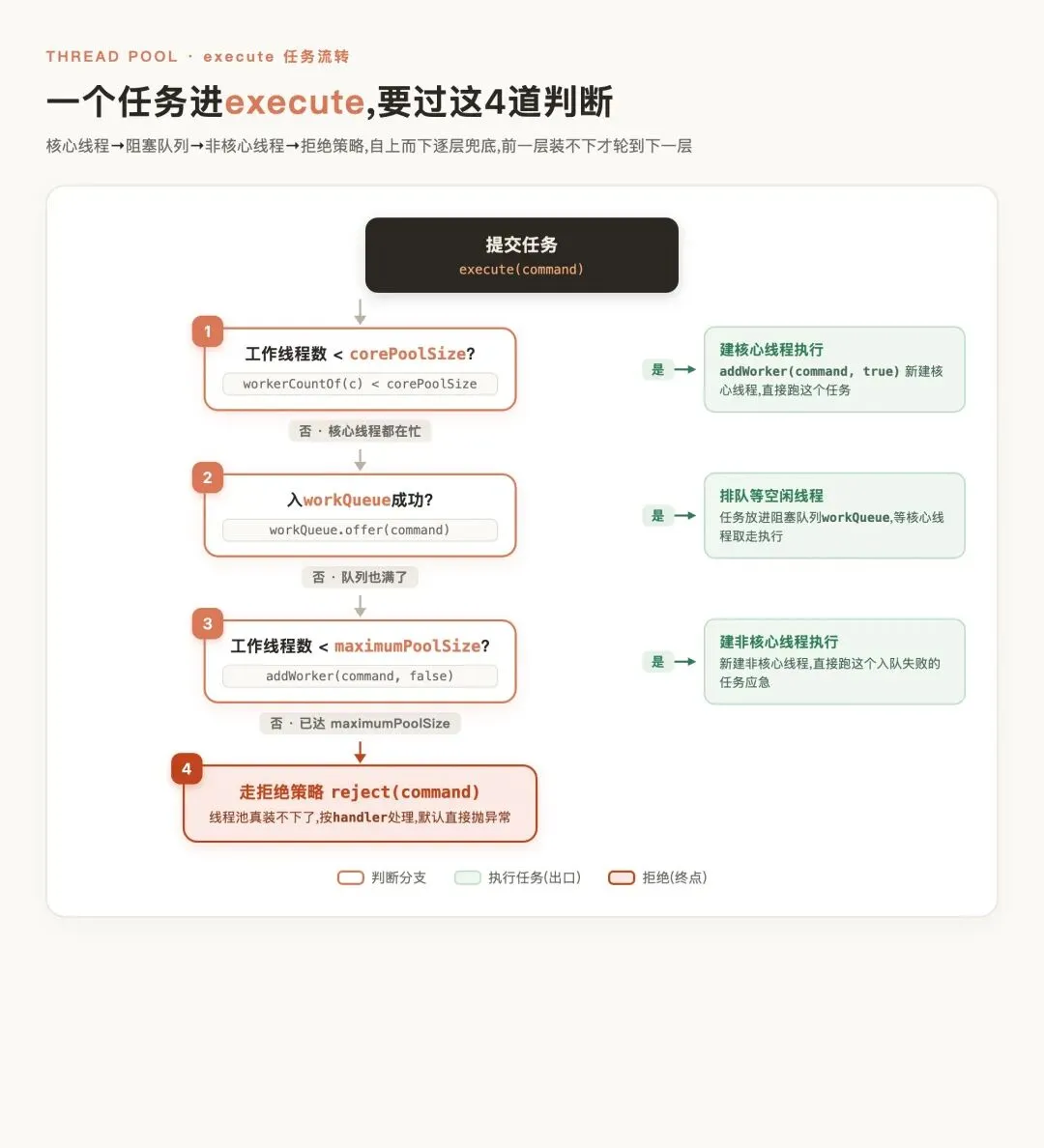
对应的我们给出execute的源码核心逻辑,读者可自行参阅:
publicvoidexecute(Runnable command){
//......
//工作线程数小于核心线程数,则创建线程线程处理传入的任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {//核心线程都在工作则将任务存入阻塞队列
//......
}
elseif (!addWorker(command, false))//队列无法容纳则继续创建线程应急处理,如果创建失败说明当前线程超过maximumPoolSize,则调用reject按照拒绝策略处理任务
reject(command);
}
线程池的几种状态
ThreadPoolExecutor用一个int(源码里的ctl)同时存了两份信息:高 3 位记录运行状态,低 29 位记录工作线程数。下面几个状态值都是把状态码左移COUNT_BITS(29)位得到的,所以RUNNING = -1 << COUNT_BITS其实是个负数。这种把状态和计数打包进一个int、再靠位运算分别取用的做法,比起用两个变量分开存,既省空间,又能用一次 CAS 同时改动状态和线程数,对应的线程池状态和注释如下:
//RUNNING 说明线程正处于运行状态,正在处理任务和接受新的任务进来
privatestaticfinalint RUNNING = -1 << COUNT_BITS;
//说明线程收到关闭的通知了,继续处理手头任务,但不接受新任务
privatestaticfinalint SHUTDOWN = 0 << COUNT_BITS;
//STOP说明线程停止了不处理任务也不接受任务,即时队列中有任务,我们也会将其打断。
privatestaticfinalint STOP = 1 << COUNT_BITS;
//表明所有任务都已经停止,记录的任务数量为0
privatestaticfinalint TIDYING = 2 << COUNT_BITS;
//线程池完全停止了
privatestaticfinalint TERMINATED = 3 << COUNT_BITS;

线程池的几种拒绝策略
AbortPolicy:这个拒绝策略在无法容纳新任务的时候直接抛出异常,这种策略是线程池默认的拒绝策略。
publicstaticclassAbortPolicyimplementsRejectedExecutionHandler{
publicAbortPolicy(){ }
publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e){
thrownew RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
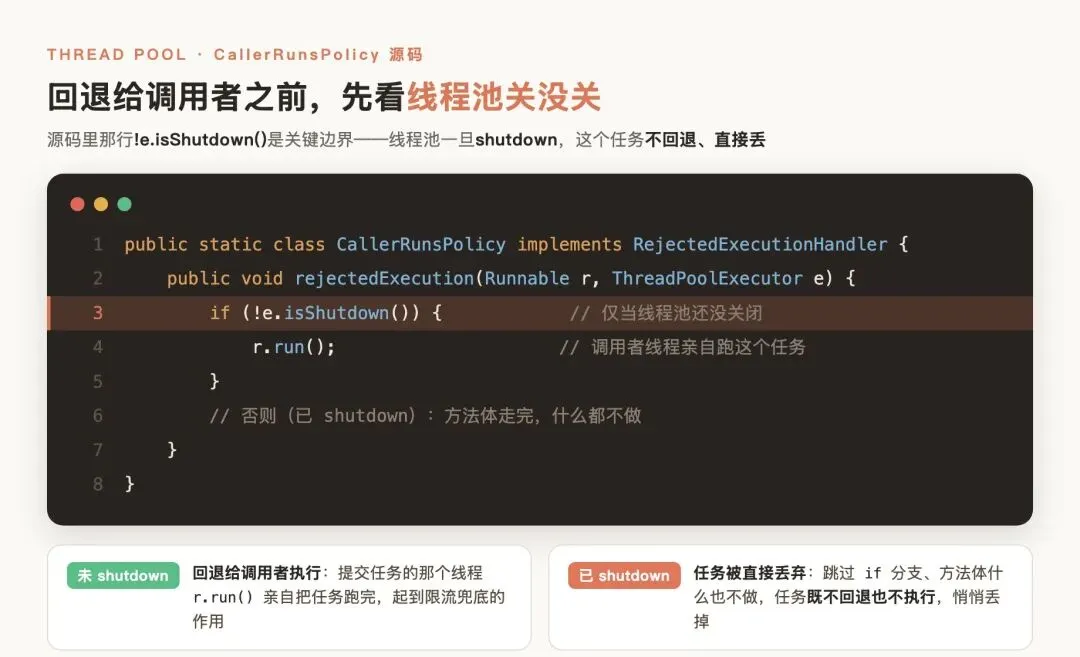
CallerRunsPolicy:从源码中可以看出,当线程池无法容纳新任务时,会把当前任务回退给调用者(也就是提交任务的那个线程)执行。但这里有个容易忽略的边界:源码先判断了!e.isShutdown(),只有线程池还没关闭时才回退给调用者跑,要是线程池已经shutdown,这个任务会被直接丢弃、并不会执行。
publicstaticclassCallerRunsPolicyimplementsRejectedExecutionHandler{
publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e){
//......
