 夜雨聆风
夜雨聆风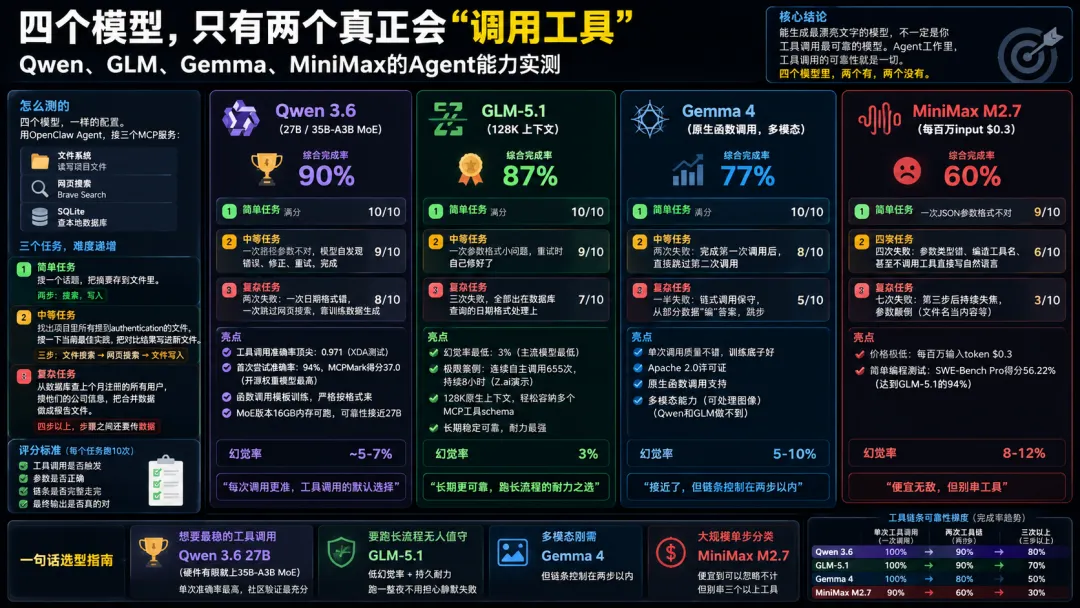
工具调用这件事,决定了你手里拿的是个"聊天模型"还是个"Agent模型"。聊天只要生成文字就行,Agent不行。Agent要读你的邮件,搜网页,查数据库,写文件,调API。而且每一次,都得用正确的参数、正确的格式,生成结构化的函数调用。
大多数模型做一次没问题。问题是连续做五次,还能不能做到不幻觉出一个不存在的工具、不乱改JSON参数、不在工具调用压根没触发的时候告诉你"搞定啦"?
我测了四个模型家族的Agent工作流。不是基准测试,不是单次演示。是真正的多步工具链——每一步都依赖上一步的结果。这才是你的Agent每天在干的事。
结果:两个跟到底了,两个在中途翻车。而且翻车的方式,比直接抛异常还麻烦。
怎么测的
四个模型,一样的配置。用OpenClaw Agent,接三个MCP服务:
文件系统(读写项目文件)
网页搜索(Brave Search)
SQLite(查本地数据库)
三个任务,难度递增:
任务1(简单):搜一个话题,把摘要存到文件里。两步:搜索,写入。
任务2(中等):找出项目里所有提到authentication的文件,搜一下当前最佳实践,把对比结果写进新文件。三步:文件搜索,网页搜索,文件写入。
任务3(复杂):从数据库查上个月注册的所有用户,搜他们的公司信息,把合并数据做成报告文件。四步以上,步骤之间还要传数据。
每个模型每个任务跑10次。评分标准:工具调用是否触发、参数是否正确、链条是否完整走完、最终输出是否真的对。
Qwen 3.6:工具调用的默认选择,不是白叫的
简单任务:10/10。 满分。
中等任务:9/10。 一次文件路径参数稍微不对,被服务拒绝了。模型自己发现错误、修正路径、重试、完成。整套动作自己搞定。
复杂任务:8/10。 两次失败。一次是数据库查询的日期格式写错了JSON参数。另一次更有意思——模型直接跳过了网页搜索,从自己的训练数据里生成了公司信息。
综合完成率:90%。 四个模型里最高。
社区的评价和我测出来的一致:Qwen在本地AI圈就是"工具调用的默认选项"。XDA的测试里,Qwen3 14B在标准化测试上达到0.971的工具调用准确率,超过GPT-4o(0.857)和Claude 3.5 Sonnet(0.851)。Qwen 3.6 Plus首次尝试准确率94%,MCPMark得分37.0,开源权重模型里最高的。
为什么Qwen这么稳?因为它是用明确的函数调用模板训练出来的。模型不会对工具调用的语法"发挥创意",它老老实实按格式来。其他模型有时候会自作聪明,Qwen不会。
它的MoE版本(35B-A3B)在16GB内存上就能跑,工具调用可靠性和完整版27B几乎一样。如果你用的是消费级硬件,这是最好的起点。
GLM-5.1:耐力之选
简单任务:10/10。 满分。
中等任务:9/10。 一次参数格式小问题,重试时自己修好了。和Qwen一个风格。
复杂任务:7/10。 三次失败,全都出在数据库查询这一步。GLM-5.1对SQL日期格式的处理确实比Qwen弱一些。但成功执行的那些步骤,工具调用非常干净。
综合完成率:87%。 比Qwen略低。但重点不在完成率,在耐力。
GLM-5.1的工具调用幻觉率是主流模型里最低的,只有3%。这里说的"幻觉"是指调用不存在的工具、自己发明参数、或者声称调用成功了但实际没触发。大多数模型的幻觉率在5%到10%。GLM-5.1几乎从不犯这种错。
Z.ai展示过一个极端案例:GLM-5.1在单个任务上连续跑了655次自主调用,持续8个小时。这种在长会话中保持工具调用可靠性的能力,才是GLM-5.1真正的护城河。Qwen是每次调用更准,GLM-5.1是长期更可靠。如果你的Agent要深夜无人值守跑一个50步的工作流,GLM-5.1的低幻觉率意味着你第二天早上发现的静默失败更少。
