夜雨聆风
夜雨聆风业务场景
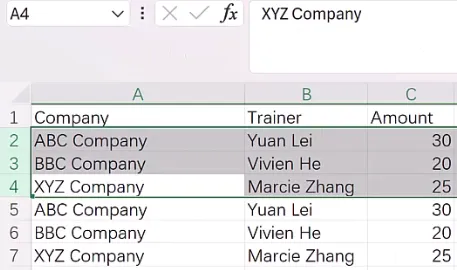
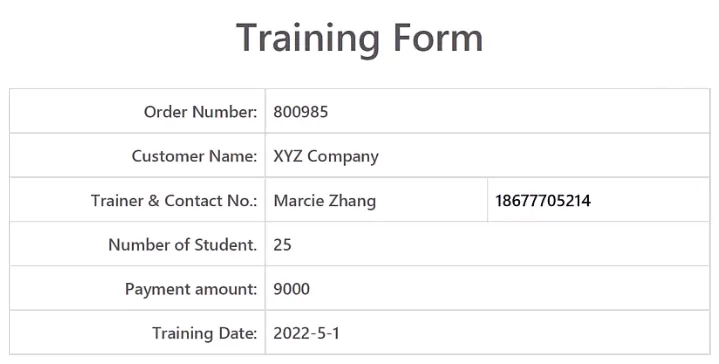
财务、运营、行政人员日常会收到大量财报、报价单、客户信息PDF单据,需要把表格数据录入Excel汇总对账;手动复制粘贴耗时易出错,先转Word再提取表格步骤繁琐、格式容易错乱。利用PAD可后台直接解析PDF原生表格,批量提取指定字段自动追加至Excel,无需打开PDF软件,大幅减少人工录入工作量。
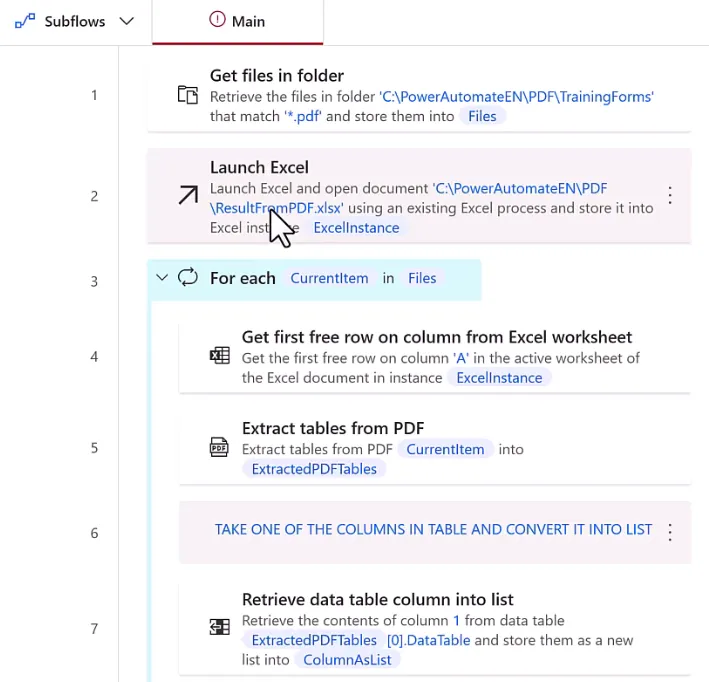
一、适用文件类型
带有规整结构化表格的PDF文件:财报、报价单、客户信息表、单据、统计报表、信息登记表等; 支持批量多份PDF文件循环处理,无需手动逐个操作; 仅解析PDF内部原生表格,无需打开PDF客户端,后台直接读取文件数据。
二、适配数据场景
需要将PDF内表格数据批量录入Excel做汇总、统计、对账; 仅需要提取表格内指定几列字段(名称、金额、电话、编号等),无需完整全文; Excel已有历史数据,需要在空白行追加新PDF数据,不覆盖原有内容; 替代「PDF转Word再提取表格」两步繁琐流程,一步完成导出。
三、技术适配范围
单页/多页PDF均可,支持指定全部页面提取表格; 一份PDF包含多张数据表:通过下标 [0]、[1]区分不同表格(下标从0开始);
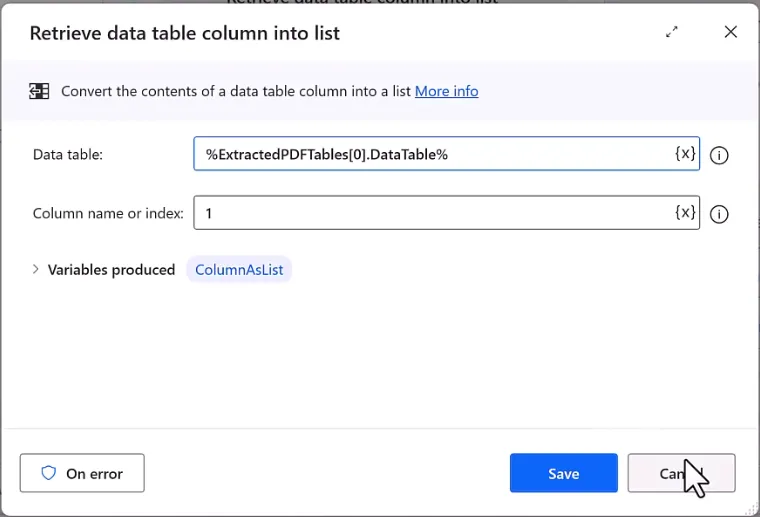
表格存在轻微不规则错位(如单元格偏移),可通过列索引精准抽取目标字段; 可将二维数据表转为一维列表,单独拆分每一列数据写入Excel对应列。
四、不适用场景
PDF内容为图片扫描件(无原生表格,纯图像无法识别表格结构); 无表格、纯零散文字排版的PDF; 复杂手绘、无边框、分段碎片化无法识别为结构化表格的文档。
之后你再输出任何教程、总结、问答内容,我都会优先补充对应的业务场景描述。