 夜雨聆风
夜雨聆风这是《智能体软件工程》系列的第十篇。 AI 编码正在变成一座"软件工厂"。这一篇谈一个工具不需要、但工厂躲不掉的问题:它凭什么可信。 一句话立在最前面:不要信,去验证。

一 · 现状
一个真实的小问题
先讲一件我经历的真事。
一个我认识的朋友,他是某大厂工程师,曾经咨询过我一个问题,如何向外部证明一件事:同样的源码、同样的环境,编出来的二进制必须逐位一模一样。为什么要这个?因为外部不放心,担心他在二进制里塞了后门。
他在虚拟机里编了一遍,发现制品大小是一样的,但问题是,怎么比对里面的二进制内容?
其实真正的问题本质不是二进制内容该如何证明,真正的问题是,「别人凭什么信他」?一个写代码的人,要怎么向一个根本不信任他的人,证明出厂的东西没被动过手脚。
这个问题,整个软件行业给出的答案只有一个方向:不要信,去验证。可复现,是验证,不是信仰。你想别让人相信你,那你就应该让别人能自己核对。
积木都造好了:一根纵轴,四层
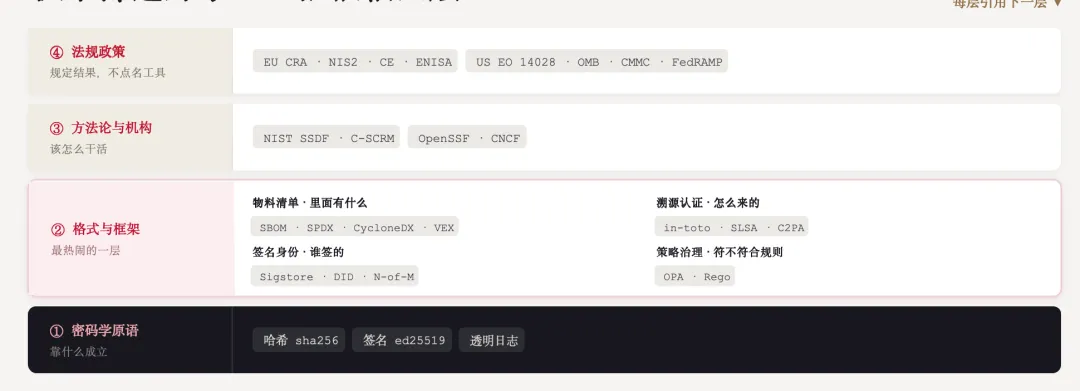
为了回答"凭什么信",业界这些年其实已经把“可信积木”都造齐了。它看着乱,是一堆缩写,但有清晰的结构:一根纵轴,从下往上四层,每层引用下一层。
最底下,第一层,是密码学原语。靠什么成立。哈希(sha256)、签名(ed25519)、透明日志。这是整套体系的地基,是数学。
往上第二层,是格式与框架,也是最热闹的一层。这一层我按"它回答什么问题"分四组。物料清单回答"里面有什么" (SBOM、SPDX、CycloneDX),再加上回答"漏洞真不真有影响"的 VEX。溯源认证回答"怎么来的"(in-toto、SLSA),还有管媒体内容的 C2PA。签名身份回答"谁签的"(Sigstore、DID,以及多人签核的 N-of-M)。策略治理回答"符不符合规则" (OPA、Rego)。