//让当前提交任务的线程运行
if (!e.isShutdown()) {
r.run();
}
}
}
DiscardOldestPolicy :顾名思义,当线程池无法最新任务时,会将队首的任务丢弃,将新任务存入。
publicstaticclassDiscardOldestPolicyimplementsRejectedExecutionHandler{
publicDiscardOldestPolicy(){ }
publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e){
if (!e.isShutdown()) {
//将队首元素poll掉,并将当前任务提交
e.getQueue().poll();
e.execute(r);
}
}
}
DiscardPolicy:从源码中可以看出这个策略什么也不做,相当于直接将当前任务丢弃。
publicstaticclassDiscardPolicyimplementsRejectedExecutionHandler{
publicDiscardPolicy(){ }
//什么都不做直接即丢弃当前任务
publicvoidrejectedExecution(Runnable r, ThreadPoolExecutor e){
}
}
线程两种任务提交方式
首先是execute,任务提交后直接按流程执行,没有返回值,源码上文已经给出,这里不再赘述。而submit会把传进来的任务封装成RunnableFuture,再把Future返回出去,调用者可以通过get方法获取执行结果:
public <T> Future<T> submit(Callable<T> task){
if (task == null) thrownew NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
//提交任务
execute(ftask);
//返回Future,后续我们可以通过get获取结果
return ftask;
}
对应的我们也给出使用示例:
@Test
voidbaseUse()throws ExecutionException, InterruptedException {
//创建含有3个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
//提交3个任务到线程池中
for (int i = 0; i < 3; i++) {
finalint taskNo = i;
Future<Integer> future = threadPool.submit(() -> {
logger.info("执行任务{}", taskNo);
return1;
});
logger.info("处理结果:{}", future.get());
}
//关闭线程池,不再接受新任务
threadPool.shutdown();
//阻塞等待线程池中已提交的任务全部执行完毕
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
输出结果:
00:24:41.204 [pool-1-thread-1] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务0
00:24:41.208 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1
00:24:41.209 [pool-1-thread-2] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务1
00:24:41.209 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1
00:24:41.209 [pool-1-thread-3] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 执行任务2
00:24:41.209 [main] INFO com.example.javacommonmistakes100.JavaCommonMistakes100ApplicationTests - 处理结果:1
线程池的关闭方式
线程池的停止方式有两种:
shutdown:笔者上述代码示例用的都是这种方式,使用这个方法之后,我们无法提交新的任务进来,线程池会继续工作,将手头的任务执行完再停止:
publicvoidshutdown(){
//上锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查并设置状态,不再接受新任务
checkShutdownAccess();
advanceRunState(SHUTDOWN);
//打断空闲的线程
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
//停止线程池
tryTerminate();
}
shutdownNow:这种方式就强硬多了。它会把线程池状态置为STOP,给所有工作线程发出中断信号,并把队列中尚未执行的任务移除、作为List<Runnable>返回给调用者。要注意中断只是请求线程停止,能否真正停下取决于任务是否响应中断——如果任务是不响应中断的纯计算或死循环,shutdownNow 也无法强行杀死它,只能等它自己结束(Java 早已废弃了Thread.stop这种强杀线程的危险做法):
public List<Runnable> shutdownNow(){
List<Runnable> tasks;
//上锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//设置状态为stop强行停止
checkShutdownAccess();
advanceRunState(STOP);
//打断空闲线程
interruptWorkers();
//移除队列中的任务
tasks = drainQueue();
} finally {
mainLock.unlock();
}
//停止线程池
tryTerminate();
return tasks;
}
这一点放到 AI 编程时代尤其值得留意。让 AI 帮你写优雅停机,它十有八九甩你一个shutdownNow()就当任务停了,可它默认不会管两件事:一是不响应中断的任务根本停不掉、会把停机流程拖住,二是shutdownNow返回的那批未执行任务该怎么处理。到底要不要兜住这批任务,得开发者结合当前业务的性质来判断——如果这些任务无关紧要、丢了也没影响,那不管也行,但如果是订单、扣款这类一条都不能丢的任务,就必须接住shutdownNow返回的List<Runnable>做持久化或重试补偿。这种取舍 AI 给不了,得你先把业务约束想清楚再定。

非核心线程创建与调度饥饿问题
了解了线程池整体工作原理后,读者是否想过,为什么先要用corePoolSize核心线程,然后当核心线程处理不过来时将异步任务先放到workQueue中,而不是直接开maximumPoolSize的线程数继续处理应急任务呢?如果按照当前的线程池执行流程不就存在一个饥饿问题?即后来的任务可能会比存在于队列中的任务先执行:

其实回答这个问题,其实我们可以通过反证法来解释,假设任务处理不过来之后,直接创建maximumPoolSize个线程处理任务,那么就会存在以下几个问题:
仅仅因为核心线程数处理不来任务就认为是应急情况,这会导致应急线程被提前创建,这就可能存在频繁创建和销毁线程的性能损耗,例如核心线程为4,某个时间段刚好来了5个异步任务,仅仅因为多了一个任务,在没有任何缓冲的情况下,直接创建应急线程然后被销毁,这就会导致这种不合理的性能损耗。 资源消耗:创建完最大线程之后,线程有可能处于空闲中,这也不能意味着线程没有任何开销,一旦线程被启动对于CPU、内存而言都是存在一定的资源开销的,如果 maximumPoolSize线程数过大,对于系统资源占用也是非常不划算的。
总的来说,设计者们认为只有缓冲区处理不来(队列容纳不下)的情况下才能开启应急线程是一种对于应急情况的判断依据,由此避免了非应急情况创建应急线程的开销:
//存入阻塞队列失败后,才会尝试调用addWorker开启非核心线程,即通过阻塞队列的阈值来作为应急情况判断的依据
if (isRunning(c) && workQueue.offer(command)) {
//......
