 夜雨聆风
夜雨聆风我折腾了3小时把100M扫描PDF转成MD,最后被一个网页10秒秒杀
一个人花三个小时折腾一件事,最后发现一个免费网页10秒就能搞定。
这不是笑话,这是我今天的真实经历。
我把这段经历写下来,不是为了炫耀踩坑能力,而是想帮你省掉那三个小时——如果你也有「PDF转Markdown」的需求的话。
为什么要把PDF转成Markdown?
先说背景,省得有人觉得这个需求很奇怪。
随着AI工具普及,越来越多的人开始用大模型处理文档:上传合同让AI提炼条款,上传报告让AI做摘要,上传技术手册让AI解答问题。
问题来了——PDF是一种「展示格式」,不是「处理格式」。它的本质是把内容冻结在一个固定的视觉快照里,对机器极不友好。
Markdown就不同了。它是纯文本,结构清晰,AI读起来高效,人工编辑也方便,还能无缝接入各种笔记工具(Obsidian、Notion、思源笔记、Logseq……)。
把PDF转成MD,是让文档从「存档状态」变成「可用状态」的关键一步。
这个需求,听起来很简单。但当你真正动手的时候,你会发现——它一点都不简单。
PS:我个人常用的就是思源笔记,一个All in One的笔记软件,用于搭建我的知识库,对markdown的支持非常友好,这就是我为什么会转换pdf等格式到markdown,方便导入并以大纲形式编辑,这个后续会再单独介绍。
第一回合:文字版PDF,工具轻松拿下——但没想象中聪明
我先是上传了一份普通的文字版PDF,不是扫描件,文字可以直接选中那种。
使用的是腾讯出品的marvis(本质是一个AI Agent,智能体),节省token。在marvis中安装了“markitdown”这个Skill。
这个Skill调用的工具是微软开源的 markitdown,GitHub 上已经超过 11 万 Star,算是这个赛道的明星项目。
我直接上传PDF,下达指令:「转为MD文档。」
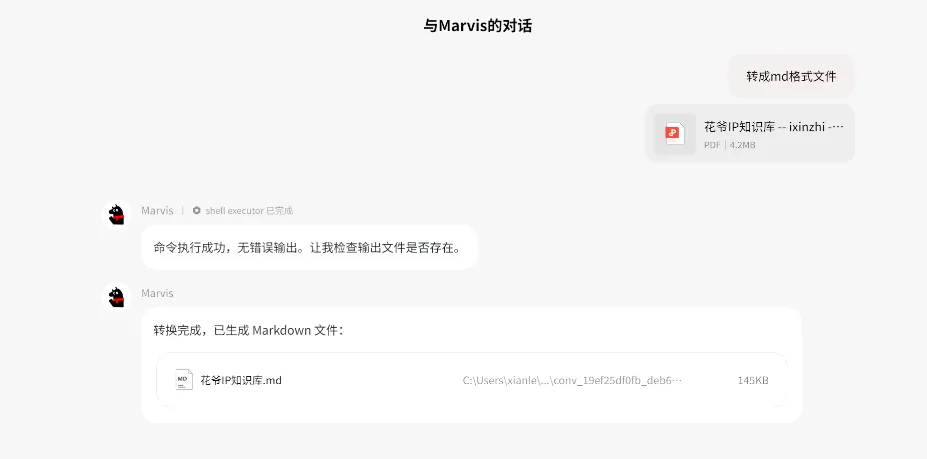
几秒钟,结果出来了。
速度是真的快,没话说。但打开MD文件一看——就是纯文字识别,把PDF里的内容原样扒了出来。没有标题层级,没有大纲结构,就是一个从头到尾的文字块。
说实话,这个效果,用 umi-ocr 也能做到,直接上传文件点击识别,每页它自己OCR,全部合并成一个TXT文件,把后缀改成md,效果大差不差。
markitdown 主打的「语义结构保留」——标题还是标题、表格还是表格——在我这份文字版PDF上压根没发挥出来。可能是PDF本身排版层级不明显,工具也没办法「无中生有」地帮你补结构。
这——肯定是达不到我的要求滴!
