 夜雨聆风
夜雨聆风兄弟们,你们见过 Redis 内存满了之后,整个系统慢慢“窒息”的样子吗?上周三下午 3 点,业务高峰期,监控突然报警——Redis 内存使用率飙到 99.8%,新的写入请求全部失败,缓存命中率从 95% 跌到 30%,数据库瞬间被打爆。
我冲到工位,第一反应是“谁写了 BigKey?”,第二反应是“淘汰策略怎么没生效?”。那天晚上我翻了一整晚源码和监控,才发现我们对 Redis 内存管理的理解,还停留在“配个 maxmemory 就完事”的程度。今天就把这次翻车的完整复盘和 7 条保命经验分享出来。
一、事故还原:内存是怎么被打满的?
我们的 Redis 实例配置了 maxmemory=12GB(物理内存 16GB),淘汰策略用的是默认的 noeviction——内存满了之后拒绝所有写入请求。
活动开始后,大量新数据写入,同时一批设置了 7 天过期时间的 Key 集中过期。但过期 Key 并没有被立即删除,而是堆积在内存中。到下午 3 点,used_memory 达到 12GB 阈值,Redis 开始拒绝写入。业务方报错、缓存失效、数据库被打爆,整个链路雪崩。
根因:我们对 Redis 过期策略和淘汰策略的理解有严重偏差。
# redis-cli INFO memory 输出used_memory: 12884901888 (12.0GB)used_memory_human: 12.00Gmaxmemory: 12884901888 (12.0GB)maxmemory_human: 12.00Gmem_fragmentation_ratio: 1.85 ← 碎片率 85%!evicted_keys: 0 ← 淘汰策略根本没触发
二、过期策略:为什么过期 Key 还在占内存?
很多人以为设置了 TTL,Key 过期后内存就自动释放了。大错特错。
Redis 的过期 Key 删除采用两种策略配合:惰性删除 + 定期删除。
2.1 惰性删除
原理:只有在访问一个 Key 时,Redis 才会检查它是否过期。如果过期,立即删除。
优点:CPU 友好,不额外消耗资源。
缺点:如果过期 Key 再也不被访问,就会永远占用内存。
// Redis 源码中惰性删除的核心逻辑(简化)int expireIfNeeded(redisDb *db, robj *key) {// 检查 Key 是否过期if (!keyIsExpired(db, key)) return 0;// 过期则删除,并通知从库和 AOFdeleteExpiredKeyAndPropagate(db, key);return 1;}
2.2 定期删除
原理:Redis 默认每隔 100ms 执行一次后台任务 serverCron(由 hz 参数控制频率,默认 10,即每秒执行 10 次)。这个任务会启动 activeExpireCycle 函数,采样式地清理过期 Key。