}
elseif (!addWorker(command, false))//如果非核心线程开启失败,则执行拒绝策略
reject(command);
再来回答另一个问题,即任务饥饿问题,这确实在一定情况下会存在,但笔者认为只要线程池参数设定得当,在非核心线程启动之后,这些堆积在阻塞队列的任务在一定时间后就会被任意抽身出来的线程从队列中取出并处理,对应的我们给出每一个worker线程的执行逻辑即ThreadPoolExecutor的runWorker方法:
finalvoidrunWorker(Worker w){
Thread wt = Thread.currentThread();
//......
try {
//从阻塞队列中获取任务task
while (task != null || (task = getTask()) != null) {
//......
try {
//......
try {
//执行任务
task.run();
} catch (RuntimeException x) {
//......
} finally {
afterExecute(task, thrown);
}
} finally {
//......
}
}
//......
} finally {
processWorkerExit(w, completedAbruptly);
}
}
当然如果读者对于任务公平有着严格要求同时系统资源也足够充分,完全可以考虑通过Executors.newSingleThreadExecutor()这种只有一个线程的线程轮询处理阻塞队列的任务模式,来保证异步任务顺序性和公平性:

对应的我们也给出singleThreadExecutor的核心实现,读者也可以参考源码了解一下:
publicstatic ExecutorService newSingleThreadExecutor(){
returnnew FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
线程池使用注意事项
避免使用Executors的newFixedThreadPool
接下来我们来看看日常使用线程池时一些错误示例,为了更好的看到线程池的变化,我们编写这样一个定时任务去监控线程池的变化。
/**
* 打印线程池情况
*
* @param threadPool
*/
privatevoidprintStats(ThreadPoolExecutor threadPool){
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("=========================");
log.info("Pool Size:{}", threadPool.getPoolSize());
log.info("Active Threads:{}", threadPool.getActiveCount());
log.info("Number of Tasks Completed: {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue:{}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}
先来看看这样一段代码,我们循环1亿次,每次创建这样一个任务:生成一串大字符串,休眠一小时后打印输出。
@GetMapping("oom1")
publicvoidoom1(){
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
printStats(threadPool);
for (int i = 0; i < 1_0000_0000; i++) {
threadPool.submit(() -> {
String payload = IntStream.rangeClosed(1, 100_0000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info(payload);
});
}
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
}
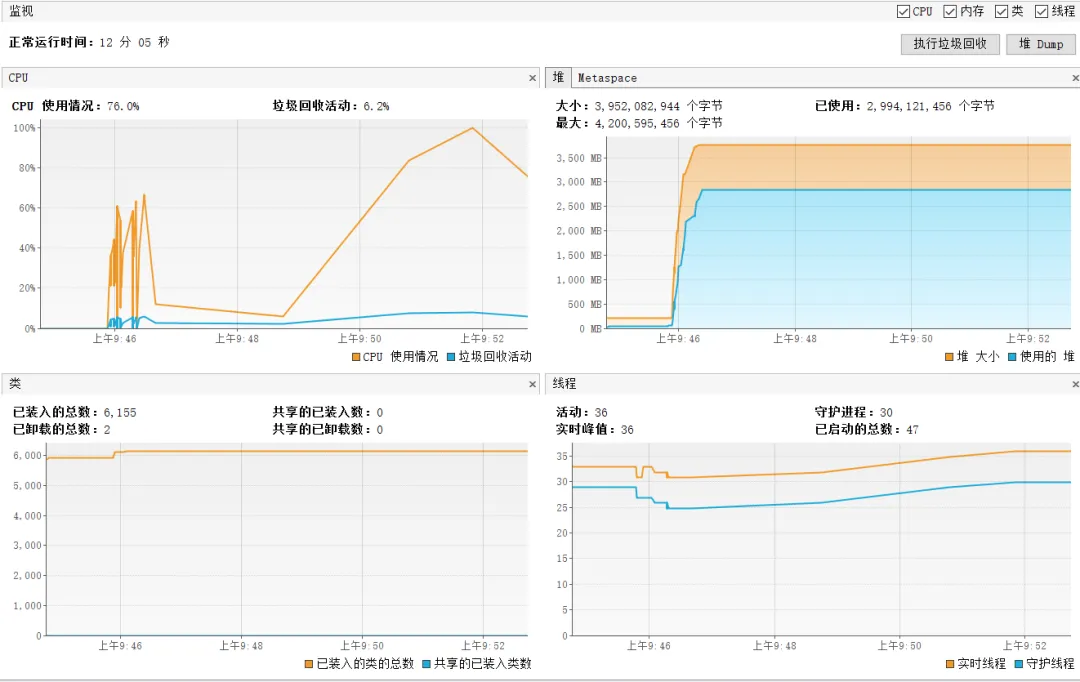
项目启动后使用jvisualvm监控项目的变化:
可以看到此时CPU使用情况,堆区、还有线程数使用情况都是正常的。
然后我们对刚刚的接口发起请求
curl http://localhost:8080/threadpooloom/oom1
我们先来看看控制台输出,可以看到线程数没有增加,而队列的任务却不断累积。

看看jvisualvm,此时堆区内存不断增加,尽管发生了几次GC,还是没有回收到足够的空间。最终引发OOM问题。
我们通过源码来观察一下newFixedThreadPool的特征,可以看到它的核心线程数和最大线程数都是传进来的值,这意味着无论多少个任务进来,线程数都是nThreads。如果我们没有足够的线程去执行的任务的话,任务就会堆到LinkedBlockingQueue中,从源码中我们也能看出,LinkedBlockingQueue是无界队列(底层是通过链表实现的):
publicstatic ExecutorService newFixedThreadPool(int nThreads){
returnnew ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
避免使用Executors的newCachedThreadPool
再来看看第二段代码,同样的任务提交到newCachedThreadPool中,我们看看会发生什么。
@GetMapping("oom2")
publicvoidoom2(){
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newCachedThreadPool();