第二回合:100M扫描PDF,噩梦开始
紧接着,重头戏来了。
我试着上传一份扫描版PDF——每一页都是一张图片,没有文字层,纯图像。我的要求很明确:
转为MD文件,保留里面的图片、表格、公式的结构。
于是,MARVIS开启了「疯狂作业模式」:
先自动安装 PaddlePaddle 试试水——不行,版本不兼容。
又装 TesseractOCR——跑起来了,但识别效果一般,对中文表格支持不好。
再换 EasyOCR——终于选定,开始正式干活。
因为文件太大(100多M),第一次跑了十几分钟,直接内存溢出中断。
工具没有放弃,换了策略:先把整份PDF每一页渲染成图片,然后分成3个阶段逐批OCR识别,最后合并输出MD文件。
具体工作日志如下图:

整个过程跑了将近两个多小时。
电脑风扇嗡嗡响,16G的内存基本都要占满,只能保持不动,别提再做其他操作了。
最终产物出来了。
一个MD文件,加一个图片文件夹。
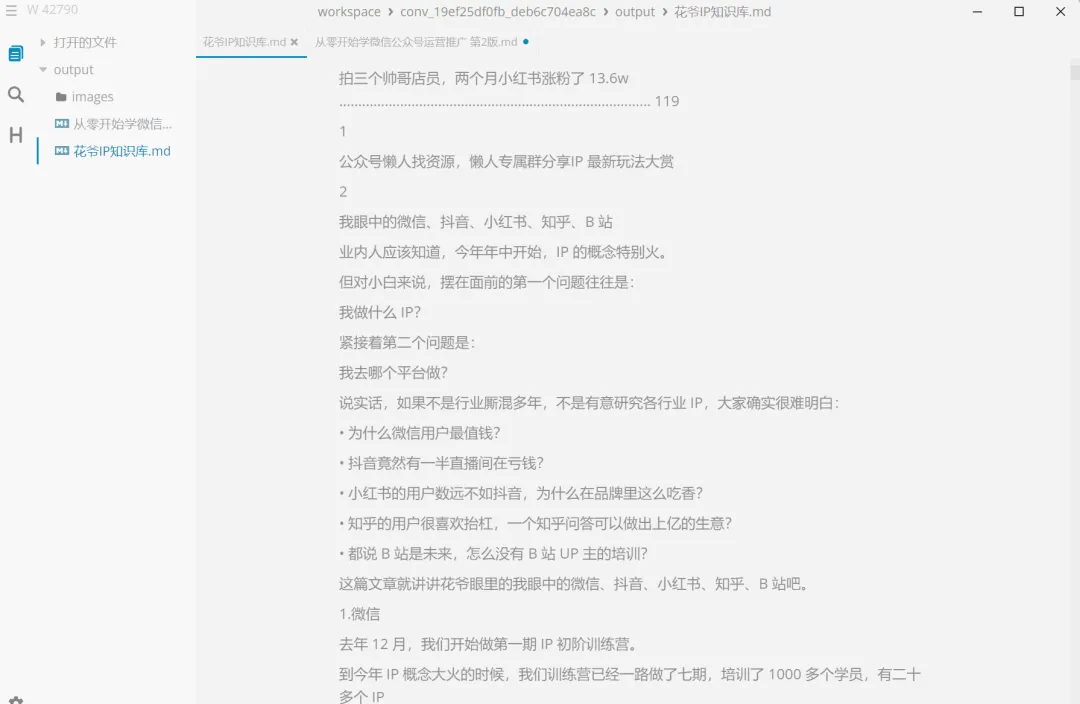
打开MD,心凉了半截。
没有大纲标题,没有结构分层。
所谓「保留图片」,是把每一页的原始扫描图直接插进MD里,而不是「在表格位置插表格图片,在公式位置插公式截图」——那是我预想中的「精细结构还原」,现实是把原图整页整页地塞进去,OCR文字跟在后面。