第三层,是方法论与机构,该怎么合规的干活。NIST 的 SSDF 是一套安全开发实践,C-SCRM 是供应链风险管理框架;再加上 OpenSSF、CNCF 这些把标准养起来的机构。
最顶上第四层,是法规政策。欧盟的 CRA、NIS2、CE、ENISA,美国的一串行政令、OMB、CMMC、FedRAMP。这一层的特点是:它规定"必须拿出什么结果",但不点名工具。
但攻击搬家了:打的就是 AI 作者层
这套体系最初是被一批事故逼出来的。历史上,攻击打的是构建和依赖:2020 年的 SolarWinds,构建系统被植入后门;2021 年的 Log4Shell;还有各种依赖混淆。
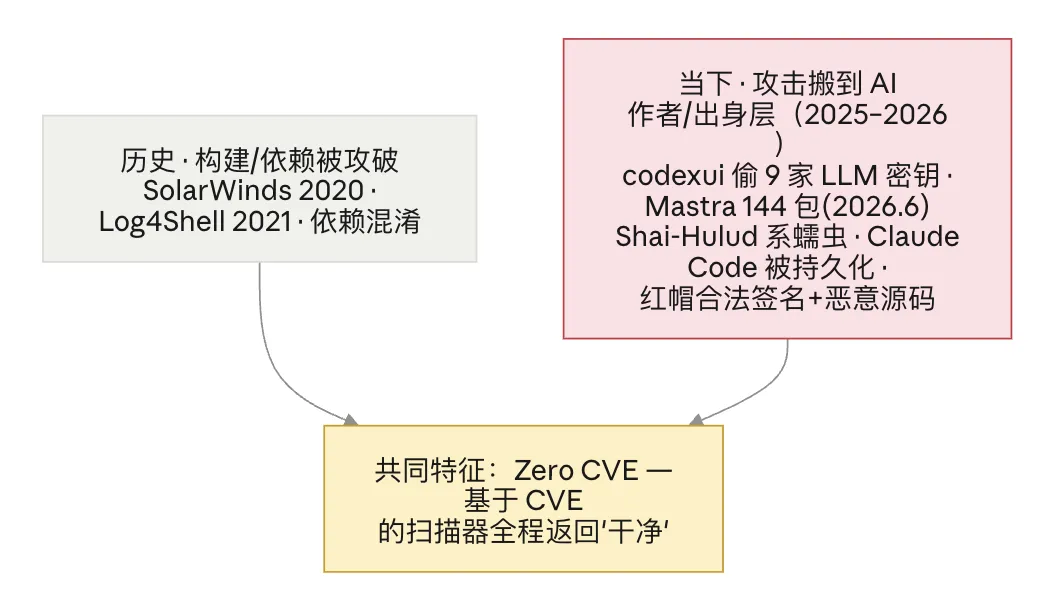
但当下,2025 到 2026 年,攻击搬家了,它打的就是 AI 作者这一层。
2025 年 9 月出现了一个叫 Shai-Hulud 的蠕虫,能自传播。偷到一个开发者的发布令牌,就自动给他维护的每一个包注入恶意代码、重发,不用人插手。它瞄准谁?有个叫 codexui 的包,伪装成 OpenAI Codex 的客户端,专偷九家大模型厂商的密钥。今年 6 月,就在十天前,有人攻陷了 Mastra 这个 AI 框架的 npm 组织,在 144 个包里塞进仿冒依赖,专偷 LLM 密钥。还有蠕虫把自己写进 Claude Code 的会话钩子,做持久化,你 uninstall 都删不掉。以及红帽那起——合法签名,盖在恶意源码上,这个后面单独讲。
这些攻击有一个共同特征,我把它叫 Zero CVE:活跃期间,它们几乎都没有被分配 CVE,基于 CVE 的漏洞扫描器全程返回"干净"。
这句话的分量在于:旧的那套栈,在"作者与出身的完整性"这一维,是失明的。它会查有什么组件、有没有已知漏洞,但攻击根本不在这一维上。
二 · AI 高速发展
AI coding 正在进化成"软件工厂"
为什么"作者"这一维突然变得这么要紧?因为写代码的,越来越不是人了。