关键参数:
hz:serverCron 的执行频率,默认 10(每秒执行 10 次)每次扫描
expires字典中最多 20 个 Key如果删除比例超过 10%,继续扫描下一批
关键认知:定期删除不是全量扫描所有 Key,而是有策略地抽样,在 CPU 耗时和内存释放之间做平衡。
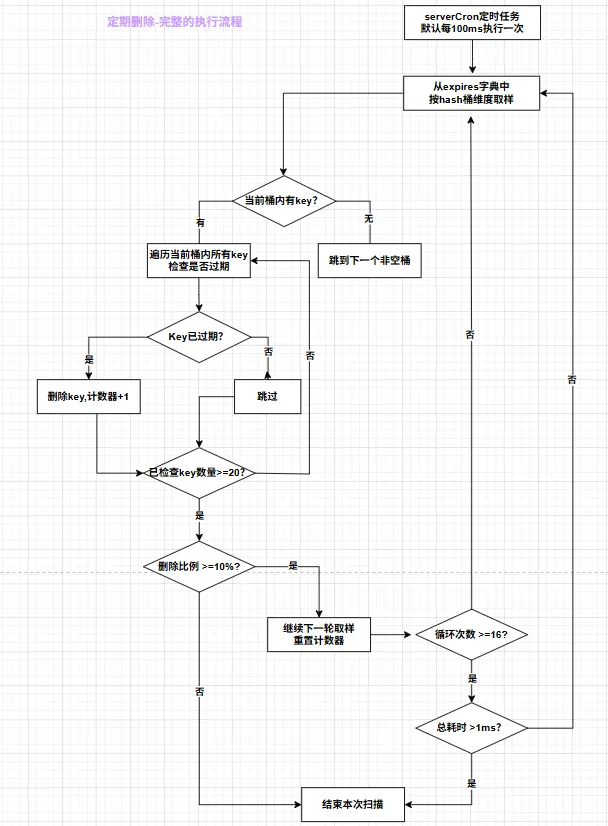
完整的执行流程
关键步骤拆解
第一步:按 Hash 桶维度取样
Redis 不是从 expires 字典中随机挑 20 个 Key,而是按 hash 桶的顺序扫描。如果当前桶内有 15 个 Key,就全部检查;如果桶是空的,跳到下一个非空桶。这保证了扫描的高效性。
第二步:最多扫描 20 个 Key
每轮扫描最多处理 20 个 Key(由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 宏定义控制)。这个数字是为了控制单次扫描的 CPU 耗时。
第三步:删除已过期的 Key
找到已过期的 Key 直接删除,同时记录删除数量。
第四步:删除比例超过 10% 则继续
如果本轮删除的 Key 占扫描总数的比例超过 10%(由 ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 控制),说明当前 expires 字典里过期 Key 比例较高,需要继续下一轮扫描,直到删除比例低于 10%。
第五步:循环次数限制与超时保护
每轮扫描最多循环 16 次(
ACTIVE_EXPIRE_CYCLE_SLOW_LOOPS)16 次之后会检查总耗时是否超过 1ms(
ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC换算),如果超时则直接返回,避免占用主线程太久
核心设计哲学:这是一个有上限的尽力而为机制。通过“删除比例 > 10% 继续”的反馈调节,确保在有大量过期 Key 时能持续清理;通过“16 次循环 + 1ms 超时”的保护机制,确保不会因为清理过期 Key 而阻塞正常请求。
为什么定期删除不保证清理所有过期 Key?
这种设计的取舍非常清晰:
如果每次扫描全量 expires 字典,在 Key 数量大的情况下会长时间阻塞 Redis
单线程模型下,任何耗时操作都会影响所有请求的延迟
所以 Redis 选择“少量多次 + 反馈调节 + 超时保护”的策略
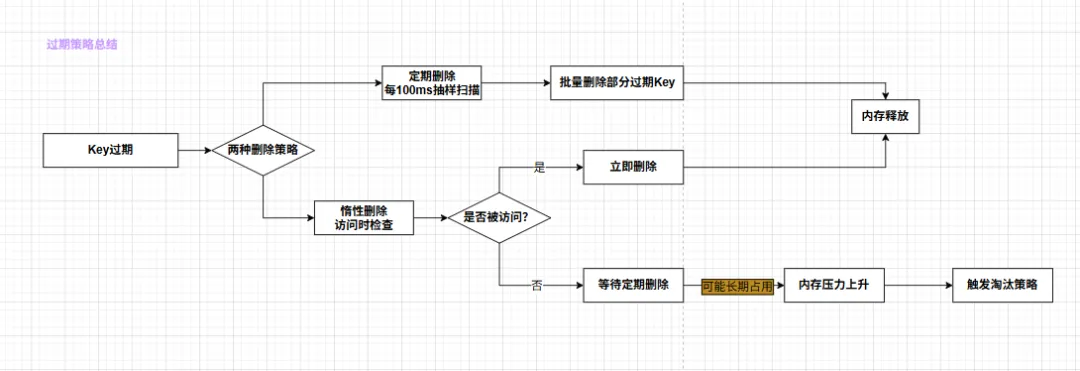
过期策略总结
2.3 两种策略配合的效果
| 惰性删除 | |||
| 定期删除 |
说白了,Redis 的过期策略是一种“尽力而为”的机制,不保证过期 Key 被立即删除。 这就是我们翻车的第一个原因——大量过期 Key 堆积,内存被撑爆。
关于过期删除的常见误区
三、淘汰策略:内存满了怎么办?