printStats(threadPool);
for (int i = 0; i < 1_0000_0000; i++) {
threadPool.submit(() -> {
String payload = IntStream.rangeClosed(1, 100_0000)
.mapToObj(__ -> "b")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info(payload);
});
}
threadPool.shutdown();
while (!threadPool.isTerminated()) {
}
}
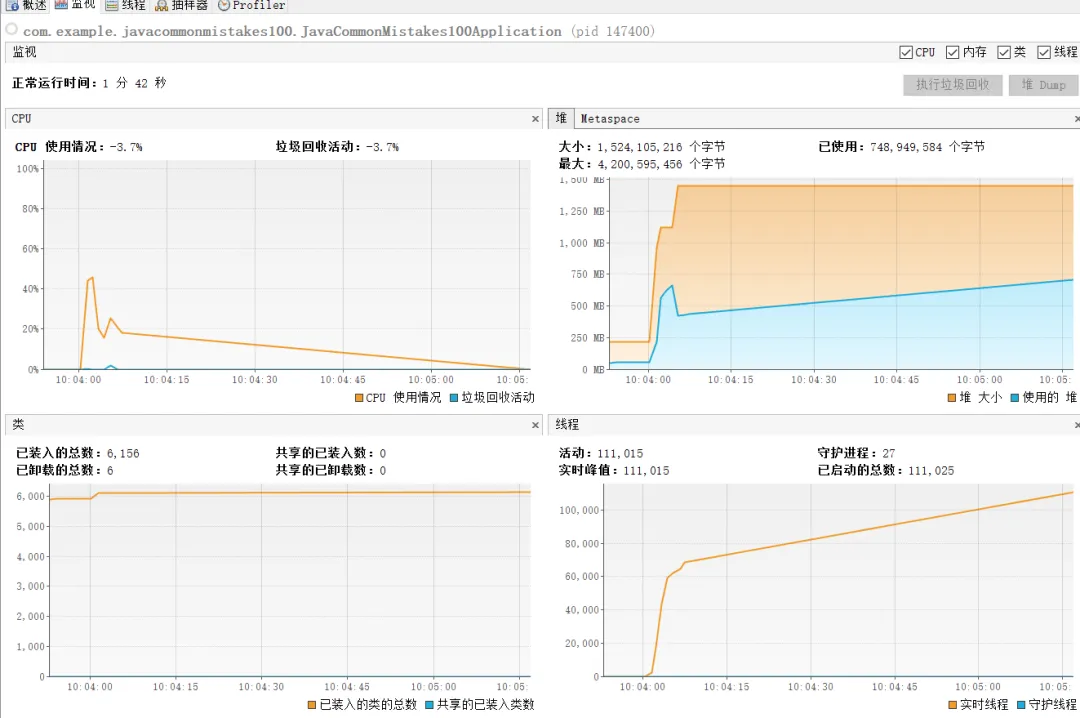
先来看看控制台,可以看到线程数正在不断的飙升。

从jvisualvm也能看出堆区和线程数也在不断飙升,最终导致OOM。
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation(malloc) failed to allocate 32744 bytes for ChunkPool::allocate
# An error report file with more information is saved as:
# F:\github\java-common-mistakes-100\hs_err_pid147400.log
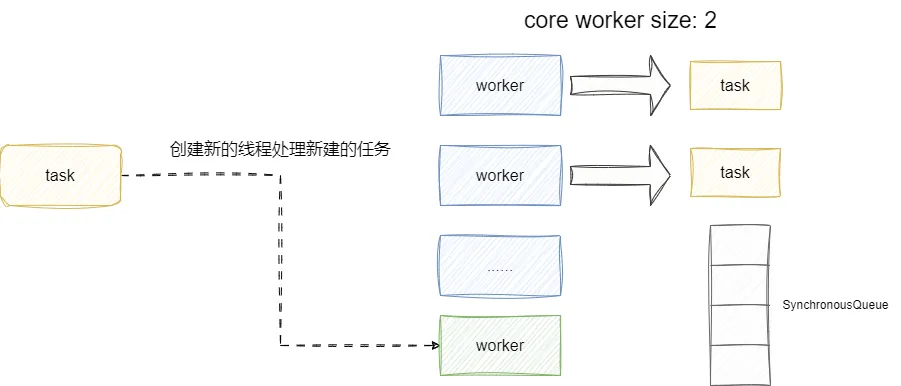
我们来看看newCachedThreadPool源码,可以看到这个线程池核心线程数初始为0,最大线程数为Integer.MAX_VALUE,而队列使用的是SynchronousQueue,所以这个队列等于不会存储任何任务。
这就意味着我们每次提交一个任务没有线程处理的话,线程池就会创建一个新的线程去处理这个任务,该线程空闲 60s 内没有新任务可处理就会被销毁。
我们的连续1亿次循环提交任务就会导致创建1亿个线程,最终导致线程数飙升,进而引发OOM问题。
publicstatic ExecutorService newCachedThreadPool(){
//队列不可容纳元素,最大线程数设置为Integer.MAX_VALUE
returnnew ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
确保你创建线程池的方式线程可以被复用
我们监控发现某段时间线程会不断飙升,然后急速下降,然后急速上升:
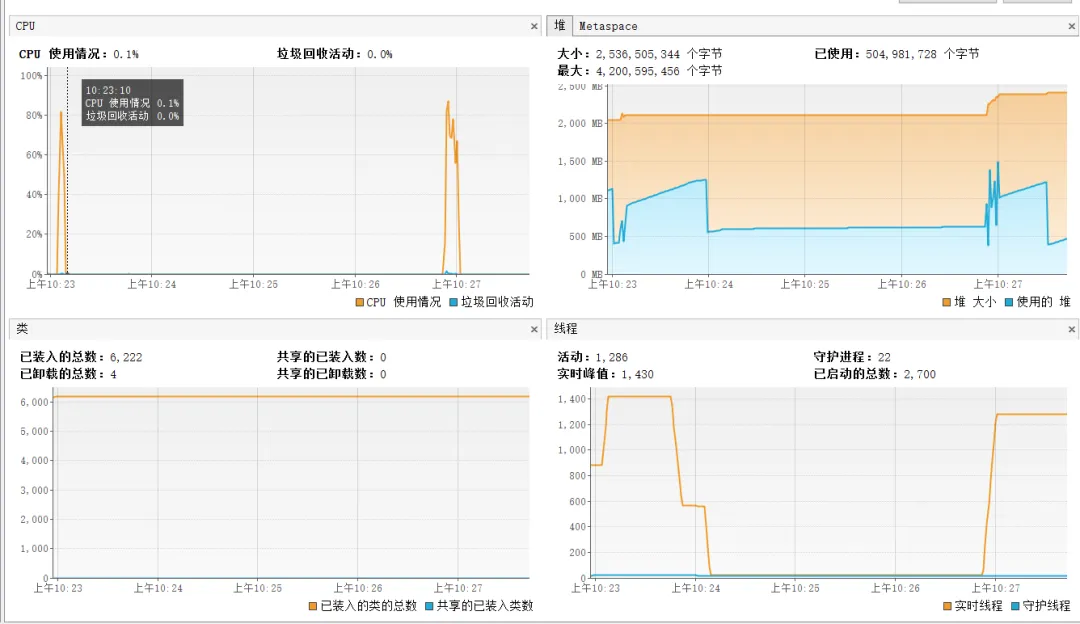
然后我们在线程的栈帧中看到SynchronousQueue,大概率有人使用newCachedThreadPool。
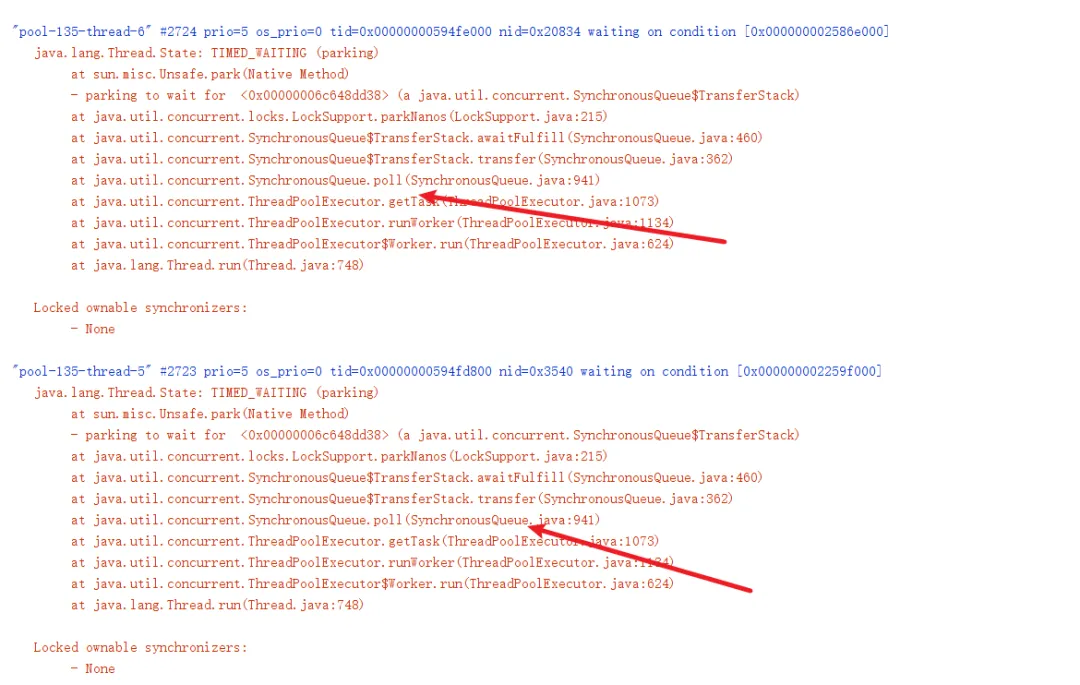
最终通过全局搜索看到这样一段代码,可以看到这个工具类每次请求就会创建一个newCachedThreadPool给用户使用。
staticclassThreadPoolHelper{
publicstatic ThreadPoolExecutor getThreadPool(){
return (ThreadPoolExecutor) Executors.newCachedThreadPool();
}
}
我们定位到调用处,真相就明了了,原来每一次请求都会创建一个newCachedThreadPool处理大量的任务,由于newCachedThreadPool空闲回收时间为 60s,所以线程使用完之后空闲一会儿就被回收了。
@GetMapping("wrong")
public String wrong(){
ThreadPoolExecutor threadPool = ThreadPoolHelper.getThreadPool();
IntStream.rangeClosed(1, 20).forEach(i -> {
threadPool.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
log.debug(payload);
});
});
return"ok";
}
解决方式也很简单,我们按需调整线程池参数,将线程池作为静态变量全局复用即可。
staticclassThreadPoolHelper{
privatestatic ThreadPoolExecutor threadPool = new ThreadPoolExecutor(10,
50,
2,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get());
publicstatic ThreadPoolExecutor getRightThreadPool(){
return threadPool;
}
}
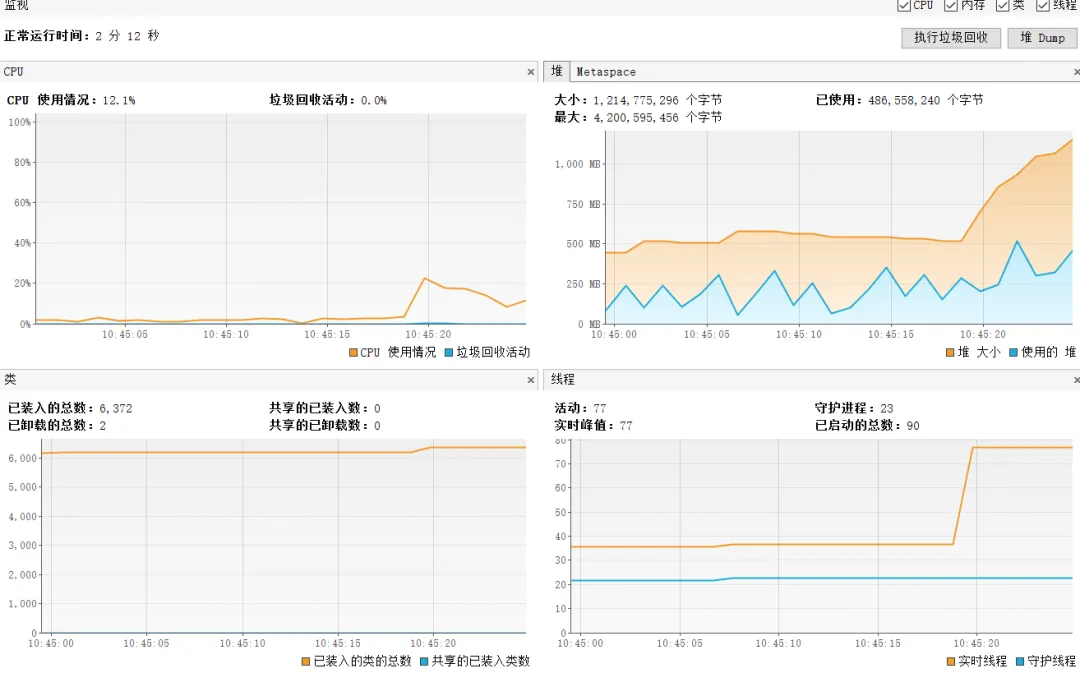
从监控来看线程数正常多了。
仔细斟酌线程混用策略
我们使用线程池来处理一些异步任务,每个任务耗时10ms左右。
@GetMapping("wrong")
publicintwrong()throws ExecutionException, InterruptedException {
return threadPool.submit(calcTask()).get();
}
private Callable<Integer> calcTask(){
return () -> {
log.info("执行异步任务");
TimeUnit.MILLISECONDS.sleep(10);
return1;
};
}
压测的时候发现性能很差,处理时间最长要283ms。
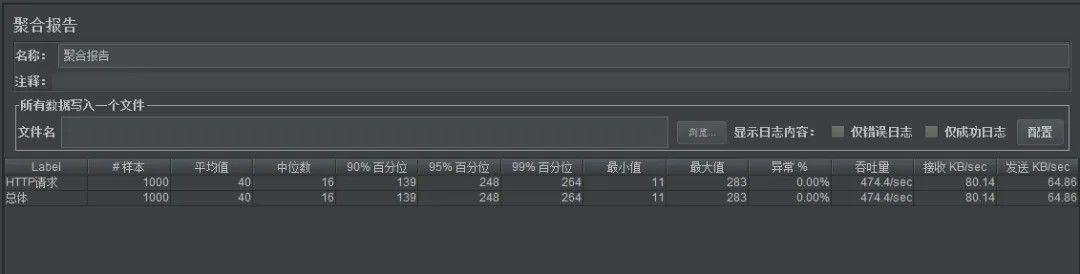
步入线程池发现,线程池的配置如下,只有2个线程和50个队列。
private ThreadPoolExecutor threadPool = new ThreadPoolExecutor(2,