AI coding 这两年的进化,是一条很清楚的阶梯。第一级,自动补全,行级的,比如 Copilot。第二级,对话助手,给你代码片段,比如 ChatGPT。第三级,单个 Agent,能自己跑命令、修 bug,比如 SWE-agent。第四级,Agent 工作流,多个 agent 协作跑很长的任务。第五级,软件工厂,意图进,系统出,你给一句话,它给你一个能跑的产品。
每往上一级,我们交给 AI 的"委托量"都在往上调。而比阶梯本身更深的一件事是:工程的重心,正在离开模型。
重心离开模型:三根轴,CBV
重心离开模型,那它落到哪儿去了?最近三年,这块空间被各种名词所定义:Prompt 工程 、Context 工程、Harness 工程、Loop 工程等。
这些名词变换的背后,实际上是工程的重心离开模型向行业领域迁移的过程,也是 AI 从「缸中大脑」逐步长出「手脚」的过程。
在这里,我只想用一个三轴框架来定坐标,叫 CBV。
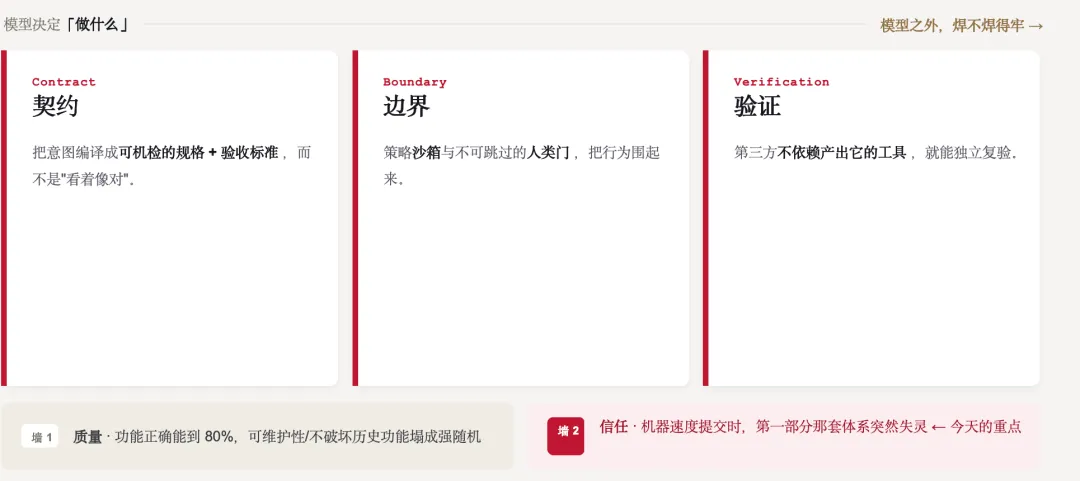
模型只决定一件事:做什么。模型之外,焊不焊得牢,看三根轴。
Contract,契约。把意图编译成可机检的规格和验收标准,而不是"看着像对"。Boundary,边界。用策略沙箱和不可跳过的人类门,把行为围起来。Verification,验证。让第三方不依赖那个产出它的工具,就能独立复验。
软件工厂能不能成,不取决于模型多强,取决于这三根轴。而工厂跑起来,会撞上两堵墙。
第一堵是质量。开放式需求里,功能正确能做到 80%,但可维护性、不破坏历史功能这些维度,会塌成强随机。第二堵是信任:当工厂以机器速度往仓库里提交,第一部分那套信任体系,突然就失灵了。第二堵,是今天的重点。
三 · 工厂要合规
机器速度提交,四个问题突然没了答案
工厂一旦以机器速度提交,四个最朴素的问题,突然就没人答得上来。
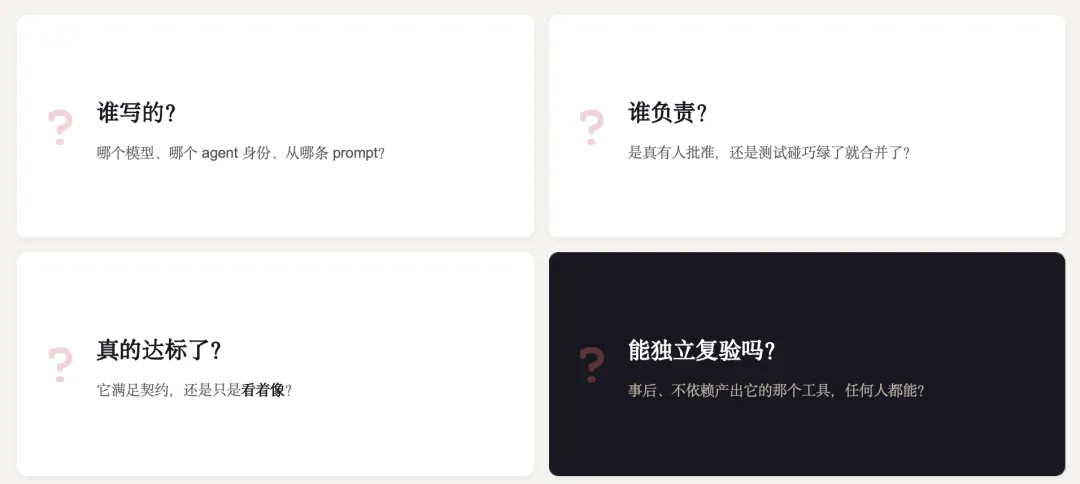
