 夜雨聆风
夜雨聆风
六月的第二周结束啦!
一起来回顾一下
这一周的日签知识吧!

6月8日
(点击图片即可放大查看详细信息)
AI给显微镜擦亮了眼睛
双光子显微镜可以深入活体组织内部,观察细胞的精细结构,但越往深处看,图像越容易变模糊。6月5日,Cell Reports Methods 发表一项研究,提出无监督深度学习方法 TENET。这种方法不需要“标准答案”,就能对双光子显微图像同时完成去模糊、超分辨和分割。研究显示,TENET 最高可实现约12倍轴向分辨率增强,并被用于小胶质细胞活体成像和三维形态分析。AI正在让显微镜突破物理限制,看得更清晰、更精细。
资料来源:https://www.cell.com/cell-reports-methods/fulltext/S2667-2375%2826%2900176-1
参考文献:Morita H, Hayashi S, Tsuji T ...
Unsupervised deep learning enables blur-free resolution enhancement in two-photon microscopy, Cell Reports Methods, 2026; 0
6月9日
(点击图片即可放大查看详细信息)
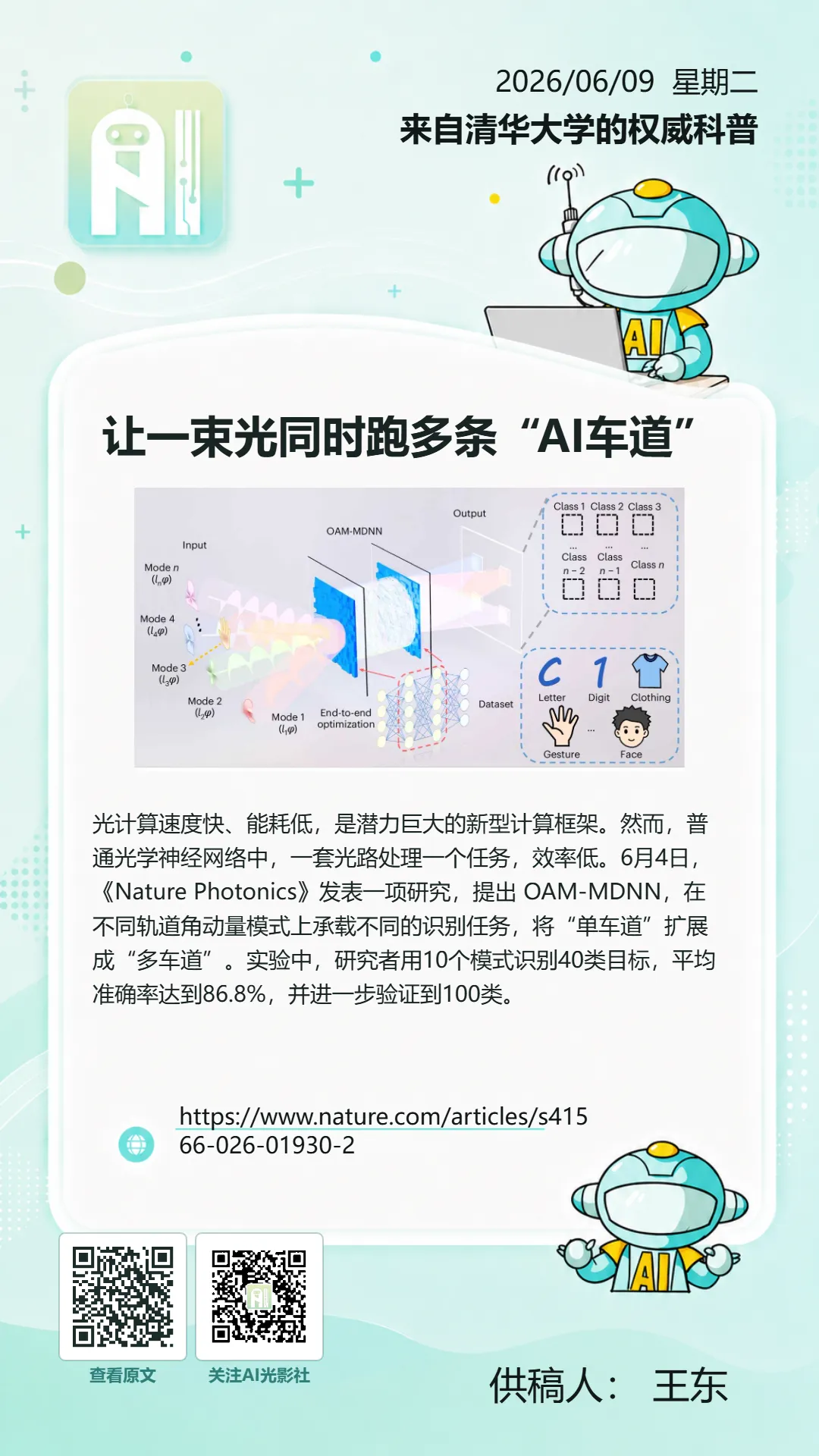
让一束光同时跑多条“AI车道”
光计算速度快、能耗低,是潜力巨大的新型计算框架。然而,普通光学神经网络中,一套光路处理一个任务,效率低。6月4日,《Nature Photonics》发表一项研究,提出 OAM-MDNN,在不同轨道角动量模式上承载不同的识别任务,将“单车道”扩展成“多车道”。实验中,研究者用10个模式识别40类目标,平均准确率达到86.8%,并进一步验证到100类。
资料来源:https://www.nature.com/articles/s41566-026-01930-2