2,
1,
TimeUnit.HOURS,
new ArrayBlockingQueue<>(50),
new ThreadFactoryBuilder().setNameFormat("batchfileprocess-threadpool-%d").get(),
new ThreadPoolExecutor.CallerRunsPolicy());
了解了上面这些概念,我们就拿这段 AI 写的线程池代码实地审查一下。审查 AI 写的这类代码,关键是结合两点:任务的真实类型,以及它在全局被怎么调用。顺着调用看下去,笔者发现这段任务并不像表面那么简单——它要先拼接一个百万字符的大字符串、再写入文件,本质是个偏重的 IO/混合型任务,而且init()里是while(true)在不停地往这个池子灌。可 AI 把它当成了偶发的轻量任务,只给了 2 个线程,又配了CallerRunsPolicy这种会把溢出任务回灌给调用者线程的拒绝策略。结果就是:池子被打满后,溢出的任务全压到 web 请求线程上,接口被越拖越慢,严重时直接夯死。这正是审查 AI 线程池代码时最该盯住的地方。
@PostConstruct
publicvoidinit(){
printStats(threadPool);
new Thread(() -> {
String payload = IntStream.rangeClosed(1, 100_0000)
.mapToObj(__ -> "a")
.collect(Collectors.joining(""));
while (true) {
threadPool.execute(() -> {
try {
Files.write(Paths.get("demo.txt"), Collections.singletonList(LocalTime.now().toString() + ":" + payload), UTF_8, CREATE, TRUNCATE_EXISTING);
} catch (IOException e) {
e.printStackTrace();
}
// log.info("batch file processing done");
});
}
}, "T1").start();
}
解决方式也很简单,上述线程池并不是为我们这种 IO/混合型任务准备的,所以我们单独为其划分一个线程池出来处理这些任务。
private ThreadPoolExecutor asyncCalcThreadPool = new ThreadPoolExecutor(200,
200,
1,
TimeUnit.HOURS,
new ArrayBlockingQueue<>(50),
new ThreadFactoryBuilder().setNameFormat("asynccalc-threadpool-%d").get(),
new ThreadPoolExecutor.CallerRunsPolicy());
@GetMapping("wrong")
publicintwrong()throws ExecutionException, InterruptedException {
return asyncCalcThreadPool.submit(calcTask()).get();
}
这里多说一句:把线程数定成 200,其实是笔者图省事直接拍的一个演示值。严谨的做法是结合压测和监控数据,量出单个任务里 CPU 计算耗时和 IO 等待耗时的占比,再套前面 IO 型的线程数公式推算出一个合理值。本文为了简单直接给了 200,实际项目里请按压测结果来定。
经过压测可以发现性能明显上来了
使用正确的方式提交任务
假如我们提交给线程池的任务没有返回值,我们建议使用execute。
这一点我们不妨看一下这样一段代码,该代码会循环提交10个算术异常的任务给线程池。可以看到我们提交的任务是没有返回值的,而我们提交任务时却用到了submit。使用submit提交任务时,会返回一个Future对象,通过Future对象我们可以使用get方法阻塞获取任务返回结果。
因为我们的任务是没有返回值的,所以我们提交过程中并没有通过get方法获取返回结果,这就导致了一个隐患——吞异常。
privatestatic ExecutorService threadPool = Executors.newFixedThreadPool(1);
publicstaticvoidmain(String[] args){
for (int i = 0; i < 10; i++) {
//提交一个算术异常的任务
threadPool.submit(() -> {
log.info("开始执行运算");
int r = 1 / 0;
log.info("结束执行运算");
});
}
//等待线程池关闭
threadPool.shutdown();
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
可以看到这段代码的输出结果如下,控制台仅仅输出线程开始工作,却没有输出结果。
09:15:36.940 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
09:15:36.942 [pool-1-thread-1] INFO com.sharkchili.Main - 开始执行运算
这一点,我们通过查看FutureTask的run源码可以得知,FutureTask的run方法执行步骤如下:
调用call方法,执行任务。 得到result后将ran设置为true。 如果执行过程中报错,直接进入catch模块,将result设置为null,并将ran设置为false。 调用setException处理异常。
try { //执行任务,返回一个结果赋值给result
result = c.call();
ran = true;
} catch (Throwable ex) {