AI Coding 让 程序员产生了身份危机。 代码是 AI 写的,为什么人类开发者还叫程序员?这身份危机背后的问题,其实是一个软件可信危机。
代码谁写的?哪个模型、哪个 agent 身份、从哪条 prompt?谁负责?是真有人批准,还是测试碰巧绿了就合并了?真的达标了?它是满足了契约,还是只是看着像?能独立复验吗?事后、不依赖那个产出它的工具,任何人都能核一遍吗?
这四个问题答不上来,"信任"就无从谈起。
合规在收紧,但要讲准
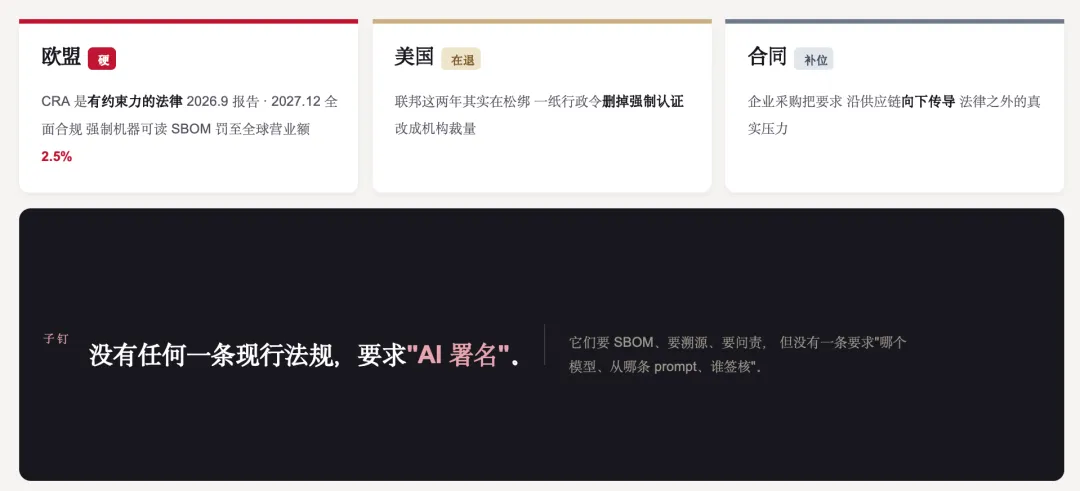
而这撞上合规收紧。但这里真正硬的约束,只有欧盟。 CRA 是有约束力的法律,2026 年 9 月报告义务、2027 年 12 月全面合规,强制机器可读 SBOM,罚到全球营业额 2.5%。企业采购在把它沿供应链往下传导。但美国联邦这两年其实在松绑。一纸行政令删掉了强制认证,改成机构裁量。所以准确的说法是:欧盟法律硬、美国在退、合同在补位。
独缺 AI 作者那一维
现有供应链栈已经拥有了三样:组件清单,有 SBOM;构建出身,有 SLSA;签名身份,有 Sigstore、DID。独缺的,是 AI 作者这一维 ,谁、哪个模型、哪条 prompt、哪几行是 AI 哪几行是人、谁签核。为什么缺?因为造这套栈的时候,AI 还不写代码。
一个可信的软件工厂,需要补上这一维。它定义一个 in-toto predicate,叫 openfab/generation,跟 SLSA 同级,骑在 in-toto、SLSA、Sigstore、DID 这批现成原语上,只补那个缺失的维,不重新发明轮子。
四 · 两个闭环
AI 可信软件工厂其实要解决两个问题
AI 自动化软件,被当成一个问题,其实是两个。

一个是生成闭环,关于正确性:生成的代码,做了要求的事吗?这一半,学术界有个很好的代表叫 ARC(上海交大林云老师团队论文[1] ),把需求"编译"成可运行系统。另一个是信任闭环,关于问责:凭什么相信它做了它声称的事?