参考文献:He, C., Li, X., Wang, H. et al. Orbital angular momentum multiplexing diffractive neural networks for high-capacity optical inference. Nat. Photon. (2026).
6月10日
(点击图片即可放大查看详细信息)
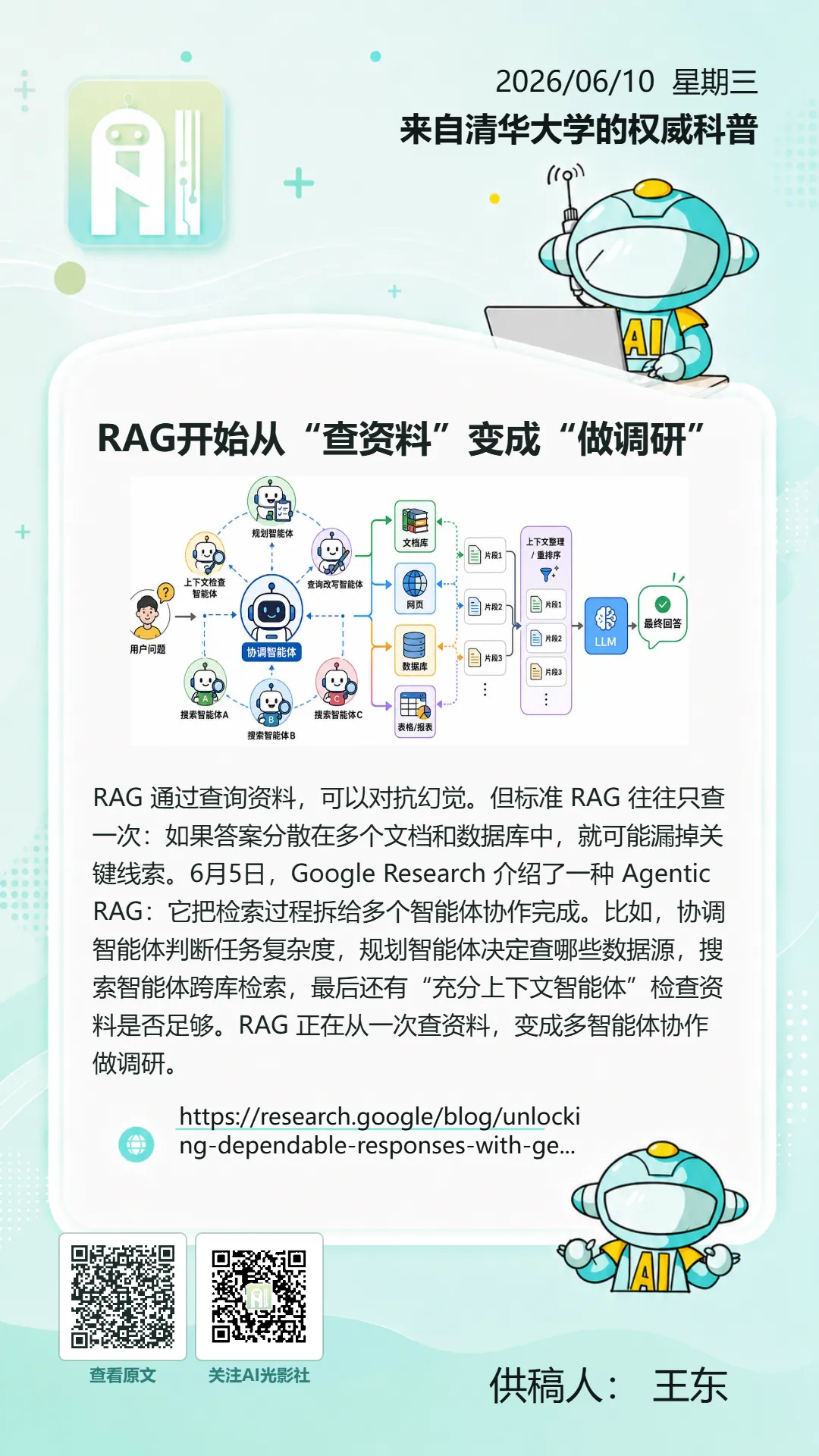
RAG开始从“查资料”变成“做调研”
RAG 通过查询资料,可以对抗幻觉。但标准 RAG 往往只查一次:如果答案分散在多个文档和数据库中,就可能漏掉关键线索。6月5日,Google Research 介绍了一种 Agentic RAG:它把检索过程拆给多个智能体协作完成。比如,协调智能体判断任务复杂度,规划智能体决定查哪些数据源,搜索智能体跨库检索,最后还有“充分上下文智能体”检查资料是否足够。RAG 正在从一次查资料,变成多智能体协作做调研。
资料来源:https://research.google/blog/unlocking-dependable-responses-with-gemini-enterprise-agent-platforms-agentic-rag/
参考文献:Unlocking dependable responses with Gemini Enterprise Agent Platform’s Agentic RAG, Google Research blog, 2026.6.5.
6月11日
(点击图片即可放大查看详细信息)
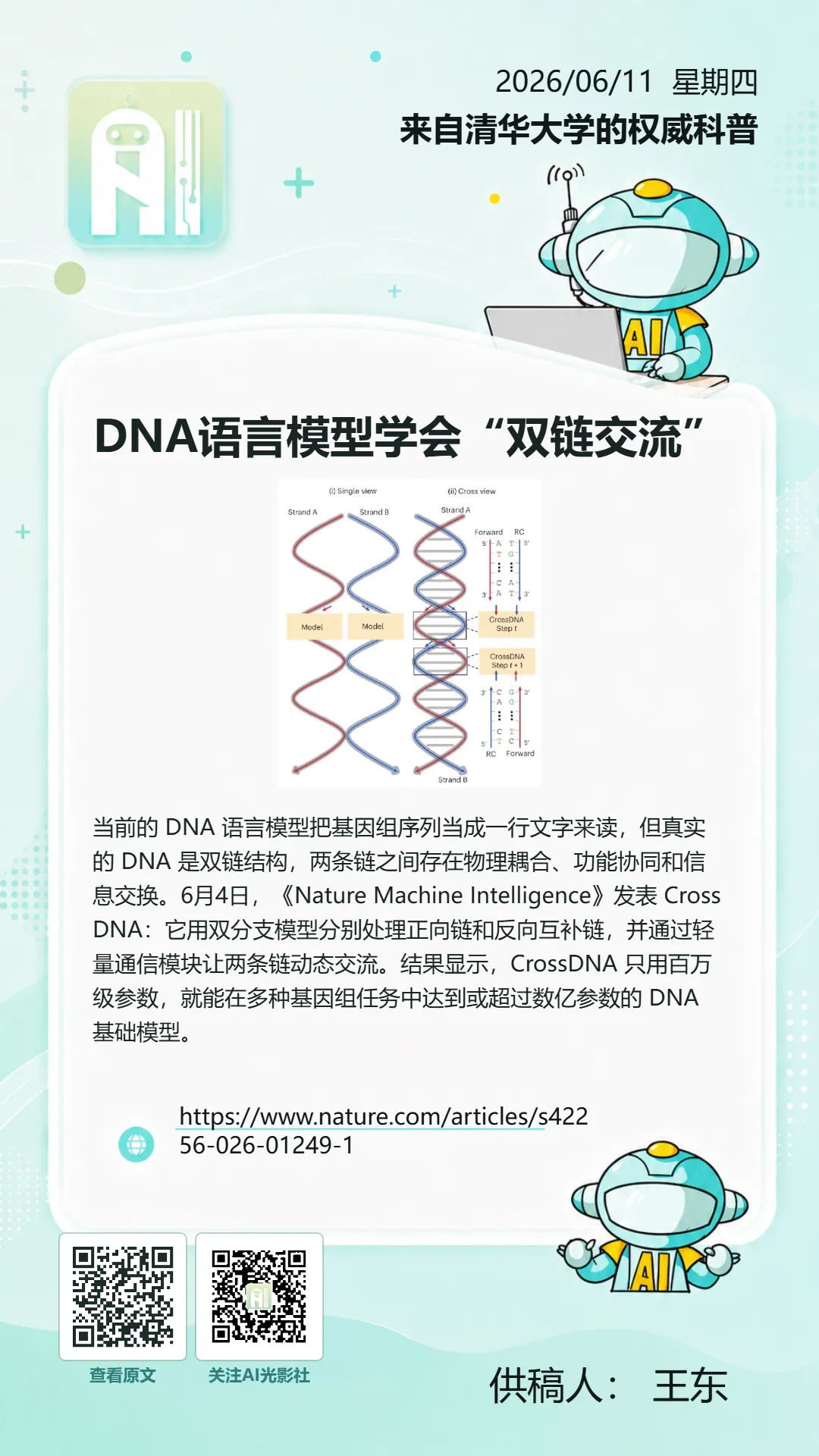
DNA语言模型学会“双链交流”