//任务抛出异常后,将result设置为null,ran状态设置为false,并调用setException处理异常
result = null;
ran = false;
setException(ex);
}
步入代码查看setException我们可以发现,它会将异常结果赋值给outcome然后调用finishCompletion结束任务,所以如果我们没有主动获取任务结果,那么这个错误就永远不会被感知。
protectedvoidsetException(Throwable t){
//通过cas将结果设置为完成(COMPLETING)值为1
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
//将异常赋值给outcome直接将任务结束
outcome = t;
//通过cas将结果设置为异常(EXCEPTIONAL)值为3
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}
针对上述问题,要想获取异常也很简单,主动调用get获取结果即可:
privatestatic ExecutorService threadPool = Executors.newFixedThreadPool(1);
publicstaticvoidmain(String[] args){
for (int i = 0; i < 10; i++) {
//提交一个算术异常的任务
Future<?> future = threadPool.submit(() -> {
System.out.println(Thread.currentThread().getName() + " do working");
int r = 1 / 0;
System.out.println(r);
});
try {
//通过get阻塞获取任务结果
Object o = future.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
threadPool.shutdown();
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
从输出结果可以看到出现异常后,错误直接抛出,我们就可以及时调试处理了。
pool-1-thread-1do working
java.util.concurrent.ExecutionException: java.lang.ArithmeticException: / by zero
pool-1-thread-1do working
pool-1-thread-1do working
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
pool-1-thread-1do working
pool-1-thread-1do working
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
pool-1-thread-1do working
at com.sharkChili.threadpool.Main.main(Main.java:23)
Caused by: java.lang.ArithmeticException: / by zero
at com.sharkChili.threadpool.Main.lambda$main$0(Main.java:17)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
为什么调用get才能捕获到异常呢?通过查看get源码可以了解到get方法的执行步骤:
获取任务执行状态state。 如果state小于等于COMPLETING (COMPLETING值为1)说明任务尚未完成,则调用awaitDone等待任务完成。如果大于COMPLETING(即大于1)则说明任务已完成,通过上文源码可知我们的任务已经被CAS设置为EXCEPTIONAL(值为3),所以直接调用report。
public V get()throws InterruptedException, ExecutionException {
int s = state;
//如果s小于等于COMPLETING说明任务未完成,调用awaitDone等待完成,再调用report
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
查看report代码我们终于知道原因了,我们任务执行报错所以s的值为3,小于CANCELLED,所以调用了最后一段代码将异常抛出了。
private V report(int s)throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
thrownew CancellationException();
thrownew ExecutionException((Throwable)x);
}
通过上述我们知道的submit使用不当可能存在吞异常的情况以及应对办法,实际上对于没有返回值的任务,我们建议直接使用execute,execute感知异常时会直接将任务抛出:
privatestatic ExecutorService threadPool = Executors.newFixedThreadPool(1);
publicstaticvoidmain(String[] args){
for (int i = 0; i < 10; i++) {
//提交一个算术异常的任务
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " do working");
int r = 1 / 0;
System.out.println(r);
});
}
threadPool.shutdown();
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