这两个是正交的。 AI 写得对,和能证明写得对、能追溯谁写的,是两件事。
信任闭环:Spec Cycle 七步
信任闭环具体怎么转?我们目前做的 OpenFab[2] 的心脏是一条七步流水线,叫 Spec Cycle,每一步本身都是一个带溯源信息的签名提交。
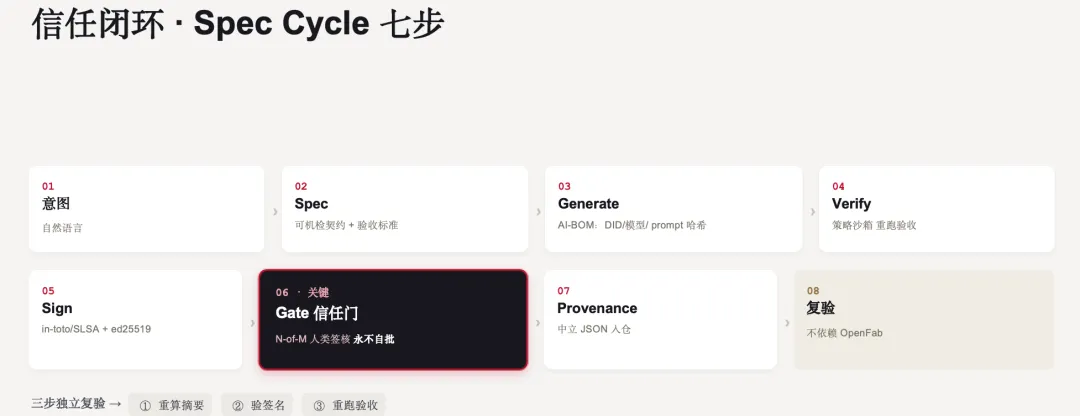
第一步,意图,自然语言。第二步,Spec,把意图"编译"成可机检的契约加验收标准。第三步,Generate,agent 写代码,同时记下 AI-BOM——DID、模型、prompt 哈希。第四步,Verify,把验收放进策略沙箱里真跑一遍。第五步,Sign,出 in-toto/SLSA 认证并用 ed25519 签名。第六步是关键,Gate 信任门——N-of-M 人类签核,永不自批。第七步,Provenance,溯源以中立 JSON 入仓。
最后是复验,而且不依赖 OpenFab:任何人三步就能独立核对——重算摘要、验签名、重跑验收。
同构的接缝:“焊”成一个闭环
两个闭环不是相邻,是能咬合成一个的,因为它们的接缝是同构的。

生成闭环这边,ARC 这类 Agent 负责生成得对:自然语言意图,先用 DSL 形式化成 Given/When/Then,再走双向 TDD、测试先于代码,产出一个可运行系统,外加一张可追溯记录 M。
信任闭环这边,OpenFab 负责证明它可信:冻结验收契约,做 ai/human 署名加签名,过 N-of-M 人类门,最后产出一个签名构件,任何 forge 上、三步可复验。
中间的接缝,是 ARC 那张可追溯记录 M,约等于 OpenFab 那个 predicate。它们都是把意图锚到被验证构件的同一种溯源图。
映射到我前面提到的 CBV:Contract 就是验收,Boundary 就是沙箱加 N-of-M,Verification 就是三步复验。
一个回答"它对不对",一个回答"凭什么信",合起来,才是"可信的 AI 自动化软件"。
诚实校准之一:签名 ≠ 安全
先说一个反直觉的事实:签名不等于安全。两种真实的失败,正好划清了 provenance 的边界。
第一种,伪造签名。同一波攻击里,@antv 那起就是伪造 SLSA 认证来伪装合法。这种挡得住——靠透明日志,Sigstore 的 Rekor:有一份不可篡改、人人可查的记录,伪造的一比对就露馅。
第二种更难缠,合法签名盖在恶意源码上。红帽那起:攻击者用 OIDC 真签名,加孤儿提交绕过代码评审,把恶意代码合法地签了进去。证书是真的,包确实是合法流水线构建的。这种,签名根本挡不住。只能靠那道不可跳过的人类评审门,N-of-M。
所以 OpenFab 可信软件工厂的重点,不是"签了名就安全",而是"不可跳过的人类问责"。
本质上,OpenFab 改变不了"端点被完全接管就完蛋"这个物理极限,但对"攻击作者/出身"这一整层,它把原来一团黑的事变成了可归因、可遏制、可拉高成本的事。
具体可以分四点。