当 maxmemory 达到上限时,Redis 会根据 maxmemory-policy 配置决定淘汰哪些数据。
3.1 八种淘汰策略
noeviction | ||
allkeys-lru | ||
allkeys-lfu | ||
allkeys-random | ||
volatile-lru | ||
volatile-lfu | ||
volatile-random | ||
volatile-ttl |
3.2 近似 LRU vs 精确 LRU
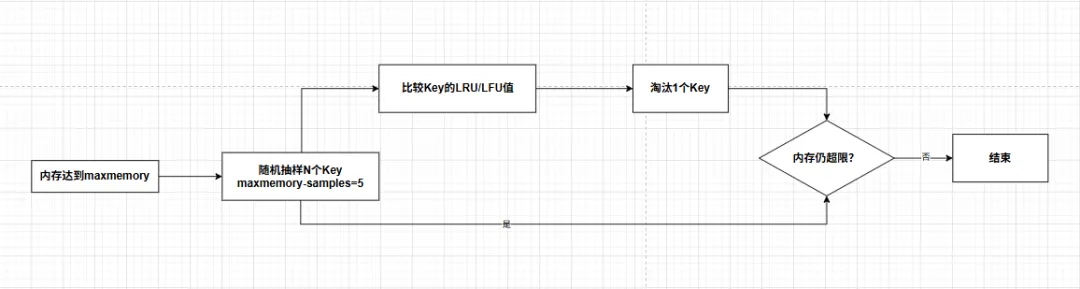
Redis 没有使用严格的 LRU 算法,而是采用近似 LRU:
每次淘汰时,随机选出
maxmemory-samples个 Key(默认 5 个)从这些样本中选出最久未被访问的 Key 淘汰
样本数越大,淘汰越精确,但 CPU 开销也越大
3.3 我们翻车的第二个原因:用了 noeviction
# 配置建议:生产环境千万别用 noevictionmaxmemory-policy allkeys-lru # 大多数场景推荐# 或maxmemory-policy volatile-lru # 只淘汰有过期时间的 Key
四、内存碎片:被忽略的“隐形杀手”
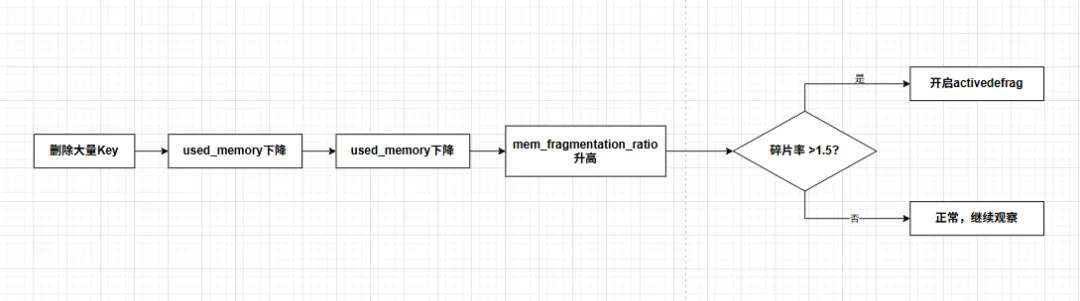
删除大量 Key 后,used_memory 下降了,但 used_memory_rss(操作系统看到的物理内存)可能纹丝不动。
4.1 碎片是怎么产生的?
Redis 使用 jemalloc 内存分配器。频繁的写入和删除会导致内存块被拆分成不连续的小块,无法被有效利用。
4.2 如何判断碎片是否严重?
redis-cli INFO memory | grep mem_fragmentation_ratiomem_fragmentation_ratio在 1~1.5 之间:正常mem_fragmentation_ratio在 1.5~2 之间:需要关注mem_fragmentation_ratio超过 2:严重,必须处理
我们当时的碎片率是 1.85,属于严重级别。
4.3 如何清理碎片?
方案一:主动碎片整理(Redis 4.0+)
# 开启主动碎片整理config set activedefrag yes
配置参数:
active-defrag-threshold-lower 10:碎片率超过 10% 时启动整理active-defrag-cycle-min 25:CPU 最低占用 25%active-defrag-cycle-max 75:CPU 最高占用 75%
方案二:重启实例(最彻底,但需要停服)
五、BigKey:Redis 性能的“头号杀手”
BigKey 是我心目中排名前三的 Redis 杀手。BigKey 最大的问题不是内存,而是:
网络传输慢:一个 10MB 的 Key,读一次就要传输 10MB 数据
阻塞其他请求:Redis 单线程执行命令,BigKey 操作会卡住所有后续请求
集群数据倾斜:BigKey 所在的节点内存远高于其他节点
迁移/扩容巨慢:集群 rehash 时迁移 BigKey 耗时极长
5.1 如何发现 BigKey?