从输出结果来看,算术异常直接抛出,被主线程感知了。
pool-1-thread-1do working
Exception in thread "pool-1-thread-1" Exception in thread "pool-1-thread-2" java.lang.ArithmeticException: / by zero
pool-1-thread-2do working
pool-1-thread-3do working
at com.sharkChili.threadpool.Main.lambda$main$0(Main.java:17)
pool-1-thread-4do working
pool-1-thread-5do working
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
pool-1-thread-6do working
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
pool-1-thread-7do working
通过查看execute执行源码,我们可以看到代码调用栈会来到ThreadPoolExecutor的runWorker下面这个代码段的逻辑:
调用 run执行任务。afterExecute收尾任务。如果感知异常则抛出异常throw x。
所以我们的任务会因为算术异常而向上抛出。
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行算数任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; thrownew Error(x);
} finally {
afterExecute(task, thrown);
}
最终代码被JVM感知直接将异常抛到控制台,所以对于没有返回值的任务,我们建议使用execute执行任务。
privatevoiddispatchUncaughtException(Throwable e){
getUncaughtExceptionHandler().uncaughtException(this, e);
}
这里其实藏着一个更本质的点:异步任务跑在线程池的工作线程上,不在你提交任务的那条主链路上,所以任务里抛的异常,提交线程天然感知不到——要么被 submit 包进 Future、不调 get 就石沉大海,要么走 execute 冒泡到工作线程的 UncaughtExceptionHandler。正因为异常脱离了主链路,任务异常的处理才要格外小心:如果这个任务的成败业务上很敏感、必须在调用侧拿到异常来处理,那就用 submit 再用 get() 把异常重新抛回提交线程(注意 get() 会阻塞、本质是把这步同步化了,适合确实需要同步拿结果的场景)。如果只是不想让异常被悄悄吞掉、能打日志告警就够,那 execute 配一个全局 UncaughtExceptionHandler 更合适。最忌讳的是用 submit 又从不 get,异常既不冒泡也没人接,是最隐蔽的坑。
举个业务敏感的例子:异步开通一个用户的账户体系,建主账户、初始化钱包、发默认权益这几步要"一荣俱荣、一损俱损"。我们把它们并行 submit 出去,再逐个 get() 感知异常,一旦有人失败就把已经做成功的步骤补偿掉:
// 开通账户的几个相对独立的子步骤,丢进线程池并行跑
Future<?> fAccount = pool.submit(() -> createAccount(userId)); // 建主账户
Future<?> fWallet = pool.submit(() -> initWallet(userId)); // 初始化钱包
Future<?> fRole = pool.submit(() -> grantDefaultRole(userId)); // 发默认权益
try {
// 逐个 get():任一子步骤在工作线程里抛的异常,都会在这里以 ExecutionException 抛回当前线程
fAccount.get();
fWallet.get();
fRole.get();
} catch (ExecutionException e) {
// 有子步骤失败,对"可能已做成功"的步骤统一补偿回滚(每个回滚都要幂等)
rollbackAccountOpen(userId);
thrownew BizException("账户开通失败,已回滚", e.getCause());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
rollbackAccountOpen(userId);
thrownew BizException("账户开通被中断,已回滚", e);
}
这里要特别说清楚一点:上面这种"出错就回滚"不是数据库级的 ACID 原子性,而是补偿事务(Saga)。因为几个子步骤跑在不同工作线程上,一个本地事务跨不了线程,做不到"要么全成要么全不动",只能事后把已成功的步骤补偿掉,本质是最终一致。所以有两点要记牢:一是每个补偿(回滚)操作都必须幂等,因为并行下你并不确定每步到底做到了哪。二是如果这几步其实在同一个库、能塞进一个本地事务,那就别为并行硬拆,直接 @Transactional 同步执行更简单也更可靠。
顺带一提,上面这套"并行提交 + 汇总异常 + 失败补偿",用 CompletableFuture.allOf(...).exceptionally(...) 写会更顺手,原理是一样的,这里用 submit + Future 是为了贴合本文的层次。

放到审 AI 代码上,这正是要盯死的一点:AI 写异步任务时往往只管把活儿丢进线程池,根本不管异常怎么捞回来——submit 完不 get、execute 不配 UncaughtExceptionHandler,任务里一抛异常就神不知鬼不觉。审的时候先问一句:这个任务的异常,到底由谁、在哪条线程上接住?