当前的 DNA 语言模型把基因组序列当成一行文字来读,但真实的 DNA 是双链结构,两条链之间存在物理耦合、功能协同和信息交换。6月4日,《Nature Machine Intelligence》发表 CrossDNA:它用双分支模型分别处理正向链和反向互补链,并通过轻量通信模块让两条链动态交流。结果显示,CrossDNA 只用百万级参数,就能在多种基因组任务中达到或超过数亿参数的 DNA 基础模型。
资料来源:https://www.nature.com/articles/s42256-026-01249-1
参考文献:Yang, C., Liu, Y., Ling, L. et al. Explicit dynamic cross-strand interactions for DNA sequence language modelling. Nat Mach Intell (2026).

6月12日
(点击图片即可放大查看详细信息)
UniBiomed:可解释的医疗AI模型
传统医学影像 AI 是个“黑盒”:它能给出诊断,却不会给出依据。6月4日,《Nature Communications》发表 UniBiomed,一个面向医学影像的通用基础模型。它结合多模态大语言模型和 Segment Anything Model,不仅生成诊断描述,还能在图像中分割出目标区域。研究者用2700万组数据样本训练模型,并在70个内部数据集和14个外部数据集上进行了验证,效果显著。
资料来源:https://www.nature.com/articles/s41467-026-73986-1
参考文献:Wu, L., Nie, Y., He, S. et al. A universal foundation model for grounded biomedical image interpretation. Nat Commun (2026).

6月13日
(点击图片即可放大查看详细信息)
Diffusion Gemma: 更快的并行大语言模型