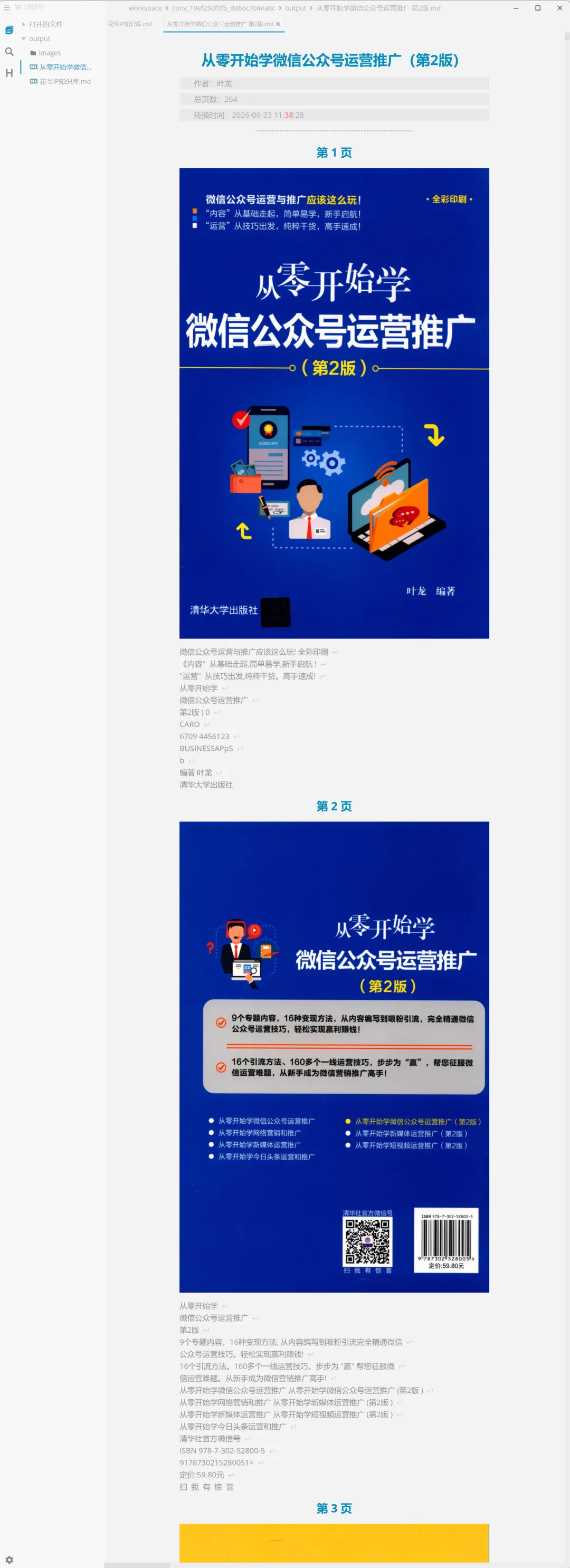
本质上,这和直接把PDF里的每张图截出来,再附上OCR文字,没有本质区别。
折腾了两小时,离我想要的效果,差得不是一点半点。
第三回合:在线工具出场,被速度震惊
被本地工具教育了一整个下午之后,我决定试试在线工具。
我选了两个:MinerU在线版 和 PaddlePaddle 在线版。
两个工具的体验高度一致:
上传PDF → 等待几秒到十几秒 → 下载MD文件。
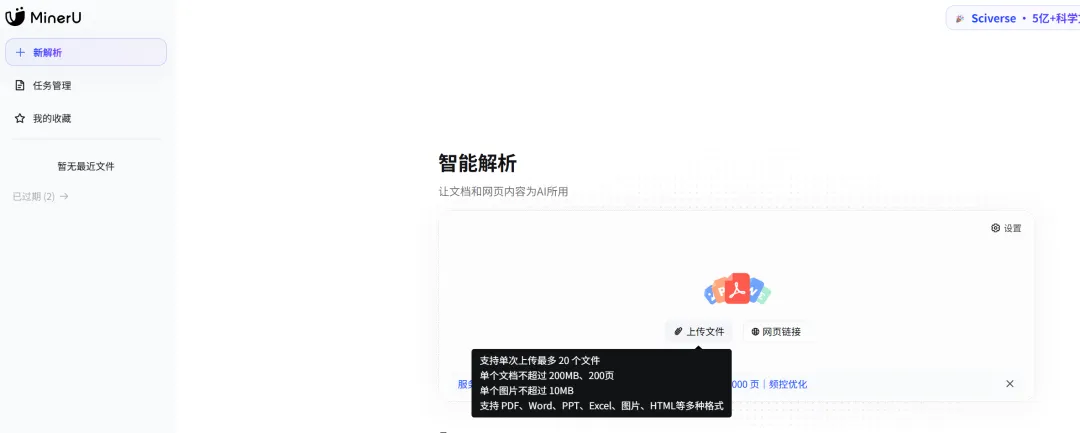
就这样。转换后就可以下载所要的文件了。
以MinerU转换文字版为例,可以左右两边输出转换前后的对比,基本保持了原版大纲标题

然后右上角点击下载即可以。

值得一提的是,下载的md文件是单文件,要保留图片之类的话,它是在文档中以链接形式存在,后续可编辑替换或者使用图床之类。
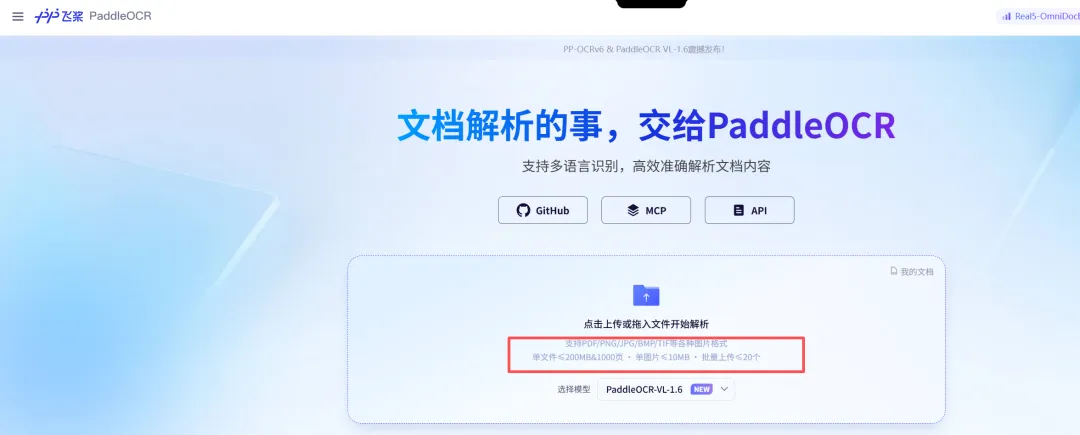
然后上传扫描版PDF到PaddlePaddle 在线版转换。(两个软件为什么分开识别不同文件?因为他们对文件大小和页数限制不一样,我这个扫描版文件页数比较多。不影响对比)
PaddlePaddle转换效果如下,也保持了大致的层级大纲

这两个在线工具转换完总耗时不到两分钟,速度快到我以为自己哪里操作错了,赶紧打开下载的本地MD文件验证——