一、把"AI 作者"从盲区变成一等公民。 现有供应链栈(SBOM/SLSA/签名)焊住了组件、构建、身份,唯独缺"这段代码是人还是 AI 写的、哪个模型、哪条 prompt"。因为造它时 AI 还不写代码。OpenFab 的 openfab/generation predicate 就补这一维:逐文件、精确到行,记下 ai/human 署名、agent 身份、模型、prompt 哈希。这是它唯一真正新增的东西,也是别的栈给不了的。
二、把签核动作钉成不可抵赖的记录。 即便攻击者用合法身份签了恶意代码(红帽那种、或接管你电脑那种),他也在 append-only 的透明日志里、以真实身份、留下了一条带时间戳、带文件级 diff、带 prompt 哈希的证据,抹不掉。于是出事后能精确定位:哪个身份、哪次签核、动了哪几行。把"神不知鬼不觉"变成"必然留下一条以你名义、删不掉的供述"。
三、用 N-of-M 多人多机把单点沦陷和发布沦陷拉开。发布必须 M 个里有 N 个独立的人、在各自机器上签核、且永不自批,攻击者就得同时攻陷 N 台不同电脑,成本指数级上升。它消除不了端点沦陷,但让"放倒一台 = 发布完蛋"变成"得同时放倒好几台"。这是它在自己这一层对"接管作者"最实在的抵抗。
四、让出身可被第三方离线复验,不依赖信任它。 溯源是中立 JSON 入仓,任何人三步复验(重算摘要、验签名、重跑验收),不需要装 OpenFab、不需要信任你的工具。出身从"你说的"变成"谁都能自己核的"。
但要诚实划清它的两条边界(这也是它和"我们能防住一切"的根本区别):
它防不住"端点被完全接管"和"合法签名盖恶意源码"。这两种攻击用的是真身份、真签名,密码学上跟本人无法区分。这是信任根的物理极限,不是 OpenFab 的缺陷。守住端点本身,是 HSM(私钥进硬件)+ N-of-M 多机多人的活,不是溯源这一层该解决的。 它证明的是"来历",不是"安全"。"谁、用什么、写了哪几行"有锚点,它焊得死;"源码本身干不干净"没有锚点,签名和复现都焊不住,只能靠那道不可跳过的人类评审门。而那道门也只在人真的去读时才有用。
诚实校准之二:可复现,不等于可信
回到开头那位工程师的"证明无后门"。可复现构建能证明二进制对应源码。编译过程没插后门,这正切掉他外部方的恐惧。但它不证明源码本身干净,一个写在源码里的后门,会完美地逐位复现。所以"复现/签名 ≠ 安全":复现挡住"编译期注入",签名挡住"事后篡改",但源码本身有没有后门,只能靠那道人类评审门。而那道门,正是 OpenFab 做成不可跳过的东西。
验收标准在自动模式下也是模型写的,同一个模型既写代码又写验收,所以人类门必须真读验收,而不是看见绿就签。这里说的"可复现"是源码与签名摘要逐位一致,不是从 prompt 重新生成同样的代码,LLM 生成非确定。OpenFab 给的是验证的信封,不是锚点本身。它不替你造裁判,但这恰恰是对的,因为可验证性是任务自带的属性,你本来就造不出锚点,只能诚实地把它围起来、签下来。