# 使用 redis-cli 扫描 BigKeyredis-cli --bigkeys# 或使用 MEMORY USAGE 命令查看单个 Key 的内存占用MEMORY USAGE mykey
--bigkeys 的局限性:它会遍历所有 Key,生产环境慎用,建议在低峰期执行。5.2 如何治理 BigKey?
| String 大 Value | |
| Hash 大 Field | |
| List 长列表 | LTRIM 限制长度,或分页存储 |
| Set/ZSet 大集合 |
六、SCAN 遍历:不用 keys * 也能优雅遍历
KEYS * 命令会阻塞 Redis,在数据量大的情况下可能导致服务卡顿数秒甚至数分钟。
6.1 SCAN 的核心原理
SCAN 通过游标(cursor) 分段遍历,每次只返回一小部分 Key。
# 第一次扫描,游标从 0 开始SCAN 0 MATCH user:* COUNT 100# 返回结果包含下一个游标和本次匹配的 Key1) "38" # 下一个游标2) 1) "user:1001"2) "user:1002"...# 继续用返回的游标迭代SCAN 38 MATCH user:* COUNT 100
6.2 SCAN 的遍历顺序:高位进位加法
Redis 的 SCAN 采用了高位进位加法遍历哈希表,而不是从 0 到 N 顺序遍历。
为什么这样设计? 在字典扩容/缩容时,保证同一个 Key 不会被重复遍历,也不会被遗漏。

6.3 SCAN vs KEYS
| KEYS | |||
| SCAN |
SCAN 的注意事项:
每次返回的 Key 数量不固定,
COUNT只是提示可能会有重复 Key,客户端需要自己去重
遍历期间如果有 Key 被删除,可能遍历不到
七、内存优化实战:7 条保命经验
7.1 maxmemory 设置
建议:设置为物理内存的 70%~80%。剩余内存留给操作系统和 AOF/RDB 子进程。
# 32GB 物理内存maxmemory 24gb
7.2 淘汰策略选择
allkeys-lru | |
volatile-lru | |
allkeys-lfu | |
千万不要用noeviction |
7.3 监控指标
每天巡检以下指标:
redis-cli INFO memory | grep -E"used_memory_human|maxmemory|mem_fragmentation_ratio|evicted_keys"
used_memory_human:当前使用内存mem_fragmentation_ratio:碎片率,超过 1.5 需要关注evicted_keys:被淘汰的 Key 数量,突增说明内存不足
7.4 过期时间设计
给 Key 设置合理的 TTL,不要永久保留
大量 Key 的过期时间加随机偏移,避免集中过期
// 过期时间加随机偏移,防雪崩int baseExpire = 3600;int randomOffset = new Random().nextInt(600);int actualExpire = baseExpire + randomOffset;redis.setex(key, actualExpire, value);
7.5 主动碎片整理
config set activedefrag yesconfig set active-defrag-threshold-lower 10config set active-defrag-cycle-min 25
7.6 数据结构优化
小 Hash 用 ziplist:
hash-max-ziplist-entries 512小 ZSet 用 ziplist:
zset-max-ziplist-entries 128String 尽量用整数:整数存储比字符串省内存
Redis 7.4 和 8.0 对 Hash 和 Sorted Set 的内存占用有显著优化,Hash 最多可降低 16.7%,ZSet 最多可降低 30.5%。
7.7 定期巡检 BigKey
# 低峰期执行redis-cli --bigkeys -i 0.1 # -i 0.1 表示每扫描 100 个 Key 暂停 0.1 秒
八、总结:7 条保命经验
过期 Key 不会自动删除——惰性删除 + 定期删除只是尽力而为
千万别用
noeviction——内存满了会直接拒绝写入碎片率超过 1.5 就要处理——开启
activedefragBigKey 是头号杀手——
--bigkeys定期扫描,及时拆分生产环境禁用
KEYS *——用SCAN替代maxmemory设 70%~80%——留内存给操作系统和子进程过期时间加随机偏移——防止集中过期导致雪崩
兄弟们,你们在生产环境中遇到过 Redis 内存被打满的情况吗?是 BigKey 导致的还是淘汰策略没配好?评论区聊聊,我帮你们分析分析。