避免任务频繁抛出异常
上文提到使用execute提交无返回值的任务,这样异常就会被感知,但还需要注意的是频繁的抛出异常会让线程消亡,导致线程池每次执行新任务时会去创建新的线程。
还是以这段代码为例,我们对于算术异常没有任务处理。
privatestatic ExecutorService threadPool = Executors.newFixedThreadPool(1);
publicstaticvoidmain(String[] args){
for (int i = 0; i < 10; i++) {
//提交一个算术异常的任务
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " do working");
int r = 1 / 0;
System.out.println(r);
});
}
threadPool.shutdown();
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
可以看到我们明明只有一个线程的线程池,每次抛出异常后,都会创建一个新的线程处理任务。
pool-1-thread-1do working
pool-1-thread-2do working
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
at com.sharkChili.threadpool.Main.lambda$main$0(Main.java:17)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Exception in thread "pool-1-thread-2" pool-1-thread-3do working
这一点我们从源码中可知,抛出的异常被JVM感知并调用dispatchUncaughtException方法,该方法会通过getUncaughtExceptionHandler得到线程组,然后调用uncaughtException处理异常。
privatevoiddispatchUncaughtException(Throwable e){
getUncaughtExceptionHandler().uncaughtException(this, e);
}
最终代码会走到e.printStackTrace打印异常堆栈信息并终止任务,销毁线程。
publicvoiduncaughtException(Thread t, Throwable e){
if (parent != null) {
parent.uncaughtException(t, e);
} else {
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} elseif (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}
所以我们建议,对于线程池中的任务,尽可能不要用异常来驱动业务逻辑,对于可以预见的异常,提前用业务手段处理掉,避免线程销毁再创建的开销。
那遇到这种业务,AI 一般会怎么写?大概率给你套一个大 try/catch,把所有异常都兜住:
threadPool.execute(() -> {
try {
int r = 1 / num; // num 可能为 0
System.out.println(r);
} catch (Exception e) { // 兜住一切,worker 线程就不会死
log.error("任务执行失败", e);
}
});
这么写确实能挡住 worker 线程消亡,作为不可预判异常的兜底没问题。但如果这个错误是可预判、而且高频的(比如 num 经常为 0),就别用它来扛了。原因在于:异常真正的开销不在 catch、而在 throw——每抛一次,JVM 都要构造异常对象、尤其要调 fillInStackTrace() 把整条调用栈抓下来,这一步相当贵,高频抛出会把性能悄悄拖垮。
这一点《Effective Java》早有定论:Joshua Bloch 在「Use exceptions only for exceptional conditions」(第 3 版 Item 69)这一条里明确讲,异常是为异常情况设计的,不该拿来做常规控制流——JVM 实现者没什么动力去优化异常路径,把代码塞进 try 块还可能抑制 JIT 的某些优化,所以用异常当控制流往往比显式判断更慢。
对这种可预判的高频错误,更划算的是业务级 fail-fast:在出问题前先判一下、直接 return,根本不让异常产生出来。还是以算术异常为例,我们可以提前判断一下除数,用业务手段处理掉:
privatestatic ExecutorService threadPool = Executors.newFixedThreadPool(1);
publicstaticvoidmain(String[] args){
for (int i = 0; i < 10; i++) {
//提交一个算术异常的任务
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + " do working");
//手动处理业务代码的异常
int num= RandomUtil.randomInt(0,10);
if (num==0){
System.out.println("The divisor cannot be zero. ");
return;
}
int r = 1 / num;
System.out.println(r);
});
}
threadPool.shutdown();
try {
threadPool.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}

审 AI 写的线程池任务,这里要分两层看:它有没有兜底(连 try/catch 都没有,worker 一抛就死),以及兜得对不对(对可预判的高频错误无脑用大 catch,靠 throw 扛、白白吃 fillInStackTrace 的开销)。该用 fail-fast 前置拦截的地方用了 catch,是 AI 给的方案里很典型、又不报错的隐性性能坑。
实战:审一段 AI 写的线程池代码
前面的坑都讲完了,最后来一次综合体检。下面这段是笔者让 AI 写的,业务场景很常见:用户下单成功后,异步去做几件后续的事——发优惠券、加积分、发短信通知、写操作日志。AI 给出的代码长这样:
publicclassOrderAsyncHandler{
// 处理下单后续动作的线程池
privatestaticfinal ExecutorService POOL = Executors.newFixedThreadPool(10);
publicvoidhandleAfterOrder(Order order){
POOL.submit(() -> couponService.grant(order.getUserId())); // 发券
POOL.submit(() -> pointService.add(order.getUserId(), order)); // 加积分
POOL.submit(() -> smsService.send(order.getPhone())); // 发短信
POOL.submit(() -> logService.record(order)); // 写日志
}
}
这段代码乍一看挺干净、也能跑,但拿前面学的东西逐条审,至少能揪出四个雷:

雷① Executors.newFixedThreadPool(10)——无界队列,高峰会 OOM。 它底层是无界 LinkedBlockingQueue,大促下单洪峰一来,10 个线程处理不过来,任务在队列里无限堆积,迟早把堆撑爆。改成 new ThreadPoolExecutor(...) 显式给一个有界队列 + 合适的拒绝策略。(对应前面《避免使用 newFixedThreadPool》)
雷② submit 提交了无返回值任务、却从不 get()——异常被悄悄吞了。 发券、加积分任一步抛异常,都被 Future 兜住、没人去 get(),于是"券没发成、积分没到账",你在日志里什么都看不到。这类无返回值任务应该用 execute、并在任务内兜底,或者 submit 后把 Future 收集起来处理结果。(对应《使用正确的方式提交任务》)
雷③ 任务体裸奔,没有 try/catch——worker 线程会被打死。 上面每个 lambda 里都是直接调外部服务,一旦短信网关超时抛异常,这个 worker 线程就消亡,线程池又得重建,高频出错时吞吐悄悄往下掉。任务体内应有兜底 try/catch。(对应《避免任务频繁抛出异常》)
雷④ 发短信(IO)、加积分/写日志(DB) 全挤一个池——类型混用、没隔离。 短信网关一慢,IO 任务把 10 个线程占满,积分、日志跟着饿死。按任务类型拆成独立线程池更稳。(对应《仔细斟酌线程混用策略》)
再往深一层:如果这几件事业务上要求"要么都成、要么回滚",那还得上前面讲的 submit + get() 感知异常 + 补偿那套,而不是 fire-and-forget 丢进池子不管。说到底,审 AI 写的并发代码,本质就是拿这些原理,逐条去对它有没有踩坑。
小结
总结一下上述线程池的使用经验:
避免使用 Executors 创建线程池。 确保线程确实被复用到。 使用合适的方式提交任务,并及时处理任务中的异常。 在合适的场景使用合适的线程池,线程数按任务类型估算:
CPU 密集型:任务几乎没有 IO、希望尽量榨干 CPU,理想线程数就等于 CPU 核心数。但考虑到偶发的缺页、GC 等会让线程短暂阻塞,一般留一点余量,建议 线程数 = CPU核心数 + 1。IO 密集型:每个任务都可能因 IO 阻塞,单核下建议 线程数 = (IO时长 / CPU计算耗时) + 1,多核下建议线程数 = CPU核心数 × (IO时长 / CPU计算耗时 + 1)。
这两个公式只是估算起点,具体还得结合压测结果做相应调整。
SharkChili · 禅与计算机程序设计的艺术
开源项目
mini-redis:笔者用 Go 从零手写的教学级 Redis,适合对着源码把缓存与网络底层一行行啃透,欢迎 Star 和交流 · https://github.com/shark-ctrl/mini-redis
如果想进一步交流,欢迎关注笔者的公众号 写代码的SharkChili ,发送关键字 【加群】 添加笔者好友、进技术交流群。
参考
新手也能看懂的线程池总结:https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect
线程池最佳实践:https://juejin.cn/post/6844904186400899086#heading-7
线程池系列之CallerRunsPolicy()拒绝策略 :https://juejin.cn/post/6982123485103390734
面渣逆袭(Java并发编程面试题八股文)必看:https://tobebetterjavaer.com/sidebar/sanfene/javathread.html#_46-能简单说一下线程池的工作流程吗
JVisualVM的使用教程:https://blog.csdn.net/DevelopmentStack/article/details/117385852