大语言模型的工作原理可以类比打字机,从左到右一个词一个词生成文本。6月10日,Google 发布实验性开源模型 DiffusionGemma,尝试用“扩散”方式生成文字:它先生成一整块随机占位文本,再像图像扩散模型修图一样,反复修改、填充和润色。这样每次前向计算可并行处理256个 token,在专用 GPU 上文本生成速度最高可提升4倍,单张 H100 可超过每秒1000个 token。它的质量仍不如标准 Gemma 4,但延迟低,适合代码填空和快速编辑等场景。
资料来源:https://blog.google/innovation-and-ai/technology/developers-tools/diffusion-gemma-faster-text-generation/
参考文献:DiffusionGemma: 4x faster text generation, Google blog, 2026.6.10

6月14日
(点击图片即可放大查看详细信息)
Nature Medicine:通用 LLM 在医疗基准测试上超过专用临床AI
6月12日,Nature Medicine 发表研究,比较 OpenEvidence、UpToDate Expert AI 等专用临床 AI 工具与 GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6 等通用前沿模型。结果显示,通用 LLM 在三类评测中整体优于专用临床 AI 工具,证明了通用AI模型的强大。
资料来源:https://www.nature.com/articles/s41591-026-04431-5
参考文献:Vishwanath, K., Alyakin, A., Ghosh, M. et al. General-purpose large language models outperform specialized clinical AI tools on medical benchmarks. Nat Med (2026).