当然,也得说两句公道话,因为一座诚实的工厂得知道自己的极限。
人这道门不是万能的。它只在人真的去读、真的去想的时候才有用。如果签字的人只是看见绿色就点同意,这道门就是个橡皮图章。机器能保证门存在、能记下谁签了字,但门后面那个人有没有用心,机器担保不了"人有没有认真审"这件事本身,也没有锚点。
还有一种攻击,这套体系也防不住:如果攻击者完全接管了签核人的电脑,他就是那个人,能用真身份、真签名签出恶意代码,密码学上和本人无法区分。这是信任根的物理极限,不是这套体系的缺陷——任何体系都跨不过去。守住那台电脑本身,是硬件密钥和多人多机的活,不是溯源这一层该解决的。这套体系能做的是另外两件:用 N-of-M 多人多机,把"攻陷一台"和"发布成功"之间拉开距离,逼攻击者同时放倒好几台;以及,无论谁签的,都让这次签核成为一条以真实身份留痕、删不掉的记录。它不让沦陷不可能,它让沦陷藏不住、且更贵。
这就是为什么我说它是"补齐",不是"魔法"。
五 · Demo
不是 PPT 概念,是能跑的东西
OpenFab 不是一套 PPT 概念,是能跑的东西。三种用法。可以看我们的展示 OpenFab demo 视频。
人在聊天室(基于我们用 Rust 开发的 Matrix IM Robrix[3] 和我们的 Agentic OS Octos[4])里提需求,自然语言;Coordinator 起草 spec 并触发构建;OpenFab 跑生成、验收、签名;信任门阻断,把待签核的请求推回房间;人在房间里回一句 approve;OpenFab 合并、溯源入仓;最后把合并回执推回房间。

人始终在自己熟悉的聊天室里,就完成了"提需求—审批—拿回执"的闭环。
结尾
所以,一座可信的软件工厂,不是一台能给你盖章"安全"的机器。它是一条产线:把所有有锚点的事,工业化地变成谁都能复验的记录;在那些机器判不了的工位上,逼一个具体的人站出来,签上自己的名字。有锚点的,它可以与 AI 深度绑定;没锚点的,它老实交还给人,并且把"谁交还给了谁"记下来。
这就是为什么我说,赌注不该下在模型更强。模型再强,也跨不过锚点那道坎;真正稀缺的,是让有锚点的部分可被验证、让没锚点的部分有人负责的那套纪律。芯片厂用一百年磨出了这套纪律。软件,才刚开始。
而把这套纪律落到代码上,Rust 是个好材料。一个把"不可信"当一等公民、逼你在编译期就把边界讲清楚的语言,天生适合用来搭那一层可信。
可复现,不等于可信。能复现、能签名的,是来历;不能的,是安全。一座工厂能把来历做到极致,但安全,到今天为止,还得有人,站在那个工位上,签下名字。
上海交大林云老师团队论文: https://arxiv.org/pdf/2602.13723
[2]OpenFab: https://github.com/Open-fab-ai/openfab
[3]Robrix: https://github.com/Project-Robius-China/robrix2
[4]Octos: https://github.com/octos-org/octos