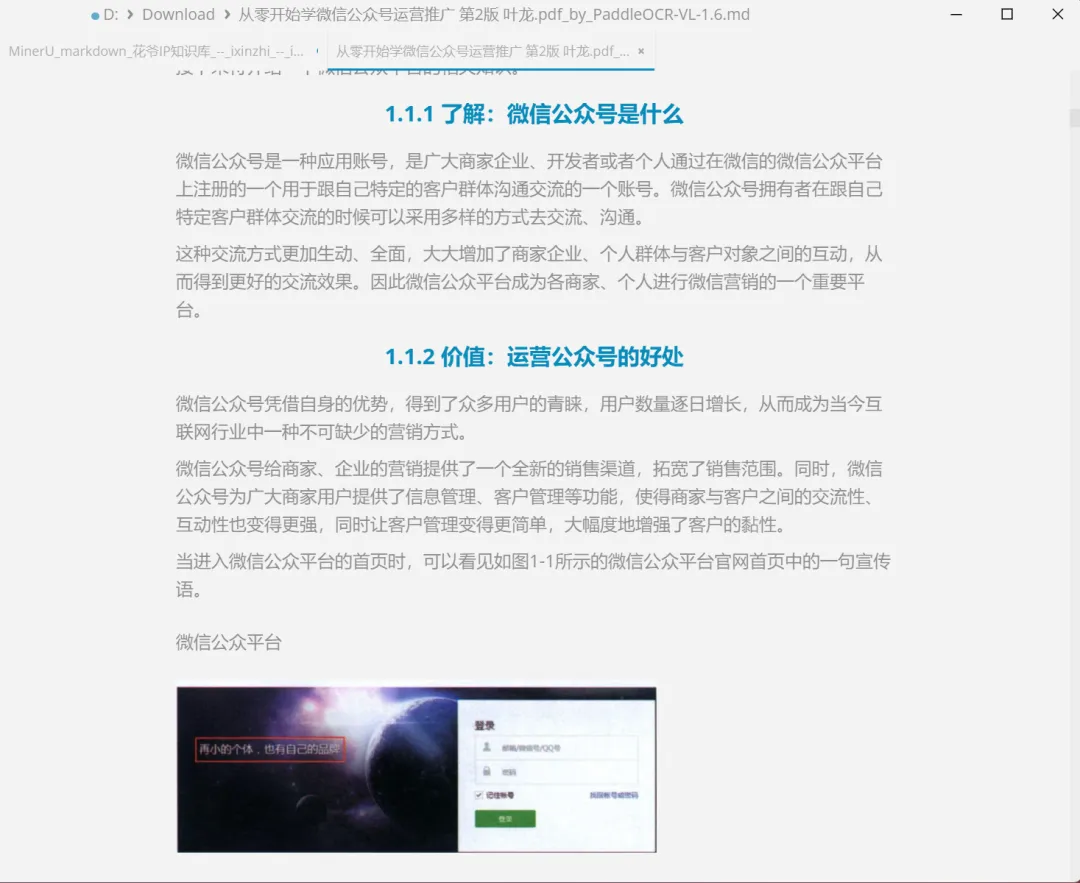
大纲标题保留了。目录结构清晰。图片大体在正确的位置。
和我在本地折腾两个小时的成果相比,简直是降维打击。
当然,两个工具之间也有差别,主要体现在图片处理方式上:
MinerU 的图片用的是在线链接引用。速度极快,文件体积小,但图片托管在它的服务器上——如果链接哪天失效,你的MD里就全是断图,一片空白。
PaddlePaddle 在线版 的图片用HTML标签嵌入。不依赖外部服务器,离线查看没问题,但MD文件体积会比较大,而且HTML标签在部分纯Markdown编辑器里不一定能正常渲染。
如果你的文档只用一两次,MinerU完全够用,快就是生产力。
如果你要把MD长期存档,多年后还要能打开看,PaddlePaddle的本地嵌入更稳妥。
但也要注意两者对上传的文件的大小及页数的限制。可查看上面上传文档时的截图标记。
三轮下来,我学到了什么?
现在,我们来思考一个问题:
一个免费在线工具,10秒能做完的事,为什么有人愿意花两个小时在本地折腾?
答案只有一个:数据不能离开你的电脑。
这是本地工具唯一真正无法被替代的价值——数据主权。
如果你处理的是合同、财报、内部报告、客户隐私文件,那些绝对不能上传到任何外部服务器的东西,那么本地部署是你唯一的选择,再慢再麻烦也得折腾。