还有一个硬优势:128K的上下文窗口是原生的。每连一个MCP服务,工具schema就会往上下文里加。三个服务各带10个工具,就是3000到5000个token的schema。GLM-5.1的窗口能轻松吞下这些,不会压缩你的对话内容。上下文小的模型,工具描述会被裁剪,然后调用就开始出问题了。
Gemma 4:接近了,但还不够
简单任务:10/10。 满分。
中等任务:8/10。 两次失败,模式一模一样:Gemma完成了第一次调用,拿到结果,然后——直接从结果生成答案,跳过了第二次调用。输出看起来合理,因为它从部分数据做了综合。但步骤就是跳了。
复杂任务:5/10。 一半的测试都失败了。模式贯穿始终:Gemma对链式调用很保守。第一次调用可靠,第二次看运气。到第三第四次,它就开始"编"了,用已有的东西凑答案,而不是真的去调下一个工具。输出读起来没问题,只是没有基于它本该检索到的数据。
综合完成率:77%。
最让人懊恼的是,Gemma的单次调用本身质量不错。函数调用的训练底子是好的。Apache 2.0许可证,原生函数调用支持,还能做多模态(在工具链里处理图像——这是Qwen和GLM做不到的)。纸面上看,它应该是首选。
但在实践中,"链条走捷径"这个毛病让它在三步以上的Agent工作流里完全不可靠。你的Agent看起来做完了任务,输出读起来也连贯,你压根不会发现它跳过了网页搜索、用训练数据代替了实时结果——直到你手动验证。
如果只用单步工具(分类一封邮件、搜个网页、读个文件),Gemma 4很优秀。多步链式调用?它会悄悄偷工减料。
MiniMax M2.7:没达标
简单任务:9/10。 一次JSON参数格式不对。
中等任务:6/10。 四次失败。翻车方式五花八门:参数类型传错、自己编造不存在的工具名、甚至有一次直接生成了一段自然语言描述"我想做什么"——而不是真正去调用工具。
复杂任务:3/10。 七次失败。到第三步之后,模型就开始持续失焦。工具调用越来越"有创意"(越来越错)。最经典的一个错误:调用文件系统写入工具的时候,把搜索结果当成了文件名,把文件名当成了内容——参数完全颠倒了。
综合完成率:60%。
每百万输入token才0.3美元,MiniMax是这次测试里最便宜的,而且是大幅度便宜。在简单编程测试上,它的SWE-Bench Pro得分56.22%,达到GLM-5.1的94%。但这个数据对Agent工作有误导性。编程测试测的是代码生成,Agent工作测的是在上下文压力下的结构化工具调用。MiniMax写代码还行,工具调用不行。
如果只用单步任务(分类、提取、摘要),MiniMax能用,价格无敌。如果要串三个以上工具,60%的完成率意味着你调试失败的时间比用结果的时间还多。
总结:四兄弟的真实差距
从测试结果里能看到一条清晰的梯度线:
单次工具调用:四个模型都行(完成率77%到100%)。一次调用、一个结果、一段输出。这种演示让每个模型看起来都不错。
两次工具链:差距开始浮现。Gemma开始走捷径,MiniMax开始生成错误调用。
三次以上:只有Qwen和GLM能稳定走完。Gemma靠部分数据"编"答案,MiniMax彻底失焦。
如果你的Agent每次交互只用一次工具(搜一下、分个类、提个取),挑最便宜的就行。但如果你的Agent要把工具串起来——先搜索,再分析结果,然后写报告,最后发摘要——模型的选择就至关重要。这个选择直接决定了你得到的是一套自动化流水线,还是一个需要不断擦屁股的半成品。
一句话选型指南:
想要最稳的工具调用 → Qwen 3.6 27B(硬件有限就上35B-A3B MoE),单次准确率最高,社区验证最充分。
要跑长流程无人值守 → GLM-5.1,低幻觉率 + 持久耐力,跑一整夜不用担心静默失败。
多模态刚需 → Gemma 4,但链条控制在两步以内。
大规模单步分类 → MiniMax M2.7,便宜到可以忽略不计,但别串。
或者更直白一点:能生成最漂亮文字的模型,不一定是你工具调用最可靠的模型。Agent工作里,工具调用的可靠性就是一切。四个模型里,两个有,两个没有。