但是,如果你处理的只是普通技术文档、公开资料、个人学习材料——
那就不要浪费自己的时间了。
在线工具无论是速度、效果还是易用性,都已经把本地方案按在地上摩擦。
因为,
在线工具他们的后台处理速度也确实比我本地电脑处理速度快。
选工具,先回答这一个问题
经过这三轮折腾,我把选工具的逻辑浓缩成了一张表:
使用在线工具之前,你只需要回答一个问题:
这份文档能上网吗?
能上网——在线工具,10秒解决,完事。
不能上网——本地工具,准备好时间和耐心。
最后说一句
我发现很多人(包括我自己)在面对工具选择的时候,有一种「本地部署才是硬核」的执念。
觉得用本地工具才叫真正掌握技术,用在线工具像是在作弊。
但这个想法是有问题的。
工具是手段,不是目的。你真正需要的,是那份干净可用的MD文档,而不是在部署本地OCR环境这件事上消耗你的精力。
把时间留给真正重要的事。
如果一个在线工具10秒能帮你解决问题,那它就是最好的工具——不管它看起来多"简单"。
我在本地工具上折腾了三个小时,才学会了这句话。
你不用了。
本文工具清单(都是免费可用的):· MinerU:opendatalab.com/MinerU· PaddlePaddle在线文档转换:aistudio.baidu.com· MarkItDown(微软开源):github.com/microsoft/markitdown
